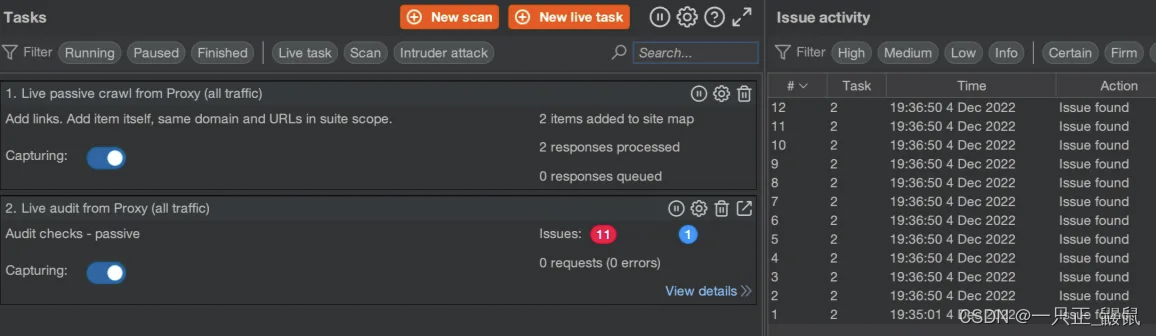
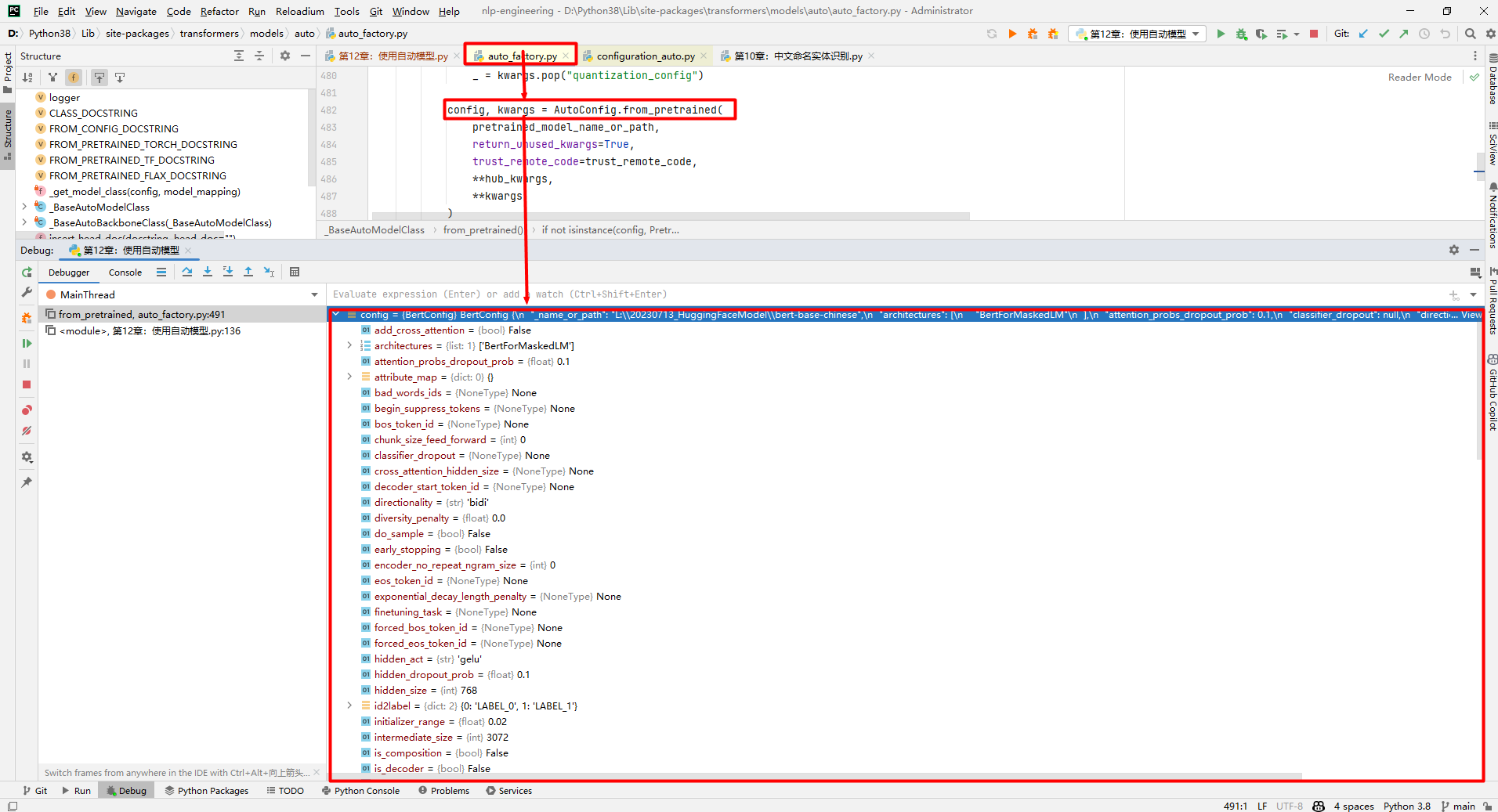
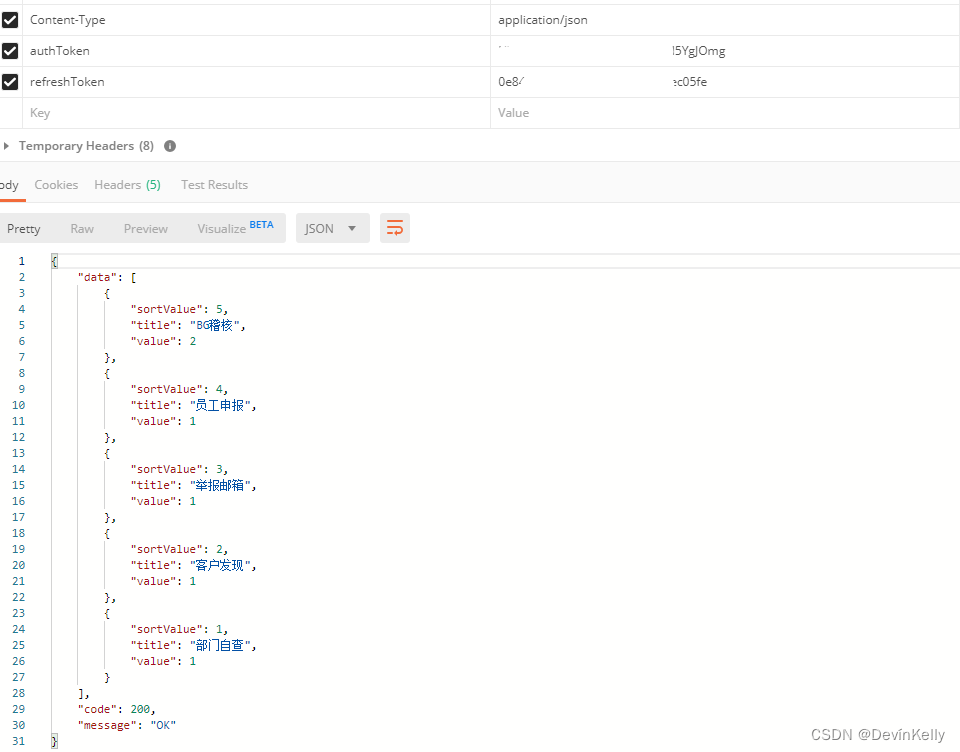
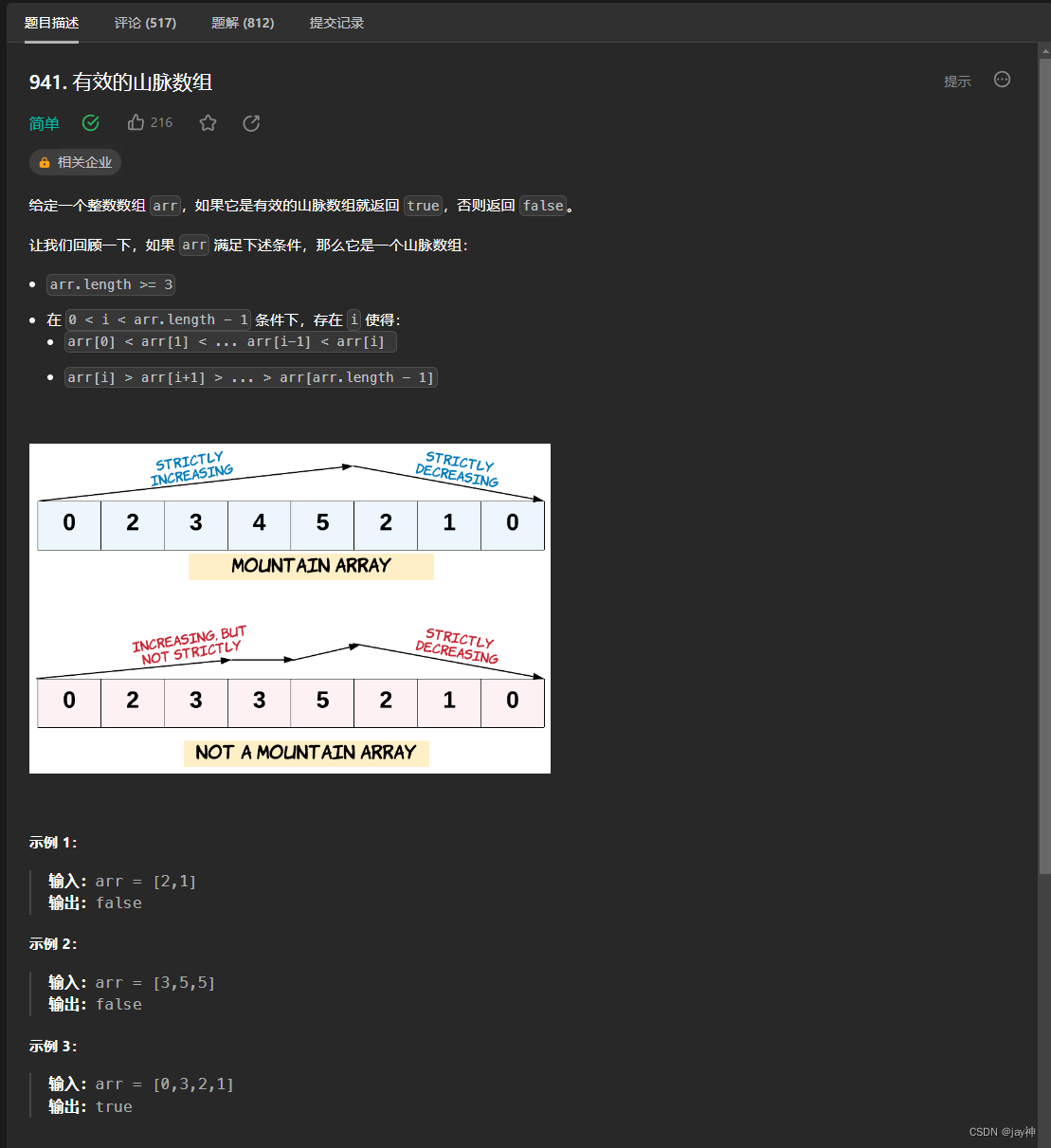
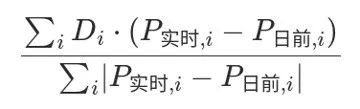当你为项目选择数据库或搜索引擎时,了解每个选项的细微差别至关重要。 今天,我们将深入探讨 Elasticsearch 的优势,并探讨它与传统 SQL 和 NoSQL 数据库的比较。
1. Elasticsearch简介
Elasticsearch 以强大的 Apache Lucene 库为基础,是一个分布式搜索和分析引擎。 它以其速度、可扩展性以及快速索引大量数据的能力而闻名。 与许多传统数据库不同,Elasticsearch 是为以搜索为中心的应用程序量身定制的,提供许多数据库本身不支持的功能。更多关于 Elasticsearch 的介绍,请参阅文章 “Elasticsearch 简介”。
有关 Elasticsearch 的版权问题,请参阅文章 “Elastic:开发者上手指南” 中的 “版权介绍” 章节。
2. Elasticsearch 的优势
a. 全文搜索功能
- 倒排索引:Elasticsearch 的核心使用倒排索引,这是一种列出每个唯一单词及其在数据中对应位置的数据结构。 这种结构针对速度进行了优化,可实现跨海量数据集的快速文本搜索。详细阅读文章 “Elasticsearch:inverted index,doc_values 及 source”。
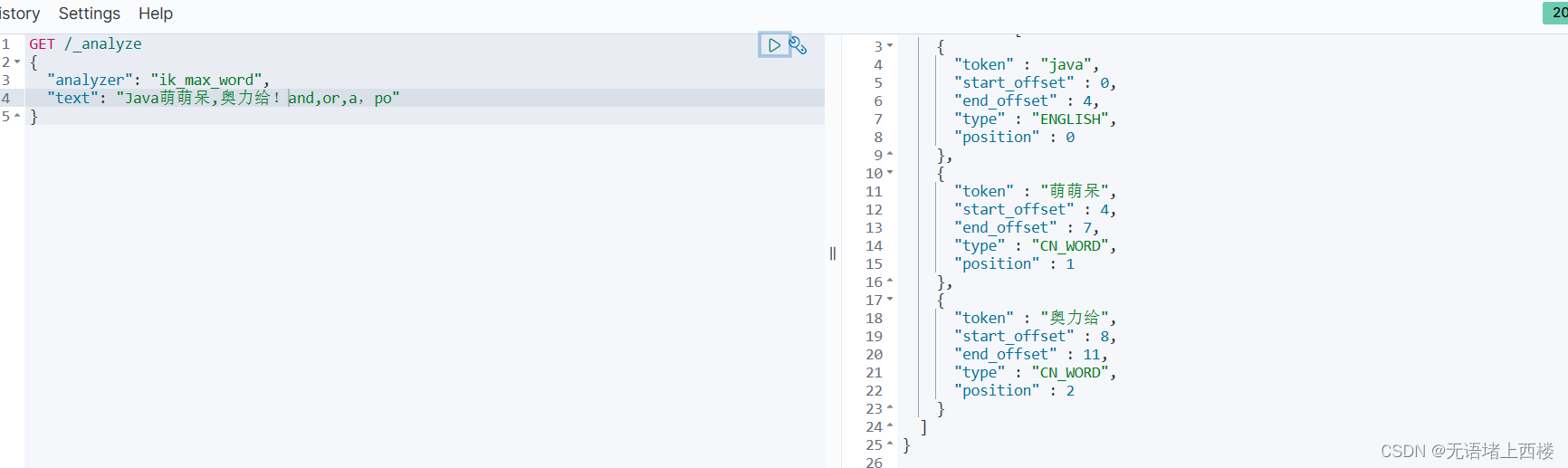
- 高级文本处理:Elasticsearch 提供开箱即用的功能,例如标记化(将文本分解为单个单词或术语)、词干提取(将单词还原为其根形式)和处理同义词等。 这些过程增强了搜索相关性和精确度。详细阅读文章 “Elasticsearch: analyzer”。
- 相关性评分和排名:当你在 Elasticsearch 中搜索时,它不仅会查找匹配项,还会使用各种算法根据相关性对它们进行排名,确保首先返回最相关的结果。相关阅读 “Elasticsearch:分布式计分”。
b. 数据的灵活性
- JSON 原生结构:Elasticsearch 将数据视为 JSON 文档。 这种格式不仅在现代 Web 应用程序中普遍存在,而且还允许对数据进行分层结构,从而实现更复杂的查询。
- 动态映射:与某些需要固定模式的数据库不同,Elasticsearch 可以自动检测文档中字段的数据类型并为其建立索引。 这种灵活性有利于不断发展的数据集。详细阅读 “Elasticsearch:Dynamic mapping”。
c. 批量索引
- 高效的数据摄取:Elasticsearch 的 bulk API 允许在单个请求中执行多个索引、更新或删除操作。 这种简化的方法可确保高速数据摄取,尤其是在处理大量信息时。
- 并行处理:Elasticsearch 旨在处理跨分布式节点的同步索引操作。 这种并发处理可确保快速对大量数据建立索引。
d. 分布式设计
- 分片和复制:Elasticsearch 中的数据本质上分为 “分片”。 这些分片可以跨节点复制,从而提供可扩展性(通过添加更多分片)和弹性(通过副本)。 随着 你的数据增长,Elasticsearch 也会与你一起成长。更多关于分片的描述,请阅读文章 “Elasticsearch 中的一些重要概念: cluster, node, index, document, shards 及 replica”。
- 水平可扩展性:需要处理更多数据? 只需向你的 Elasticsearch 集群添加更多节点即可。 系统自动分配您的数据和查询负载,确保最佳性能。
- 容错:在节点发生故障时,副本分片的存在可确保你的数据保持可用,并且你的搜索操作可以继续进行而不会中断。
e. 实时索引
- 近乎即时的数据可用性:Elasticsearch 中的数据一旦被摄取,几乎可以立即用于搜索操作。 这种实时索引功能得益于其优化的刷新间隔,确保你的应用程序始终能够访问最新数据。请详细阅读 “Elasticsearch:Elasticsearch 中的 refresh 和 flush 操作指南”。
- 针对高吞吐量进行了优化:除了实时索引之外,Elasticsearch 还旨在处理连续的数据更新流,这使其对于日志监控或实时数据分析等时间敏感型应用程序特别有效。
3. 传统数据库可能具有优势的地方
a. ACID 事务
SQL 数据库通常优先考虑强 ACID 保证,使它们更适合需要严格数据完整性和一致性的应用程序。
b. 复杂的关系
SQL 数据库是围绕数据规范化和关系设计的。 他们擅长处理复杂的连接和关系数据建模。
c. 通用用例
虽然 Elasticsearch 擅长搜索和分析,但 SQL 数据库更加通用,适合各种应用程序。
4. Elasticsearch最适合的场景
- 日志记录和监控:由于其能够处理大量数据并使其可近实时搜索。
- 全文搜索应用:例如电子商务平台,其中搜索、过滤和排名的组合是必不可少的。
- 分析和可视化:Kibana 等工具可以将 Elasticsearch 转变为强大的数据可视化平台。
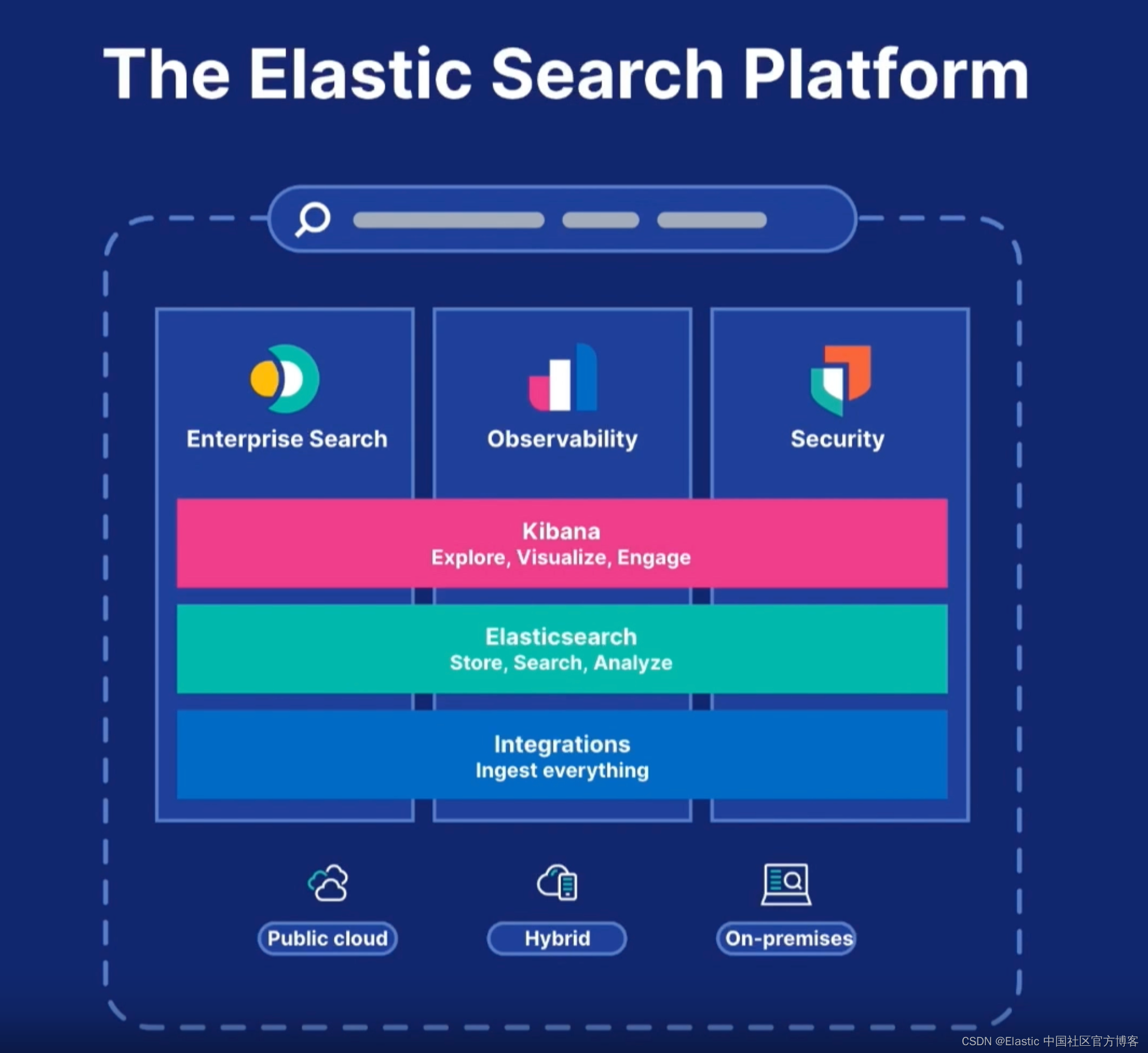
在 Elastic Stack 的发布中,围绕 Elasticsearch,它提供了三大开箱即用的解决方案:企业搜索(Enterprise Search),可观则性(Observability)及安全性(Security)。
5. 结论
在数据库和搜索引擎的广阔世界中,每种工具都有其独特的优势。 虽然 Elasticsearch 对于以搜索为中心和数据量大的应用程序来说无疑是强大的,但评估你的特定项目的需求至关重要。 通过了解每个选项的功能和权衡,你可以确保利用正确的工具来应对独特的挑战。