Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例
14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性
15、Flink 的table api与sql之流式概念-详解的介绍了动态表、时间属性配置(如何处理更新结果)、时态表、流上的join、流上的确定性以及查询配置
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及FileSystem示例(1)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Elasticsearch示例(2)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Apache Kafka示例(3)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及JDBC示例(4)
20、Flink SQL之SQL Client: 不用编写代码就可以尝试 Flink SQL,可以直接提交 SQL 任务到集群上
22、Flink 的table api与sql之创建表的DDL
30、Flink SQL之SQL 客户端(通过kafka和filesystem的例子介绍了配置文件使用-表、视图等)
文章目录
- Flink 系列文章
- 一、Table & SQL Connectors 示例:Elasticsearch
- 1、maven依赖(java编码依赖)
- 2、创建 Elasticsearch 表并写入数据
- 3、连接器参数
- 4、特性
- 1)、Key 处理
- 2)、动态索引
- 5、数据类型映射
- 二、Flink SQL示例:将kafka数据写入es
- 1、依赖环境
- 2、创建表并提交任务
- 3、验证
- 1)、创建es表
- 2)、创建kafka表
- 3)、提交任务
- 4)、创建kafkatopic
- 5)、往kafka topic中写入数据
- 6)、查看es中的数据
本文介绍了Elasticsearch连接器的使用,并以2个示例完成了外部系统是Elasticsearch的介绍,即使用datagen作为数据源写入Elasticsearch和kafka作为数据源写入Elasticsearch中。
本文依赖环境是Flink、kafka、Elasticsearch、hadoop环境好用,如果是ha环境则需要zookeeper的环境。
本文分为2个部分,即Elasticsearch的基本介绍及示例和Elasticsearch与kafka的使用示例。
一、Table & SQL Connectors 示例:Elasticsearch
Elasticsearch 连接器允许将数据写入到 Elasticsearch 引擎的索引中(不支持读取,截至1.17版本)。本文档描述运行 SQL 查询时如何设置 Elasticsearch 连接器。
连接器可以工作在 upsert 模式,使用 DDL 中定义的主键与外部系统交换 UPDATE/DELETE 消息。
如果 DDL 中没有定义主键,那么连接器只能工作在 append 模式,只能与外部系统交换 INSERT 消息。
1、maven依赖(java编码依赖)
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-elasticsearch7</artifactId><version>3.0.1-1.17</version>
</dependency>
2、创建 Elasticsearch 表并写入数据
本示例的Elasticsearch是7.6,故需要Elasticsearch7的jar文件
flink-sql-connector-elasticsearch7_2.11-1.13.6.jar
CREATE TABLE source_table (userId INT,age INT,balance DOUBLE,userName STRING,t_insert_time AS localtimestamp,WATERMARK FOR t_insert_time AS t_insert_time
) WITH ('connector' = 'datagen','rows-per-second'='5','fields.userId.kind'='sequence','fields.userId.start'='1','fields.userId.end'='5000','fields.balance.kind'='random','fields.balance.min'='1','fields.balance.max'='100','fields.age.min'='1','fields.age.max'='1000','fields.userName.length'='10'
);CREATE TABLE alan_flink_es_user_idx (userId INT,age INT,balance DOUBLE,userName STRING,t_insert_time AS localtimestamp,PRIMARY KEY (userId) NOT ENFORCED
) WITH ('connector' = 'elasticsearch-7','hosts' = 'http://192.168.10.41:9200,http://192.168.10.42:9200,http://192.168.10.43:9200','index' = 'alan_flink_es_user_idx'
);INSERT INTO alan_flink_es_user_idx
SELECT userId, age, balance , userName FROM source_table;---------------------具体操作如下-----------------------------------
Flink SQL> CREATE TABLE source_table (
> userId INT,
> age INT,
> balance DOUBLE,
> userName STRING,
> t_insert_time AS localtimestamp,
> WATERMARK FOR t_insert_time AS t_insert_time
> ) WITH (
> 'connector' = 'datagen',
> 'rows-per-second'='5',
> 'fields.userId.kind'='sequence',
> 'fields.userId.start'='1',
> 'fields.userId.end'='5000',
>
> 'fields.balance.kind'='random',
> 'fields.balance.min'='1',
> 'fields.balance.max'='100',
>
> 'fields.age.min'='1',
> 'fields.age.max'='1000',
>
> 'fields.userName.length'='10'
> );
[INFO] Execute statement succeed.Flink SQL>
>
> CREATE TABLE alan_flink_es_user_idx (
> userId INT,
> age INT,
> balance DOUBLE,
> userName STRING,
> t_insert_time AS localtimestamp,
> PRIMARY KEY (userId) NOT ENFORCED
> ) WITH (
> 'connector' = 'elasticsearch-7',
> 'hosts' = 'http://192.168.10.41:9200,http://192.168.10.42:9200,http://192.168.10.43:9200',
> 'index' = 'alan_flink_es_user_idx'
> );
[INFO] Execute statement succeed.Flink SQL>
>
> INSERT INTO alan_flink_es_user_idx
> SELECT userId, age, balance , userName FROM source_table;
[INFO] Submitting SQL update statement to the cluster...
[INFO] SQL update statement has been successfully submitted to the cluster:
Job ID: 1163eb7a404c2678322adaa89409bcda
-----由于es的表不支持source,故不能查询,查询会报如下错误----
Flink SQL> select * from alan_flink_es_user_idx;
[ERROR] Could not execute SQL statement. Reason:
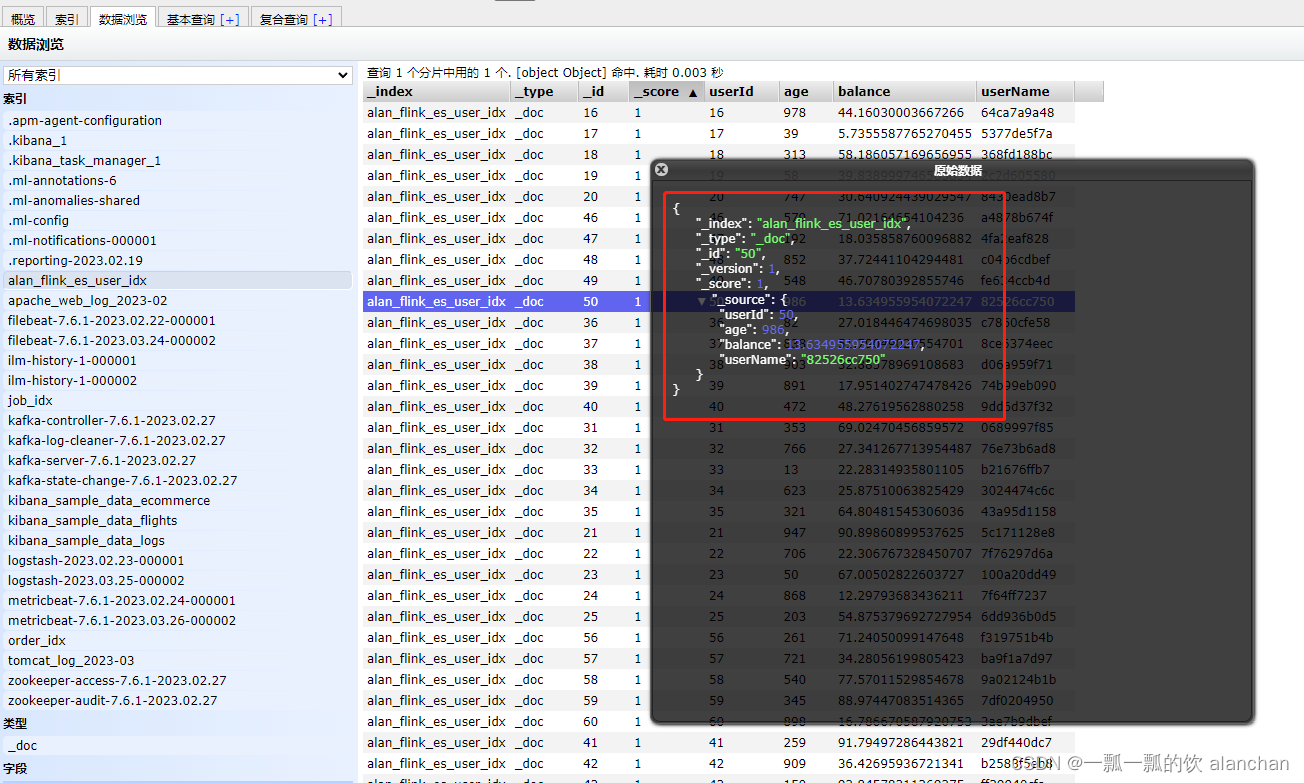
org.apache.flink.table.api.ValidationException: Connector 'elasticsearch-7' can only be used as a sink. It cannot be used as a source.Elasticsearch结果如下图
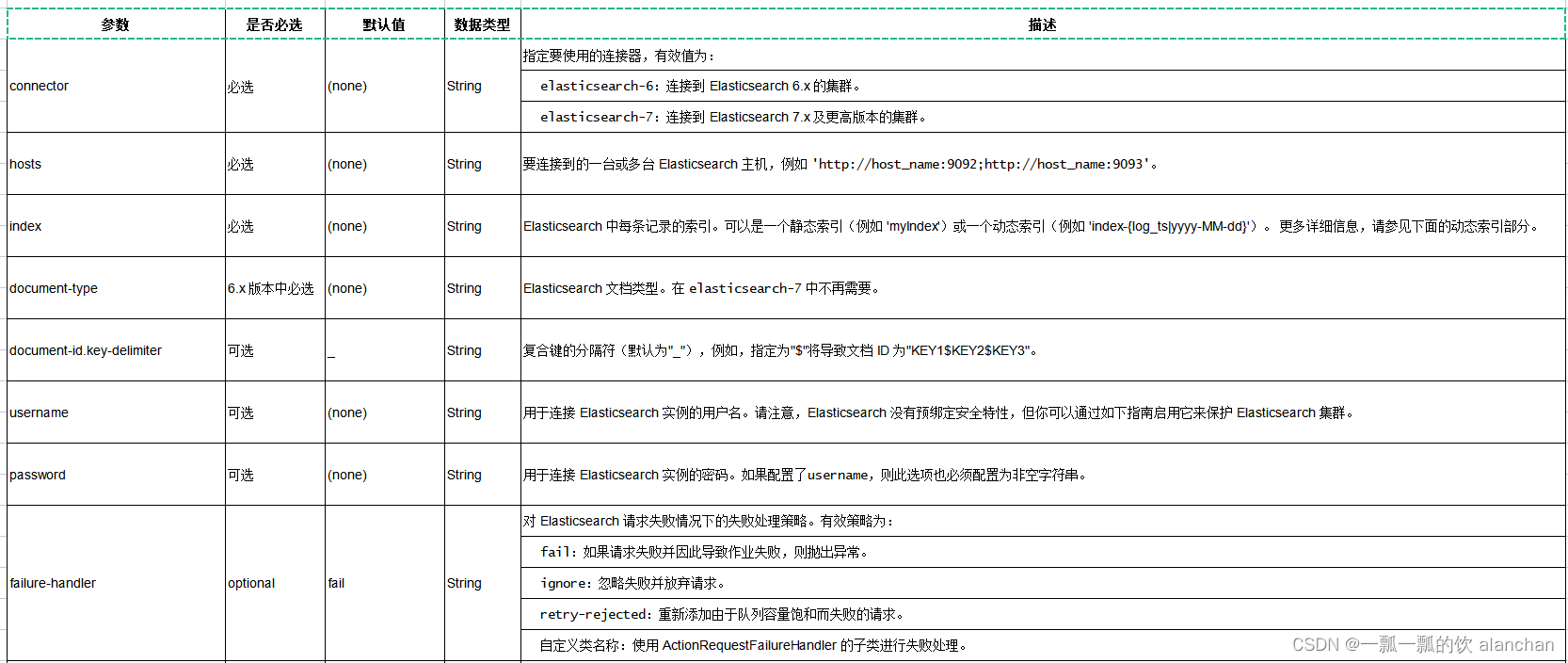
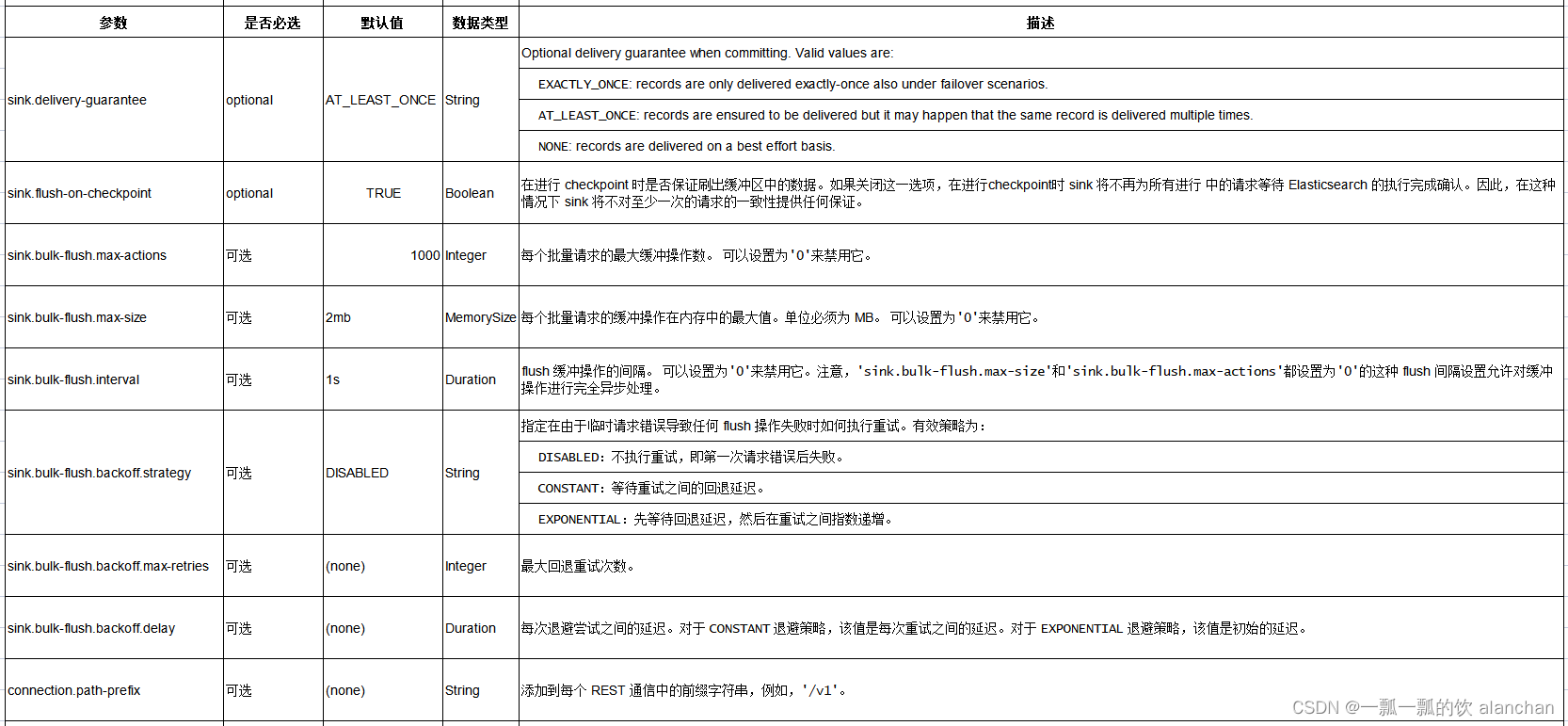
3、连接器参数

4、特性
1)、Key 处理
Elasticsearch sink 可以根据是否定义了一个主键来确定是在 upsert 模式还是 append 模式下工作。 如果定义了主键,Elasticsearch sink 将以 upsert 模式工作,该模式可以消费包含 UPDATE/DELETE 消息的查询。 如果未定义主键,Elasticsearch sink 将以 append 模式工作,该模式只能消费包含 INSERT 消息的查询。
在 Elasticsearch 连接器中,主键用于计算 Elasticsearch 的文档 id,文档 id 为最多 512 字节且不包含空格的字符串。 Elasticsearch 连接器通过使用 document-id.key-delimiter 指定的键分隔符按照 DDL 中定义的顺序连接所有主键字段,为每一行记录生成一个文档 ID 字符串。 某些类型不允许作为主键字段,因为它们没有对应的字符串表示形式,例如,BYTES,ROW,ARRAY,MAP 等。 如果未指定主键,Elasticsearch 将自动生成文档 id。
有关 PRIMARY KEY 语法的更多详细信息,请参见 22、Flink 的table api与sql之创建表的DDL。
2)、动态索引
Elasticsearch sink 同时支持静态索引和动态索引。
如果你想使用静态索引,则 index 选项值应为纯字符串,例如 ‘myusers’,所有记录都将被写入到 “myusers” 索引中。
如果你想使用动态索引,你可以使用 {field_name} 来引用记录中的字段值来动态生成目标索引。 你也可以使用 ‘{field_name|date_format_string}’ 将 TIMESTAMP/DATE/TIME 类型的字段值转换为 date_format_string 指定的格式。 date_format_string 与 Java 的 DateTimeFormatter 兼容。 例如,如果选项值设置为 ‘myusers-{log_ts|yyyy-MM-dd}’,则 log_ts 字段值为 2020-03-27 12:25:55 的记录将被写入到 “myusers-2020-03-27” 索引中。
你也可以使用 ‘{now()|date_format_string}’ 将当前的系统时间转换为 date_format_string 指定的格式。now() 对应的时间类型是 TIMESTAMP_WITH_LTZ 。 在将系统时间格式化为字符串时会使用 session 中通过 table.local-time-zone 中配置的时区。 使用 NOW(), now(), CURRENT_TIMESTAMP, current_timestamp 均可以。
使用当前系统时间生成的动态索引时, 对于 changelog 的流,无法保证同一主键对应的记录能产生相同的索引名, 因此使用基于系统时间的动态索引,只能支持 append only 的流。
5、数据类型映射
Elasticsearch 将文档存储在 JSON 字符串中。因此数据类型映射介于 Flink 数据类型和 JSON 数据类型之间。 Flink 为 Elasticsearch 连接器使用内置的 ‘json’ 格式。更多类型映射的详细信息,请参阅 35、Flink 的JSON Format。
二、Flink SQL示例:将kafka数据写入es
本示例是将kafka的数据通过Flink 的任务写入es中。
1、依赖环境
需要增加kafka和es相关的jar包,本示例用到如下:
flink-sql-connector-elasticsearch7_2.11-1.13.6.jar
flink-sql-connector-kafka_2.11-1.13.5.jar
2、创建表并提交任务
在flink sql中运行
CREATE TABLE alan_flink_es_kafka_user_idx (userId INT,age INT,balance DOUBLE,userName STRING,t_insert_time AS localtimestamp,PRIMARY KEY (userId) NOT ENFORCED
) WITH ('connector' = 'elasticsearch-7','hosts' = 'http://192.168.10.41:9200','index' = 'alan_flink_es_kafka_user_idx_test'
);CREATE TABLE alanchan_kafka_table (`id` INT,name STRING,age INT,balance DOUBLE,ts BIGINT, -- 以毫秒为单位的时间t_insert_time AS TO_TIMESTAMP_LTZ(ts,3),WATERMARK FOR t_insert_time AS t_insert_time - INTERVAL '5' SECOND -- 在 TIMESTAMP_LTZ 列上定义 watermark
) WITH ('connector' = 'kafka','topic' = 't_kafkasource2','scan.startup.mode' = 'earliest-offset','properties.bootstrap.servers' = '192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092','format' = 'csv'
);INSERT INTO alan_flink_es_kafka_user_idx
SELECT id, age, balance , name FROM alanchan_kafka_table;
3、验证
本示例没有特别说明,则是在flink sql cli中操作,kafka则是kafka的运行环境命令。
1)、创建es表
Flink SQL> CREATE TABLE alan_flink_es_kafka_user_idx (
> userId INT,
> age INT,
> balance DOUBLE,
> userName STRING,
> t_insert_time AS localtimestamp,
> PRIMARY KEY (userId) NOT ENFORCED
> ) WITH (
> 'connector' = 'elasticsearch-7',
> 'hosts' = 'http://192.168.10.41:9200',
> 'index' = 'alan_flink_es_kafka_user_idx_test'
> );
[INFO] Execute statement succeed.2)、创建kafka表
Flink SQL> CREATE TABLE alanchan_kafka_table (
> `id` INT,
> name STRING,
> age INT,
> balance DOUBLE,
> ts BIGINT, -- 以毫秒为单位的时间
> t_insert_time AS TO_TIMESTAMP_LTZ(ts,3),
> WATERMARK FOR t_insert_time AS t_insert_time - INTERVAL '5' SECOND -- 在 TIMESTAMP_LTZ 列上定义 watermark
> ) WITH (
> 'connector' = 'kafka',
> 'topic' = 't_kafkasource2',
> 'scan.startup.mode' = 'earliest-offset',
> 'properties.bootstrap.servers' = '192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092',
> 'format' = 'csv'
> );
[INFO] Execute statement succeed.3)、提交任务
Flink SQL> INSERT INTO alan_flink_es_kafka_user_idx
> SELECT id, age, balance , name FROM alanchan_kafka_table;
........
[INFO] SQL update statement has been successfully submitted to the cluster:
Job ID: dc19c9b904f69985d40eca372af9553a4)、创建kafkatopic
[alanchan@server3 bin]$ kafka-topics.sh --create --bootstrap-server server1:9092 --topic t_kafkasource2 --partitions 1 --replication-factor 1
WARNING: Due to limitations in metric names, topics with a period ('.') or underscore ('_') could collide. To avoid issues it is best to use either, but not both.
Created topic t_kafkasource2.>5)、往kafka topic中写入数据
[alanchan@server3 bin]$ kafka-console-producer.sh --broker-list server1:9092 --topic t_kafkasource2
>1,alan,15,100,1692593500222
>2,alanchan,20,200,1692593501230
>3,alanchanchn,25,300,1692593502242
>4,alan_chan,30,400,1692593503256
>5,alan_chan_chn,500,45,1692593504270
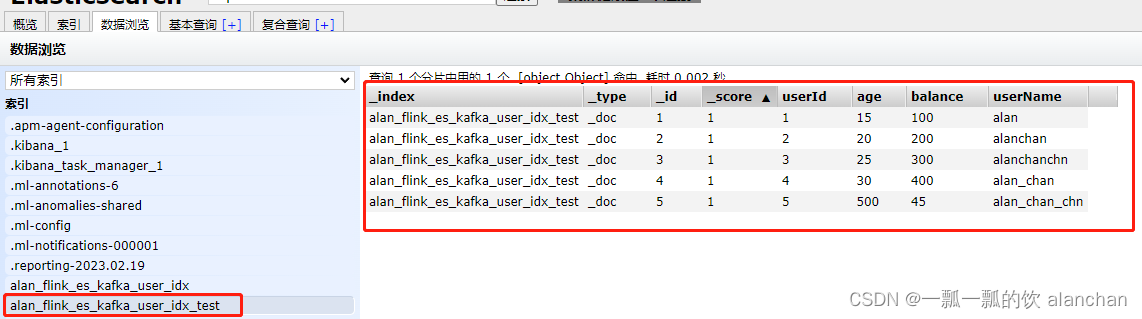
>6)、查看es中的数据
以上,完成了外部系统是Elasticsearch的介绍,使用了2个示例,即使用datagen作为数据源写入Elasticsearch和kafka作为数据源写入Elasticsearch中。