复合数据类型
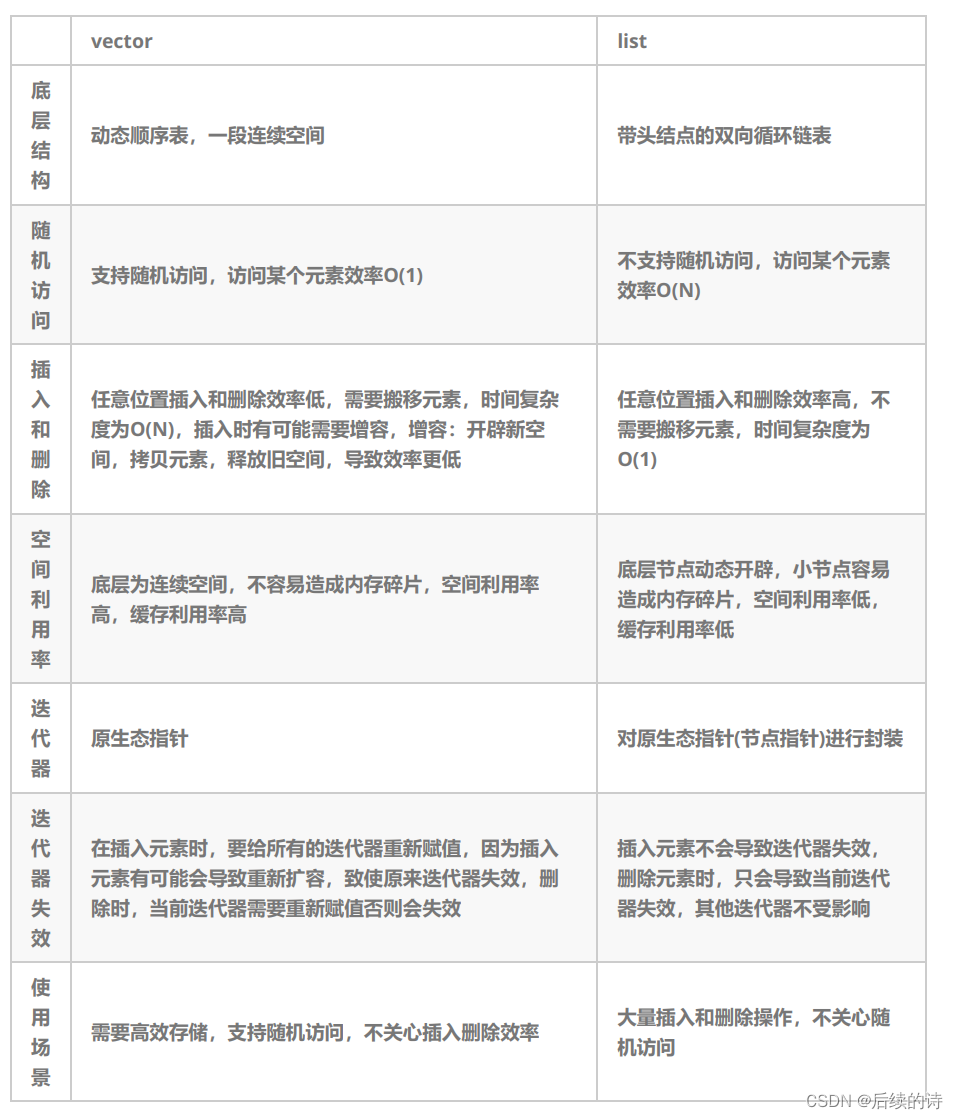
同构复合类型:从定长数组到变长切片
- 由多个同构类型(相同类型)或异构类型(不同类型)的元素的值组合而成,这类数据类型在 Go 语言中被称为复合类型。
数组有哪些基本特性?
- Go 语言的数组是一个长度固定的、由同构类型元素组成的连续序列。
- 通过这个定义,我们可以识别出 Go 的数组类型包含两个重要属性:元素的类型和数组长度(元素的个数):
var arr [N]T。 - 这里我们声明了一个数组变量 arr,它的类型为[N]T,其中元素的类型为 T,数组的长度为 N。
- 数组元素的类型可以为任意的 Go 原生类型或自定义类型,而且数组的长度必须在声明数组变量时提供,Go 编译器需要在编译阶段就知道数组类型的长度,所以,我们只能用整型数字面值或常量表达式作为 N 值。
- 数组元素的类型可以为任意的 Go 原生类型或自定义类型,而且数组的长度必须在声明数组变量时提供,Go 编译器需要在编译阶段就知道数组类型的长度,所以,我们只能用整型数字面值或常量表达式作为 N 值。
- 如果两个数组类型的元素类型 T 与数组长度 N 都是一样的,那么这两个数组类型是等价的,如果有一个属性不同,它们就是两个不同的数组类型。
- 通过这个定义,我们可以识别出 Go 的数组类型包含两个重要属性:元素的类型和数组长度(元素的个数):
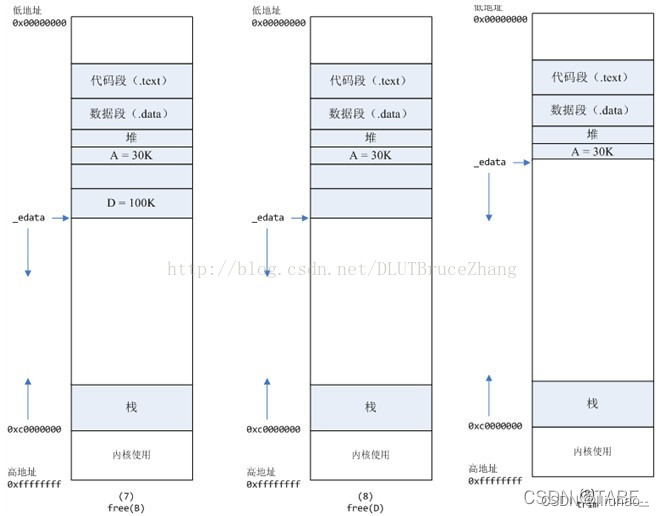
- 数组类型不仅是逻辑上的连续序列,而且在实际内存分配时也占据着一整块内存。
- Go 编译器在为数组类型的变量实际分配内存时,会为 Go 数组分配一整块、可以容纳它所有元素的连续内存。
- Go 提供了预定义函数 len 可以用于获取一个数组类型变量的长度,通过 unsafe 包提供的 Sizeof 函数,我们可以获得一个数组变量的总大小:
var arr = [6]int{1, 2, 3, 4, 5, 6} fmt.Println("数组长度:", len(arr)) // 6 fmt.Println("数组大小:", unsafe.Sizeof(arr)) // 48
- 和基本数据类型一样,我们声明一个数组类型变量的同时,也可以显式地对它进行初始化。
- 如果不进行显式初始化,那么数组中的元素值就是它类型的零值。
- 如果要显式地对数组初始化,我们需要在右值中显式放置数组类型,并通过大括号的方式给各个元素赋值。
- 当然,我们也可以忽略掉右值初始化表达式中数组类型的长度,用“…”替代,Go 编译器会根据数组元素的个数,自动计算出数组长度。
- 如果我们要对一个长度较大的稀疏数组进行显式初始化,这样逐一赋值就太麻烦了,我们可以通过使用下标赋值的方式对它进行初始化:
var arr4 = [...]int{99: 39, // 将第100个元素(下标值为99)的值赋值为39,其余元素值均为0 } fmt.Printf("%T\n", arr4) // [100]int - 如果下标值超出数组长度范畴,或者是负数,那么 Go 编译器会给出错误提示,防止访问溢出。
- 多维数组
- 数组类型自身也可以作为数组元素的类型,这样就会产生多维数组:
var mArr [2][3][4]int。 - 数组类型变量是一个整体,这就意味着一个数组变量表示的是整个数组。这样一来,无论是参与迭代,还是作为实际参数传给一个函数 / 方法,Go 传递数组的方式都是纯粹的值拷贝,这会带来较大的内存拷贝开销。
- Go 语言为我们提供了一种更为灵活、更为地道的方式 ,切片,来解决这个问题。
- 数组类型自身也可以作为数组元素的类型,这样就会产生多维数组:
切片是怎么一回事?
- 数组作为最基本同构类型在 Go 语言中被保留了下来,但数组在使用上确有两点不足:固定的元素个数,以及传值机制下导致的开销较大。于是 Go 设计者们又引入了另外一种同构复合类型:切片(slice),来弥补数组的这两处不足。
- 与数组声明相比,切片声明仅仅是少了一个“长度”属性。
- 虽然不需要像数组那样在声明时指定长度,但切片也有自己的长度,只不过这个长度不是固定的,而是随着切片中元素个数的变化而变化的。我们可以通过 len 函数获得切片类型变量的长度。
- 通过 Go 内置函数 append,我们可以动态地向切片中添加元素。
- Go 切片在运行时其实是一个三元组结构,它在 Go 运行时中的表示如下:
type slice struct {array unsafe.Pointerlen intcap int }- array: 是指向底层数组的指针;
- len: 是切片的长度,即切片中当前元素的个数;
- cap: 是底层数组的长度,也是切片的最大容量,cap 值永远大于等于 len 值。
- Go 编译器会自动为每个新创建的切片,建立一个底层数组,默认底层数组的长度与切片初始元素个数相同。
- 我们可以用以下几种方法创建切片,并指定它底层数组的长度:
- 方法一:通过 make 函数来创建切片,并指定底层数组的长度:
sl := make([]byte, 6, 10) // 其中10为cap值,即底层数组长度,6为切片的初始长度。- 如果没有在 make 中指定 cap 参数,那么底层数组长度 cap 就等于 len,比如:
sl := make([]byte, 6) // cap = len = 6。
- 方法二:采用 array[low : high : max] 语法基于一个已存在的数组创建切片。
- 这种方式被称为数组的切片化:
arr := [10]int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10} sl := arr[3:7:9] - 基于数组创建的切片,它的起始元素从 low 所标识的下标值开始,切片的长度(len)是 high - low,它的容量是 max - low。
- 而且,由于切片 sl 的底层数组就是数组 arr,对切片 sl 中元素的修改将直接影响数组 arr 变量。
- 切片好比打开了一个访问与修改数组的“窗口”,通过这个窗口,我们可以直接操作底层数组中的部分元素。
- 我们在进行数组切片化的时候,通常省略 max,而 max 的默认值为数组的长度。
- 这种方式被称为数组的切片化:
- 方法三:基于切片创建切片。
- 这种切片的运行时表示原理与上面的是一样的。
- 切片与数组最大的不同,就在于其长度的不定长,这种不定长需要 Go 运行时提供支持,这种支持就是切片的“动态扩容”。
- 方法一:通过 make 函数来创建切片,并指定底层数组的长度:
- 切片的动态扩容
- “动态扩容”指的就是,当我们通过 append 操作向切片追加数据的时候,如果这时切片的 len 值和 cap 值是相等的,也就是说切片底层数组已经没有空闲空间再来存储追加的值了,Go 运行时就会对这个切片做扩容操作,来保证切片始终能存储下追加的新值。
- append 会根据切片的需要,在当前底层数组容量无法满足的情况下,动态分配新的数组,新数组长度会按一定规律扩展。针对元素是 int 型的数组,新数组的容量是当前数组的 2 倍。新数组建立后,append 会把旧数组中的数据拷贝到新数组中,之后新数组便成为了切片的底层数组,旧数组会被垃圾回收掉。
- 基于一个已有数组建立的切片,一旦追加的数据操作触碰到切片的容量上限(实质上也是数组容量的上界),切片就会和原数组解除“绑定”,后续对切片的任何修改都不会反映到原数组中了。
原生 map 类型的实现机制是怎样的?
什么是 map 类型?
- map 是 Go 语言提供的一种抽象数据类型,它表示一组无序的键值对。
- 我们会直接使用 key 和 value 分别代表 map 的键和值。而且,map 集合中每个 key 都是唯一的。
- 和切片类似,作为复合类型的 map,它在 Go 中的类型表示也是由 key 类型与 value 类型组成的:
map[key_type]value_type。 - key 与 value 的类型可以相同,也可以不同。
- 如果两个 map 类型的 key 元素类型相同,value 元素类型也相同,那么我们可以说它们是同一个 map 类型,否则就是不同的 map 类型。
- Go 语言中要求,key 的类型必须支持“==”和“!=”两种比较操作符。
- 在 Go 语言中,函数类型、map 类型自身,以及切片只支持与 nil 的比较,而不支持同类型两个变量的比较。函数类型、map 类型自身,以及切片类型是不能作为 map 的 key 类型的。
map 变量的声明和初始化
- 我们可以这样声明一个 map 变量:
var m map[string]int // 一个map[string]int类型的变量。 - 和切片类型变量一样,如果我们没有显式地赋予 map 变量初值,map 类型变量的默认值为 nil。
- 初值为零值 nil 的切片类型变量,可以借助内置的 append 的函数进行操作,这种在 Go 语言中被称为“零值可用”。
- map 类型,因为它内部实现的复杂性,无法“零值可用”。所以,如果我们对处于零值状态的 map 变量直接进行操作,就会导致运行时异常(panic),从而导致程序进程异常退出。所以,我们必须对 map 类型变量进行显式初始化后才能使用。
- 和切片一样,为 map 类型变量显式赋值有两种方式:一种是使用复合字面值;另外一种是使用 make 这个预声明的内置函数。
- 使用复合字面值初始化 map 类型变量:
m := map[int]string{}。m2 := map[Position]string{{29.935523, 52.568915}: "school",{25.352594, 113.304361}: "shopping-mall",{73.224455, 111.804306}: "hospital", } - 使用 make 为 map 类型变量进行显式初始化,通过 make 的初始化方式,我们可以为 map 类型变量指定键值对的初始容量,但无法进行具体的键值对赋值。
- 使用复合字面值初始化 map 类型变量:
map 的基本操作
-
针对一个 map 类型变量,我们可以进行诸如插入新键值对、获取当前键值对数量、查找特定键和读取对应值、删除键值对,以及遍历键值等操作。
- 操作一:插入新键值对
- 面对一个非 nil 的 map 类型变量,插入新键值对的方式很简单,我们只需要把 value 赋值给 map 中对应的 key 就可以了:
m := make(map[int]string) m[1] = "value1" m[2] = "value2" m[3] = "value3" - 我们不需要自己判断数据有没有插入成功,因为 Go 会保证插入总是成功的。
- Go 运行时会负责 map 变量内部的内存管理,因此除非是系统内存耗尽,我们可以不用担心向 map 中插入新数据的数量和执行结果。
- 如果我们插入新键值对的时候,某个 key 已经存在于 map 中了,那我们的插入操作就会用新值覆盖旧值。
- 面对一个非 nil 的 map 类型变量,插入新键值对的方式很简单,我们只需要把 value 赋值给 map 中对应的 key 就可以了:
- 操作二:获取键值对数量。
- 如果我们在编码中,想知道当前 map 类型变量中已经建立了多少个键值对,和切片一样,map 类型也可以通过内置函数 len,获取当前变量已经存储的键值对数量。
- 我们不能对 map 类型变量调用 cap,来获取当前容量,这是 map 类型与切片类型的一个不同点。
- 操作三:查找和数据读取
- Go 语言的 map 类型支持通过用一种名为“comma ok”的惯用法,进行对某个 key 的查询。
m := make(map[string]int) v, ok := m["key1"] if !ok { // "key1"不在map中 } / / "key1"在map中,v将被赋予"key1"键对应的value - 如果我们并不关心某个键对应的 value,而只关心某个键是否在于 map 中,我们可以使用空标识符替代变量 v,忽略可能返回的 value:
m := make(map[string]int) _, ok := m["key1"] ... ... - 在 Go 语言中,请使用“comma ok”惯用法对 map 进行键查找和键值读取操作。
- Go 语言的 map 类型支持通过用一种名为“comma ok”的惯用法,进行对某个 key 的查询。
- 操作四:删除数据
- 在 Go 中,我们需要借助内置函数 delete 来从 map 中删除数据。使用 delete 函数的情况下,传入的第一个参数是我们的 map 类型变量,第二个参数就是我们想要删除的键。
m := map[string]int {"key1" : 1,"key2" : 2, } fmt.Println(m) // map[key1:1 key2:2] delete(m, "key2") // 删除"key2" fmt.Println(m) // map[key1:1] - delete 函数是从 map 中删除键的唯一方法。
- 即便传给 delete 的键在 map 中并不存在,delete 函数的执行也不会失败,更不会抛出运行时的异常。
- 在 Go 中,我们需要借助内置函数 delete 来从 map 中删除数据。使用 delete 函数的情况下,传入的第一个参数是我们的 map 类型变量,第二个参数就是我们想要删除的键。
- 操作五:遍历 map 中的键值数据
- 在 Go 中,遍历 map 的键值对只有一种方法,那就是像对待切片那样通过 for range 语句对 map 数据进行遍历。
func main() {m := map[int]int{1: 11,2: 12,3: 13,} fmt.Printf("{ ")for k, v := range m {fmt.Printf("[%d, %d] ", k, v)}fmt.Printf("}\n") } - 对同一 map 做多次遍历的时候,每次遍历元素的次序都不相同。
- 程序逻辑千万不要依赖遍历 map 所得到的的元素次序。
- 在 Go 中,遍历 map 的键值对只有一种方法,那就是像对待切片那样通过 for range 语句对 map 数据进行遍历。
- 操作一:插入新键值对
-
和切片类型一样,map 也是引用类型。这就意味着 map 类型变量作为参数被传递给函数或方法的时候,实质上传递的只是一个“描述符”,而不是整个 map 的数据拷贝,所以这个传递的开销是固定的,而且也很小。
-
当 map 变量被传递到函数或方法内部后,我们在函数内部对 map 类型参数的修改在函数外部也是可见的。
package main import "fmt" func foo(m map[string]int) {m["key1"] = 11m["key2"] = 12 } func main() {m := map[string]int{"key1": 1,"key2": 2,fmt.Println(m) // map[key1:1 key2:2]foo(m)fmt.Println(m) // map[key1:11 key2:12] }
map 的内部实现
- Go 运行时使用一张哈希表来实现抽象的 map 类型。运行时实现了 map 类型操作的所有功能,包括查找、插入、删除等。在编译阶段,Go 编译器会将 Go 语法层面的 map 操作,重写成运行时对应的函数调用。
- map 类型在 Go 运行时层实现的示意图:
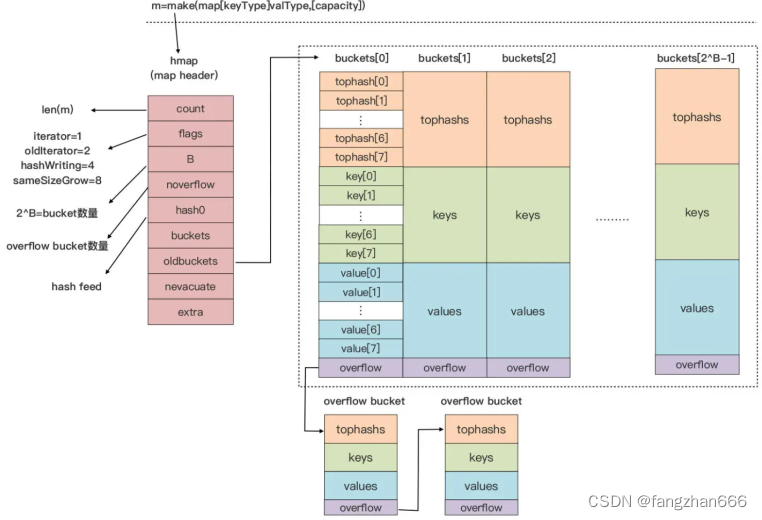
- 初始状态
- 与语法层面 map 类型变量(m)一一对应的是 runtime.hmap 的实例。
- hmap 类型是 map 类型的头部结构(header),也就是 map 类型的描述符,它存储了后续 map 类型操作所需的所有信息:
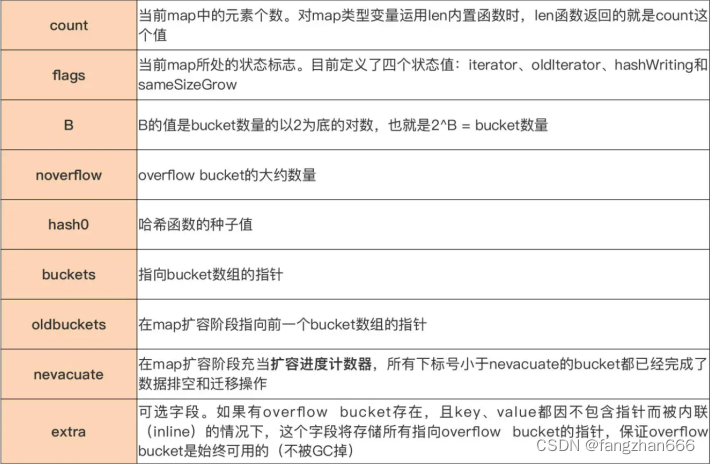
- 真正用来存储键值对数据的是桶,也就是 bucket,每个 bucket 中存储的是 Hash 值低 bit 位数值相同的元素,默认的元素个数为 BUCKETSIZE(默认值为 8)。
- 当某个 bucket 都填满了,且 map 尚未达到扩容的条件的情况下,运行时会建立 overflow bucket,并将这个 overflow bucket 挂在上面 bucket 末尾的 overflow 指针上,这样两个 buckets 形成了一个链表结构,直到下一次 map 扩容之前,这个结构都会一直存在。
- 每个 bucket 由三部分组成,从上到下分别是 tophash 区域、key 存储区域和 value 存储区域。
- tophash 区域
- 当我们向 map 插入一条数据,或者是从 map 按 key 查询数据的时候,运行时都会使用哈希函数对 key 做哈希运算,并获得一个哈希值(hashcode)。
- 这个 hashcode 非常关键,运行时会把 hashcode“一分为二”来看待,其中低位区的值用于选定 bucket,高位区的值用于在某个 bucket 中确定 key 的位置。
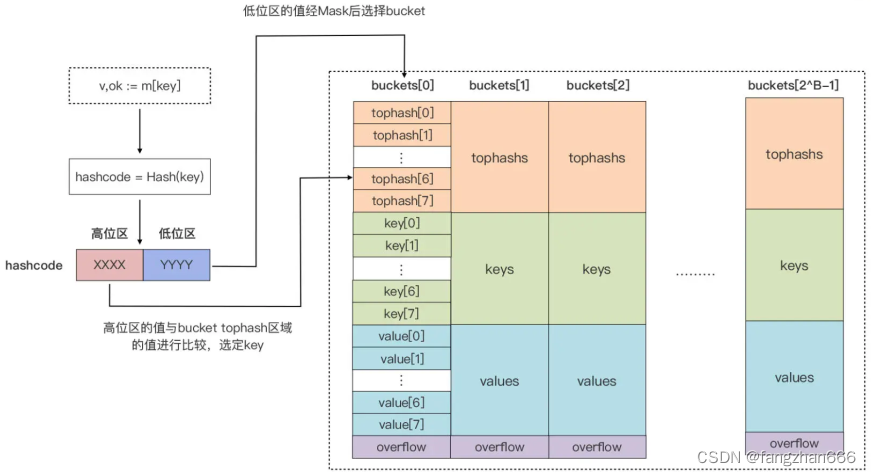
- 每个 bucket 的 tophash 区域其实是用来快速定位 key 位置的,这样就避免了逐个 key 进行比较这种代价较大的操作。尤其是当 key 是 size 较大的字符串类型时,好处就更突出了。这是一种以空间换时间的思路。
- key 存储区域
- tophash 区域下面是一块连续的内存区域,存储的是这个 bucket 承载的所有 key 数据。
- 运行时在分配 bucket 的时候需要知道 key 的 Size。
- 当我们声明一个 map 类型变量,比如 var m map[string]int 时,Go 运行时就会为这个变量对应的特定 map 类型,生成一个 runtime.maptype 实例。如果这个实例已经存在,就会直接复用。
type maptype struct {typ _typekey *_typeelem *_typebucket *_type // internal type representing a hash bucketkeysize uint8 // size of key slotelemsize uint8 // size of elem slotbucketsize uint16 // size of bucketflags uint32 } - 这个实例包含了我们需要的 map 类型中的所有"元信息"。编译器会把语法层面的 map 操作重写成运行时对应的函数调用,这些运行时函数都有一个共同的特点,那就是第一个参数都是 maptype 指针类型的参数。
- Go 运行时就是利用 maptype 参数中的信息确定 key 的类型和大小的。
- map 所用的 hash 函数也存放在 maptype.key.alg.hash(key, hmap.hash0) 中。
- 同时 maptype 的存在也让 Go 中所有 map 类型都共享一套运行时 map 操作函数,而不是像 C++ 那样为每种 map 类型创建一套 map 操作函数,这样就节省了对最终二进制文件空间的占用。
- value 存储区域
- key 存储区域下方的另外一块连续的内存区域存储的是 key 对应的 value。
- 和 key 一样,这个区域的创建也是得到了 maptype 中信息的帮助。
- Go 运行时采用了把 key 和 value 分开存储的方式,而不是采用一个 kv 接着一个 kv 的 kv 紧邻方式存储,这带来的其实是算法上的复杂性,但却减少了因内存对齐带来的内存浪费。
- 如果 key 或 value 的数据长度大于一定数值,那么运行时不会在 bucket 中直接存储数据,而是会存储 key 或 value 数据的指针。
- tophash 区域
- map 扩容
- Go 运行时的 map 实现中引入了一个 LoadFactor(负载因子),当 count > LoadFactor * 2^B 或 overflow bucket 过多时,运行时会自动对 map 进行扩容。
- 如果是因为 overflow bucket 过多导致的“扩容”,实际上运行时会新建一个和现有规模一样的 bucket 数组,然后在 assign 和 delete 时做排空和迁移。
- 如果是因为当前数据数量超出 LoadFactor 指定水位而进行的扩容,那么运行时会建立一个两倍于现有规模的 bucket 数组,但真正的排空和迁移工作也是在 assign 和 delete 时逐步进行的。原 bucket 数组会挂在 hmap 的 oldbuckets 指针下面,直到原 buckets 数组中所有数据都迁移到新数组后,原 buckets 数组才会被释放。
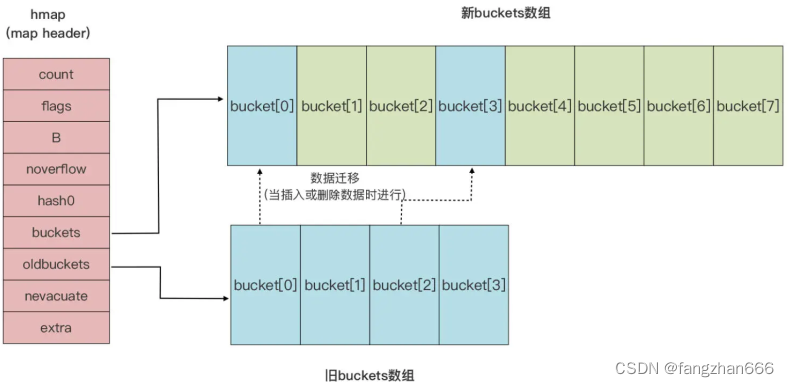
- map 与并发
- 充当 map 描述符角色的 hmap 实例自身是有状态的(hmap.flags),而且对状态的读写是没有并发保护的,所以说 map 实例不是并发写安全的,也不支持并发读写。
- 如果我们对 map 实例进行并发读写,程序运行时就会抛出异常。
- 不过,如果我们仅仅是进行并发读,map 是没有问题的。
- Go 1.9 版本中引入了支持并发写安全的 sync.Map 类型,可以用来在并发读写的场景下替换掉 map。
- 考虑到 map 可以自动扩容,map 中数据元素的 value 位置可能在这一过程中发生变化,所以 Go 不允许获取 map 中 value 的地址,这个约束是在编译期间就生效的。
- 初始状态
结构体
如何自定义一个新类型?
- 在 Go 中,提供聚合抽象能力的类型是结构体类型,也就是 struct。
- 在 Go 中,我们自定义一个新类型一般有两种方法。
- 第一种是类型定义(Type Definition),这也是我们最常用的类型定义方法。
- 在这种方法中,我们会使用关键字 type 来定义一个新类型 T,具体形式是这样的:
type T S // 定义一个新类型 T。 - 在这里,S 可以是任何一个已定义的类型,包括 Go 原生类型,或者是其他已定义的自定义类型。
- 如果一个新类型是基于某个 Go 原生类型定义的,那么我们就叫 Go 原生类型为新类型的底层类型(Underlying Type)。
- 底层类型在 Go 语言中有重要作用,它被用来判断两个类型本质上是否相同(Identical)。
- 本质上相同的两个类型,它们的变量可以通过显式转型进行相互赋值,相反,如果本质上是不同的两个类型,它们的变量间连显式转型都不可能,更不要说相互赋值了。
- 除了基于已有类型定义新类型之外,我们还可以基于类型字面值来定义新类型,这种方式多用于自定义一个新的复合类型:
type M map[int]string。 - 和变量声明支持使用 var 块的方式类似,类型定义也支持通过 type 块的方式进行。
- 在这种方法中,我们会使用关键字 type 来定义一个新类型 T,具体形式是这样的:
- 第二种自定义新类型的方式是使用类型别名(Type Alias),这种类型定义方式通常用在项目的渐进式重构,还有对已有包的二次封装方面。
- 它的形式是这样的:
type T = S // type alias。 - 与前面的第一种类型定义相比,类型别名的形式只是多了一个等号,但正是这个等号让新类型 T 与原类型 S 完全等价。
- 完全等价的意思就是,类型别名并没有定义出新类型,类 T 与 S 实际上就是同一种类型,它们只是一种类型的两个名字罢了。
- 它的形式是这样的:
- 第一种是类型定义(Type Definition),这也是我们最常用的类型定义方法。
如何定义一个结构体类型?
- 复合类型的定义一般都是通过类型字面值的方式来进行的,作为复合类型之一的结构体类型也不例外:
type T struct {Field1 T1Field2 T2... ...FieldN Tn }- 如果结构体类型只在它定义的包内使用,那么我们可以将类型名的首字母小写;
- 如果你不想将结构体类型中的某个字段暴露给其他包,那么我们同样可以把这个字段名字的首字母小写。
- 我们还可以用空标识符“_”作为结构体类型定义中的字段名称。这样以空标识符为名称的字段,不能被外部包引用,甚至无法被结构体所在的包使用。
- 定义一个空结构体
- 我们可以定义一个空结构体,也就是没有包含任何字段的结构体类型:
type Empty struct{} // Empty是一个不包含任何字段的空结构体类型。 - 基于空结构体类型内存零开销这样的特性,我们在日常 Go 开发中会经常使用空结构体类型元素,作为一种“事件”信息进行 Goroutine 之间的通信。
- 这种以空结构体为元素类建立的 channel,是目前能实现的、内存占用最小的 Goroutine 间通信方式。
- 我们可以定义一个空结构体,也就是没有包含任何字段的结构体类型:
- 使用其他结构体作为自定义结构体中字段的类型
- 对于包含结构体类型字段的结构体类型来说,我们可以无需提供字段的名字,只需要使用其类型就可以了。
type Book struct {Title stringPerson // 结构体... ... } - 以这种方式定义的结构体字段,我们叫做嵌入字段(Embedded Field)。我们也可以将这种字段称为匿名字段,或者把类型名看作是这个字段的名字。
var book Book println(book.Person.Phone) // 将类型名当作嵌入字段的名字 println(book.Phone) // 支持直接访问嵌入字段所属类型中字段
- 对于包含结构体类型字段的结构体类型来说,我们可以无需提供字段的名字,只需要使用其类型就可以了。
- Go 语言不支持在结构体类型定义中,递归地放入其自身类型字段的定义方式。
- 虽然我们不能在结构体类型 T 定义中,拥有以自身类型 T 定义的字段,但我们却可以拥有自身类型的指针类型、以自身类型为元素类型的切片类型,以及以自身类型作为 value 类型的 map 类型的字段:
type T struct {t *T // okst []T // okm map[string]T // ok }
结构体变量的声明与初始化
- 和其他所有变量的声明一样,我们也可以使用标准变量声明语句,或者是短变量声明语句声明一个结构体类型的变量。
- 结构体类型的变量通常都要被赋予适当的初始值后,才会有合理的意义。
- 结构体类型变量的初始化
- 零值初始化
- 零值初始化说的是使用结构体的零值作为它的初始值。
- Go 结构体类型由若干个字段组成,当这个结构体类型变量的各个字段的值都是零值时,我们就说这个结构体类型变量处于零值状态。
- 使用复合字面值
- 最简单的对结构体变量进行显式初始化的方式,就是按顺序依次给每个结构体字段进行赋值。
type Book struct {Title string // 书名Pages int // 书的页数Indexes map[string]int // 书的索引 } var book = Book{"The Go Programming Language", 700, make(map[string]int)} - Go 语言并不推荐我们按字段顺序对一个结构体类型变量进行显式初始化,甚至 Go 官方还在提供的 go vet 工具中专门内置了一条检查规则:“composites”,用来静态检查代码中结构体变量初始化是否使用了这种方法,一旦发现,就会给出警告。
- Go 推荐我们用“field:value”形式的复合字面值,对结构体类型变量进行显式初始化,这种方式可以降低结构体类型使用者和结构体类型设计者之间的耦合,这也是 Go 语言的惯用法。
var t = T{F2: "hello",F1: 11,F4: 14, } - 使用这种“field:value”形式的复合字面值对结构体类型变量进行初始化,非常灵活。和之前的顺序复合字面值形式相比,“field:value”形式字面值中的字段可以以任意次序出现。
- 最简单的对结构体变量进行显式初始化的方式,就是按顺序依次给每个结构体字段进行赋值。
- 零值初始化
使用特定的构造函数
- 使用特定的构造函数创建并初始化结构体变量的例子,并不罕见。
func NewT(field1, field2, ...) *T {... ... }- NewT 是结构体类型 T 的专用构造函数,它的参数列表中的参数通常与 T 定义中的导出字段相对应,返回值则是一个 T 指针类型的变量。
- T 的非导出字段在 NewT 内部进行初始化,一些需要复杂初始化逻辑的字段也会在 NewT 内部完成初始化。
- 这样,我们只要调用 NewT 函数就可以得到一个可用的 T 指针类型变量了。
结构体类型的内存布局
- Go 结构体类型是既数组类型之后,第二个将它的元素(结构体字段)一个接着一个以“平铺”形式,存放在一个连续内存块中的。
- 结构体类型 T 在内存中布局是非常紧凑的,Go 为它分配的内存都用来存储字段了,没有被 Go 编译器插入的额外字段。
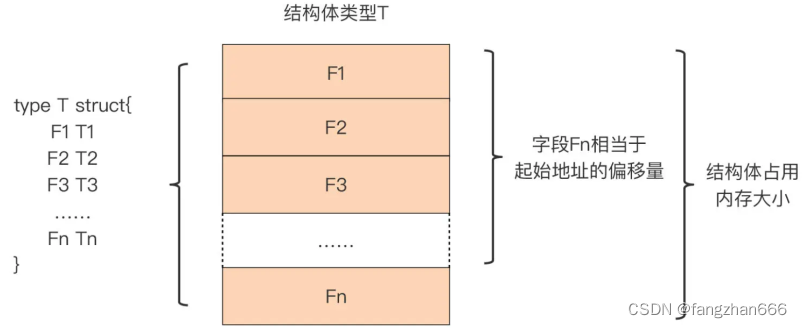
- 我们可以借助标准库 unsafe 包提供的函数,获得结构体类型变量占用的内存大小,以及它每个字段在内存中相对于结构体变量起始地址的偏移量。
- 结构体类型 T 在内存中布局是非常紧凑的,Go 为它分配的内存都用来存储字段了,没有被 Go 编译器插入的额外字段。
- 在真实情况下,虽然 Go 编译器没有在结构体变量占用的内存空间中插入额外字段,但结构体字段实际上可能并不是紧密相连的,中间可能存在“缝隙”。
- 这些“缝隙”同样是结构体变量占用的内存空间的一部分,它们是 Go 编译器插入的“填充物(Padding)”。
- 那么,Go 编译器为什么要在结构体的字段间插入“填充物”呢?
- 这其实是内存对齐的要求。
- 所谓内存对齐,指的就是各种内存对象的内存地址不是随意确定的,必须满足特定要求。
- 对于各种基本数据类型来说,它的变量的内存地址值必须是其类型本身大小的整数倍。
- 对于结构体而言,它的变量的内存地址,只要是它最长字段长度与系统对齐系数两者之间较小的那个的整数倍就可以了。但对于结构体类型来说,我们还要让它每个字段的内存地址都严格满足内存对齐要求。
- 在日常定义结构体时,一定要注意结构体中字段顺序,尽量合理排序,降低结构体对内存空间的占用。