提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
问题合集
例如:随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。
一、问题:为什么stats.norm.pdf计算出的概率分布值会大于1
PDF值>1能理解,不能理解的是CDF值为什么会大于1
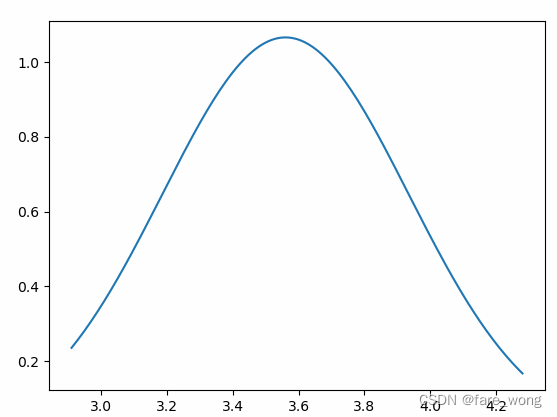
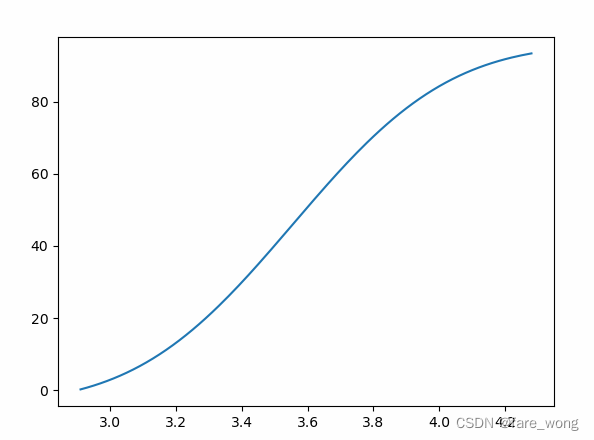
1.代码
mean_Con = 3.560227573198049
std_Con = 0.37432379884090594
x = np.arange(np.min(Con), np.max(Con), 0.01)
y = stats.norm.pdf(x, mean_Con, std_Con)
cdf = np.cumsum(y)
plt.plot(x, cdf)
2.分析
- 概率密度函数PDF:描述这个随机变量的输出值,在某个确定的取值点附近的可能性的函数。而随机变量的取值落在某个区域之内的概率则为概率密度函数在这个区域上的积分
- note:连续型的随机变量取值在任意一点的概率都是0,概率P{x=a}=0,但{X=a}并不是不可能事件
- scipy.stats.norm.pdf 函数可以实现正态分布,画出均值为u,方差为σ的概率密度分布图
- 可能是因为cumsum不能用来算概率密度积分?