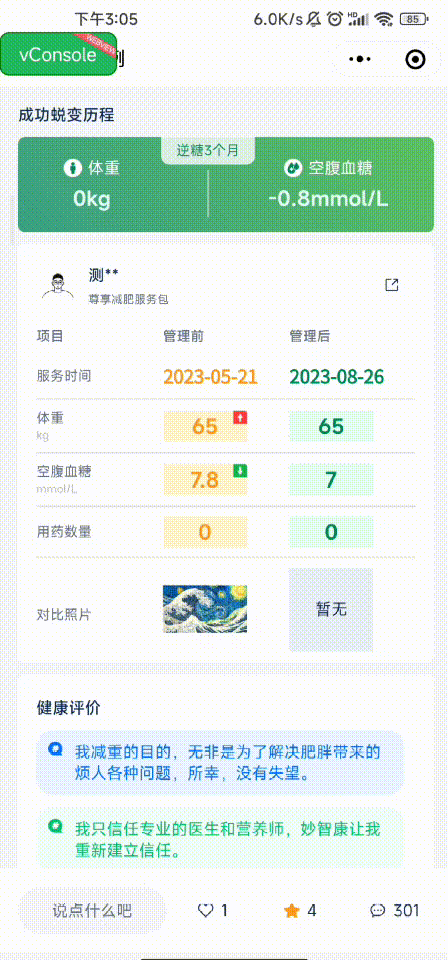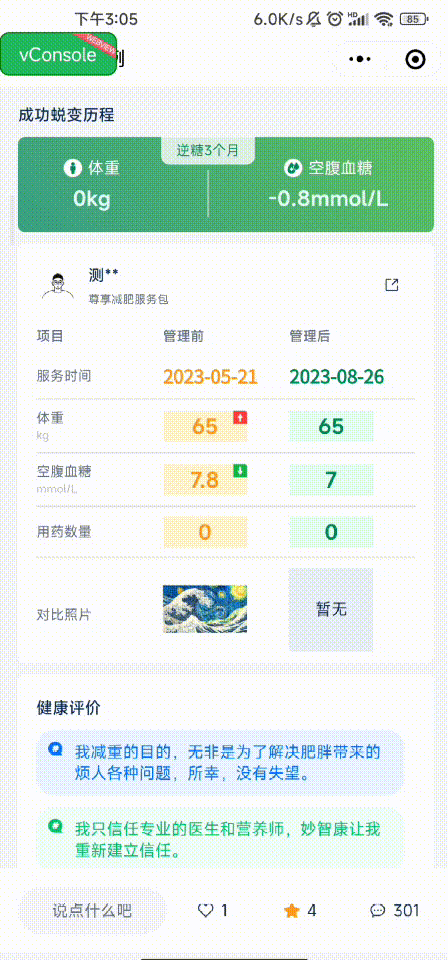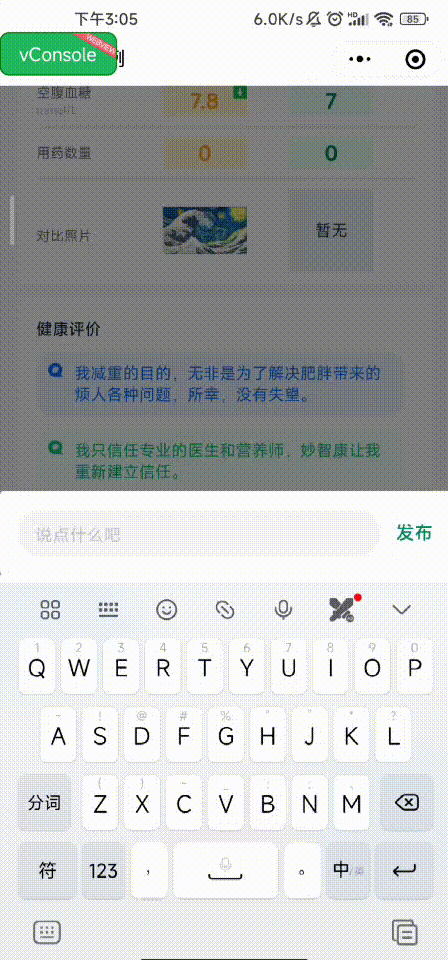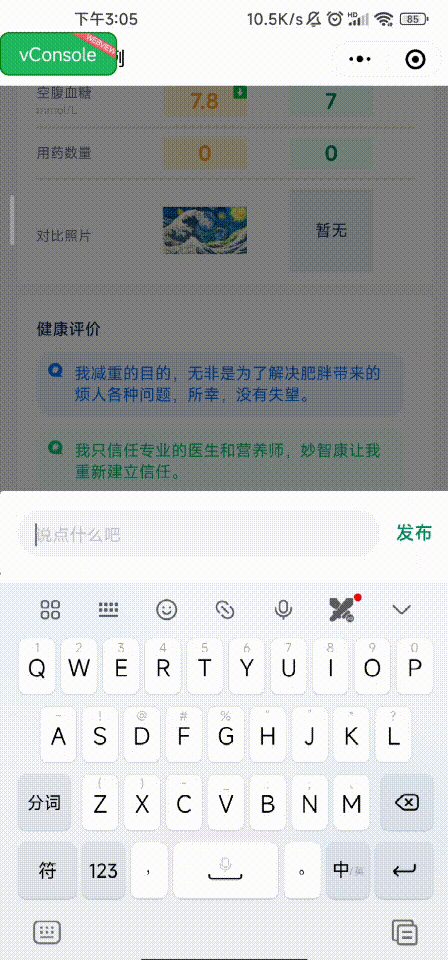
参考文章:
1、YOLOv5 深度剖析
2、如何看待YOLOv8,YOLOv5作者开源新作,它来了!?
3、anchor的简单理解
完整网络结构


YOLO v5和YOLO v8的Head部分

YOLO v8的Head 部分相比 YOLOv5 改动较大,换成了目前主流的解耦头结构,将分类和检测头分离,同时也从 Anchor-Based 换成了 Anchor-Free。anchor-based和anchor-free方法的本质区别,就是如何定义正负样本。
Anchor-Based:事先通过手工或聚类方法设定好的具有不同尺寸、宽高比的方框anchor_boxes。这些方框覆盖了整张图像,目的是为了防止漏检。在模型训练过程中,根据anchor_boxes与ground truth的IoU(交并比)损失对anchor_boxes的长宽以及位置进行回归,使其越来越接近ground truth,在回归的同时预测anchor_boxes的类别,最终输出这些回归分类好的anchors。目前主流的目标检测算法多是anchor-based这一类,其中有two-stage也有one-stage。two-stage方法要筛选和优化的anchors数量要远超one-stage方法,筛选步骤较为严谨,所以耗费时间要久一些,但是精度要高一些。在常用的检测基准上,SOTA的方法一般都是anchor-based的。
Anchor-Free:由于FPN和Focal Loss的出现,有效解决了特征语义信息不足和正负样本不均衡的问题,又涌现出了一批anchor-free的算法。anchor-free检测器以两种不同的方式检测物体,一种是首先定位到多个预定义或自学习的关键点,然后约束物体的空间范围,称为Keypoint-based方法;另一种是利用中心点或中心目标区域来定义正样本,然后预测其到目标四个边的距离,称为Center-based方法。anchor-free的方法使得目标检测的流程进一步精简,减少了相关超参数,使得网络搭建训练更简便,泛化能力也更强。
YOLOv5的C3结构 和 YOLOv8的C2f结构
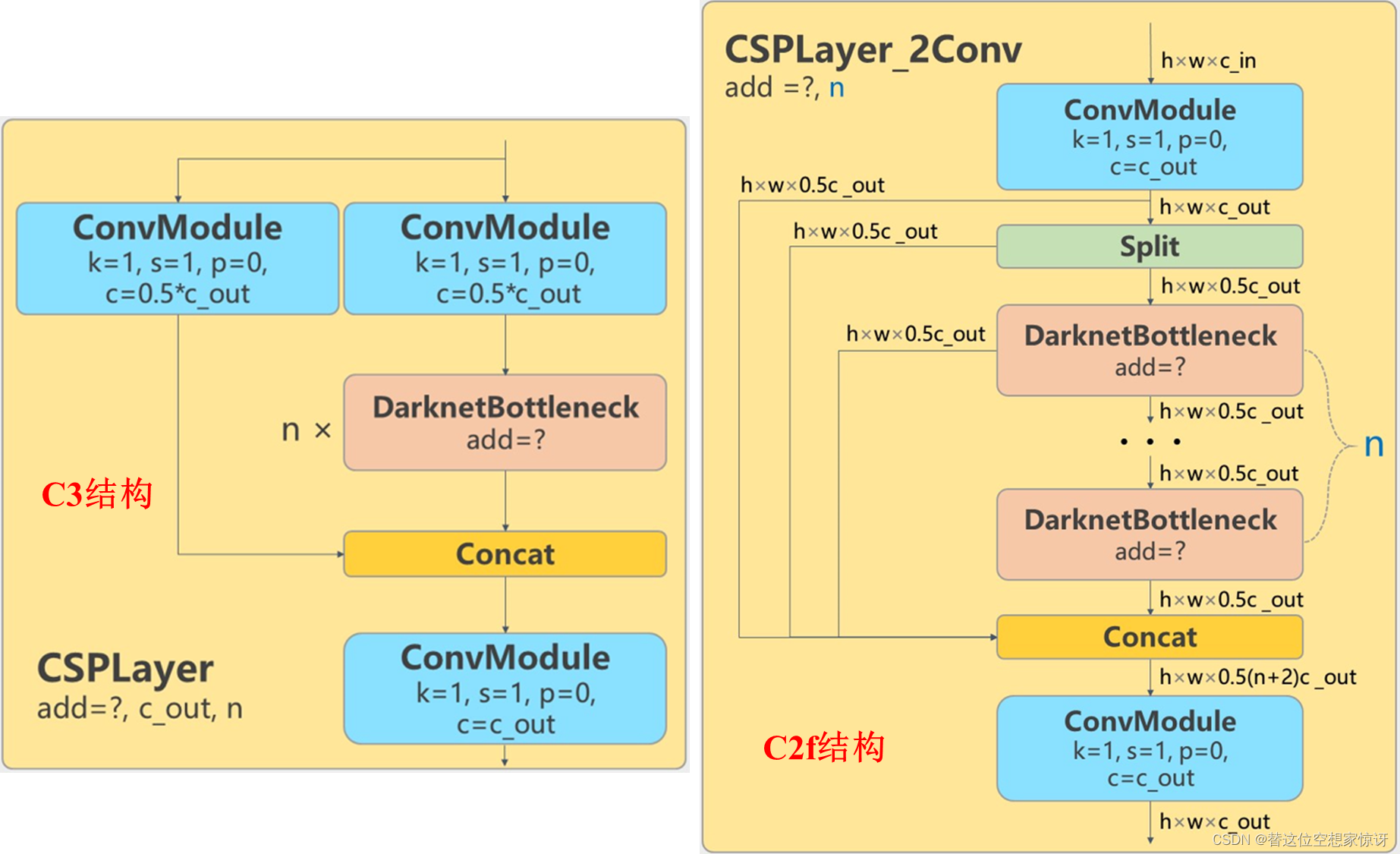
YOLO v8将 YOLOv5 的 C3 结构换成了梯度流更丰富的 C2f 结构,并对不同尺度模型调整了不同的通道数,不过这个 C2f 模块中存在 Split 等操作对特定硬件部署没有之前那么友好了。
YOLO v5和YOLO v8的loss
1、YOLO v5在类别的损失函数中,使用的是二元交叉熵损失函数,而不是softmax损失函数。因为softmax损失函数对于每个类别的处理是互斥的。而yolo考虑到了类别不互斥的情况,例如,一个类别可以是车,但也可以是汽车或货车,如果用softmax,是车就不可以是汽车,但二元交叉熵既可以是车也可以是汽车。
2、YOLO v8采用了 TaskAlignedAssigner 正样本分配策略,并引入了 Distribution Focal Loss。Loss 计算包括 2 个分支: 分类和回归分支,没有了之前的 objectness 分支。分类分支依然采用 BCE Loss。回归分支需要和 Distribution Focal Loss 中提出的积分形式表示法绑定,因此使用了 Distribution Focal Loss, 同时还使用了 CIoU Loss。3 个 Loss 采用一定权重比例加权即可。
TaskAlignedAssigner 正样本分配策略核心思想是在候选框与真实目标之间建立正确的对应关系,以便在训练过程中能够准确地学习目标检测模型,即根据分类与回归的分数加权的分数选择正样本。在目标检测中,类别不平衡是指不同类别的目标数量差异很大,这可能会导致模型在训练过程中对少数类别的预测效果较差。Focal Loss 通过在损失函数中引入一个可调节的因子,来减小易分类样本的权重,从而集中训练模型在困难样本上。Distribution Focal Loss是 Focal Loss 的一个变体,专门用于应对类别不平衡问题。其主要思想是将 Focal Loss 与样本分布信息相结合,从而更好地处理不平衡的类别。具体而言,分布 Focal 损失会根据每个类别的样本分布情况来调整 Focal Loss 中的因子,以便更有效地关注罕见类别。
YOLO v5和YOLO v8训练数据增强
YOLO v8数据增强方面和 YOLOv5 差距不大,只不过引入了 YOLOX 中提出的最后 10 个 epoch 关闭 Mosaic 的操作。假设训练 epoch 是 500,其示意图如下所示:
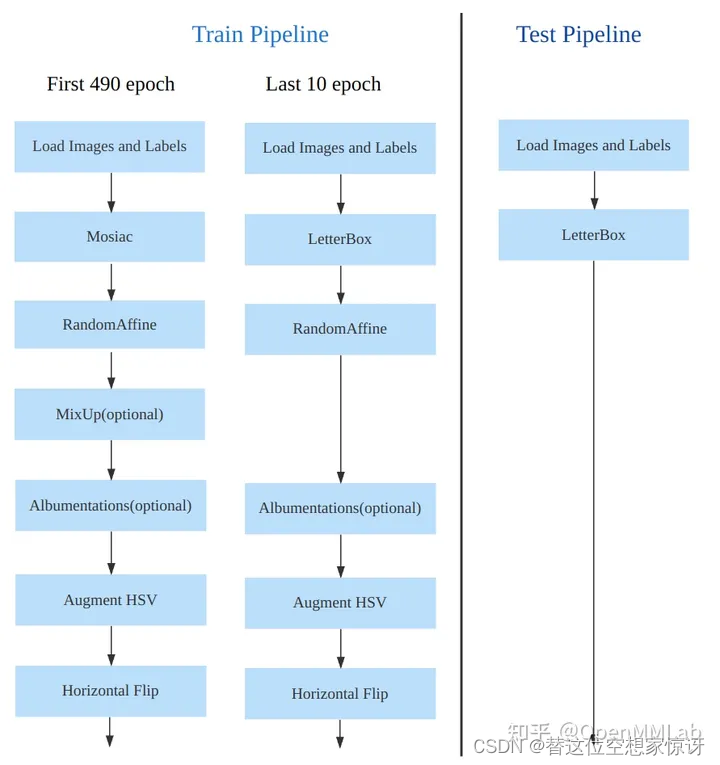
Mosaic是YOLOV4中提出的新方法,适用于目标检测,主要思想是将四张图片进行拼接到一张图上作为训练样本。由于Mosaic用于目标检测,进行拼接时目标框的坐标也要做相应的变化。Mosaic的主要操作如下:
- 对每一张图进行随机裁剪得到A;crop的目标是选择原图的某一块区域,而不是全图进行后续的拼接;
- 将A进行resize到输出图大小得到B;目标是统一坐标系尺寸,方便后续拼接;坐标框会进行相应的缩放
- 将B随机裁剪一块指定大小的区域C;
- 将C粘贴到输出图相应的位置;此时只需要坐标平移就可以调整坐标框