安全且高效的处理并发编程是 Rust 的另一个主要目标。并发编程(Concurrent programming),代表程序的不同部分相互独立的执行,而 并行编程(parallel programming)代表程序不同部分于同时执行,这两个概念随着计算机越来越多的利用多处理器的优势时显得愈发重要。由于历史原因,在此类上下文中编程一直是困难且容易出错的:Rust 希望能改变这一点。
起初,Rust 团队认为确保内存安全和防止并发问题是两个分别需要不同方法应对的挑战。随着时间的推移,团队发现所有权和类型系统是一系列解决内存安全 和 并发问题的强有力的工具!通过利用所有权和类型检查,在 Rust 中很多并发错误都是 编译时 错误,而非运行时错误。因此,相比花费大量时间尝试重现运行时并发 bug 出现的特定情况,Rust 会拒绝编译不正确的代码并提供解释问题的错误信息。因此,你可以在开发时修复代码,而不是在部署到生产环境后修复代码。我们给 Rust 的这一部分起了一个绰号 无畏并发(fearless concurrency)。无畏并发令你的代码免于出现诡异的 bug 并可以轻松重构且无需担心会引入新的 bug。
注意:出于简洁的考虑,我们将很多问题归类为 并发,而不是更准确的区分 并发和(或)并行。如果这是一本专注于并发和/或并行的书,我们肯定会更加精确的。对于本章,当我们谈到 并发 时,请自行脑内替换为 并发和(或)并行。
很多语言所提供的处理并发问题的解决方法都非常有特色。例如,Erlang 有着优雅的消息传递并发功能,但只有模糊不清的在线程间共享状态的方法。对于高级语言来说,只实现可能解决方案的子集是一个合理的策略,因为高级语言所许诺的价值来源于牺牲一些控制来换取抽象。然而对于底层语言则期望提供在任何给定的情况下有着最高的性能且对硬件有更少的抽象。因此,Rust 提供了多种工具,以符合实际情况和需求的方式来为问题建模。
16.1 使用线程同时运行代码
在大部分现代操作系统中,已执行程序的代码在一个 进程(process)中运行,操作系统则负责管理多个进程。在程序内部,也可以拥有多个同时运行的独立部分。运行这些独立部分的功能被称为 线程(threads)。
将程序中的计算拆分进多个线程可以改善性能,因为程序可以同时进行多个任务,不过这也会增加复杂性。因为线程是同时运行的,所以无法预先保证不同线程中的代码的执行顺序。这会导致诸如此类的问题:
- 竞争状态(Race conditions),多个线程以不一致的顺序访问数据或资源
- 死锁(Deadlocks),两个线程相互等待对方停止使用其所拥有的资源,这会阻止它们继续运行
- 只会发生在特定情况且难以稳定重现和修复的 bug
Rust 尝试减轻使用线程的负面影响。不过在多线程上下文中编程仍需格外小心,同时其所要求的代码结构也不同于运行于单线程的程序。
编程语言有一些不同的方法来实现线程。很多操作系统提供了创建新线程的 API。这种由编程语言调用操作系统 API 创建线程的模型有时被称为 1:1,一个 OS 线程对应一个语言线程。
很多编程语言提供了自己特殊的线程实现。编程语言提供的线程被称为 绿色(green)线程,使用绿色线程的语言会在不同数量的 OS 线程的上下文中执行它们。为此,绿色线程模式被称为 M:N 模型:M 个绿色线程对应 N 个 OS 线程,这里 M 和 N 不必相同。
每一个模型都有其优势和取舍。对于 Rust 来说最重要的取舍是运行时支持。运行时(Runtime)是一个令人迷惑的概念,其在不同上下文中可能有不同的含义。
在当前上下文中,运行时 代表二进制文件中包含的由语言自身提供的代码。这些代码根据语言的不同可大可小,不过任何非汇编语言都会有一定数量的运行时代码。为此,通常人们说一个语言 “没有运行时”,一般意味着 “小运行时”。更小的运行时拥有更少的功能不过其优势在于更小的二进制输出,这使其易于在更多上下文中与其他语言相结合。虽然很多语言觉得增加运行时来换取更多功能没有什么问题,但是 Rust 需要做到几乎没有运行时,同时为了保持高性能必需能够调用 C 语言,这点也是不能妥协的。
绿色线程的 M:N 模型需要更大的语言运行时来管理这些线程。因此,Rust 标准库只提供了 1:1 线程模型实现。由于 Rust 是较为底层的语言,如果你愿意牺牲性能来换取抽象,以获得对线程运行更精细的控制及更低的上下文切换成本,你可以使用实现了 M:N 线程模型的 crate。
使用spawn 创建新线程
为了创建一个新线程,需要调用 thread::spawn 函数并传递一个闭包(第十三章学习了闭包),并在其中包含希望在新线程运行的代码。
use std::thread;
use std::time::Duration;fn main() {thread::spawn(|| {for i in 1..10 {println!("hi number {} from the spawned thread!", i);thread::sleep(Duration::from_millis(1));}});for i in 1..5 {println!("hi number {} from the main thread!", i);thread::sleep(Duration::from_millis(1));}
}
注意这个函数编写的方式,当主线程结束时,新线程也会结束,而不管其是否执行完毕。这个程序的输出可能每次都略有不同,不过它大体上看起来像这样:
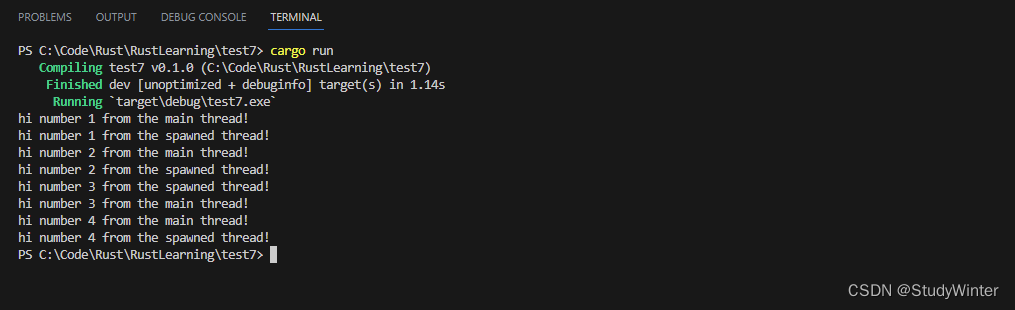
thread::sleep 调用强制线程停止执行一小段时间,这会允许其他不同的线程运行。这些线程可能会轮流运行,不过并不保证如此:这依赖操作系统如何调度线程。在这里,主线程首先打印,即便新创建线程的打印语句位于程序的开头,甚至即便我们告诉新建的线程打印直到 i 等于 9 ,它在主线程结束之前也只打印到了 5。
如果运行代码只看到了主线程的输出,或没有出现重叠打印的现象,尝试增加 range 的数值来增加操作系统切换线程的机会。
使用join 等待所有线程结束
由于主线程结束,示例中的代码大部分时候不光会提早结束新建线程,甚至不能实际保证新建线程会被执行。其原因在于无法保证线程运行的顺序!
可以通过将 thread::spawn 的返回值储存在变量中来修复新建线程部分没有执行或者完全没有执行的问题。thread::spawn 的返回值类型是 JoinHandle。JoinHandle 是一个拥有所有权的值,当对其调用 join 方法时,它会等待其线程结束。
use std::thread;
use std::time::Duration;fn main() {let handle = thread::spawn(|| {for i in 1..10 {println!("hi number {} from the spawned thread!", i);thread::sleep(Duration::from_millis(1));}});for i in 1..5 {println!("hi number {} from the main thread!", i);thread::sleep(Duration::from_millis(1));}// 调用join确保新建线程在 main 退出前结束运行handle.join().unwrap();}
通过调用 handle 的 join 会阻塞当前线程直到 handle 所代表的线程结束。阻塞(Blocking) 线程意味着阻止该线程执行工作或退出。因为我们将 join 调用放在了主线程的 for 循环之后,运行示例应该会产生类似这样的输出:
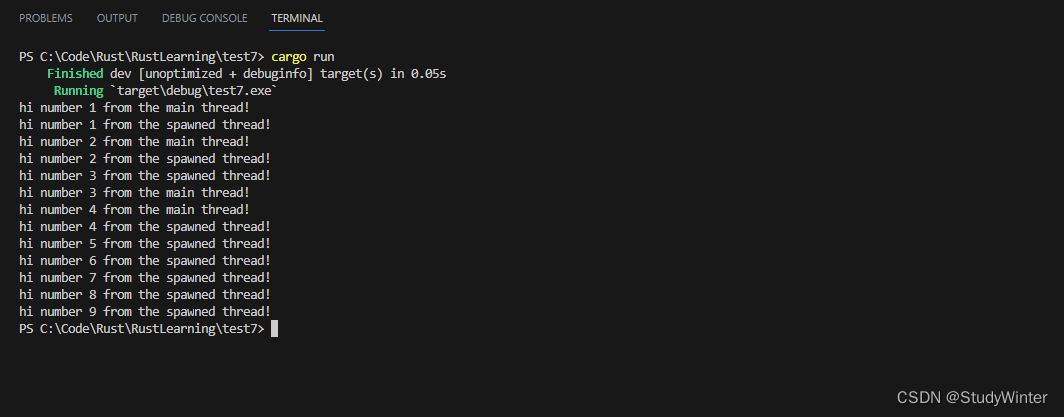
这两个线程仍然会交替执行,不过主线程会由于 handle.join() 调用会等待直到新建线程执行完毕。
不过让我们看看将 handle.join() 移动到 main 中 for 循环之前会发生什么,如下:
use std::thread;
use std::time::Duration;fn main() {let handle = thread::spawn(|| {for i in 1..10 {println!("hi number {} from the spawned thread!", i);thread::sleep(Duration::from_millis(1));}});// 调用join确保新建线程在 main 退出前结束运行handle.join().unwrap();for i in 1..5 {println!("hi number {} from the main thread!", i);thread::sleep(Duration::from_millis(1));}
}
主线程会等待直到新建线程执行完毕之后才开始执行 for 循环,所以输出将不会交替出现,如下所示:

稍微考虑一下将 join 放置于何处这样一个细节会影响线程是否同时运行。
线程与move闭包
move 闭包,其经常与 thread::spawn 一起使用,因为它允许我们在一个线程中使用另一个线程的数据。
注意上述示例中传递给 thread::spawn 的闭包并没有任何参数:并没有在新建线程代码中使用任何主线程的数据。为了在新建线程中使用来自于主线程的数据,需要新建线程的闭包获取它需要的值。下面示例展示了一个尝试在主线程中创建一个 vector 并用于新建线程的例子,不过这么写还不能工作,如下所示:
use std::thread;fn main() {let v = vec![1, 2, 3];let handle = thread::spawn(|| {println!("Here's a vector: {:?}", v);});handle.join().unwrap();
}
闭包使用了 v,所以闭包会捕获 v 并使其成为闭包环境的一部分。因为 thread::spawn 在一个新线程中运行这个闭包,所以可以在新线程中访问 v。然而当编译这个例子时,会得到如下错误:

Rust 会 推断 如何捕获 v,因为 println! 只需要 v 的引用,闭包尝试借用 v。然而这有一个问题:Rust 不知道这个新建线程会执行多久,所以无法知晓 v 的引用是否一直有效。
下面展示了一个 v 的引用很有可能不再有效的场景:
use std::thread;fn main() {let v = vec![1, 2, 3];let handle = thread::spawn(|| {println!("Here's a vector: {:?}", v);});drop(v);handle.join().unwrap();
}
假如这段代码能正常运行的话,则新建线程则可能会立刻被转移到后台并完全没有机会运行。新建线程内部有一个 v 的引用,不过主线程立刻就使用第十五章讨论的 drop 丢弃了 v。接着当新建线程开始执行,v 已不再有效,所以其引用也是无效的。噢,这太糟了!
通过在闭包之前增加 move 关键字,我们强制闭包获取其使用的值的所有权,而不是任由 Rust 推断它应该借用值。
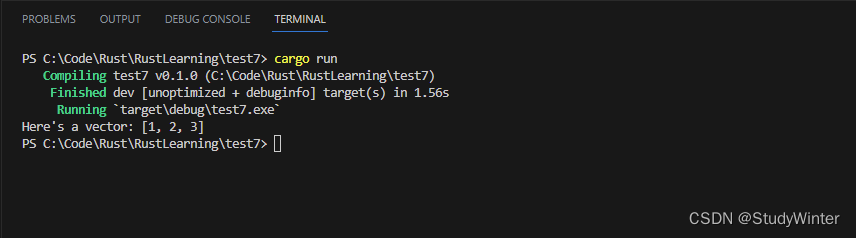
use std::thread;fn main() {let v = vec![1, 2, 3];let handle = thread::spawn(move || {println!("Here's a vector: {:?}", v);});handle.join().unwrap();
}
结果
16.2 使用消息传递在线程间传送数据
一个日益流行的确保安全并发的方式是 消息传递(message passing),这里线程或 actor 通过发送包含数据的消息来相互沟通。这个思想来源于 Go 编程语言文档中 的口号:“不要通过共享内存来通讯;而是通过通讯来共享内存。”(“Do not communicate by sharing memory; instead, share memory by communicating.”)
Rust 中一个实现消息传递并发的主要工具是 通道(channel),Rust 标准库提供了其实现的编程概念。你可以将其想象为一个水流的通道,比如河流或小溪。如果你将诸如橡皮鸭或小船之类的东西放入其中,它们会顺流而下到达下游。
编程中的通道有两部分组成,一个发送者(transmitter)和一个接收者(receiver)。发送者位于上游位置,在这里可以将橡皮鸭放入河中,接收者则位于下游,橡皮鸭最终会漂流至此。代码中的一部分调用发送者的方法以及希望发送的数据,另一部分则检查接收端收到的消息。当发送者或接收者任一被丢弃时可以认为通道被 关闭(closed)了。
这里,我们将开发一个程序,它会在一个线程生成值向通道发送,而在另一个线程会接收值并打印出来。这里会通过通道在线程间发送简单值来演示这个功能。一旦你熟悉了这项技术,就能使用通道来实现聊天系统,或利用很多线程进行分布式计算并将部分计算结果发送给一个线程进行聚合。
首先,在下面示例中,创建了一个通道但没有做任何事。注意这还不能编译,因为 Rust 不知道我们想要在通道中发送什么类型:
use std::sync::mpsc;fn main() {let (tx, rx) = mpsc::channel();
}
这里使用 mpsc::channel 函数创建一个新的通道;mpsc 是 多个生产者,单个消费者(multiple producer, single consumer)的缩写。简而言之,Rust 标准库实现通道的方式意味着一个通道可以有多个产生值的 发送(sending)端,但只能有一个消费这些值的 接收(receiving)端。想象一下多条小河小溪最终汇聚成大河:所有通过这些小河发出的东西最后都会来到下游的大河。目前我们以单个生产者开始,但是当示例可以工作后会增加多个生产者。
mpsc::channel 函数返回一个元组:第一个元素是发送端,而第二个元素是接收端。由于历史原因,tx 和 rx 通常作为 发送者(transmitter)和 接收者(receiver)的缩写,所以这就是我们将用来绑定这两端变量的名字。这里使用了一个 let 语句和模式来解构了此元组;第十八章会讨论 let 语句中的模式和解构。如此使用 let 语句是一个方便提取 mpsc::channel 返回的元组中一部分的手段。
让我们将发送端移动到一个新建线程中并发送一个字符串,这样新建线程就可以和主线程通讯了,如下面示例所示。这类似于在河的上游扔下一只橡皮鸭或从一个线程向另一个线程发送聊天信息:
use std::sync::mpsc;
use std::thread;fn main() {let (tx, rx) = mpsc::channel();thread::spawn(move || {let val = String::from("hi");tx.send(val).unwrap();});
}
将 tx 移动到一个新建的线程中并发送 “hi”
这里再次使用 thread::spawn 来创建一个新线程并使用 move 将 tx 移动到闭包中这样新建线程就拥有 tx 了。新建线程需要拥有通道的发送端以便能向通道发送消息。
通道的发送端有一个 send 方法用来获取需要放入通道的值。send 方法返回一个 Result<T, E> 类型,所以如果接收端已经被丢弃了,将没有发送值的目标,所以发送操作会返回错误。在这个例子中,出错的时候调用 unwrap 产生 panic。不过对于一个真实程序,需要合理地处理它:回到第九章复习正确处理错误的策略。
我们在主线程中从通道的接收端获取值。这类似于在河的下游捞起橡皮鸭或接收聊天信息:
use std::sync::mpsc;
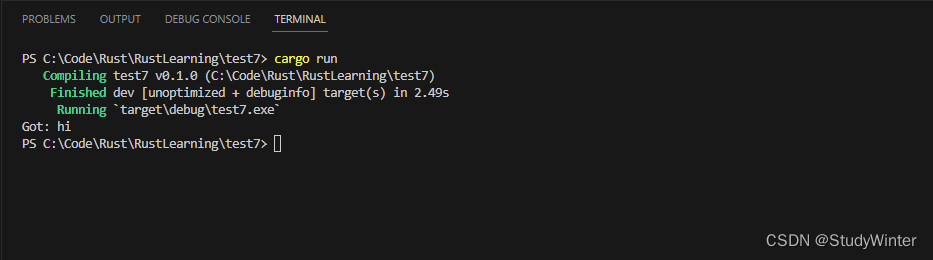
use std::thread;fn main() {let (tx, rx) = mpsc::channel();thread::spawn(move || {let val = String::from("hi");tx.send(val).unwrap();});// 接收数据let received = rx.recv().unwrap();println!("Got: {}", received);
}
通道的接收端有两个有用的方法:recv 和 try_recv。这里,我们使用了 recv,它是 receive 的缩写。这个方法会阻塞主线程执行直到从通道中接收一个值。一旦发送了一个值,recv 会在一个 Result<T, E> 中返回它。当通道发送端关闭,recv 会返回一个错误表明不会再有新的值到来了。
try_recv 不会阻塞,相反它立刻返回一个 Result<T, E>:Ok 值包含可用的信息,而 Err 值代表此时没有任何消息。如果线程在等待消息过程中还有其他工作时使用 try_recv 很有用:可以编写一个循环来频繁调用 try_recv,在有可用消息时进行处理,其余时候则处理一会其他工作直到再次检查。
出于简单的考虑,这个例子使用了 recv;主线程中除了等待消息之外没有任何其他工作,所以阻塞主线程是合适的。
通道与所有权转移
所有权规则在消息传递中扮演了重要角色,其有助于我们编写安全的并发代码。防止并发编程中的错误是在 Rust 程序中考虑所有权的一大优势。现在让我们做一个试验来看看通道与所有权如何一同协作以避免产生问题:我们将尝试在新建线程中的通道中发送完 val 值 之后 再使用它。
use std::sync::mpsc;
use std::thread;fn main() {let (tx, rx) = mpsc::channel();thread::spawn(move || {let val = String::from("hi");tx.send(val).unwrap();println!("val is {}", val); // 不可以});// 接收数据let received = rx.recv().unwrap();println!("Got: {}", received);
}
这里尝试在通过 tx.send 发送 val 到通道中之后将其打印出来。允许这么做是一个坏主意:一旦将值发送到另一个线程后,那个线程可能会在我们再次使用它之前就将其修改或者丢弃。其他线程对值可能的修改会由于不一致或不存在的数据而导致错误或意外的结果。
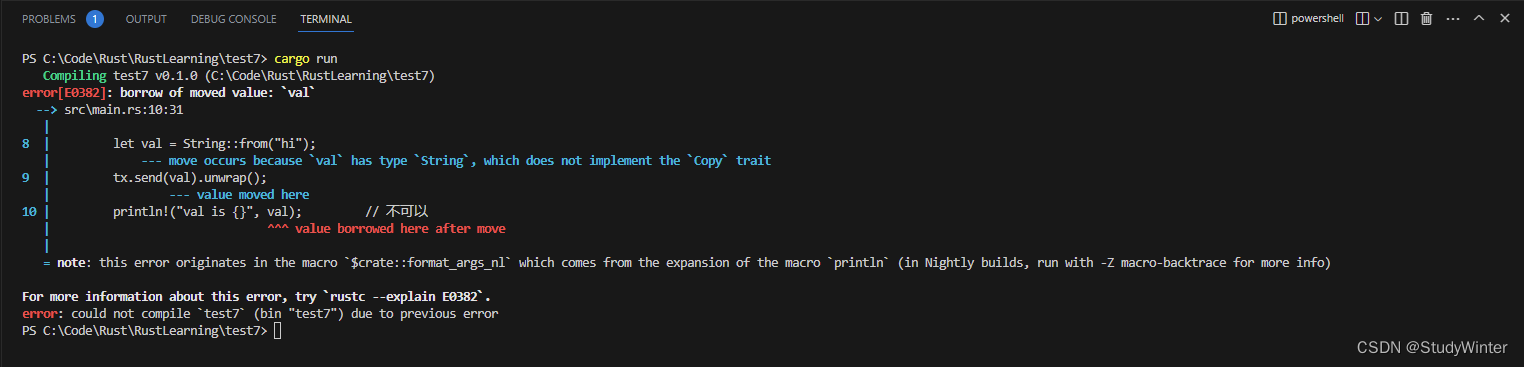
我们的并发错误会造成一个编译时错误。send 函数获取其参数的所有权并移动这个值归接收者所有。这可以防止在发送后再次意外地使用这个值;所有权系统检查一切是否合乎规则。
发送多个值并观察接收者的等待
新建线程现在会发送多个消息并在每个消息之间暂停一秒钟。
use std::sync::mpsc;
use std::thread;
use std::time::Duration;fn main() {let (tx, rx) = mpsc::channel();thread::spawn(move || {let vals = vec![String::from("hi"),String::from("from"),String::from("the"),String::from("thread"),];for val in vals {tx.send(val).unwrap();thread::sleep(Duration::from_secs(1));}});// 接收数据for received in rx {println!("Got: {}", received);}
}
这一次,在新建线程中有一个字符串 vector 希望发送到主线程。我们遍历他们,单独的发送每一个字符串并通过一个 Duration 值调用 thread::sleep 函数来暂停一秒。
在主线程中,不再显式调用 recv 函数:而是将 rx 当作一个迭代器。对于每一个接收到的值,我们将其打印出来。当通道被关闭时,迭代器也将结束。
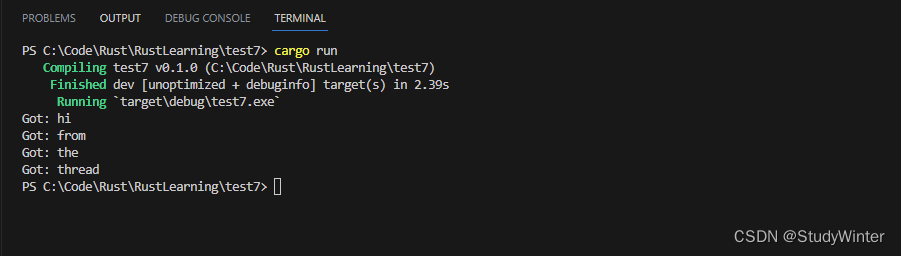
因为主线程中的 for 循环里并没有任何暂停或等待的代码,所以可以说主线程是在等待从新建线程中接收值。
通过克隆发送者来创建多个生产者
之前我们提到了mpsc是 multiple producer, single consumer 的缩写。可以运用 mpsc 来扩展示例 中的代码来创建向同一接收者发送值的多个线程。这可以通过克隆通道的发送端来做到,如下面示例所示:
use std::sync::mpsc;
use std::thread;
use std::time::Duration;fn main() {let (tx, rx) = mpsc::channel();let tx1 = mpsc::Sender::clone(&tx);thread::spawn(move || {let vals = vec![String::from("hi"),String::from("from"),String::from("the"),String::from("thread"),];for val in vals {tx1.send(val).unwrap();thread::sleep(Duration::from_secs(1));}});thread::spawn(move || {let vals = vec![String::from("more"),String::from("messages"),String::from("for"),String::from("you"),];for val in vals {tx.send(val).unwrap();thread::sleep(Duration::from_secs(1));}});for received in rx {println!("Got: {}", received);}
}
这一次,在创建新线程之前,我们对通道的发送端调用了 clone 方法。这会给我们一个可以传递给第一个新建线程的发送端句柄。我们会将原始的通道发送端传递给第二个新建线程。这样就会有两个线程,每个线程将向通道的接收端发送不同的消息。
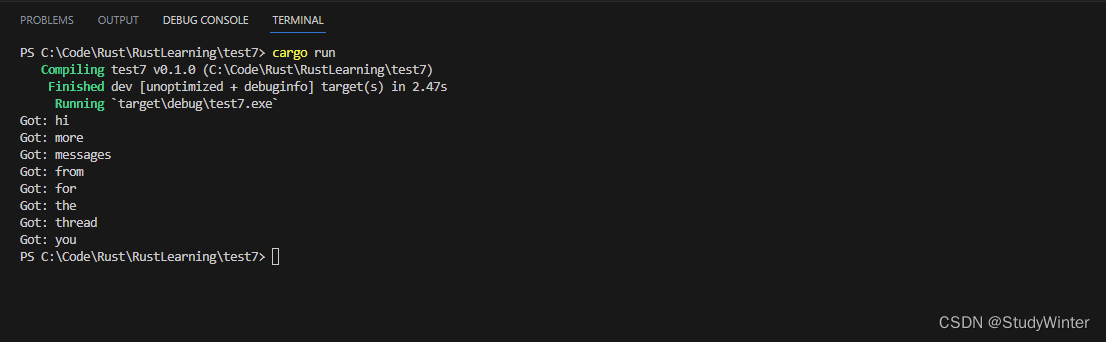
虽然你可能会看到这些值以不同的顺序出现;这依赖于你的系统。这也就是并发既有趣又困难的原因。如果通过 thread::sleep 做实验,在不同的线程中提供不同的值,就会发现他们的运行更加不确定,且每次都会产生不同的输出。
16.3 共享状态并发
虽然消息传递是一个很好的处理并发的方式,但并不是唯一一个。再一次思考一下 Go 编程语言文档中口号的这一部分:“不要通过共享内存来通讯”(“do not communicate by sharing memory.”):
在某种程度上,任何编程语言中的通道都类似于单所有权,因为一旦将一个值传送到通道中,将无法再使用这个值。共享内存类似于多所有权:多个线程可以同时访问相同的内存位置。第十五章介绍了智能指针如何使得多所有权成为可能,然而这会增加额外的复杂性,因为需要以某种方式管理这些不同的所有者。Rust 的类型系统和所有权规则极大的协助了正确地管理这些所有权。作为一个例子,让我们看看互斥器,一个更为常见的共享内存并发原语。
互斥器一次只允许一个线程访问数据
互斥器(mutex)是 mutual exclusion 的缩写,也就是说,任意时刻,其只允许一个线程访问某些数据。为了访问互斥器中的数据,线程首先需要通过获取互斥器的 锁(lock)来表明其希望访问数据。锁是一个作为互斥器一部分的数据结构,它记录谁有数据的排他访问权。因此,我们描述互斥器为通过锁系统 保护(guarding)其数据。
互斥器以难以使用著称,因为你不得不记住:
- 在使用数据之前尝试获取锁。
- 处理完被互斥器所保护的数据之后,必须解锁数据,这样其他线程才能够获取锁。
作为一个现实中互斥器的例子,想象一下在某个会议的一次小组座谈会中,只有一个麦克风。如果一位成员要发言,他必须请求或表示希望使用麦克风。一旦得到了麦克风,他可以畅所欲言,然后将麦克风交给下一位希望讲话的成员。如果一位成员结束发言后忘记将麦克风交还,其他人将无法发言。如果对共享麦克风的管理出现了问题,座谈会将无法如期进行!
正确的管理互斥器异常复杂,这也是许多人之所以热衷于通道的原因。然而,在 Rust 中,得益于类型系统和所有权,我们不会在锁和解锁上出错。
Mutex<T>的API
作为展示如何使用互斥器的例子,让我们从在单线程上下文使用互斥器开始
use std::sync::Mutex;fn main() {let m = Mutex::new(5);{let mut num = m.lock().unwrap();*num = 6;}println!("m = {:?}", m);
}
像很多类型一样,我们使用关联函数 new 来创建一个 Mutex<T>。使用 lock 方法获取锁,以访问互斥器中的数据。这个调用会阻塞当前线程,直到我们拥有锁为止。
如果另一个线程拥有锁,并且那个线程 panic 了,则 lock 调用会失败。在这种情况下,没人能够再获取锁,所以这里选择 unwrap 并在遇到这种情况时使线程 panic。
一旦获取了锁,就可以将返回值(在这里是num)视为一个其内部数据的可变引用了。类型系统确保了我们在使用 m 中的值之前获取锁:Mutex<i32> 并不是一个 i32,所以 必须 获取锁才能使用这个 i32 值。我们是不会忘记这么做的,因为反之类型系统不允许访问内部的 i32 值。
正如你所怀疑的,Mutex<T> 是一个智能指针。更准确的说,lock 调用 返回 一个叫做 MutexGuard 的智能指针。这个智能指针实现了 Deref 来指向其内部数据;其也提供了一个 Drop 实现当 MutexGuard 离开作用域时自动释放锁,这正发生于示例内部作用域的结尾。为此,我们不会冒忘记释放锁并阻塞互斥器为其它线程所用的风险,因为锁的释放是自动发生的。
丢弃了锁之后,可以打印出互斥器的值,并发现能够将其内部的 i32 改为 6。
在线程间共享 Mutex<T>
现在让我们尝试使用 Mutex<T> 在多个线程间共享值。我们将启动十个线程,并在各个线程中对同一个计数器值加一,这样计数器将从 0 变为 10。
use std::sync::Mutex;
use std::thread;fn main() {let counter = Mutex::new(0);let mut handles = vec![];for _ in 0..10 {let handle = thread::spawn(move || {let mut num = counter.lock().unwrap();*num += 1;});handles.push(handle);}for handle in handles {handle.join().unwrap();}println!("res: {}", *counter.lock().unwrap());
}
这里创建了一个 counter 变量来存放内含 i32 的 Mutex<T>,类似前面示例那样。接下来遍历 range 创建了 10 个线程。使用了 thread::spawn 并对所有线程使用了相同的闭包:他们每一个都将调用 lock 方法来获取 Mutex<T> 上的锁,接着将互斥器中的值加一。当一个线程结束执行,num 会离开闭包作用域并释放锁,这样另一个线程就可以获取它了。
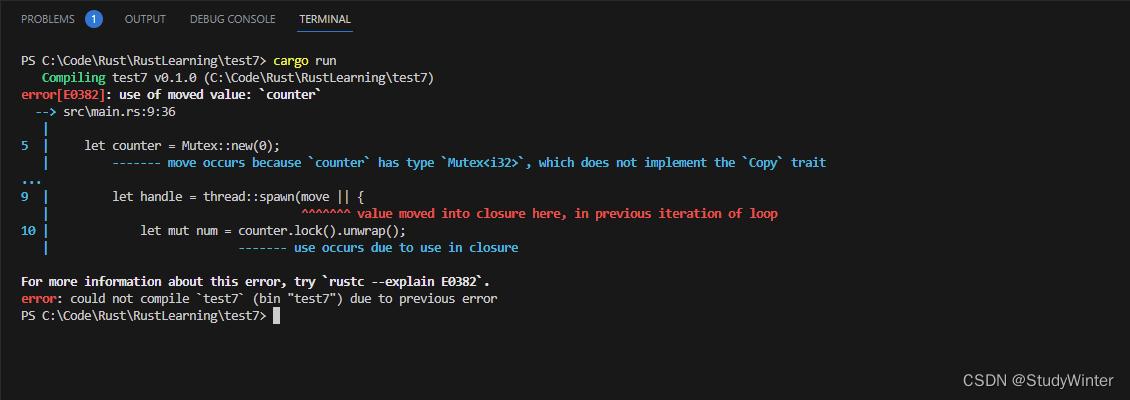
错误信息表明 counter 值在上一次循环中被移动了。所以 Rust 告诉我们不能将 counter 锁的所有权移动到多个线程中。让我们通过一个第十五章讨论过的多所有权手段来修复这个编译错误。
多线程和多所有权
在第十五章中,通过使用智能指针 Rc<T> 来创建引用计数的值,以便拥有多所有者。让我们在这也这么做看看会发生什么。将下面示例中的 Mutex<T> 封装进 Rc<T> 中并在将所有权移入线程之前克隆了 Rc<T>。现在我们理解了所发生的错误,同时也将代码改回使用 for 循环,并保留闭包的 move 关键字:
use std::rc::Rc;
use std::sync::Mutex;
use std::thread;fn main() {let counter = Rc::new(Mutex::new(0));let mut handles = vec![];for _ in 0..10 {let counter = Rc::clone(&counter);let handle = thread::spawn(move || {let mut num = counter.lock().unwrap();*num += 1;});handles.push(handle);}for handle in handles {handle.join().unwrap();}println!("Result: {}", *counter.lock().unwrap());
}
再一次编译并...出现了不同的错误!编译器真是教会了我们很多!
哇哦,错误信息太长不看!这里是一些需要注意的重要部分:第一行错误表明 `std::rc::Rc<std::sync::Mutex<i32>>` cannot be sent between threads safely。编译器也告诉了我们原因 the trait bound `Send` is not satisfied。下一部分会讲到 Send:这是确保所使用的类型可以用于并发环境的 trait 之一。
不幸的是,Rc<T> 并不能安全的在线程间共享。当 Rc<T> 管理引用计数时,它必须在每一个 clone 调用时增加计数,并在每一个克隆被丢弃时减少计数。Rc<T> 并没有使用任何并发原语,来确保改变计数的操作不会被其他线程打断。在计数出错时可能会导致诡异的 bug,比如可能会造成内存泄漏,或在使用结束之前就丢弃一个值。我们所需要的是一个完全类似 Rc<T>,又以一种线程安全的方式改变引用计数的类型。
原子引用计数Arc<T>
所幸 Arc<T> 正是 这么一个类似 Rc<T> 并可以安全的用于并发环境的类型。字母 “a” 代表 原子性(atomic),所以这是一个原子引用计数(atomically reference counted)类型。原子性是另一类这里还未涉及到的并发原语:请查看标准库中 std::sync::atomic 的文档来获取更多细节。其中的要点就是:原子性类型工作起来类似原始类型,不过可以安全的在线程间共享。
你可能会好奇为什么不是所有的原始类型都是原子性的?为什么不是所有标准库中的类型都默认使用 Arc<T> 实现?原因在于线程安全带有性能惩罚,我们希望只在必要时才为此买单。如果只是在单线程中对值进行操作,原子性提供的保证并无必要,代码可以因此运行的更快。
回到之前的例子:Arc<T> 和 Rc<T> 有着相同的 API,所以修改程序中的 use 行和 new 调用。
use std::sync::{Mutex, Arc};
use std::thread;fn main() {let counter = Arc::new(Mutex::new(0));let mut handles = vec![];for _ in 0..10 {let counter = Arc::clone(&counter);let handle = thread::spawn(move || {let mut num = counter.lock().unwrap();*num += 1;});handles.push(handle);}for handle in handles {handle.join().unwrap();}println!("Result: {}", *counter.lock().unwrap());
}
结果
 成功了!我们从 0 数到了 10,这可能并不是很显眼,不过一路上我们确实学习了很多关于
成功了!我们从 0 数到了 10,这可能并不是很显眼,不过一路上我们确实学习了很多关于 Mutex<T> 和线程安全的内容!这个例子中构建的结构可以用于比增加计数更为复杂的操作。使用这个策略,可将计算分成独立的部分,分散到多个线程中,接着使用 Mutex<T> 使用各自的结算结果更新最终的结果。
Refce11<T>/Rc<T>与Mutex<T>/Arc<T>的相似性
你可能注意到了,因为 counter 是不可变的,不过可以获取其内部值的可变引用;这意味着 Mutex<T> 提供了内部可变性,就像 Cell 系列类型那样。正如第十五章中使用 RefCell<T> 可以改变 Rc<T> 中的内容那样,同样的可以使用 Mutex<T> 来改变 Arc<T> 中的内容。
另一个值得注意的细节是 Rust 不能避免使用 Mutex<T> 的全部逻辑错误。回忆一下第十五章使用 Rc<T> 就有造成引用循环的风险,这时两个 Rc<T> 值相互引用,造成内存泄露。同理,Mutex<T> 也有造成 死锁(deadlock) 的风险。这发生于当一个操作需要锁住两个资源而两个线程各持一个锁,这会造成它们永远相互等待。如果你对这个主题感兴趣,尝试编写一个带有死锁的 Rust 程序,接着研究任何其他语言中使用互斥器的死锁规避策略并尝试在 Rust 中实现他们。标准库中 Mutex<T> 和 MutexGuard 的 API 文档会提供有用的信息。
16.4 使用Sync和Send trait 的可扩展并发
Rust 的并发模型中一个有趣的方面是:语言本身对并发知之 甚少。我们之前讨论的几乎所有内容,都属于标准库,而不是语言本身的内容。由于不需要语言提供并发相关的基础设施,并发方案不受标准库或语言所限:我们可以编写自己的或使用别人编写的并发功能。
然而有两个并发概念是内嵌于语言中的:std::marker 中的 Sync 和 Send trait。
通过send允许在线程间转移所有权
Send 标记 trait 表明类型的所有权可以在线程间传递。几乎所有的 Rust 类型都是Send 的,不过有一些例外,包括 Rc<T>:这是不能 Send 的,因为如果克隆了 Rc<T> 的值并尝试将克隆的所有权转移到另一个线程,这两个线程都可能同时更新引用计数。为此,Rc<T> 被实现为用于单线程场景,这时不需要为拥有线程安全的引用计数而付出性能代价。
因此,Rust 类型系统和 trait bound 确保永远也不会意外的将不安全的 Rc<T> 在线程间发送。当尝试在示例 16-14 中这么做的时候,会得到错误 the trait Send is not implemented for Rc<Mutex<i32>>。而使用标记为 Send 的 Arc<T> 时,就没有问题了。
任何完全由 Send 的类型组成的类型也会自动被标记为 Send。几乎所有基本类型都是 Send 的,除了第十九章将会讨论的裸指针(raw pointer)。
Sync允许多线程访问
Sync 标记 trait 表明一个实现了 Sync 的类型可以安全的在多个线程中拥有其值的引用。换一种方式来说,对于任意类型 T,如果 &T(T 的引用)是 Send 的话 T 就是 Sync 的,这意味着其引用就可以安全的发送到另一个线程。类似于 Send 的情况,基本类型是 Sync 的,完全由 Sync 的类型组成的类型也是 Sync 的。
智能指针 Rc<T> 也不是 Sync 的,出于其不是 Send 相同的原因。RefCell<T>(第十五章讨论过)和 Cell<T> 系列类型不是 Sync 的。RefCell<T> 在运行时所进行的借用检查也不是线程安全的。Mutex<T> 是 Sync 的,正如 “在线程间共享 Mutex<T>” 部分所讲的它可以被用来在多线程中共享访问。
手动实现send和sync是不安全的
通常并不需要手动实现 Send 和 Sync trait,因为由 Send 和 Sync 的类型组成的类型,自动就是 Send 和 Sync 的。因为他们是标记 trait,甚至都不需要实现任何方法。他们只是用来加强并发相关的不可变性的。
手动实现这些标记 trait 涉及到编写不安全的 Rust 代码,第十九章将会讲述具体的方法;当前重要的是,在创建新的由不是 Send 和 Sync 的部分构成的并发类型时需要多加小心,以确保维持其安全保证。The Rustonomicon 中有更多关于这些保证以及如何维持他们的信息。
参考:无畏并发 - Rust 程序设计语言 简体中文版 (bootcss.com)