ceph的PGLog是由PG来维护,记录了该PG的所有操作,其作用类似于数据库里的undo log。PGLog通常只保存近千条的操作记录(默认是3000条, 由osd_min_pg_log_entries指定),但是当PG处于降级状态时,就会保存更多的日志(默认是10000条),这样就可以在故障的PG重新上线后用来恢复PG的数据。本文主要从PG的格式、存储方式、如何参与恢复来解析PGLog。
相关配置说明:
-
osd_min_pg_log_entries: 正常情况下pg log记录的条数
-
osd_max_pg_log_entries: 异常情况下pg log记录的条数,达到该限制会进行trim操作
1. PGLog模块静态类图
PGLog模块的静态类图如下图所示:

2. PGLog的格式
ceph使用版本控制的方式来标记一个PG内的每一次更新,每个版本包括一个(epoch, version)来组成。其中,epoch是osdmap的版本,每当有OSD状态变化(如增加、删除等时),epoch就递增;version是PG内每次更新操作的版本号,是递增的,由PG内的Primary OSD进行分配。
PGLog在代码实现中有3个主要的数据结构来维护(相关代码位于src/osd/osd_types.h中):
- pg_log_entry_t
结构体pg_log_entry_t记录了PG日志的单条记录,其数据结构如下:
struct pg_log_entry_t {ObjectModDesc mod_desc; //用于保存本地回滚的一些信息,用于EC模式下的回滚操作bufferlist snaps; //克隆操作,用于记录当前对象的snap列表hobject_t soid; //操作的对象osd_reqid_t reqid; //请求唯一标识(caller + tid)vector<pair<osd_reqid_t, version_t> > extra_reqids;eversion_t version; //本次操作的版本eversion_t prior_version; //前一个操作的版本eversion_t reverting_to; //本次操作回退的版本(仅用于回滚操作)version_t user_version; //用户的版本号utime_t mtime; //用户的本地时间__s32 op; //操作的类型bool invalid_hash; // only when decoding sobject_t based entriesbool invalid_pool; // only when decoding pool-less hobject based entries...
};- pg_log_t
结构体pg_log_t在内存中保存了该PG的所有操作日志,以及相关的控制结构:
/*** pg_log_t - incremental log of recent pg changes.** serves as a recovery queue for recent changes.*/
struct pg_log_t {/** head - newest entry (update|delete)* tail - entry previous to oldest (update|delete) for which we have* complete negative information. * i.e. we can infer pg contents for any store whose last_update >= tail.*/eversion_t head; //日志的头,记录最新的日志记录版本eversion_t tail; //指向最老的pg log记录的前一个版本eversion_t can_rollback_to; //用于EC,指示本地可以回滚的版本, 可回滚的版本都大于can_rollback_to的值//在EC的实现中,本地保留了不同版本的数据。本数据段指示本PG里可以删除掉的对象版本。rollback_info_trimmed_to的值 <= can_rollback_toeversion_t rollback_info_trimmed_to; //所有日志的列表list<pg_log_entry_t> log; // the actual log....
};需要注意的是,PG日志的记录是以整个PG为单位,包括该PG内的所有对象的修改记录。
- pg_info_t
结构体pg_info_t是对当前PG信息的一个统计:
/*** pg_info_t - summary of PG statistics.** some notes: * - last_complete implies we have all objects that existed as of that* stamp, OR a newer object, OR have already applied a later delete.* - if last_complete >= log.bottom, then we know pg contents thru log.head.* otherwise, we have no idea what the pg is supposed to contain.*/
struct pg_info_t {spg_t pgid; //对应的PG ID//PG内最近一次更新的对象的版本,还没有在所有OSD上完成更新。在last_update和last_complete之间的操作表示//该操作已在部分OSD上完成,但是还没有全部完成。eversion_t last_update; eversion_t last_complete; //该指针之前的版本都已经在所有的OSD上完成更新(只表示内存更新完成)epoch_t last_epoch_started; //本PG在启动时候的epoch值version_t last_user_version; //最后更新的user object的版本号eversion_t log_tail; //用于记录日志的尾部版本//上一次backfill操作的对象指针。如果该OSD的Backfill操作没有完成,那么[last_bakfill, last_complete)之间的对象可能//处于missing状态hobject_t last_backfill; bool last_backfill_bitwise; //true if last_backfill reflects a bitwise (vs nibblewise) sortinterval_set<snapid_t> purged_snaps; //PG要删除的snap集合pg_stat_t stats; //PG的统计信息pg_history_t history; //用于保存最近一次PG peering获取到的epoch等相关信息pg_hit_set_history_t hit_set; //这是Cache Tier用的hit_set
};下面简单画出三者之间的关系示意图:

其中:
-
last_complete: 在该指针
之前的版本都已经在所有的OSD上完成更新(只表示内存更新完成); -
last_update: PG内最近一次更新的对象的版本,还没有在所有OSD上完成更新。在last_update与last_complete之间的操作表示该操作已在部分OSD上完成,但是还没有全部完成。
-
log_tail: 指向pg log最老的那条记录;
-
head: 最新的pg log记录
-
tail: 指向最老的pg log记录的前一个;
-
log: 存放实际的pglog记录的list
从上面结构可以得知,PGLog里只有对象更新操作相关的内容,没有具体的数据以及偏移大小等,所以后续以PGLog来进行恢复时都是按照整个对象来进行恢复的(默认对象大小是4MB)。
另外,这里再介绍两个概念:
- epoch是一个单调递增序列,其序列由monitor负责维护,当集群中的配置及OSD状态(up、down、in、out)发生变更时,其数值加1。这一机制等同于时间轴,每次序列变化是时间轴上的点。这里说的epoch是针对OSD的,具体到PG时,即对于每个PG的版本eversion中的epoch的变化并不是跟随集群epoch变化的,而是当前PG所在OSD的状态变化,当前PG的epoch才会发生变化。
如下图所示:
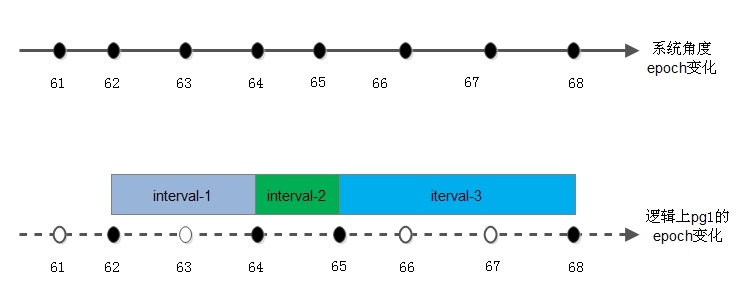
- 根据epoch增长的概念,即引入第二个重要概念interval
因为pg的epoch在其变化的时间轴上并非是完全连续的,所以在每两个变化的pg epoch所经历的时间段我们称之为intervals。
3. PGLog的存储方式
了解了PGLog的格式之后,我们就来分析一下PGLog的存储方式。在ceph实现里,对于写IO的处理,都是先封装成一个transaction,然后将这个transaction写到journal里。在Journal写完后,触发回调流程,经过多个线程及回调的处理后,再进行写数据到buffer cache的操作,从而完成整个写journal和本地缓存的流程(具体的流程在《OSD读写处理流程》一文中有详细描述)。
总体来说,PGLog也是封装到transaction中,在写journal的时候一起写到日志磁盘上,最后在写本地缓存的时候遍历transaction里的内容,将PGLog相关的东西写到LevelDB里,从而完成该OSD上PGLog的更新操作。
3.1 PGLog更新到journal
3.1.1 写IO序列化到transaction
在《OSD读写流程》里描述了主OSD上的读写处理流程,这里就不说明。在ReplicatedPG::do_osd_ops()函数里根据类型CEPH_OSD_OP_WRITE就会进行封装写IO到transaction的操作(即: 将要写的数据encode到ObjectStore::Transaction::tbl里,这是个bufferlist,encode时都先将op编码进去,这样后续在处理时就可以根据op来操作。注意这里的encode其实就是序列化操作)。
这个transaction经过的过程如下:

3.1.2 PGLog序列化到transaction
- 在ReplicatedPG::do_op()中创建了一个对象修改操作的上下文OpContext,然后在ReplicatedPG::execute_ctx()中完成PGLog日志版本等的设置:
eversion_t get_next_version() const {eversion_t at_version(get_osdmap()->get_epoch(),pg_log.get_head().version+1);assert(at_version > info.last_update);assert(at_version > pg_log.get_head());return at_version;
}void ReplicatedPG::do_op(OpRequestRef& op)
{...OpContext *ctx = new OpContext(op, m->get_reqid(), m->ops, obc, this);...execute_ctx(ctx);...
}void ReplicatedPG::execute_ctx(OpContext *ctx){....// versionctx->at_version = get_next_version();ctx->mtime = m->get_mtime();...int result = prepare_transaction(ctx);...RepGather *repop = new_repop(ctx, obc, rep_tid);issue_repop(repop, ctx);eval_repop(repop);....
}void ReplicatedPG::issue_repop(RepGather *repop, OpContext *ctx)
{...Context *on_all_commit = new C_OSD_RepopCommit(this, repop);Context *on_all_applied = new C_OSD_RepopApplied(this, repop);Context *onapplied_sync = new C_OSD_OndiskWriteUnlock(ctx->obc,ctx->clone_obc,unlock_snapset_obc ? ctx->snapset_obc : ObjectContextRef());pgbackend->submit_transaction(soid,ctx->at_version,std::move(ctx->op_t),pg_trim_to,min_last_complete_ondisk,ctx->log,ctx->updated_hset_history,onapplied_sync,on_all_applied,on_all_commit,repop->rep_tid,ctx->reqid,ctx->op);
}上面我们看到submit_transaction()的第三个参数传递的就是ctx->opt_t,在prepare_transaction()中我们已经将要修改的对象数据打包放入了该transaction。
- 在ReplicatedPG::prepare_transaction()里调用ReplicatedPG::finish_ctx,然后finish_ctx函数里就会调用ctx->log.push_back(),在此就会构造pg_log_entry_t插入到vector log里;
int ReplicatedPG::prepare_transaction(OpContext *ctx)
{...finish_ctx(ctx,ctx->new_obs.exists ? pg_log_entry_t::MODIFY :pg_log_entry_t::DELETE);
}void ReplicatedPG::finish_ctx(OpContext *ctx, int log_op_type, bool maintain_ssc,bool scrub_ok)
{// append to logctx->log.push_back(pg_log_entry_t(log_op_type, soid, ctx->at_version,ctx->obs->oi.version,ctx->user_at_version, ctx->reqid,ctx->mtime));...
}/*** pg_log_entry_t - single entry/event in pg log** (src/osd/osd_types.h)*/
struct pg_log_entry_t {// describes state for a locally-rollbackable entryObjectModDesc mod_desc;bufferlist snaps; // only for clone entrieshobject_t soid;osd_reqid_t reqid; // caller+tid to uniquely identify requestvector<pair<osd_reqid_t, version_t> > extra_reqids;eversion_t version, prior_version, reverting_to;version_t user_version; // the user version for this entryutime_t mtime; // this is the _user_ mtime, mind you__s32 op;bool invalid_hash; // only when decoding sobject_t based entriesbool invalid_pool; // only when decoding pool-less hobject based entriespg_log_entry_t(): user_version(0), op(0),invalid_hash(false), invalid_pool(false) {}pg_log_entry_t(int _op, const hobject_t& _soid,const eversion_t& v, const eversion_t& pv,version_t uv,const osd_reqid_t& rid, const utime_t& mt): soid(_soid), reqid(rid), version(v), prior_version(pv), user_version(uv),mtime(mt), op(_op), invalid_hash(false), invalid_pool(false){}
};上面我们可以看到将ctx->at_version传递给了pg_log_entry_t.version; 将ctx->obs->oi.version传递给了pg_log_entry_t.prior_version;将ctx->user_at_version传递给了pg_log_entry_t.user_version。
对于ctx->obs->oi.version,其值是在如下函数中赋予的:
void ReplicatedPG::do_op(OpRequestRef& op)
{...int r = find_object_context(oid, &obc, can_create,m->has_flag(CEPH_OSD_FLAG_MAP_SNAP_CLONE),&missing_oid);...execute_ctx(ctx);...
}- 在ReplicatedBackend::submit_transaction()里调用parent->log_operation()将PGLog序列化到transaction里。在PG::append_log()里将PGLog相关信息序列化到transaction里。
//issue_repop()即处理replication operations,
void ReplicatedPG::issue_repop(RepGather *repop, OpContext *ctx)
{...Context *on_all_commit = new C_OSD_RepopCommit(this, repop);Context *on_all_applied = new C_OSD_RepopApplied(this, repop);Context *onapplied_sync = new C_OSD_OndiskWriteUnlock(ctx->obc,ctx->clone_obc,unlock_snapset_obc ? ctx->snapset_obc : ObjectContextRef());pgbackend->submit_transaction(soid,ctx->at_version,std::move(ctx->op_t),pg_trim_to,min_last_complete_ondisk,ctx->log,ctx->updated_hset_history,onapplied_sync,on_all_applied,on_all_commit,repop->rep_tid,ctx->reqid,ctx->op);...
}void ReplicatedBackend::submit_transaction(const hobject_t &soid,const eversion_t &at_version,PGTransactionUPtr &&_t,const eversion_t &trim_to,const eversion_t &trim_rollback_to,const vector<pg_log_entry_t> &log_entries,boost::optional<pg_hit_set_history_t> &hset_history,Context *on_local_applied_sync,Context *on_all_acked,Context *on_all_commit,ceph_tid_t tid,osd_reqid_t reqid,OpRequestRef orig_op)
{std::unique_ptr<RPGTransaction> t(static_cast<RPGTransaction*>(_t.release()));assert(t);ObjectStore::Transaction op_t = t->get_transaction();...parent->log_operation(log_entries,hset_history,trim_to,trim_rollback_to,true,op_t);....
}//src/osd/ReplicatedPG.h
void log_operation(const vector<pg_log_entry_t> &logv,boost::optional<pg_hit_set_history_t> &hset_history,const eversion_t &trim_to,const eversion_t &trim_rollback_to,bool transaction_applied,ObjectStore::Transaction &t) {if (hset_history) {info.hit_set = *hset_history;dirty_info = true;}append_log(logv, trim_to, trim_rollback_to, t, transaction_applied);
}void PG::append_log(const vector<pg_log_entry_t>& logv,eversion_t trim_to,eversion_t trim_rollback_to,ObjectStore::Transaction &t,bool transaction_applied)
{//进行日志的序列化
}上面我们注意到对于PGLog的处理,PGLog所对应的Transaction与实际的对象数据对应的Transaction是相同的。
- 序列化ctx->log中的日志
在ReplicatedPG::prepare_transaction()中我们构造了pg_log_entry_t对象放入了ctx->log中。接着在如下函数中将会把这些与PGLog相关的信息序列化到ctx->op_t这一transaction中:
void PG::append_log(const vector<pg_log_entry_t>& logv,eversion_t trim_to,eversion_t trim_rollback_to,ObjectStore::Transaction &t,bool transaction_applied)
{/* The primary has sent an info updating the history, but it may not* have arrived yet. We want to make sure that we cannot remember this* write without remembering that it happened in an interval which went* active in epoch history.last_epoch_started.* * (注: 在PG完成Peering之后,会由Primary发送消息来更新副本PG的history,但由于网络延时等,* 可能存在相应的更新消息未到达的情况。这里我们要确保: 只有在PG进入active epoch之后的写操作* 才是有效的(该epoch记录在history.last_epoch_started字段中)。*/if (info.last_epoch_started != info.history.last_epoch_started) {info.history.last_epoch_started = info.last_epoch_started;}dout(10) << "append_log " << pg_log.get_log() << " " << logv << dendl;for (vector<pg_log_entry_t>::const_iterator p = logv.begin();p != logv.end();++p) {add_log_entry(*p);}// update the local pg, pg logdirty_info = true;write_if_dirty(t);
}void PG::add_log_entry(const pg_log_entry_t& e)
{// raise last_complete only if we were previously up to dateif (info.last_complete == info.last_update)info.last_complete = e.version;// raise last_update.assert(e.version > info.last_update);info.last_update = e.version;// raise user_version, if it increased (it may have not get bumped// by all logged updates)if (e.user_version > info.last_user_version)info.last_user_version = e.user_version;// log mutationpg_log.add(e);dout(10) << "add_log_entry " << e << dendl;
}//src/osd/pglog.h
void add(const pg_log_entry_t& e) {mark_writeout_from(e.version);log.add(e);
}在上面PG::append_log()函数中,首先调用PG::add_log_entry()将PGLog添加到pg_log中进行缓存,以方便查询。之后再调用write_if_dirty():
void PG::write_if_dirty(ObjectStore::Transaction& t)
{map<string,bufferlist> km;if (dirty_big_info || dirty_info)prepare_write_info(&km);pg_log.write_log(t, &km, coll, pgmeta_oid, pool.info.require_rollback());if (!km.empty())t.omap_setkeys(coll, pgmeta_oid, km);
}在PG::write_if_dirty()中,由于在PG::append_log()时将dirty_info设置为了true,因此肯定先调用prepare_write_info()函数,该函数可能会将当前的epoch信息、pg_info信息打包放入km中。之后如果km不为空,则调用t.omap_setkeys()将相关信息打包进transaction中。
注:通过上面我们可以看到,PGLog中除了包含当前所更新的object信息外,还可能包含如下:
// prefix pgmeta_oid keys with _ so that PGLog::read_log() can
// easily skip themconst string infover_key("_infover");
const string info_key("_info");
const string biginfo_key("_biginfo");
const string epoch_key("_epoch");现在我们来看pg_log.write_log():
void PGLog::write_log(ObjectStore::Transaction& t,map<string,bufferlist> *km,const coll_t& coll, const ghobject_t &log_oid,bool require_rollback)
{if (is_dirty()) {dout(5) << "write_log with: "<< "dirty_to: " << dirty_to<< ", dirty_from: " << dirty_from<< ", dirty_divergent_priors: "<< (dirty_divergent_priors ? "true" : "false")<< ", divergent_priors: " << divergent_priors.size()<< ", writeout_from: " << writeout_from<< ", trimmed: " << trimmed<< dendl;_write_log(t, km, log, coll, log_oid, divergent_priors,dirty_to,dirty_from,writeout_from,trimmed,dirty_divergent_priors,!touched_log,require_rollback,(pg_log_debug ? &log_keys_debug : 0));undirty();} else {dout(10) << "log is not dirty" << dendl;}
}void PGLog::_write_log(ObjectStore::Transaction& t,map<string,bufferlist> *km,pg_log_t &log,const coll_t& coll, const ghobject_t &log_oid,map<eversion_t, hobject_t> &divergent_priors,eversion_t dirty_to,eversion_t dirty_from,eversion_t writeout_from,const set<eversion_t> &trimmed,bool dirty_divergent_priors,bool touch_log,bool require_rollback,set<string> *log_keys_debug)
{...for (list<pg_log_entry_t>::iterator p = log.log.begin();p != log.log.end() && p->version <= dirty_to; ++p) {bufferlist bl(sizeof(*p) * 2);p->encode_with_checksum(bl);(*km)[p->get_key_name()].claim(bl);}for (list<pg_log_entry_t>::reverse_iterator p = log.log.rbegin();p != log.log.rend() &&(p->version >= dirty_from || p->version >= writeout_from) &&p->version >= dirty_to; ++p) {bufferlist bl(sizeof(*p) * 2);p->encode_with_checksum(bl);(*km)[p->get_key_name()].claim(bl);}...
}
void pg_log_entry_t::encode_with_checksum(bufferlist& bl) const
{bufferlist ebl(sizeof(*this)*2);encode(ebl);__u32 crc = ebl.crc32c(0);::encode(ebl, bl);::encode(crc, bl);
}通过上面,我们可以看到在PGLog::_write_log()函数中将pg_log_entry_t数据放入了km对应的bufferlist中,然后PG::write_if_dirty()函数的最后将这些bufferlist打包进transaction中。
注: 这里PGLog所在的transaction与实际的object对象数据所在的transaction是同一个
- 完成PGLog日志数据、object对象数据的写入
void ReplicatedBackend::submit_transaction(const hobject_t &soid,const eversion_t &at_version,PGTransactionUPtr &&_t,const eversion_t &trim_to,const eversion_t &trim_rollback_to,const vector<pg_log_entry_t> &log_entries,boost::optional<pg_hit_set_history_t> &hset_history,Context *on_local_applied_sync,Context *on_all_acked,Context *on_all_commit,ceph_tid_t tid,osd_reqid_t reqid,OpRequestRef orig_op)
{...op_t.register_on_applied_sync(on_local_applied_sync);op_t.register_on_applied(parent->bless_context(new C_OSD_OnOpApplied(this, &op)));op_t.register_on_commit(parent->bless_context(new C_OSD_OnOpCommit(this, &op)));vector<ObjectStore::Transaction> tls;tls.push_back(std::move(op_t));parent->queue_transactions(tls, op.op);
}void ReplicatedPG::queue_transactions(vector<ObjectStore::Transaction>& tls, OpRequestRef op) {osd->store->queue_transactions(osr.get(), tls, 0, 0, 0, op, NULL);
}在前面的步骤中完成了Transaction的构建,在这里调用ReplicatedPG::queue_transactions()来写入到ObjectStore中。
3.1.3 Trim Log
前面说到PGLog的记录数是有限制的,正常情况下默认是3000条(由参数osd_min_pg_log_entries控制),PG降级情况下默认增加到10000条(由参数osd_max_pg_log_entries)。当达到限制时,就会trim log进行截断。
在ReplicatedPG::execute_ctx()里调用ReplicatedPG::calc_trim_to()来进行计算。计算的时候从log的tail(tail指向最老的记录的前一个)开始,需要trim的条数为log.head - log.tail - max_entries。但是trim的时候需要考虑到min_last_complete_ondisk(这个表示各个副本上last_complete的最小版本,是主OSD在收到3个副本都完成时再进行计算的,也就是计算last_complete_ondisk和其他副本OSD上的last_complete_ondisk,即peer_last_complete_ondisk的最小值得到min_last_complete_ondisk),也就是说trim的时候不能超过min_last_complete_ondisk,因为超过了也trim掉的话就会导致没有更新到磁盘上的pg log丢失。所以说可能存在某个时刻,pglog的记录数超过max_entries。例如:
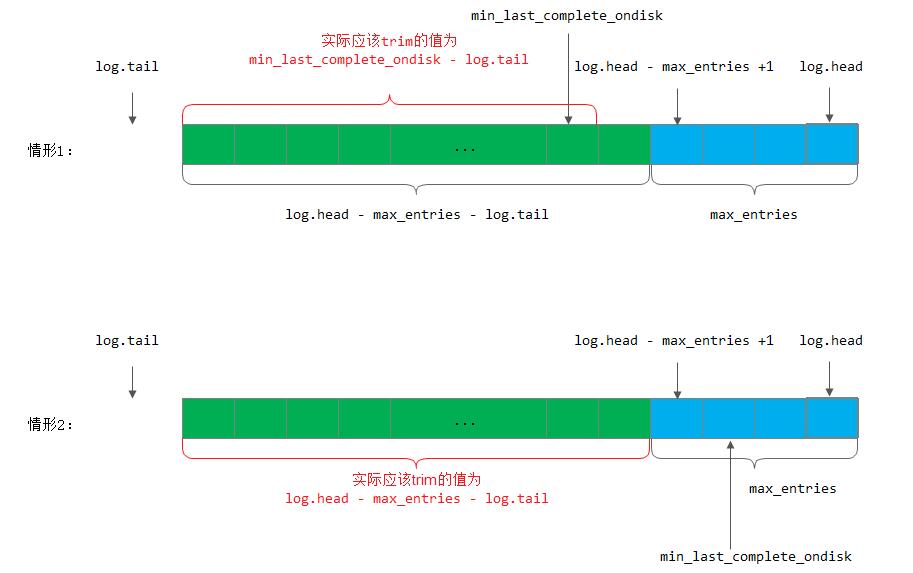
在ReplicatedPG::log_operation()的trim_to就是pg_trim_to,trim_rollback_to就是min_last_complete_ondisk。log_operation()里调用pg_log.trim(&handler, trim_to, info)进行trim,会将需要trim的key加入到PGLog::trimmed这个set里。然后在_write_log()里将trimmed中的元素插入到to_remove里,最后再调用t.omap_rmkeys()序列化到transaction的bufferlist里。
void ReplicatedPG::execute_ctx(OpContext *ctx){calc_trim_to();
}void ReplicatedPG::log_operation(const vector<pg_log_entry_t> &logv,boost::optional<pg_hit_set_history_t> &hset_history,const eversion_t &trim_to,const eversion_t &trim_rollback_to,bool transaction_applied,ObjectStore::Transaction &t) {if (hset_history) {info.hit_set = *hset_history;dirty_info = true;}append_log(logv, trim_to, trim_rollback_to, t, transaction_applied);
}void PG::append_log(const vector<pg_log_entry_t>& logv,eversion_t trim_to,eversion_t trim_rollback_to,ObjectStore::Transaction &t,bool transaction_applied){pg_log.trim(&handler, trim_to, info);write_if_dirty(t);
}void PGLog::_write_log(ObjectStore::Transaction& t,map<string,bufferlist> *km,pg_log_t &log,const coll_t& coll, const ghobject_t &log_oid,map<eversion_t, hobject_t> &divergent_priors,eversion_t dirty_to,eversion_t dirty_from,eversion_t writeout_from,const set<eversion_t> &trimmed,bool dirty_divergent_priors,bool touch_log,bool require_rollback,set<string> *log_keys_debug){set<string> to_remove;for (set<eversion_t>::const_iterator i = trimmed.begin();i != trimmed.end();++i) {to_remove.insert(i->get_key_name());if (log_keys_debug) {assert(log_keys_debug->count(i->get_key_name()));log_keys_debug->erase(i->get_key_name());}}...if (!to_remove.empty())t.omap_rmkeys(coll, log_oid, to_remove);
}3.1.4 PGLog写到journal盘
PGLog写到Journal盘上就是journal一样的流程,具体如下:
- 在ReplicatedBackend::submit_transaction()调用log_operation()将PGLog序列化到transaction里,然后调用queue_transactions()传到后续处理;
void ReplicatedBackend::submit_transaction(...)
{...parent->log_operation(log_entries,hset_history,trim_to,trim_rollback_to,true,op_t);...vector<ObjectStore::Transaction> tls;tls.push_back(std::move(op_t));parent->queue_transactions(tls, op.op);
}这里ReplicatedPG实现了PGBackend::Listener接口:
class ReplicatedPG : public PG, public PGBackend::Listener {
};ReplicatedPG::ReplicatedPG(OSDService *o, OSDMapRef curmap,const PGPool &_pool, spg_t p) :PG(o, curmap, _pool, p),pgbackend(PGBackend::build_pg_backend(_pool.info, curmap, this, coll_t(p), ch, o->store, cct)),object_contexts(o->cct, g_conf->osd_pg_object_context_cache_count),snapset_contexts_lock("ReplicatedPG::snapset_contexts"),backfills_in_flight(hobject_t::Comparator(true)),pending_backfill_updates(hobject_t::Comparator(true)),new_backfill(false),temp_seq(0),snap_trimmer_machine(this)
{ missing_loc.set_backend_predicates(pgbackend->get_is_readable_predicate(),pgbackend->get_is_recoverable_predicate());snap_trimmer_machine.initiate();
}因此这里调用的parent->queue_transactions()就是ReplicatedPG::queue_transactions()
- 调用到FileStore::queue_transactions()里,就将list构造成一个FileStore::Op,对应的list放到FileStore::Op::tls里
void ReplicatedPG::queue_transactions(vector<ObjectStore::Transaction>& tls, OpRequestRef op) {osd->store->queue_transactions(osr.get(), tls, 0, 0, 0, op, NULL);
}int ObjectStore::queue_transactions(Sequencer *osr, vector<Transaction>& tls,Context *onreadable, Context *ondisk=0,Context *onreadable_sync=0,TrackedOpRef op = TrackedOpRef(),ThreadPool::TPHandle *handle = NULL) {assert(!tls.empty());tls.back().register_on_applied(onreadable);tls.back().register_on_commit(ondisk);tls.back().register_on_applied_sync(onreadable_sync);return queue_transactions(osr, tls, op, handle);
}int FileStore::queue_transactions(Sequencer *posr, vector<Transaction>& tls,TrackedOpRef osd_op,ThreadPool::TPHandle *handle)
{...if (journal && journal->is_writeable() && !m_filestore_journal_trailing) {Op *o = build_op(tls, onreadable, onreadable_sync, osd_op);...}...
}- 接着在FileJournal::prepare_entry()中遍历vector &tls,将ObjectStore::Transaction encode到一个bufferlist里(记为tbl)
int FileJournal::prepare_entry(vector<ObjectStore::Transaction>& tls, bufferlist* tbl) {}- 然后在JournalingObjectStore::_op_journal_transactions()函数里调用FileJournal::submit_entry(),将bufferlist构造成write_item放到writeq里
void JournalingObjectStore::_op_journal_transactions(bufferlist& tbl, uint32_t orig_len, uint64_t op,Context *onjournal, TrackedOpRef osd_op)
{if (osd_op.get())dout(10) << "op_journal_transactions " << op << " reqid_t "<< (static_cast<OpRequest *>(osd_op.get()))->get_reqid() << dendl;elsedout(10) << "op_journal_transactions " << op << dendl;if (journal && journal->is_writeable()) {journal->submit_entry(op, tbl, orig_len, onjournal, osd_op);} else if (onjournal) {apply_manager.add_waiter(op, onjournal);}
}void FileJournal::submit_entry(uint64_t seq, bufferlist& e, uint32_t orig_len,Context *oncommit, TrackedOpRef osd_op)
{...
}- 接着在FileJournal::write_thread_entry()函数里,会从writeq里取出write_item,放到另一个bufferlist里
void FileJournal::write_thread_entry()
{...bufferlist bl;int r = prepare_multi_write(bl, orig_ops, orig_bytes);...
}- 最后调用do_write()将bufferlist的内容异步写到磁盘上(也就是写journal)
void FileJournal::write_thread_entry()
{...#ifdef HAVE_LIBAIOif (aio)do_aio_write(bl);elsedo_write(bl);#elsedo_write(bl);#endif...
}3.1.5 PGLog写入leveldb
在上面完成了journal盘的写操作之后,接着就会有另外的线程异步的将这些日志数据写成实际的object对象、pglog等。如下我们主要关注对pglog的持久化操作:
在《OSD读写流程》里描述到是在FileStore::_do_op()里进行写数据到本地缓存的操作。将pglog写入到leveldb里的操作也是从这里出发的,会根据不同的op类型来进行不同的操作。
void FileStore::_do_op(OpSequencer *osr, ThreadPool::TPHandle &handle)
{if (!m_disable_wbthrottle) {wbthrottle.throttle();}// inject a stall?if (g_conf->filestore_inject_stall) {int orig = g_conf->filestore_inject_stall;dout(5) << "_do_op filestore_inject_stall " << orig << ", sleeping" << dendl;for (int n = 0; n < g_conf->filestore_inject_stall; n++)sleep(1);g_conf->set_val("filestore_inject_stall", "0");dout(5) << "_do_op done stalling" << dendl;}osr->apply_lock.Lock();Op *o = osr->peek_queue();apply_manager.op_apply_start(o->op);dout(5) << "_do_op " << o << " seq " << o->op << " " << *osr << "/" << osr->parent << " start" << dendl;int r = _do_transactions(o->tls, o->op, &handle);apply_manager.op_apply_finish(o->op);dout(10) << "_do_op " << o << " seq " << o->op << " r = " << r << ", finisher " << o->onreadable << " " << o->onreadable_sync << dendl;o->tls.clear();}int FileStore::_do_transactions(vector<Transaction> &tls,uint64_t op_seq,ThreadPool::TPHandle *handle)
{
}1) 比如OP_OMAP_SETKEYS(PGLog写入leveldb就是根据这个key)
void FileStore::_do_transaction(Transaction& t, uint64_t op_seq, int trans_num,ThreadPool::TPHandle *handle){switch (op->op) {case Transaction::OP_OMAP_SETKEYS:{coll_t cid = i.get_cid(op->cid);ghobject_t oid = i.get_oid(op->oid);_kludge_temp_object_collection(cid, oid);map<string, bufferlist> aset;i.decode_attrset(aset);tracepoint(objectstore, omap_setkeys_enter, osr_name);r = _omap_setkeys(cid, oid, aset, spos);tracepoint(objectstore, omap_setkeys_exit, r);}break; }
}int FileStore::_omap_setkeys(const coll_t& cid, const ghobject_t &hoid,const map<string, bufferlist> &aset,const SequencerPosition &spos) {
{...r = object_map->set_keys(hoid, aset, &spos);
}int DBObjectMap::set_keys(const ghobject_t &oid,const map<string, bufferlist> &set,const SequencerPosition *spos){t->set(user_prefix(header), set);return db->submit_transaction(t);
}int LevelDBStore::submit_transaction(KeyValueDB::Transaction t)
{utime_t start = ceph_clock_now(g_ceph_context);LevelDBTransactionImpl * _t =static_cast<LevelDBTransactionImpl *>(t.get());leveldb::Status s = db->Write(leveldb::WriteOptions(), &(_t->bat));utime_t lat = ceph_clock_now(g_ceph_context) - start;logger->inc(l_leveldb_txns);logger->tinc(l_leveldb_submit_latency, lat);return s.ok() ? 0 : -1;
}2) 再比如OP_OMAP_RMKEYS(trim pglog的时候就是用到了这个key)
//前面流程同上int DBObjectMap::rm_keys(const ghobject_t &oid,const set<string> &to_clear,const SequencerPosition *spos)
{t->rmkeys(user_prefix(header), to_clear);db->submit_transaction(t);
}PGLog封装到transaction里面和journal一起写到盘上的好处: 如果osd异常崩溃时,journal写完成了,但是数据有可能没有写到磁盘上,相应的pg log也没有写到leveldb里,这样在OSD再启动起来时,就会进行journal replay,这样从journal里就能读出完整的transaction,然后再进行事务的处理,也就是将数据写到盘上,pglog写到leveldb里。
4. PGLog的查看方法
具体的PGLog内容可以使用如下工具查看:
4.1 某一个PG的整体pglog信息
1) 停掉运行中的osd,获取osd的挂载路径,使用如下命令获取pg列表
# ceph-objectstore-tool --data-path /var/lib/ceph/osd/ceph-13/ --journal-path /dev/disk/by-id/virtio-ca098220-3a26-404a-8-part1 --type filestore --op list-pgs
41.2
32.4
39.4
41.a
53.1ab
53.5a
54.31
42.d
53.1da
41.d2
41.9f
41.bd
36.0
...注意: 对于type为filestore类型,我们还必须指定--journal-path选项;而对于bluestore类型,则不需要指定该选项。
2) 获取具体的pg_log_t信息
# ceph-objectstore-tool --data-path /var/lib/ceph/osd/ceph-13/ --journal-path /dev/disk/by-id/virtio-ca098220-3a26-404a-8-part1 --type filestore --pgid 53.62 --op log
{"pg_log_t": {"head": "18042'298496","tail": "9354'295445","log": [{"op": "modify ","object": "53:462f48b1:::5c470d18-0d9e-4a34-8a6c-7a6d64784c3e.355583.2__multipart_487ead6c025ac8a2dce846bafd222c11_23.2~g0pDMHqf8sMPKcIj1WoP79w2gNICzeA.1:h
ead","version": "9354'295446","prior_version": "9354'295445","reqid": "client.955398.0:2032","extra_reqids": [],"mtime": "2019-12-12 14:38:07.371069","mod_desc": {"object_mod_desc": {"can_local_rollback": false,"rollback_info_completed": false,"ops": []}}},{"op": "modify ","object": "53:462f48b1:::5c470d18-0d9e-4a34-8a6c-7a6d64784c3e.355583.2__multipart_487ead6c025ac8a2dce846bafd222c11_23.2~g0pDMHqf8sMPKcIj1WoP79w2gNICzeA.1:h
ead","version": "9354'295447","prior_version": "9354'295446","reqid": "client.955398.0:2033","extra_reqids": [],"mtime": "2019-12-12 14:38:07.373229","mod_desc": {"object_mod_desc": {"can_local_rollback": false,"rollback_info_completed": false,"ops": []}}},....注: 对于某一些PG,可能查询出来pg log信息为空。
3) 获取具体的pg_info_t信息
# ceph-objectstore-tool --data-path /var/lib/ceph/osd/ceph-13/ --journal-path /dev/disk/by-id/virtio-ca098220-3a26-404a-8-part1 --type filestore --pgid 53.62 --op info
{"pgid": "53.62","last_update": "18042'298496","last_complete": "18042'298496","log_tail": "9354'295445","last_user_version": 298496,"last_backfill": "MAX","last_backfill_bitwise": 1,"purged_snaps": "[]","history": {"epoch_created": 748,"last_epoch_started": 18278,"last_epoch_clean": 18278,"last_epoch_split": 0,"last_epoch_marked_full": 431,"same_up_since": 18276,"same_interval_since": 18277,"same_primary_since": 17958,"last_scrub": "17833'298491","last_scrub_stamp": "2020-06-03 15:16:15.370988","last_deep_scrub": "17833'298491","last_deep_scrub_stamp": "2020-06-03 15:16:15.370988","last_clean_scrub_stamp": "2020-06-03 15:16:15.370988"},"stats": {"version": "18017'298495","reported_seq": "545855","reported_epoch": "18042","state": "active+clean","last_fresh": "2020-06-05 19:23:43.328125","last_change": "2020-06-05 19:23:43.328125","last_active": "2020-06-05 19:23:43.328125","last_peered": "2020-06-05 19:23:43.328125","last_clean": "2020-06-05 19:23:43.328125","last_became_active": "2020-06-05 19:23:43.327839","last_became_peered": "2020-06-05 19:23:43.327839","last_unstale": "2020-06-05 19:23:43.328125","last_undegraded": "2020-06-05 19:23:43.328125","last_fullsized": "2020-06-05 19:23:43.328125","mapping_epoch": 18276,"log_start": "9354'295445","ondisk_log_start": "9354'295445","created": 748,"last_epoch_clean": 18042,"parent": "0.0","parent_split_bits": 8,"last_scrub": "17833'298491","last_scrub_stamp": "2020-06-03 15:16:15.370988","last_deep_scrub": "17833'298491","last_deep_scrub_stamp": "2020-06-03 15:16:15.370988","last_clean_scrub_stamp": "2020-06-03 15:16:15.370988","log_size": 3050,"ondisk_log_size": 3050,"stats_invalid": false,"dirty_stats_invalid": false,"omap_stats_invalid": false,"hitset_stats_invalid": false,"hitset_bytes_stats_invalid": false,"pin_stats_invalid": false,"stat_sum": {"num_bytes": 967900926,"num_objects": 23059,"num_object_clones": 0,"num_object_copies": 69180,"num_objects_missing_on_primary": 0,"num_objects_missing": 0,"num_objects_degraded": 0,"num_objects_misplaced": 0,"num_objects_unfound": 0,"num_objects_dirty": 23059,"num_whiteouts": 0,"num_read": 35977,"num_read_kb": 1905404,"num_write": 244022,"num_write_kb": 3560580,"num_scrub_errors": 0,"num_shallow_scrub_errors": 0,"num_deep_scrub_errors": 0,"num_objects_recovered": 1833,"num_bytes_recovered": 333589036,"num_keys_recovered": 0,"num_objects_omap": 0,"num_objects_hit_set_archive": 0,"num_bytes_hit_set_archive": 0,"num_flush": 0,"num_flush_kb": 0,"num_evict": 0,"num_evict_kb": 0,"num_promote": 0,"num_flush_mode_high": 0,"num_flush_mode_low": 0,"num_evict_mode_some": 0,"num_evict_mode_full": 0,"num_objects_pinned": 0},"up": [12,14,13],"acting": [12,14,13],"blocked_by": [],"up_primary": 12,"acting_primary": 12},"empty": 0,"dne": 0,"incomplete": 0,"last_epoch_started": 18278,"hit_set_history": {"current_last_update": "0'0","history": []}
}4.2 追踪单个op的pglog
1) 查看某个object映射到的PG
采用ceph osd map pool-name object-name-id命令查看object映射到的PG,例如:
# ceph osd map oss-uat.rgw.buckets.data 135882fc-2865-43ab-9f71-7dd4b2095406.20037185.269__multipart_批量上传走joss文件 -003-KZyxg.docx.VLRHO5x1l3nV4-v5W4r6YA2Fkqlfwj3.107
osdmap e16540 pool 'oss-uat.rgw.buckets.data' (189) object '-003-KZyxg.docx.VLRHO5x1l3nV4-v5W4r6YA2Fkqlfwj3.107/135882fc-2865-43ab-9f71-7dd4b2095406.20037185.269__multipart_批量上传走joss文件' -> pg 189.db7b914a (189.14a) -> up ([66,9,68], p66) acting ([66,9,68], p66)具体查看方法请参看《如何在ceph中定位文件》
2) 确认PG所在的OSD
# ceph pg dump pgs_brief |grep ^19|grep 19.3f
3) 通过以上两步找到会落入到指定pg的对象,以该对象为名将指定文件put到资源池中
# rados -p oss-uat.rgw.buckets.data put 135882fc-2865-43ab-9f71-7dd4b2095406.20037185.269__multipart_批量上传走joss文件 -003-KZyxg.docx.VLRHO5x1l3nV4-v5W4r6YA2Fkqlfwj3.107 test.file
4) 从该pg所在的osd集合中任意选择一个down掉,查看写入的关于135882fc-2865-43ab-9f71...的log信息
# ceph-objectstore-tool --data-path /var/lib/ceph/osd/ceph-66/ --journal-path /dev/disk/by-id/virtio-ca098220-3a26-404a-8-part1 --type filestore --pgid 189.14a --op log5. PGLog如何参与恢复
根据PG的状态机(主要是pg 从reset -> activte过程中的状态转换,其中包括pg从peering到activate 以及epoch变化时pg 状态恢复的处理流程。如下图所示)我们可以看到,

PG状态恢复为active的过程需要区分Primary和Replicated两种,因为不论是pg还是osd的消息都是由Primary主导,再分发给从组件。同时PGLog参与恢复主要体现在ceph进行peering的时候建立missing列表来标记过时的数据,以便于对这些数据进行恢复。故障OSD重新上线后,PG就会标记为peering状态并暂停处理请求。
对于故障OSD所拥有的Primary PG
-
它作为这部分数据
“权责”主体,需要发送查询PG元数据请求给所有属于该PG的Replicate角色节点; -
该PG的Replicate角色节点实际上在故障OSD下线期间成为了Primary角色并维护了
权威的PGLog,该PG在得到故障OSD的Primary PG的查询请求后会发送响应; -
Primary PG通过对比Replicate PG发送的元数据 和 PG版本信息后发现处于落后状态,因此它会合并得到的PGLog并建立
权威PGLog,同时会建立missing列表来标记过时数据; -
Primary PG在完成
权威PGLog的建立后,就可以标志自己处于Active状态。
对于故障OSD所拥有的Replicate PG
-
这时上线后故障OSD的Replicate PG会得到Primary PG的查询请求,发送自己这份
“过时”的元数据和PGLog; -
Primary PG对比数据后发现该PG落后并且过时,然后通过PGLog建立missing列表(注: 这里其实是peer_missing列表);
-
Primary PG标记自己处于Active状态;
Peering过程中涉及到PGLog(pg_info、pg_log)的主要步骤
1) GetInfo
PG的Primary OSD通过发送消息获取各个Replicate OSD的pg_info信息。在收到各个Replicate OSD的pg_info后,会调用PG::proc_replica_info()处理副本OSD的pg_info,在这里面会调用info.history.merge()合并Replicate OSD发过来的pg_info信息,合并的原则就是更新为最新的字段(比如last_epoch_started和last_epoch_clean都变成最新的)
bool PG::proc_replica_info(pg_shard_t from, const pg_info_t &oinfo, epoch_t send_epoch)
{...unreg_next_scrub();if (info.history.merge(oinfo.history))dirty_info = true;reg_next_scrub();...
}bool merge(const pg_history_t &other) {// Here, we only update the fields which cannot be calculated from the OSDmap.bool modified = false;if (epoch_created < other.epoch_created) {epoch_created = other.epoch_created;modified = true;}if (last_epoch_started < other.last_epoch_started) {last_epoch_started = other.last_epoch_started;modified = true;}if (last_epoch_clean < other.last_epoch_clean) {last_epoch_clean = other.last_epoch_clean;modified = true;}if (last_epoch_split < other.last_epoch_split) {last_epoch_split = other.last_epoch_split; modified = true;}if (last_epoch_marked_full < other.last_epoch_marked_full) {last_epoch_marked_full = other.last_epoch_marked_full;modified = true;}if (other.last_scrub > last_scrub) {last_scrub = other.last_scrub;modified = true;}if (other.last_scrub_stamp > last_scrub_stamp) {last_scrub_stamp = other.last_scrub_stamp;modified = true;}if (other.last_deep_scrub > last_deep_scrub) {last_deep_scrub = other.last_deep_scrub;modified = true;}if (other.last_deep_scrub_stamp > last_deep_scrub_stamp) {last_deep_scrub_stamp = other.last_deep_scrub_stamp;modified = true;}if (other.last_clean_scrub_stamp > last_clean_scrub_stamp) {last_clean_scrub_stamp = other.last_clean_scrub_stamp;modified = true;}return modified;
}2) GetLog
根据pg_info的比较,选择一个拥有权威日志的OSD(auth_log_shard),如果Primary OSD不是拥有权威日志的OSD,就去该OSD上获取权威日志。
PG::RecoveryState::GetLog::GetLog(my_context ctx): my_base(ctx),NamedState(context< RecoveryMachine >().pg->cct, "Started/Primary/Peering/GetLog"),msg(0)
{...// adjust acting?if (!pg->choose_acting(auth_log_shard, false,&context< Peering >().history_les_bound)){}...
}选取拥有权威日志的OSD时,遵循3个原则(在find_best_info()函数里)
/*** find_best_info** Returns an iterator to the best info in infos sorted by:* 1) Prefer newer last_update* 2) Prefer longer tail if it brings another info into contiguity* 3) Prefer current primary*/
map<pg_shard_t, pg_info_t>::const_iterator PG::find_best_info(const map<pg_shard_t, pg_info_t> &infos,bool restrict_to_up_acting,bool *history_les_bound) const
{...
}也就是说对比各个OSD的pg_info_t,谁的last_update大,就选谁; 如果last_update一样大,则谁的log_tail小,就选谁;如果log_tail也一样,就选当前的Primary OSD
如果Primary OSD不是拥有权威日志的OSD,则需要去拥有权威日志的OSD上去拉取权威日志,收到权威日志后,会调用proc_master_log()将权威日志合并到本地pg log。在merge权威日志到本地pg log的过程中,会将merge的pg_log_entry_t对应的oid和eversion放到missing列表里,这个missing列表里的对象就是Primary OSD缺失的对象,后续在recovery的时候需要从其他OSD pull的。
void PG::proc_master_log(ObjectStore::Transaction& t, pg_info_t &oinfo,pg_log_t &olog, pg_missing_t& omissing, pg_shard_t from)
{ ...merge_log(t, oinfo, olog, from);...
}3) GetMissing
拉取其他Replicate OSD的pg log(或者部分获取,或者全部获取FULL_LOG),通过与本地的auth log对比,调用proc_replica_log()处理日志,会将Replicate OSD里缺失的对象放到peer_missing列表里,以用于后续recovery过程的依据。
注意: 实际上是在PG::activate()里更新peer_missing列表的,在proc_replica_log()处理的只是从replica传过来它本地的missing(就是replica重启后根据自身的last_update和last_complete构造的missing列表),一般情况下这个missing列表是空。
[参看]
-
PGLog写流程梳理
-
ceph存储 ceph中pglog处理流程
-
ceph PGLog处理流程
-
Log Based PG
-
ceph基于pglog的一致性协议
-
Ceph读写流程








![java八股文面试[多线程]——synchronized 和lock的区别](https://img-blog.csdnimg.cn/2b8ee88522c34c6d83d844fc6cbb6698.png)