摘要:本文整理自阿里云/数据湖 Spark 引擎负责人周克勇(一锤)在 Streaming Lakehouse Meetup 的分享。内容主要分为五个部分:
- Apache Celeborn 的背景
- Apache Celeborn——快
- Apache Celeborn——稳
- Apache Celeborn——弹
- Evaluation
点击查看原文视频 & 演讲PPT
一、背景
大数据引擎的中间数据有两个来源: Shuffle 和 Spill,其中最重要的是 Shuffle,据统计有超过 15%的资源消耗在 Shuffle。
1.1 传统 Shuffle 的问题
下图右侧结构图是传统 Shuffle 的过程,左边是 Mapper Task,基于 Partition ID 对 Shuffle 数据排序,然后写到本地盘,同时会写一个索引文件,以记录文件里属于每一个 Partition 的 offset 和 length。在 Reduce Task 启动的时候,需要从每一个 Shuffle 文件里读取属于自己的数据。
从 Shuffle 文件的角度来看,它接收大量并发的读请求,且这些请求所读的数据是随机的,这就会带来随机的磁盘 I/O。
另外一方面,从下图也可以看到网络的连接数也非常多。
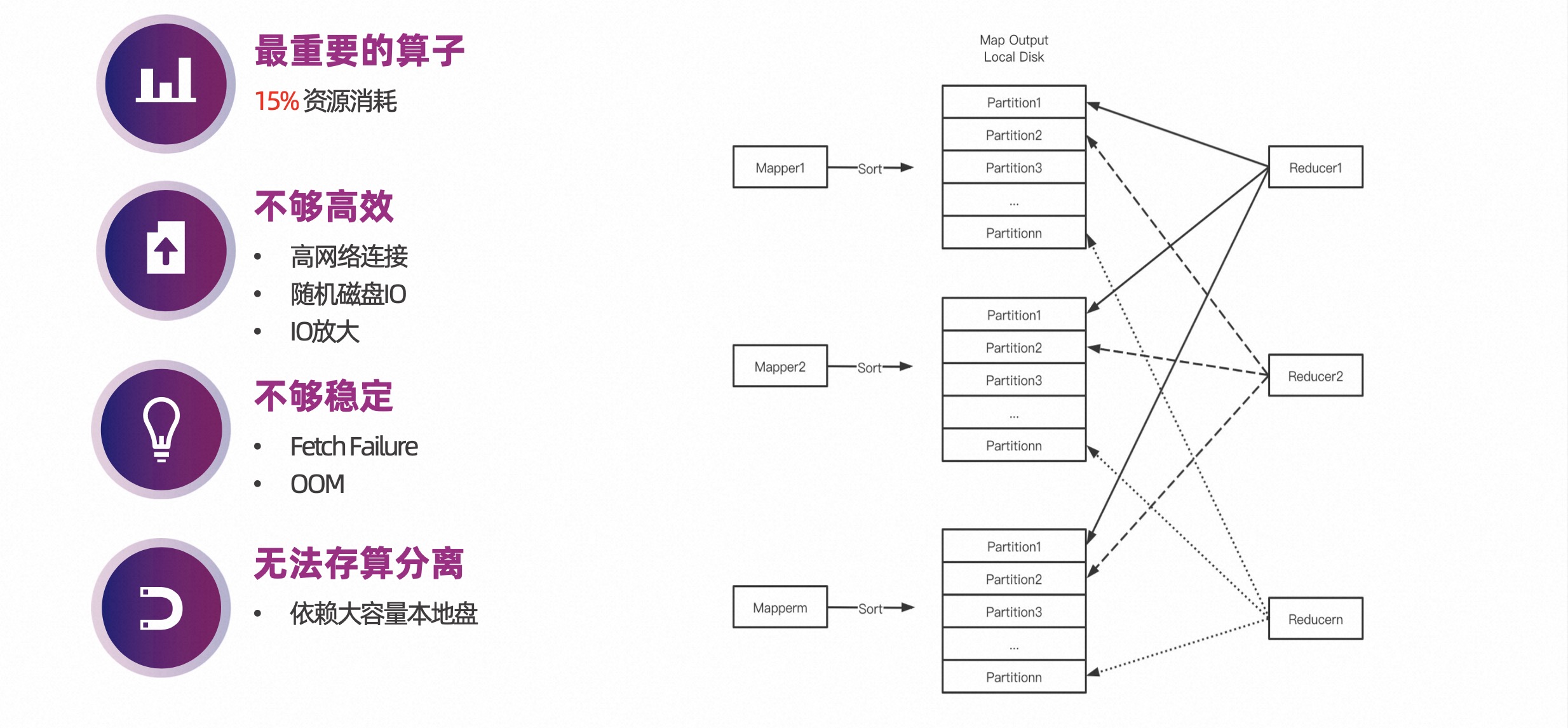
总结而言,Shuffle 算子非常重要,但是也存在一些问题:
- 作为最重要的算子,资源消耗超过 15%;
-
高网络连接、随机磁盘 I/O 和 I/O 放大,使得其不够高效;
-
Fetch Failure 和 OOM,导致其不够稳定;
-
依赖大容量本地磁盘,无法存算分离。
1.2 Apache Celeborn 的介绍
Apache Celeborn 是为了解决上述 Shuffle 的问题,定位是统一中间数据服务。

Apache Celeborn 具有两个维度:
-
第一,引擎无关。官方已经实现了 Spark 和 Flink。当前我们也在做 MR 和 Tez 的集成。
-
第二,中间数据。这里是指包括 Shuffle 和 Spill Data。当我们把中间数据全部托管,它的计算节点就不需要这么大的本地盘了,也就意味着计算节点可以做到真正的无状态,这就可以实现在作业运行的过程中做到更好的伸缩,从而获得更好的弹性和资源使用率。
Apache Celeborn 的发展史:
-
2020 年,诞生于阿里云;
-
2021 年 12 月,对外开源,同年做到云上开发者共建,构建多元化社区;
-
2022 年 10 月,进入 Apache 孵化器。
二、Apache Celeborn——快
Apache Celeborn 的快,将从四个角度展开介绍:
-
核心设计
-
列式 Shuffle
-
向量化引擎
-
多层存储
2.1 核心设计:Push/聚合/Spilt
从下图可见,左侧是 Apache Celeborn 最核心的设计,本质是一种 Push Shuffle 和 Partition 聚合的设计。它会把同一个 Partition 数据推送给同一个 Celeborn Worker。
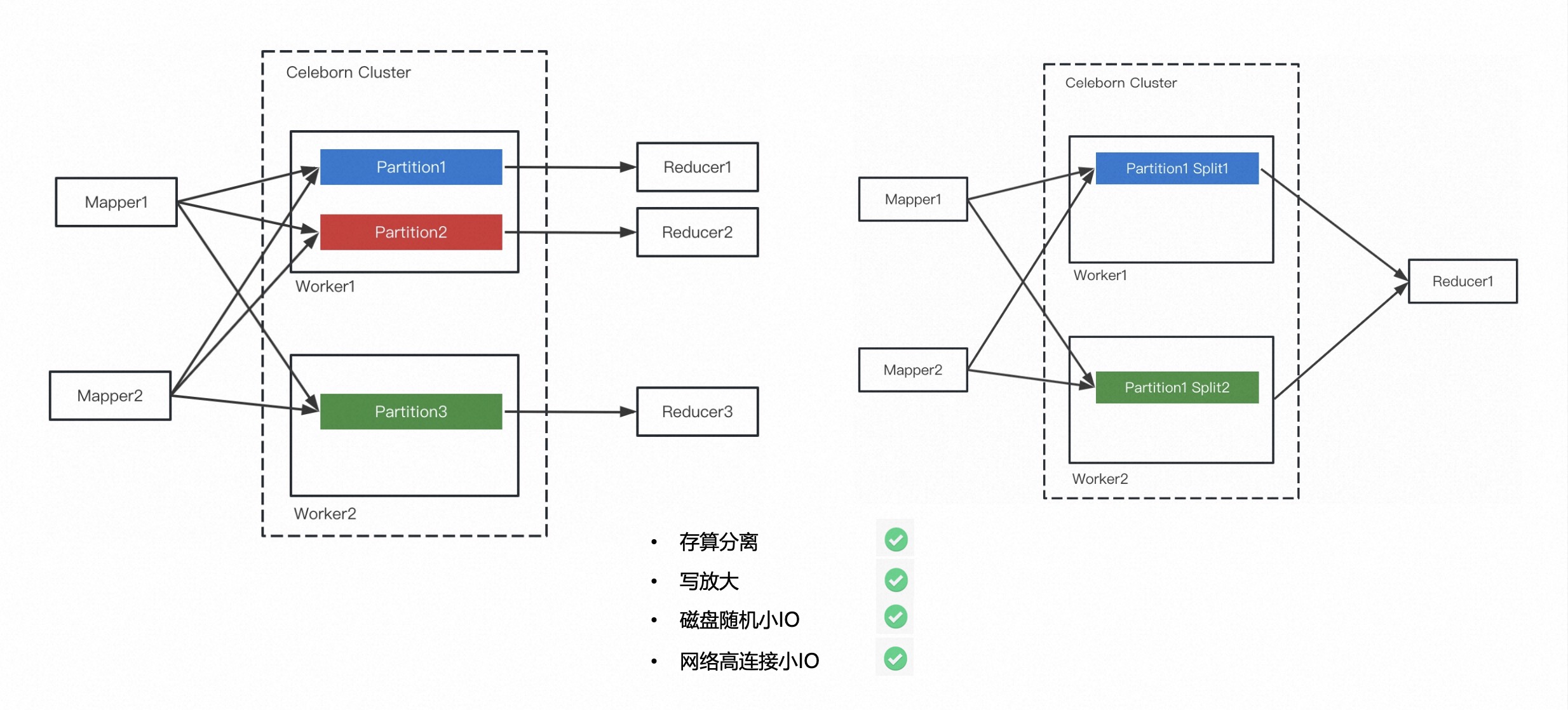
正常情况下,每一个 Partition 的数据都会最终形成一个文件,Reducer 在读取的时候只需要从 Worker 上读取一个文件就可以了。
因为 Shuffle 数据存在 Celeborn Cluster 里,不需要存放在本地磁盘,所以可以更好的做存算分离。另外,它是 Push Shuffle,不需要对全量 Shuffle 做数据排序,所以也不存在写放大的问题。
第三,通过 Partition 的聚合解决了网络和磁盘 I/O 低效的问题。
上图右侧的架构表明,数据倾斜很常见,即使在非倾斜的情况下,某一个 Partition 的数据特别大也是很容易发生的。这就会给磁盘带来较大的压力。所以这边做了一个 Split 机制。简单来讲就是 Celeborn Cluster 会检查某一个文件的大小,如果超过了阈值就会触发 Split,也就是说这个 Partition 数据最终会生成多个 Split 文件,Reduce Task 会从这些 Split 文件中读取 Partition 的数据。
2.2 核心设计:异步
我们在很多环节做了异步化,为的是不论在写、读还是 Control Message 过程中,不 block 计算引擎本身的计算。
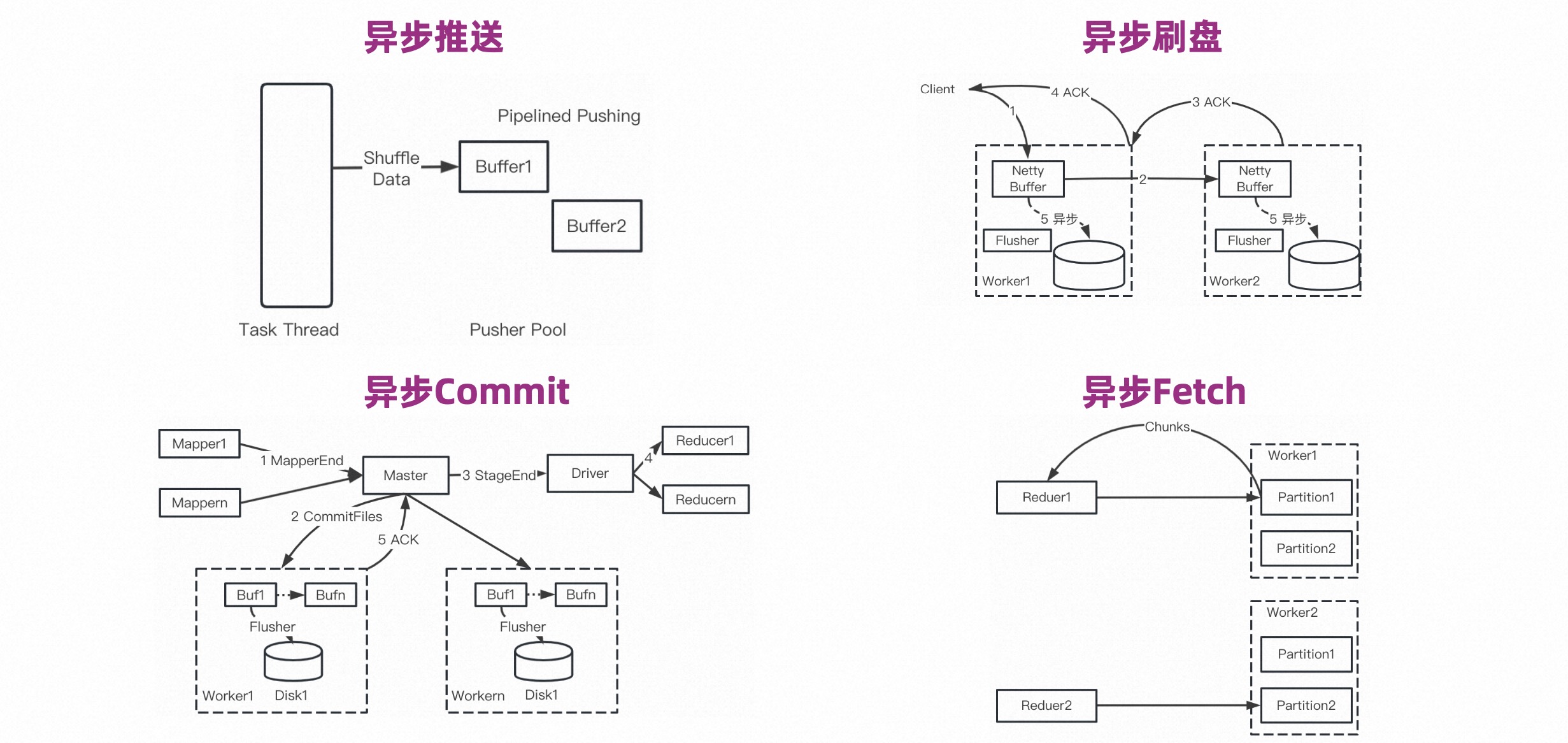
异步刷盘,无论是双备份还是单备份,在 Worker 端接收到数据后,不需要等刷盘就可以发 ACK。刷盘是异步的,当属于某个 Partition 的 Netty Buffer 达到某个阈值后触发刷盘,从而提升刷盘效率。
异步 Commit 是指在 Stage 结束后会有一个 Commit 过程,简单来讲需要让参与 Shuffle 的 Worker 把内存数据刷盘。这个过程也是异步的。
异步 Fetch 是比较常见的,意思是 Partition 数据生成了文件,切成很多 Chunk,那么在 Fetch 的时候可以 Fetch 多个 Chunk,这样就可以把 Fetch 数据和 Reduce 计算 Pipeline 起来。
2.3 列式 Shuffle
Celeborn 支持列式 Shuffle,写时做行专列,读时做列转行。相比于行存,列存具有更高的压缩率,数据量可以减少 40%。
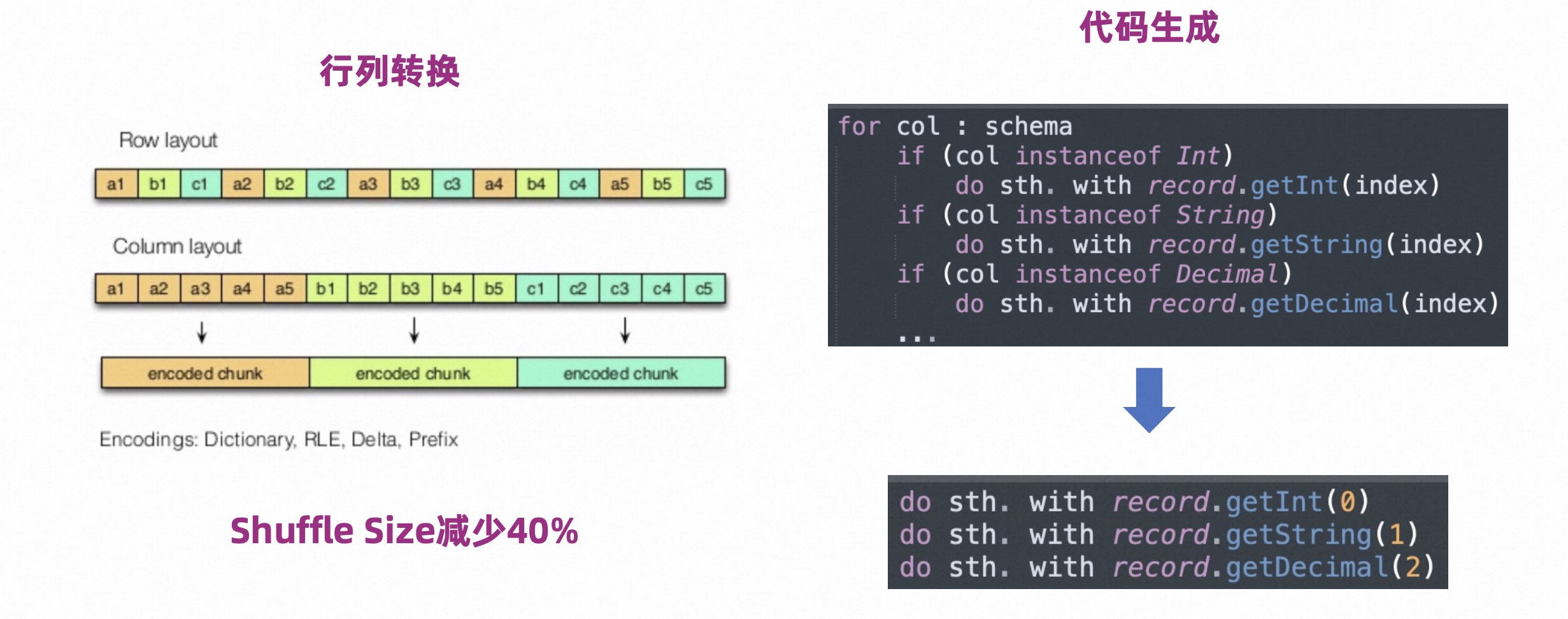
为了降低行列转换过程中的解释执行开销,Celeborn 引入了 Code Generation 的技术,如上图右侧所示。
2.4 对接向量化引擎
大数据计算引擎用 Native 向量化提升性能,这是目前的一个共识。无论是 Spark 还是别的引擎,大家都在往这个方向探索。
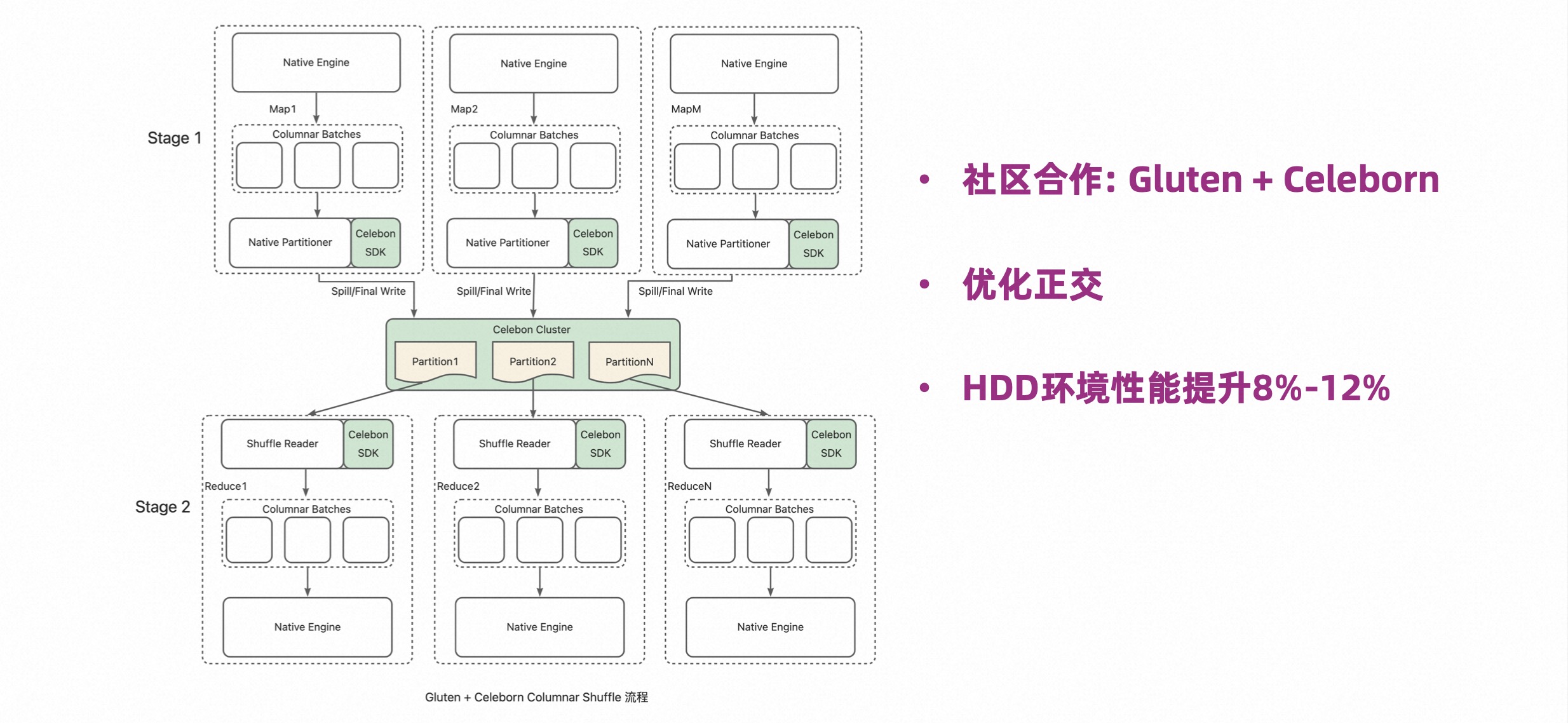
Gluten 是英特尔和麒麟联合发起的项目,能够让 Spark 集成其他的 Native 引擎。除此之外,Gluten 还做了内存管理和 Native Shuffle,它的 Native Shuffle 相比原生的 Java Shuffle 更加高效,但其沿用了 ESS 框架,因而存在前述的限制。
当 Celeborn 社区和 Gluten 社区合作,就可以将两者的优势结合,这样就可以做到优化正交。
2.5 多层存储
Shuffle 有大有小,对于小的 Shuffle 需要走一层网络,效率是难以保障的。多层存储从通过内存缓存进行优化。
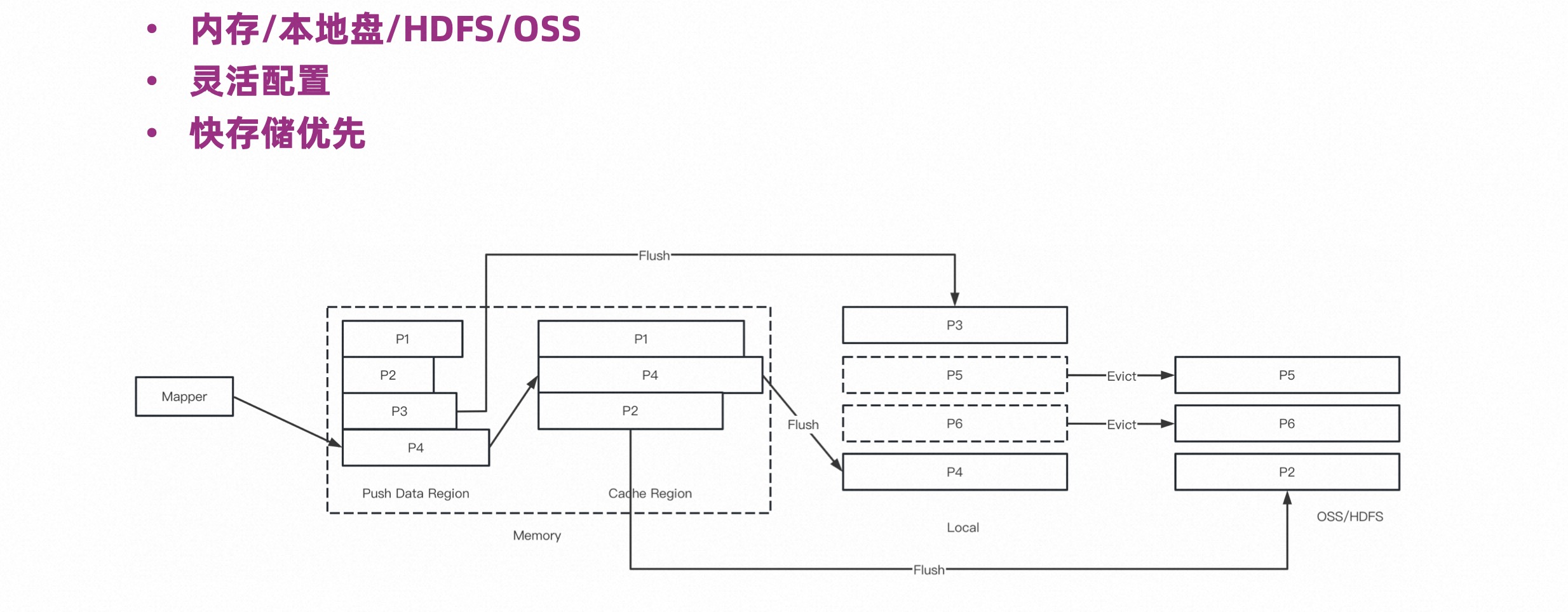
多层存储定义了内存,本地盘和外部存储,外部存储包括 HDFS 或 OSS,设计理念是尽可能让小 Shuffle 的整个生命周期都能贮存在内存里,并尽可能的落在更快的盘里。
三、Apache Celeborn——稳
有了 Celeborn 的核心设计,大 Shuffle 作业在性能和稳定性上有了很大提升。Celeborn 服务自身的稳定性,可以从四个角度展开:
-
容错
-
快速滚动升级
-
Traffic Control
-
负载均衡
3.1 容错
如下图,在容错这个层面,我们做了以下工作:
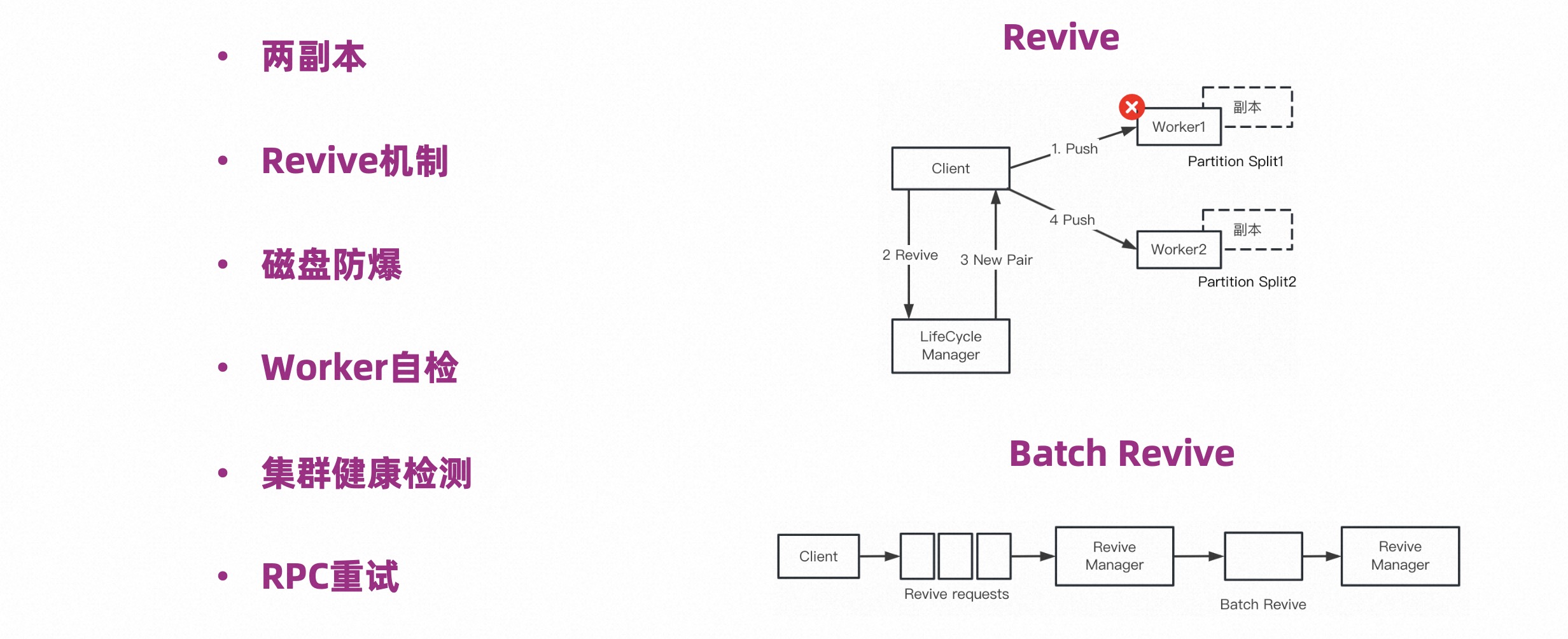
上图右侧描述了 Revive 机制。Client 推数据是最高频的操作,也是最容易发生错误的地方。当 Push 失败,我们采取了比较宽容的策略,将这次推送认为是 Worker 短暂不可用,只需要把将来的数据推送到别的 Worker 上就可以了,这就是 Revive 机制的核心。
右侧下面的 Batch Revive 是针对 Revive 机制的一个优化。也就是说当 Worker 不可用,所有往这个 Worker 上推送的数据请求都会失败,那么就会产生大量的 Revive 请求,为了降低这些请求的数量,我们对 Revive 做了 Batch,Batch 化之后就可以批量的处理错误。
关于磁盘防爆上文也提及过,我们会检测单个文件大小,并让其切分。另外还会检查当前磁盘的可用容量是否足够,如果不足会触发 Split。
3.2 快速滚动升级
下图详细的介绍了 Celeborn Worker 需要滚动升级的时候,是怎么样在不影响当前运行作业的情况下完成滚动升级的。
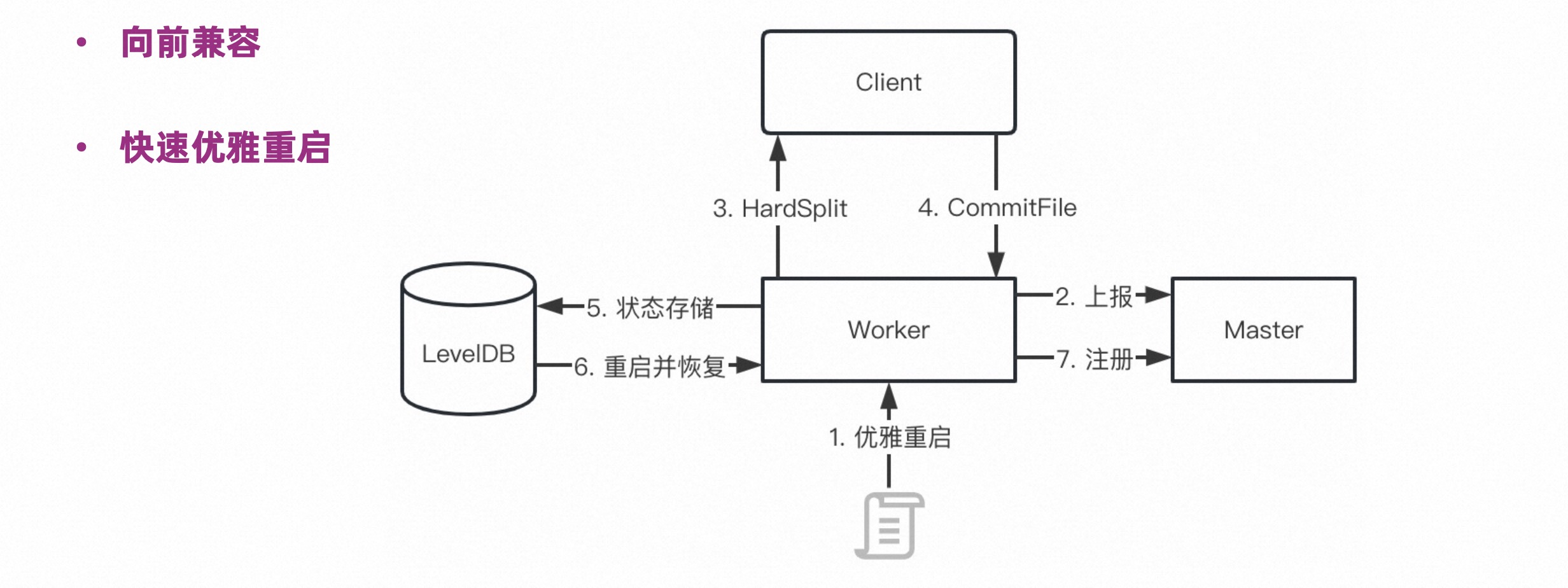
Worker 触发优雅停机后,把状态告诉 Master,Master 就不会继续往 Worker 上分配负载,同时 Worker 上正在服务的 Partition 请求会收到一个 HardSplit 标记,然后触发 Revive,Client 就不会再往这里推送数据,同时会给 Worker 发一个 CommitFile,触发内存的数据的刷盘。这个时候 Worker 不会收到新的负载,老的负载也不会被推送,内存的数据也全部都写入磁盘了。此时 Worker 把内存状态存储到本地的 LevelDB 后,就可以安全退出了。重启之后,从 LevelDB 中读取状态,继续提供服务了。
通过以上的这种机制,可以做到快速滚动升级。
3.3 Traffic Control
Traffic Control 的目的是不要打爆 Worker 的内存,也不希望打爆 Client 的内存。如下图所示,这里面提供了三个机制:
第一,反压机制。从 Worker 角度来讲,数据来源有两个,一是 Mapper 推给它的数据,二是如果开启两个副本,那么主副本会往从副本发送数据。
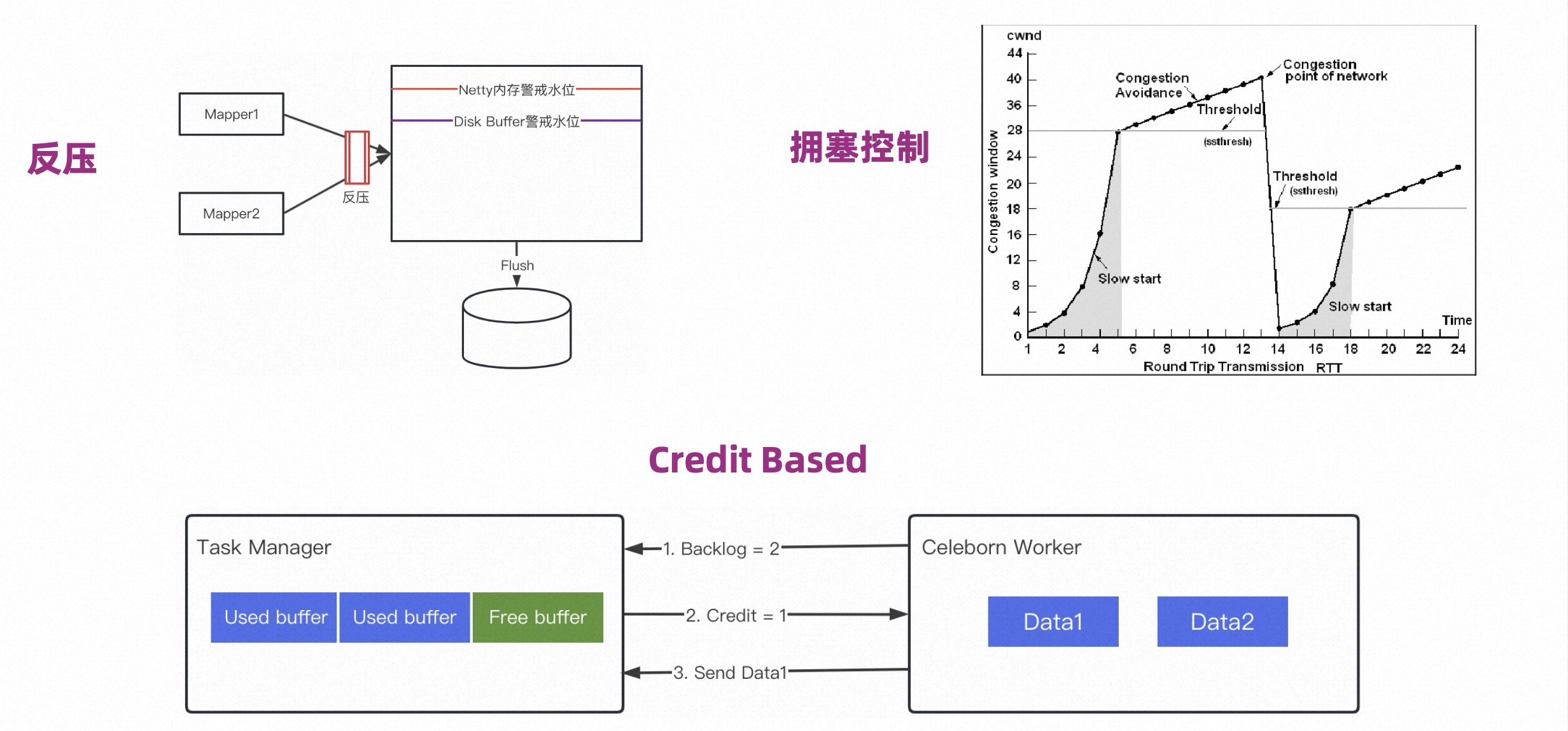
那么当内存达到警戒线,就会停止数据源头推送数据,同时还需要“泄洪”,把内存卸下来。
第二,拥塞控制。在 Shuffle Client 端采用类似 TCP 的拥塞控制主动控制推送数据的速率,避免瞬时流量把 Worker 内存打爆。
一开始处于 Slow Start 的状态,推送速率较低,但是速率增长很快,当达到拥塞避免阶段,速率增长会变慢。一旦收到 Worker 端拥塞控制的信号,就会马上回到 Slow Start 状态。Worker 端会记录过去一段时间来自各个用户或是各个作业推送的数据量,然后决定谁应该被拥塞控制。
第三,Credit Based。用于 Flink Read 场景,在 Shuffle Read 时,需要保证所 Read 的数据是被 Flink 管理的。简单讲就是 Worker 把数据推给 Task Manager 之前,需要拿到 Credit。
3.4 负载均衡
这里主要是指磁盘的负载均衡,针对的是异构集群场景。

异构情况下机器的处理能力、磁盘容量和磁盘健康都是不一样的。每个 Worker 都会自检本地磁盘的健康状态和性能,同时把结果汇报给 Master,这样 Master 有一个全局的磁盘视野,可以根据一定的策略在这些磁盘之间做负载分配,实现更好的负载均衡。
四、Apache Celeborn——弹
使用 Apache Celeborn 的典型场景有三种:完全混部、Celeborn 独立部署和存算分离。
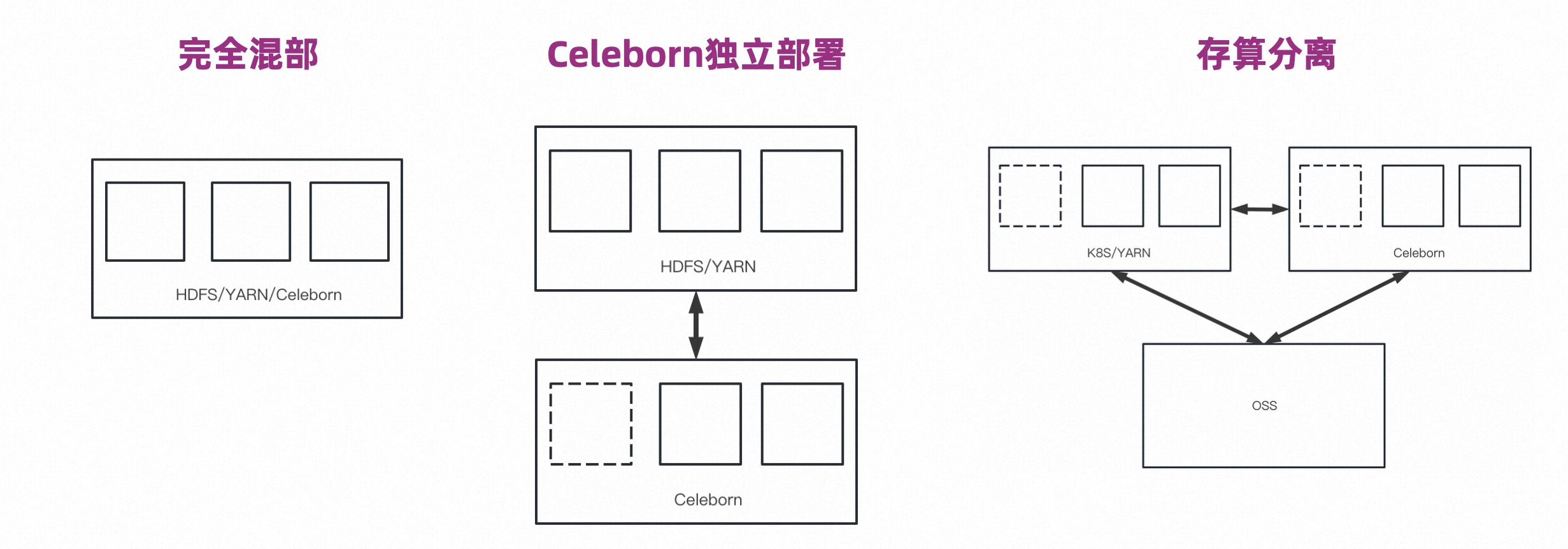
完全混部的收益主要是提升性能和稳定性,但是它的资源因为固定,所以很难做到弹性。
Celeborn 独立部署,Celeborn 的 I/O 和 HDFS 的 I/O 可以做隔离,免去互相的影响,且 Celeborn 集群具备一定弹性。
存算分离,计算和存储是分开的,Celeborn 集群独立部署。计算集群因为 Shuffle 变为无状态可以做很好的弹性,Celeborn 集群本身也具有弹性能力,存储这边也可以按照存储量收费。所以这是一个成本、性价比比较好的方案。
五、Evalution
5.1 稳定性
- Spark 大作业
场景:混部方式,用 Spark on Yarn + Celeborn。部署了 1000 台 Celeborn Worker,但 Worker 资源使用量是比较少的,内存大概是 30g 左右,每天的 Shuffle 数据量是若干个 PB。
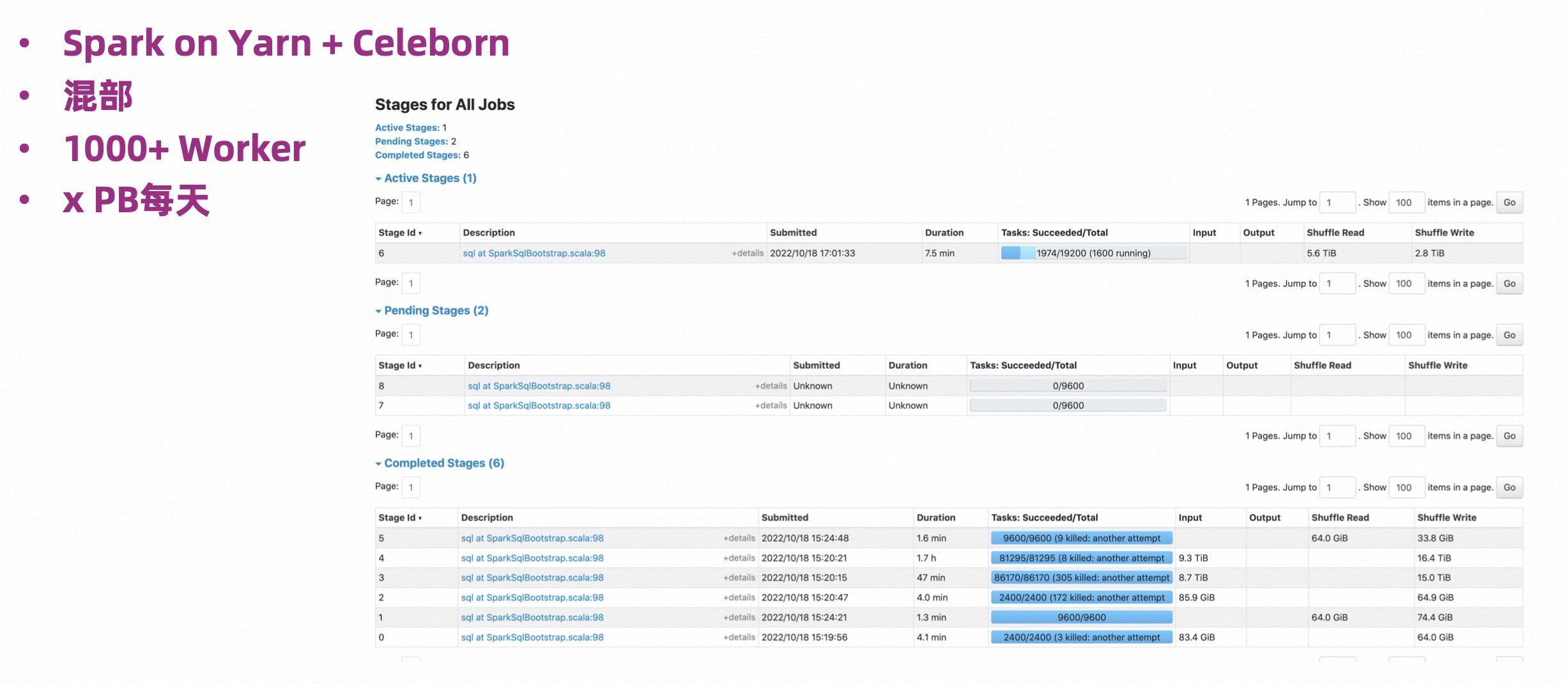
从上图可见,这是一个非常典型的大作业,有几万个并发,在运行的过程中仍然非常稳定。
- Flink 大作业
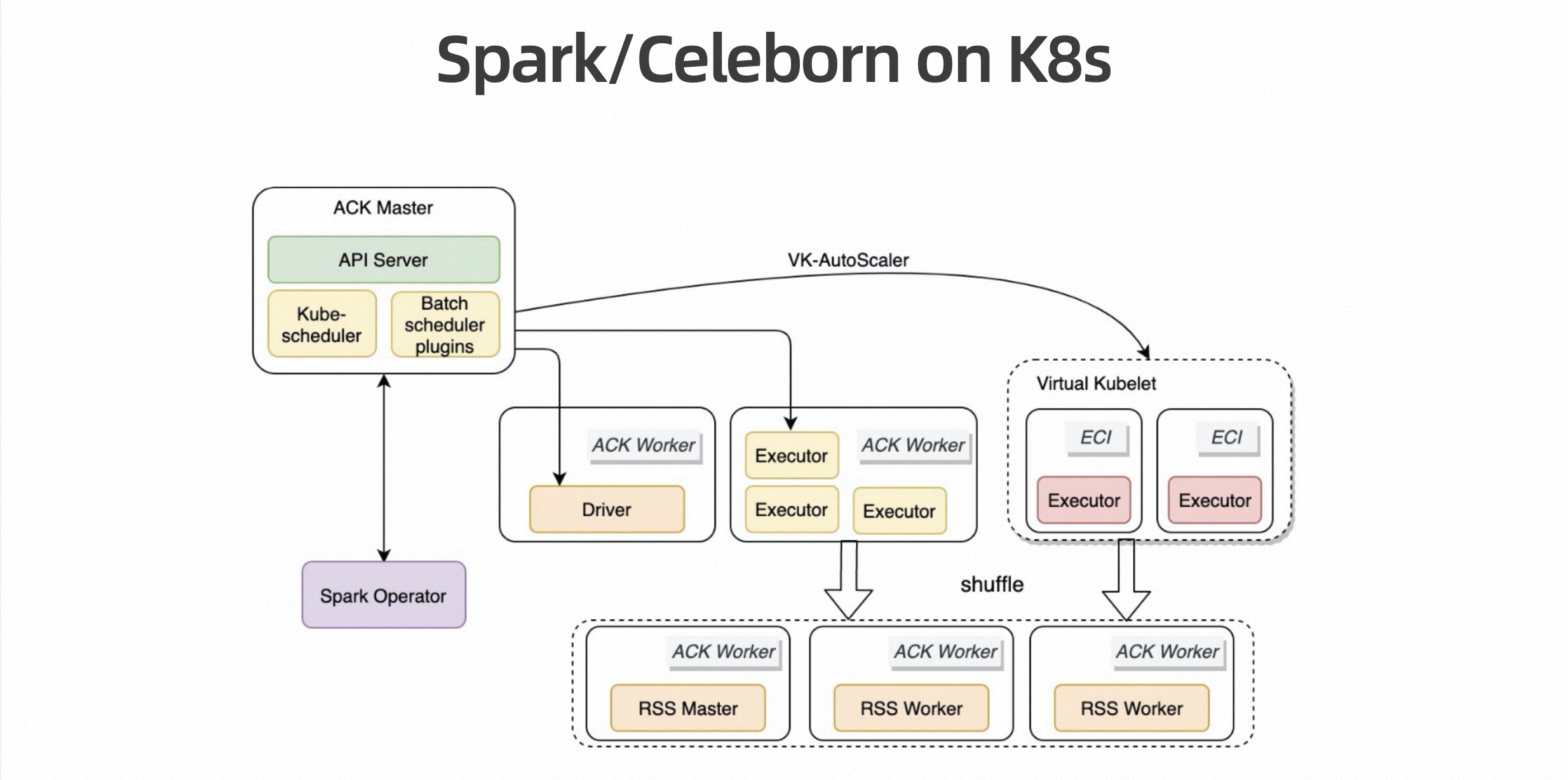
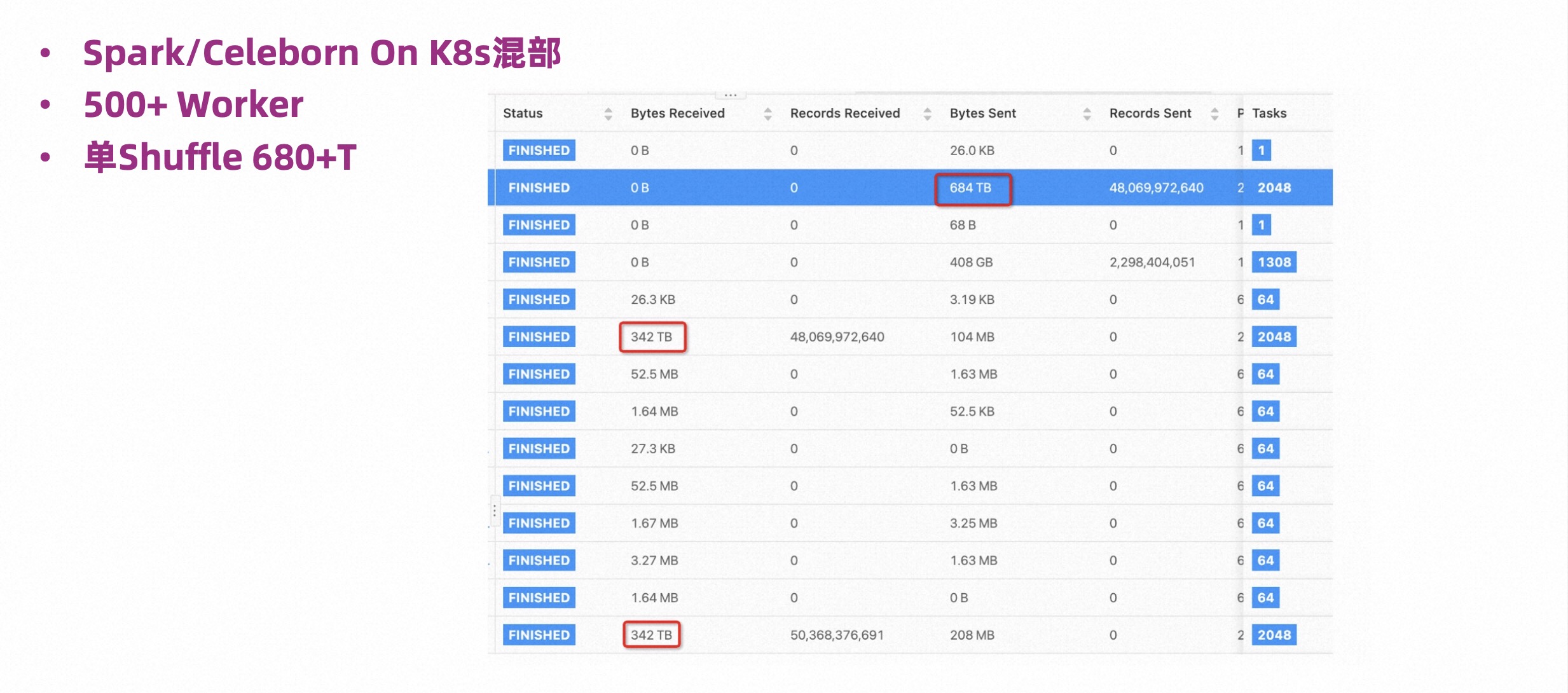
下图是阿里内部 Flink Batch 作业的一个截图。部署方式是 Flink on K8s + Celeborn On K8s,部署了 500 台 Worker,每个 Worker 是 20G 的内存。
这也是一个非常大的作业,可以看到它单个 Shuffle 有 680TB,但运行过程也是很稳定的。
5.2 滚动重启
下图是已经测试作业运行中 Worker 的滚动重启。将一个 Worker 停掉,等进程退出,再重新启动。下图的时间点可见,从 19 分 44 秒开始停止,19 分 53 秒退出作业,20 分 1 秒的时候重新启动并完成注册,并继续开始提供服务。整个过程只需 27 秒,作业完全没有受到影响。
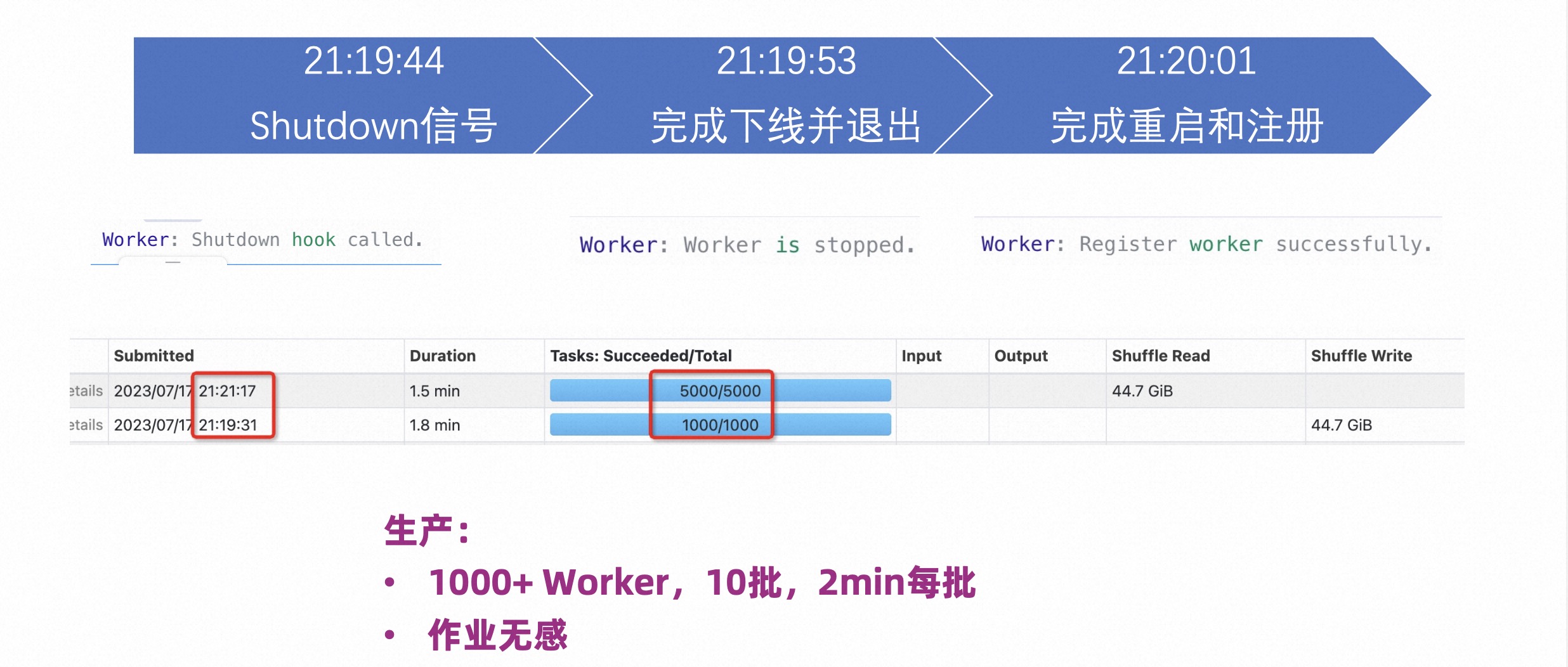
另外一个用户,在生产上做了滚动重启升级,滚动重启 1000 台 Worker,分了 10 批执行,观察下来是每 2 分钟左右就可以完成一批次的重启,完全不影响作业。
5.3 性能
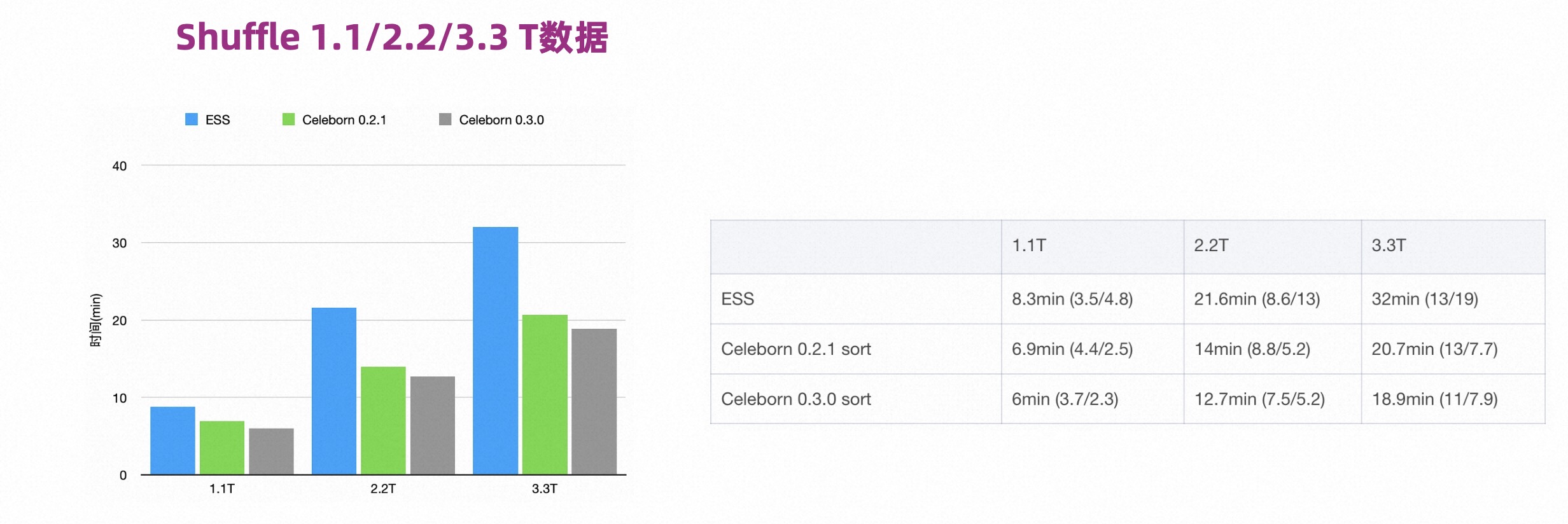
如下图所示,Celeborn0.2 和 0.3 相比 ESS 都有比较明显的性能提升,同时 0.3 版本比 0.2 版本有进一步的性能提升。
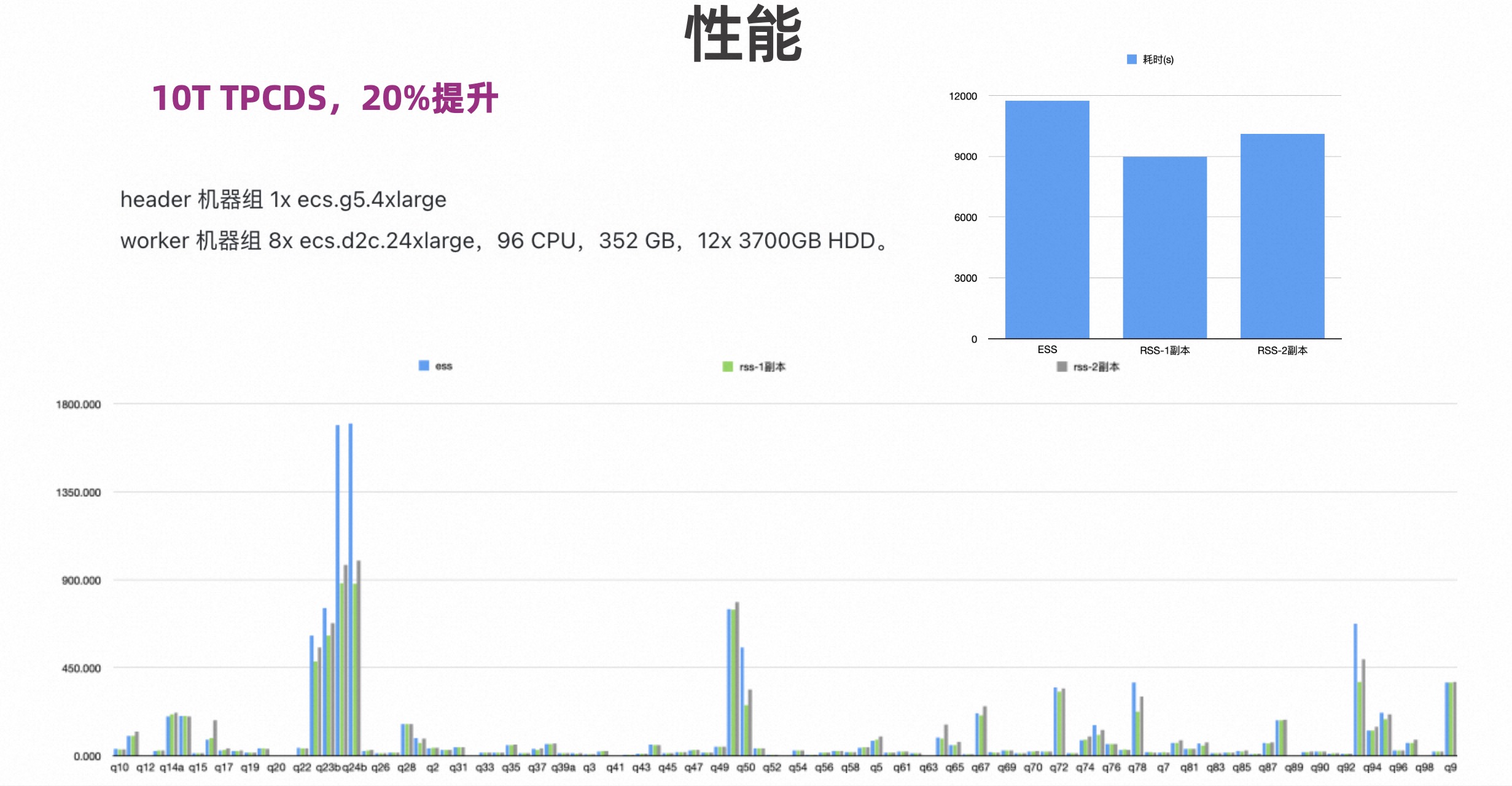
下图测试的是 TPCDS,对比的是 ESS,Celeborn 单副本和两副本。可以看到单副本性能有 20%多的提升,两副本有 15%的提升。
5.4 弹性
如下图所示,用存算分离的架构,部署 100 台 Worker,计算是 Spark On K8s,每天伸缩数万个 Pods。

加入我们
-
GitHub GitHub - apache/incubator-celeborn: Apache Celeborn is an elastic and high-performance service for shuffle and spilled data.
-
钉钉群: 41594456
-
微信加好友进群:brick_carrier
-
微信公众号:Apache Celeborn孵化
Q&A
Q:请问是不是把以上说的那些优化手段,放在本地上,会不会取得更好的效果?
A:Spark 有一个 LinkedIn 主导的 Magnet 的优化,但因为 Shuffle 依然使用 Node Manage 管理,会存在一些问题。
第一个问题是,解决不了存算分离的问题;第二从性能角度来讲,Magnet 保留两种方式,在保留了写本地 Shuffle 的同时做 Push Shuffle,也就是异步读取本地 Shuffle 文件之后,再去 Push 远端的 ESS,而不是一边产生数据一边去 Push。
这样就带来一个问题,当 Shuffle 结束的时候,并不能保证所有的数据都 Push 到远端,那么为了避免过长的等待时间,它会强行中断这个过程。也就是最终有一部分数据被推到远端,有一部分并没有。
这种情况下,从控制逻辑来讲,读数据的时候要先尽量去读 push 的 Shuffle,如果没有的话再读本地的 Shuffle,这是一个混合的过程。这个过程是有 Overhead 的。
Q:请问单独部署 Shuffle 会不会带来额外的网络开销?
A:这其实是架构选择的问题。如果不需要存算分离,不需要对计算集群做弹性扩容,只是为了解决性能和稳定性的问题,那么可以选择混合部署。如果需要做计算的弹性,那就更倾向于单独部署。
Q:请问 Spark 在执行过程中,Stage 可能会失败,在这种情况下,怎么处理呢?
A:这其实是数据正确性的问题。Spark Task 重算会导致重复数据的推送,Celeborn Client 也可能重复推送数据。
第一,Spark 会记录哪个 attempt 成功了,Celeborn 要拿到这个信息。
第二,推送的每个数据都会有一个 Map ID,attempt ID 和 Batch ID,这个 Batch ID 就是在 attempt里全局唯一的 ID。在 Shuffle read 的时候,只读成功的那个 attempt 数据;第二针对这个 attempt 数据,会记录下来之前读到的所有 Batch ID,如果发现了之前读过的,就直接忽略了。
这样可以保证既不会丢失数据,也不会重复数据。
Q:请问如果 Spark 或 Flink 和 Celeborn 一起去用的话,如果提交 Spark 任务,中间的 Shuffle 过程是 Celeborn 自己接管那个状态,还是我们可以直接用 Celeborn 实现这些功能?
A:这是用法的问题。如果想用 Celeborn,首先需要部署 Celeborn 集群;第二步,把 Celeborn 客户端的 Jar 拷贝到 Spark 或 Flink 的 Jars 目录;第三步,启动作业的时候多加一些参数。做好这几步,就可以正常使用 Celeborn 了。
点击查看原文视频 & 演讲PPT