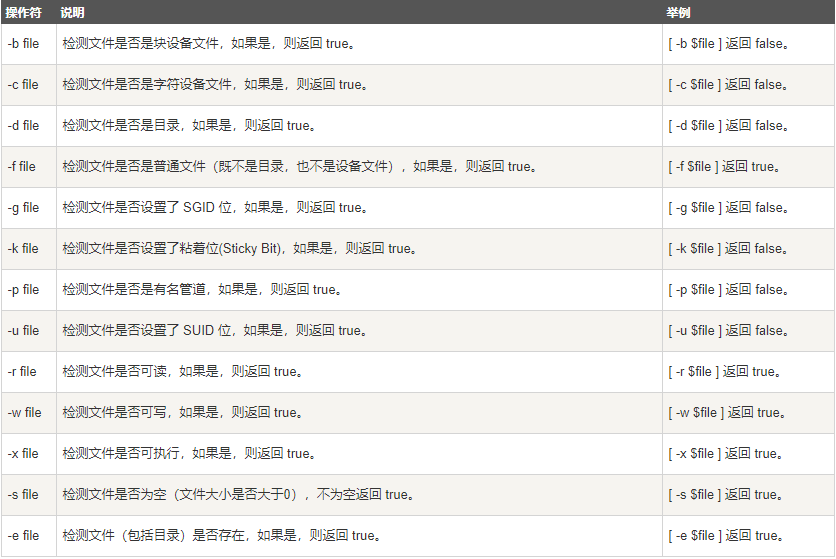
在“使用大型语言模型(LLMs)的生成性AI”中,您将学习生成性AI的基本工作原理,以及如何在实际应用中部署它。
通过参加这门课程,您将学会:
- 深入了解生成性AI,描述基于LLM的典型生成性AI生命周期中的关键步骤,从数据收集和模型选择,到性能评估和部署
- 详细描述为LLMs提供动力的变换器架构,它们是如何被训练的,以及微调如何使LLMs能够适应各种特定的用例
- 使用经验性的缩放法则来优化模型的目标函数,跨数据集大小、计算预算和推断要求
- 应用最先进的训练、调整、推断、工具和部署方法,以在项目的特定约束条件下最大化模型的性能
- 在听取行业研究人员和从业者的故事后,讨论生成性AI为企业带来的挑战和机会
对于那些对LLMs的工作原理有良好基础理解的开发者,以及了解训练和部署它们背后的最佳实践的人,他们将能够为公司做出明智的决策,并更快地构建工作原型。这门课程将帮助学习者建立关于如何最好地利用这一令人兴奋的新技术的实用直觉。
这是一门中级课程,所以您应该有一些Python编码的经验,以便从中获得最大的收益。您还应该熟悉机器学习的基础知识,如有监督和无监督学习、损失函数、以及将数据分为训练、验证和测试集。如果您已经参加了DeepLearning.AI的机器学习专项课程或深度学习专项课程,那么您将准备好参加这门课程,并深入探讨生成性AI的基础知识。
我们将讨论大型语言模型、它们的使用案例、模型如何工作、提示工程、如何生成创意文本输出,并为生成性AI项目概述一个项目生命周期。

考虑到您对这门课程的兴趣,可以肯定地说,您已经有机会尝试一个生成性AI工具或希望这样做。无论是聊天机器人、
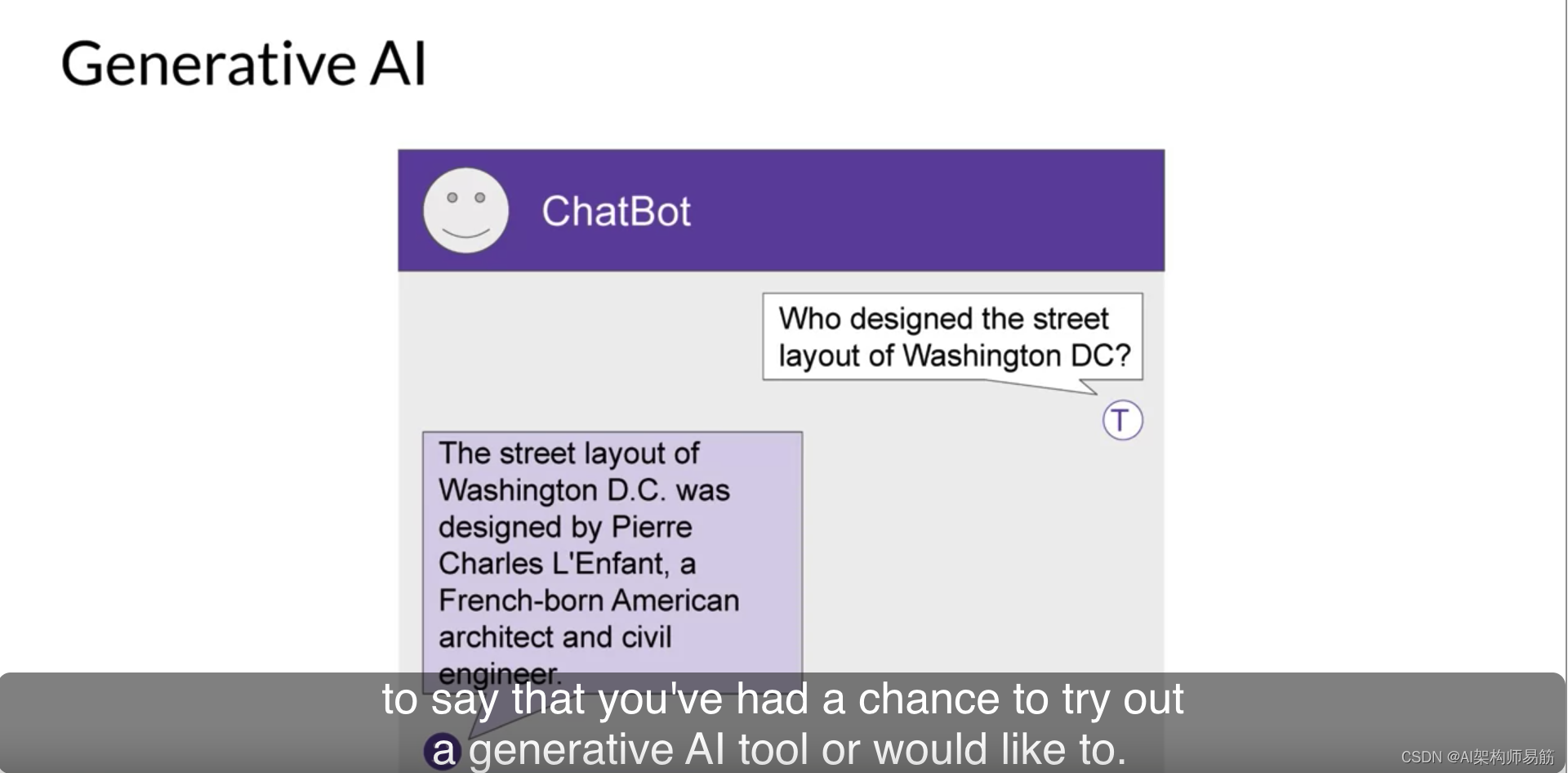
从文本生成图像,
还是使用插件帮助您开发代码,
您在这些工具中看到的都是一台能够创建模仿或接近人类能力的内容的机器。
生成性AI是传统机器学习的一个子集。支撑生成性AI的机器学习模型通过在由人类最初生成的大量内容数据集中找到统计模式来学习这些能力。大型语言模型经过数周和数月的时间,在数万亿的词上进行了训练,并使用了大量的计算能力。我们称之为基础模型的这些模型,拥有数十亿的参数,展现出超越语言本身的突现性质,研究人员正在解锁它们分解复杂任务、推理和解决问题的能力。

这里是一系列基础模型的集合,有时被称为基础模型,以及它们在参数方面的相对大小。稍后您将更详细地了解这些参数,但现在,请将它们视为模型的记忆。模型的参数越多,记忆就越多,事实证明,它可以执行的任务也越复杂。在整个课程中,我们将用这些紫色的圆圈代表LLM,在实验室中,您将使用一个特定的开源模型,flan-T5,来执行语言任务。通过直接使用这些模型或应用微调技术将它们适应您的特定用例,您可以迅速构建定制解决方案,而无需从头开始训练新模型。
现在,虽然为多种模式创建了生成性AI模型,包括图像、视频、音频和语音,但在这门课程中,您将重点关注大型语言模型及其在自然语言生成中的用途。您将了解它们是如何构建和训练的,如何通过文本与它们互动,这些文本被称为提示。以及如何为您的用例和数据微调模型,以及如何与应用程序一起部署它们来解决您的商业和社会任务。
与语言模型互动的方式与其他机器学习和编程范式大不相同。在那些情况下,您使用正式化的语法编写计算机代码与库和API互动。相反,大型语言模型能够接受自然语言或人类编写的指令,并像人类一样执行任务。您传递给LLM的文本被称为提示。可用于提示的空间或记忆称为上下文窗口,这通常足够容纳几千个词,但因模型而异。

在这个例子中,您要求模型确定Ganymede在太阳系中的位置。提示传递给模型,模型然后预测下一个词,因为您的提示包含了一个问题,这个模型生成了一个答案。模型的输出称为完成,使用模型生成文本的行为称为推断。完成包括原始提示中包含的文本,后跟生成的文本。您可以看到这个模型很好地回答了您的问题。它正确地识别出Ganymede是木星的一颗卫星,并为您的问题生成了一个合理的答案,说明这颗卫星位于木星的轨道内。
在整个课程中,您将看到许多这种风格的提示和完成的示例。
参考
- https://www.coursera.org/programs/hsbc-finance-people-and-personal-development-dnger/learn/generative-ai-with-llms
- https://www.coursera.org/learn/generative-ai-with-llms/lecture/IrsEw/generative-ai-llms