系列文章目录
手把手教你安装Git,萌新迈向专业的必备一步
GIT命令只会抄却不理解?看完原理才能事半功倍!
- 系列文章目录
- 一、Git 的特征
- 1. 文件系统
- 2. 分布式
- 二、GIT的术语
- 1. 区域术语
- 2. 名词术语
- 1. 提交对象
- 2. 分支
- 3. HEAD
- 4. 标签(TAG)
- 3. 动作术语
- 三、Git 存储模型
- 1. GIT 数据库
- 2. 树对象
- 3. 提交对象
- 总结

上一次,我们简单介绍了为什么要用版本管理,以及怎么安装Git以及基本认识,为新手朋友们迈出了实操的第一步。而本期的内容其实笔者犹豫了很久,到底是先讲GIT的模型和原理,还是直接讲GIT常用命令? 最终笔者决定还是先从模型与原理下手,不仅是它是命令的前提,而且笔者发现虽然很多用GIT,但只限于几个常用命令,对其运行机制却知之甚少,一旦出现问题,就容易束手无策了,难以处理,所以本期我们还是先讲讲GIT的基础原理吧
📕作者简介:战斧,从事金融IT行业,有着多年一线开发、架构经验;爱好广泛,乐于分享,致力于创作更多高质量内容
📗本文收录于 GIT 专栏,有需要者,可直接订阅专栏实时获取更新
📘高质量专栏 云原生、RabbitMQ、Spring全家桶 等仍在更新,欢迎指导
📙Zookeeper Redis kafka docker netty等诸多框架,以及架构与分布式专题即将上线,敬请期待
一、Git 的特征
1. 文件系统
我们都知道Git是个版本控制系统,但是如果你深入了解其原理,就不难发现它更像一个文件管理系统,如果你使用过其他版本控制器,不难发现它们的思路非常符合“版本控制”的逻辑,它们记录的是一个初始文件,以及后续对该文件的历次修改内容,如下:
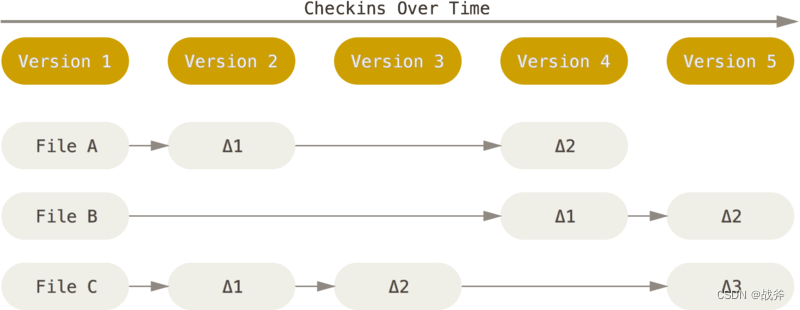
而对于GIT,则是把你每次的“提交”当作一次相机的“快门”,GIT会为你把当时的全部文件内容都做一个快照,然后进行存储,这一系列的快照,每一个快照展开都是完整的文件系统。 当然,为了效率,如果文件没有修改,Git 不再重新存储该文件,而是只保留一个链接指向之前存储的文件
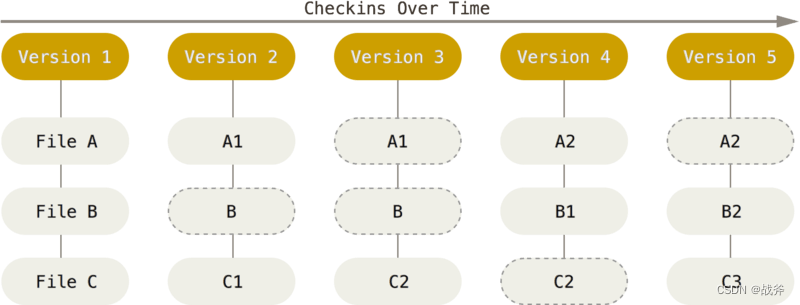
2. 分布式
我们可以把上次的图继续拿来使用,GIT的核心工作都是在本地完成的,即其主要工作都聚焦在工作区到本地仓库,这意味着,即使我们离线了,我们仍然能完成提交操作,GIT仍然能忠实的记录下我们的操作记录,而不像其他版本控制器,断网后版本控制功能就失效了。
二、GIT的术语
在接触GIT的时候,我们难免会接触到一些术语或概念,我们先对术语做个解释,如果你看了某些解释,觉得一头雾水,先别着急,我们在下面会慢慢解释
1. 区域术语
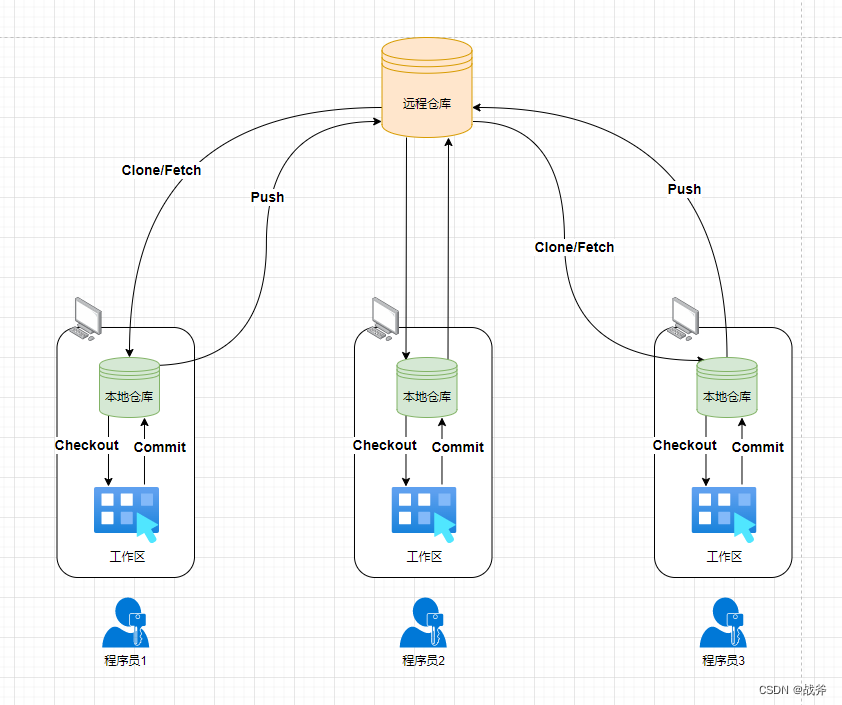
GIT一共分为四个区域,对于开发者来说,由远到近依次为:远程仓库、本地仓库、暂存区和工作区
-
远程仓库:可以是GitHub、GitLab,也可以是你自己的私有服务器,包含项目所有的版本控制信息和文件历史记录。
-
本地仓库:你电脑上的存储库,它包含项目所有的版本控制信息和文件历史记录
-
暂存区:也称为
索引(Index),用于存储下一次提交时要包含哪些修改或变更。 -
工作区:指项目的实际文件夹,即我们日常编辑的文件夹。
我们之前讲了三个部分,唯独没有讲暂存区。实际上,我们的代码不能直接从工作区就到仓库去,本地仓库只接收暂存区提供的内容,所以我们的任何新增、修改实际上都要先加入到暂存区。
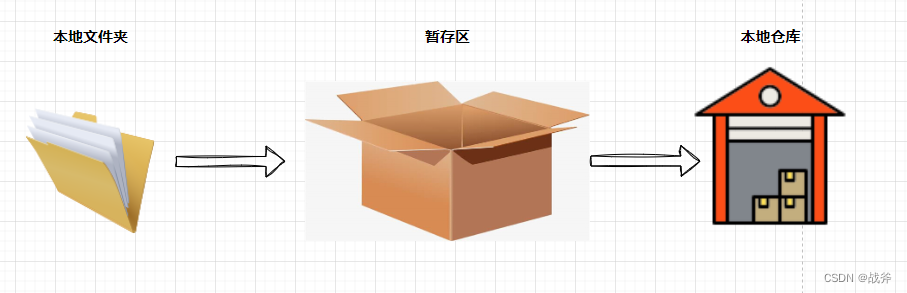
但是为什么这块暂存区存在感不强呢?主要是因为我们现在的各种工具在自动维护,比如我们添加文件时,IDEA会自动弹窗,当我们使用Tortoisegit时,提交时会让我们勾选文件,这些都让我们免于手动往暂存区进行手动添加,自然其存在感就稍弱了
2. 名词术语
1. 提交对象
我们每次把暂存区的内容放入本地仓库,称为一次提交,产生一个提交对象(也叫“提交点” 或 “提交”)。
除了手动提交,合并操作也会产生提交点,提交点包含了前一个提交点位置、文件变更信息、变更人、变更时间等所有信息,每个提交点都有自己的SHA-1哈希值作为唯一标志,一般在图中,用一个圈表示。因为提交点(除了首次提交)都会包含上一个提交点的地址,所以在实例图里一般呈链表状,如下图,就展示了三个提交点。

2. 分支
定义: 一个指向某个提交对象的指针,表示一个代码的分支。可以有多个分支,并行开发不同的功能或版本
对于分支这个概念,在讲解之前,如果你看过其他的教程,可能会经常看到类似下面的图
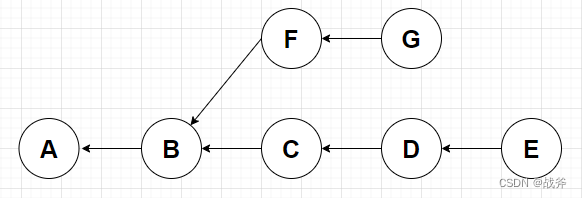
这样的话,你会认为这里有两个分支,一个是由C D E构成,一个是F G构成。的确,这里是有两个分支不假,但这张图更具体的样子应该是这样子
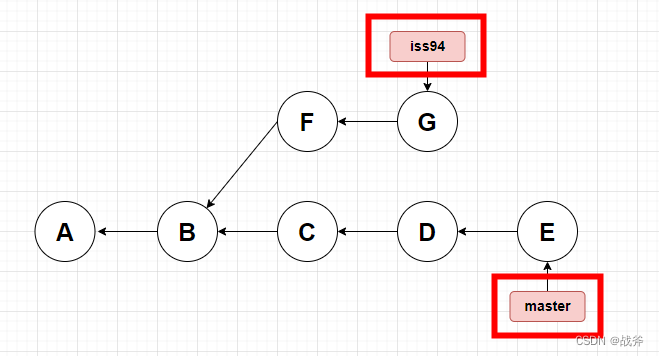
分支并不是树枝,图中真正的分支,其实只是两个指针,如图,分支iss94指向提交点G,分支master指向提交点E,理解了这个概念,你才能明白为什么Git鼓励大家,遇事不决就建立各种分支。在其他版本控制器中,拉个分支可能意味着所有的代码都要复制一遍,而在GIT中,仅仅是建立一个指针。
聪明的你可能想到了一个问题,建分支 = 建指针,那岂不是当我建分支的时候,会产生两个指针,指着同一个节点?,此时,如果我再次提交内容,岂不是乱了套?这个节点会算在哪个分支上?这时候就要用到另一个概念 HEAD
3. HEAD
定义:HEAD是一个特殊的指针,它指向当前所在的分支或提交。一般情况下,HEAD指向当前所在分支的最新提交。
没错,HEAD也是个指针,而且指向分支,如果你没有忘记分支也是个指针的话,那你应该能想象出下面的图例
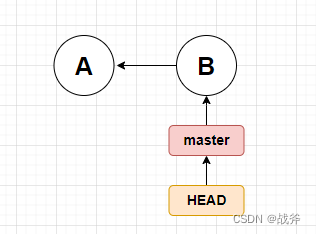
这代表着HEAD指向了master分支,我们把前面分支的知识结合起来,现在如果我们想建立个名叫 iss95 的分支,图就会变成这样子
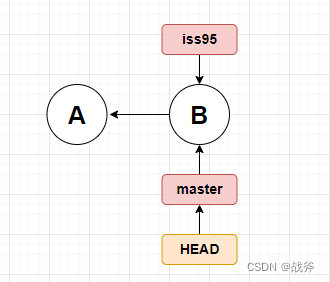
如果此时我们再进行一次提交,会变成什么样呢?
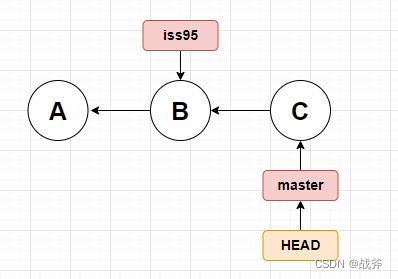
所以,你应该明白HEAD的作用了,它代表着你下次提交的位置,此处它指向master,所以我们的提交是提交至分支master上的。提交后,master指针自动移到C的位置。而iss95则没有任何变化,还是指向B。
严谨的小伙伴可能注意到我们定义中说了一句 一般情况下,HEAD指向当前所在分支的最新提交。那HEAD能指向历史提交吗?
答案是肯定的,我们可以使用 git checkout <commit> 命令将HEAD移动到某个历史提交点,如下图:
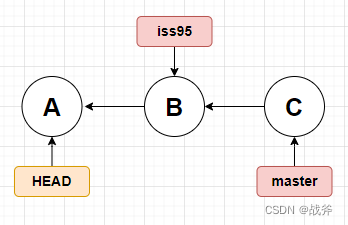
4. 标签(TAG)
定义:在 Git 中,Tag是一种重要的版本控制工具,它们是一些永久性的指针,指向某个特定的提交(commit),常用于代码发布、版本管理以及历史记录的标记等操作
.
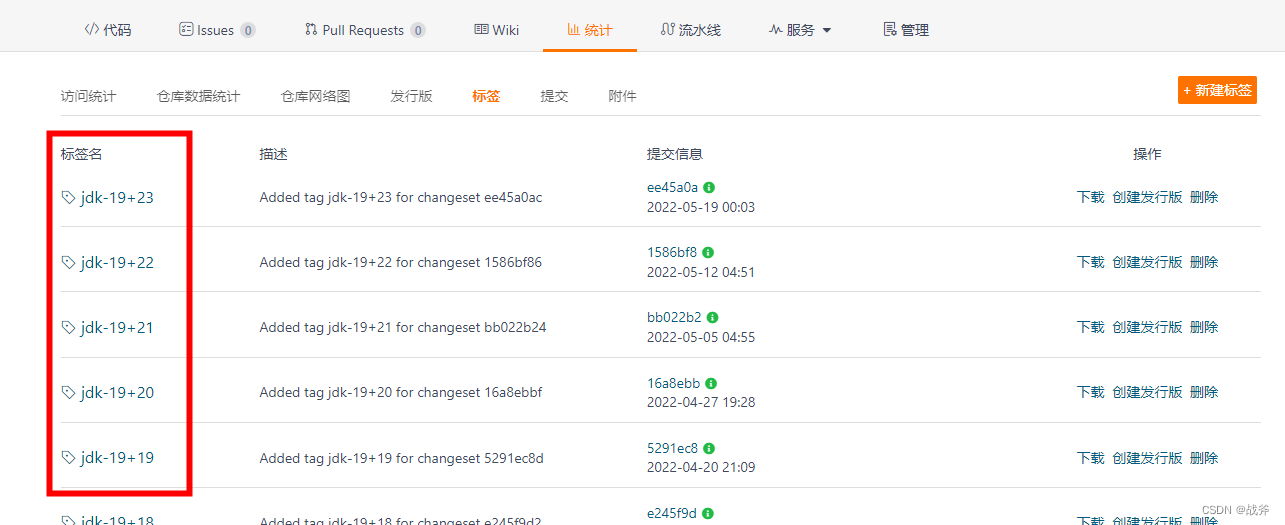
简而言之,标签也是一个指针,只是这个指针不像分支 或 HEAD 一样,它是不会移动的,我们可以看到JDK源码中就有大量的标签,用以标记节点
3. 动作术语
-
添加 (Add): 将工作目录的文件加入暂存区,可以只选择部分文件进行添加
-
提交(Commit):将暂存区的内容放入本地仓库,每个提交都有唯一的ID。
-
合并(Merge):将两个或多个分支的修改合并到一起。
-
拉取(Pull):将远程仓库的修改拉取到本地仓库,并更新工作区。
-
推送(Push):将本地仓库的修改推送到远程仓库。
-
检出(Checkout):切换某个分支,并同时切换工作目录。
如果前面你都学会了,相信这几个动作,你应该能理解,它们之前能汇聚成下面这张关系图
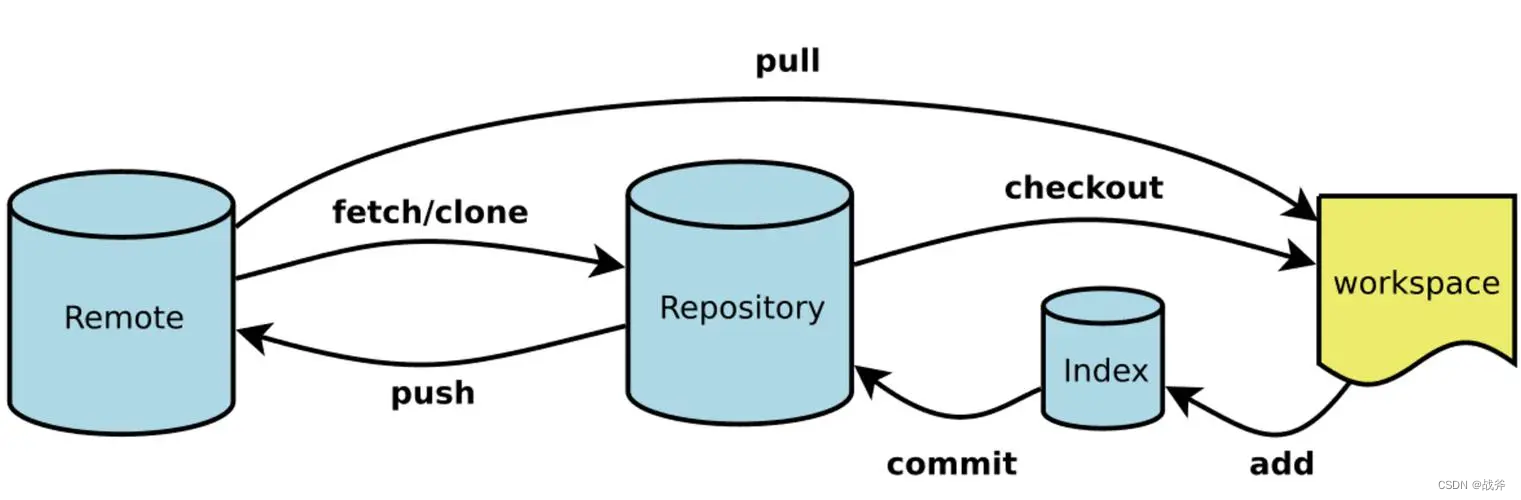
当然,这些命令实际上并不仅仅这么简单,比如 Checkout 不仅可以切换分支,还可以跟文件名,以 git checkout <file-name> 来还原文件。但是这些,我们留到下一篇文章再讲解。
三、Git 存储模型
1. GIT 数据库
前面我们三番五次的把 GIT 说成更像文件系统,这是很合理的。甚至可以说GIT是一个数据库,其实它的核心确实就是一个键值对数据库,你可以向 Git 仓库中插入任意类型的内容,它会返回一个唯一的键,通过该键可以在任意时刻再次取回该内容
$ echo ‘test content’ | git hash-object -w --stdin
d670460b4b4aece5915caf5c68d12f560a9fe3e4
如上,我们把标准输入内容 “test content” 存储进GIT,它就会返回给我们一个40字符的 SHA-1 哈希值,我们可以用这个值,重新获取存进去的内容
$ git cat-file -p d670460b4b4aece5915caf5c68d12f560a9fe3e4
test content
但注意,使用这种方式存入文件,返回的只有文件内容,等于说文件名我们丢失了,而文件名的遗失对于文件系统来说,是非常不合理的。所以我们还需要树
2. 树对象
比方说我们有一个简单的目录,目录下有两个文件,README 以及 Rakefile,并且还有个子目录lib,lib里有个文件simplegit.rb。那么当我们把这个目录及其所有文件纳入GIT管理时,其形态是这样的
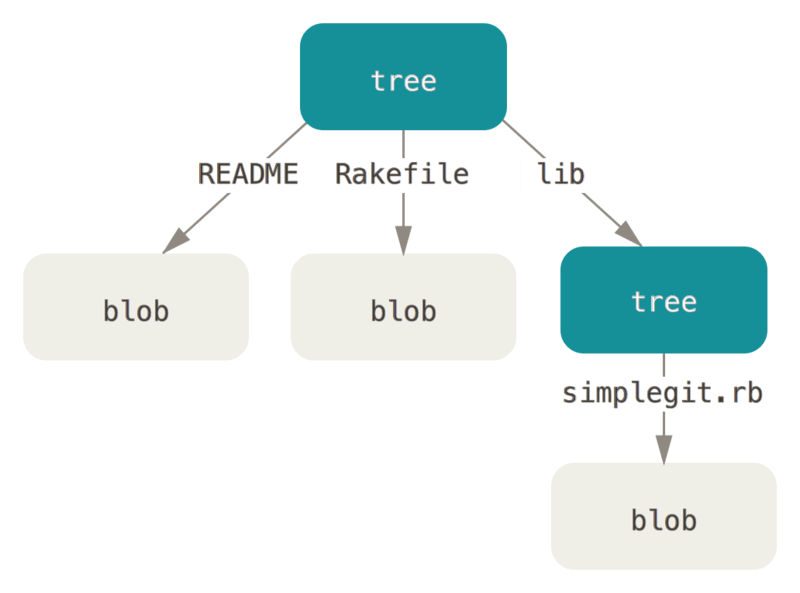
它会把我们的文件存储成blob对象,目录变成tree对象。tree对象可以存文件信息,blob对象存文件内容,而且tree对象还能下辖另一个tree对象,这就和我们目录下还有子目录是一样的。如此一来,我们就可以把我们想存放的目录及其文件,以一棵树的形式完整的存入GIT中了。存是存进去了,但这仅仅是一次保存,存进去最多说GIT保存了我这个目录,那么它的版本控制又体现在哪呢?
3. 提交对象
我们上面说了整个目录能变成一个 Tree 对象存入GIT,它是什么时候情况下会存呢?其实就是GIT执行提交命令的时候,当我们提交时,GIT会把我们整个工作目录的所有文件汇聚成一个Tree,并且把这个Tree的引用放进一个提交对象中进行存储。
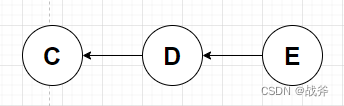
也就是说,如上图,每一个圈(提交对象)不仅有本次提交人、提交时间等信息、而且还指向着一个Tree,所以提交对象实际上就是一个快照
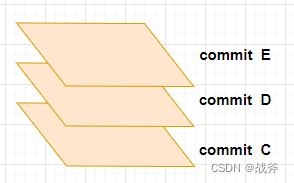
如上图,三次提交实际上构成了一个不断往上摞的切面,为啥说是切面,是因为每一个切面都包含着一棵树,也就是当时整个目录的内容。因此信息量其实是很多的。当然,提交对象、和树对象或者文件对象一样,都会存进GIT,GIT也会返回一个40长度的 SHA-1 哈希值。
这样当我们查询提交历史时,查询到的就是所有过往的提交对象的信息,如果我们确定某个提交对象后,我们就能通过该提交对象的 SHA-1 哈希值能找回当时所有的文件
$ git log
commit ca82a6dff817ec66f44342007202690a93763949
Author: Scott Chacon <schacon@gee-mail.com>
Date: Mon Mar 17 21:52:11 2008 -0700changed the version numbercommit 085bb3bcb608e1e8451d4b2432f8ecbe6306e7e7
Author: Scott Chacon <schacon@gee-mail.com>
Date: Sat Mar 15 16:40:33 2008 -0700removed unnecessary testcommit a11bef06a3f659402fe7563abf99ad00de2209e6
Author: Scott Chacon <schacon@gee-mail.com>
Date: Sat Mar 15 10:31:28 2008 -0700first commit
PS:Tree对象不是压缩包,它只是存储着当时那些文件对象的引用。另外,提交时形成的Tree并不是把所有的文件全部又做一遍保存,然后把引用放进Tree,而是只保存改动或新增的文件,那些没有改动过的文件已经存过了,不会再存,所以不用过分担心空间问题。
总结
本次我们比较形象的讲解了GIT的运行机制及存储模型,如果你意犹未尽,或对GIT想了解更多,也可以去官方的文档做更深入的了解,我把它的地址放在这里 官方中文文档 而对于大部分读者,本文中所说的内容已经足够支持我们后面的学习,那么下次我们就可以正式开始学习GIT的命令以及各种应用了。