在动手学深度学习中,这样解释的:
当y不是标量时,向量y关于向量x的导数的最自然解释是一个矩阵。 对于高阶和高维的y和x,求导的结果可以是一个高阶张量。
然而,虽然这些更奇特的对象确实出现在高级机器学习中(包括深度学习中), 但当调用向量的反向计算时,我们通常会试图计算一批训练样本中每个组成部分的损失函数的导数。 这里,我们的目的不是计算微分矩阵,而是单独计算批量中每个样本的偏导数之和。
所以,目标是要把y编程一个标量,然后进行求导。
关于 dot(x,x) 后为标量, xx后为矩阵,xx.sum() 后为标量
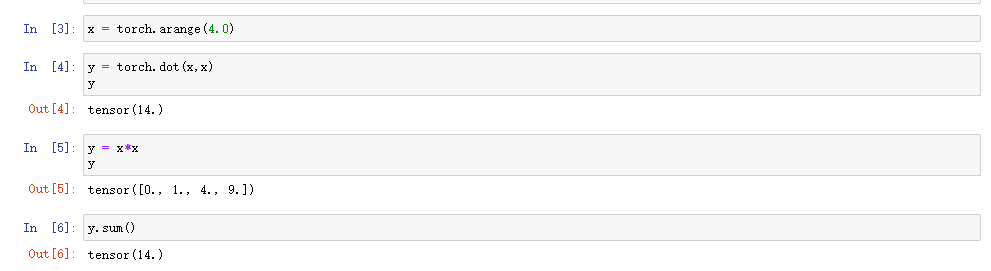
# 对非标量调用backward需要传入一个gradient参数,该参数指定微分函数关于self的梯度。
# 本例只想求偏导数的和,所以传递一个1的梯度是合适的
x.grad.zero_()
y = x * x
# 等价于y.backward(torch.ones(len(x)))
y.sum().backward()
x.grad



![java八股文面试[java基础]——浅拷贝和深拷贝](https://img-blog.csdnimg.cn/68d591e834284170bd20a61d0df0a9eb.png)