Adapter Tuning
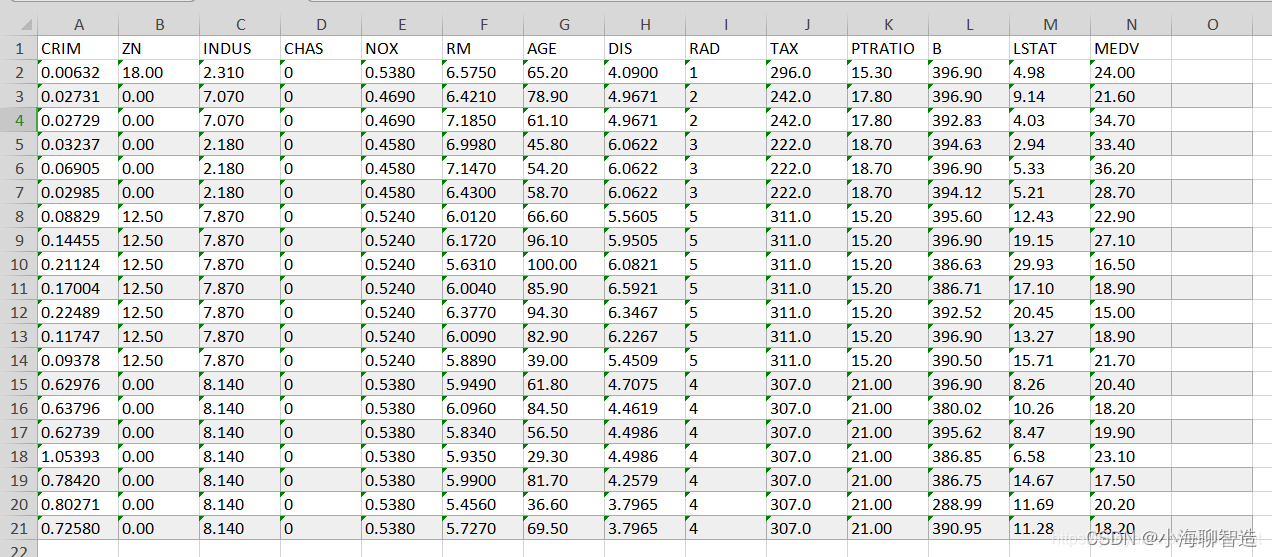
适配器模块(Adapter Moudle)可以生成一个紧凑且可扩展的模型;每个任务只需要添加少量可训练参数,并且可以在不重新访问之前任务的情况下添加新任务。原始网络的参数保持不变,实现了高度的参数共享
Paper 1: Parameter-Efficient Transfer Learning for NLP
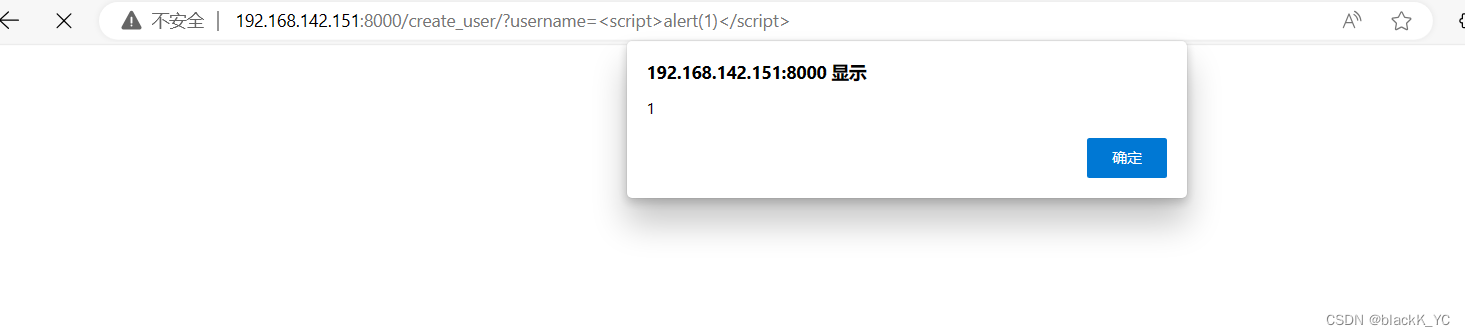
- 为了证明适配器的有效性,我们将最近提出的BERT Transformer模型应用于26个不同的文本分类任务,包括GLUE基准测试 : https://github.com/google-research/adapter-bert
adapter 的优点:
(i) 它可以获得良好的性能,
(ii) 它允许按顺序对任务进行训练,即不需要同时访问所有数据集,
(iii) 它每个任务只添加了少量额外的参数。
(iv)一个接近恒等初始化的方法。通过将适配器初始化为接近恒等函数的方式,当训练开始时,原始网络不受影响。在训练过程中,适配器可以被激活,从而改变整个网络中的激活分布。
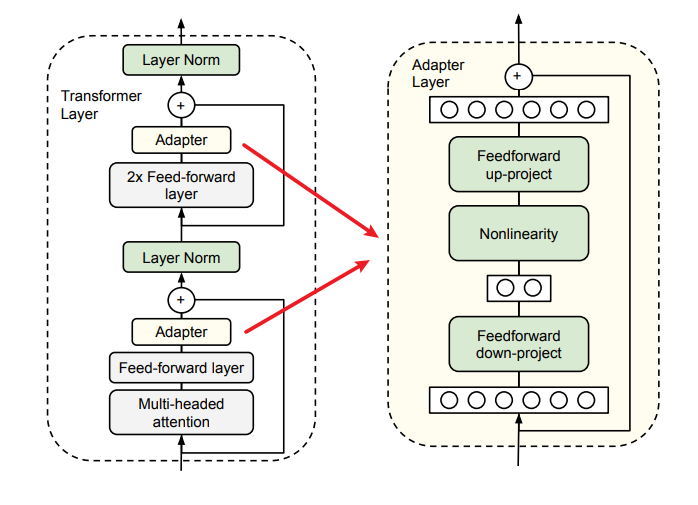
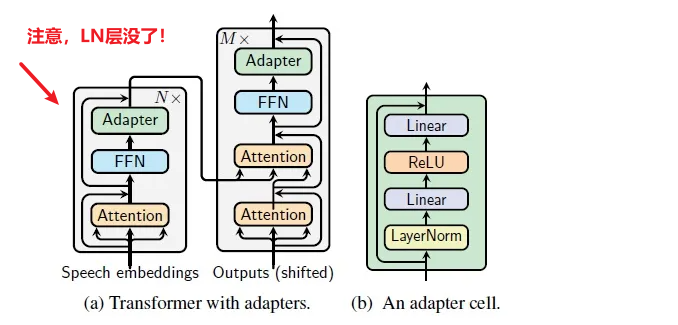
适配器还包含一个跳跃连接。在适配器微调过程中,绿色层使用下游数据进行训练,包括适配器、层归一化参数以及最终的分类层(图里没有)
实验:

- Adapter for Tansformer
Paper2:LLaMA-Adapter
Efficient Fine-tuning of Language Models with Zero-init Attention
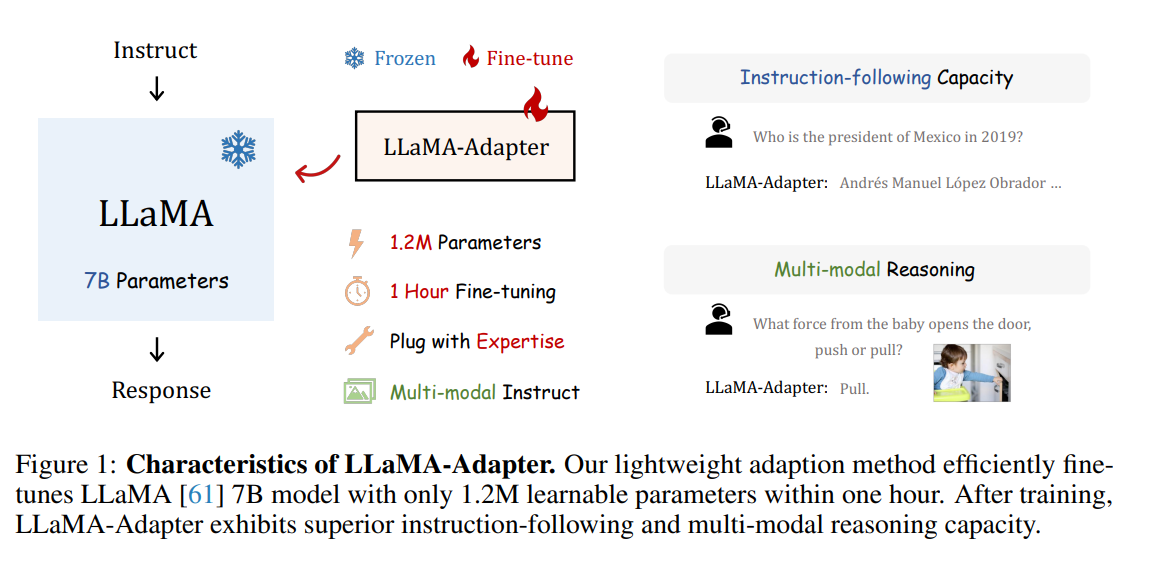
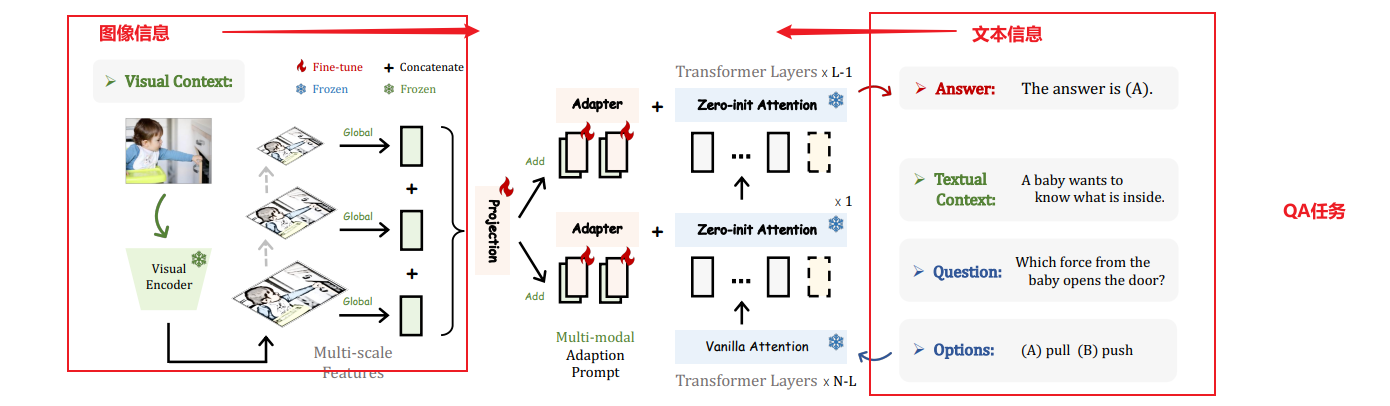
我们提出了LLaMA-Adapter,一种轻量级的适应方法,可以高效地将LLaMA模型微调为指令跟随模型。使用52K个自我指导演示,LLaMA-Adapter仅在冻结的LLaMA 7B模型上引入了1.2M个可学习参数,并且在8个A100 GPU上的微调时间不到一小时。
- 具体而言,我们采用一组可学习的适应提示,并将它们预置到较高的Transformer层的单词标记之前。(前缀 Prefix)
- 然后,我们提出了一个以零初始化的注意机制和零门控的方式,它可以自适应地将新的指令提示注入到LLaMA模型中,同时有效地保留其预训练的知识。
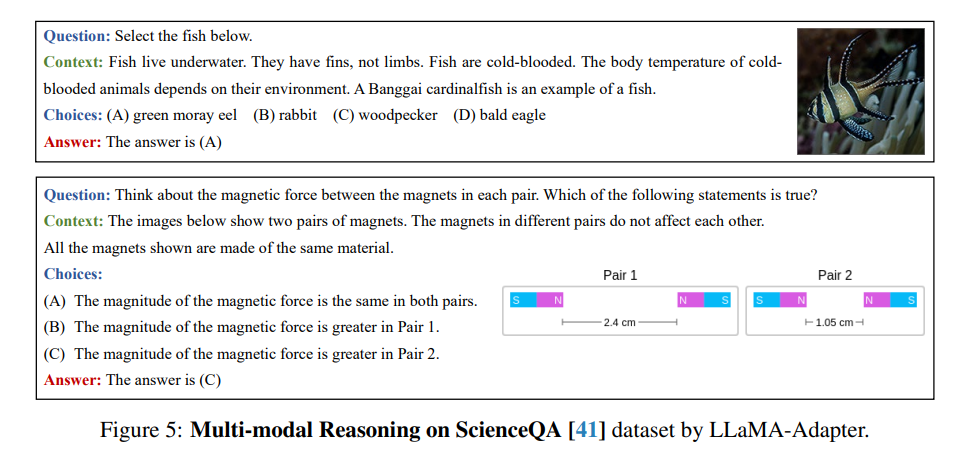
- 通过我们高效的训练,LLaMA-Adapter可以生成高质量的响应,与完全微调的7B参数的Alpaca模型相媲美。除了语言指令,我们的方法还可以简单地扩展到多模态指令,用于学习基于图像的LLaMA模型,在ScienceQA和COCO Caption基准测试上实现了更优秀的推理性能。
此外,我们还评估了以零初始化的注意机制在传统视觉和语言任务上微调其他预训练模型(ViT,RoBERTa),展示了我们方法的优越的泛化能力。
这么NB ????
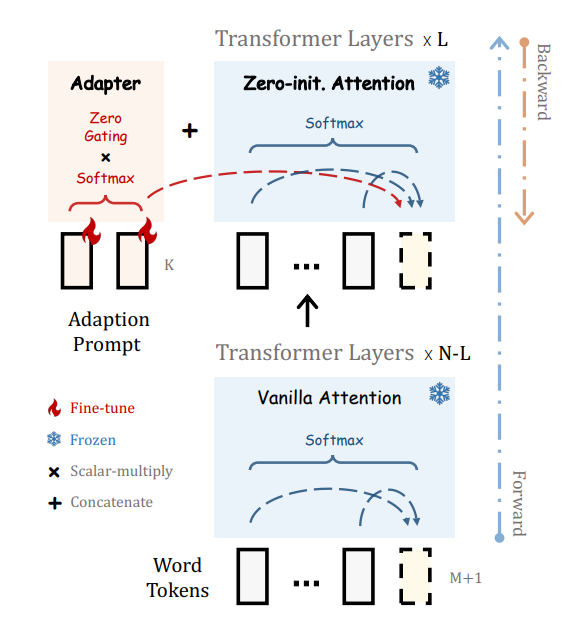
- 为了逐步学习指令知识,在早期阶段我们采用了以零初始化的注意机制和门控机制,以实现稳定的训练
如果适应提示被随机初始化,它们可能会在训练初期对单词标记带来干扰,从而损害微调的稳定性和有效性。考虑到这一点,我们修改了最后L个Transformer层上的普通注意机制,将其改为零初始化的注意机制,如图2所示。
过去的PEFT方法是直接插入随机初始化的模块, 这可能导致早期训练阶段有较大loss的不稳定微调.
llama采用zero-init attention with gating来缓解这种问题.
- insert the prompts into the topmost L layers of the transformer (L ≤ N ):
prompts for L transformer layers: P l L P_l^L PlL - 其中, P_shape=[K, C], K表示每一层的prompt长度, C表示feature dimension.
在第l层中, 有长度为M的word-tokens: T l ∈ R M × C T_l ∈ R^{M×C} Tl∈RM×C 即: 长度为M, 每个token feature dimension为C. - 将prompt Pl 与 tokens Tl, 进行concatenation.
- 计算某一层中,第M+1个word和所有的K+M+1个token的关系

-
K A d a p t i o n P r o m p t s K \ Adaption \ Prompts K Adaption Prompts 的注意力分数,它代表从prompt中学到了多少信息去生成 t i t_i ti

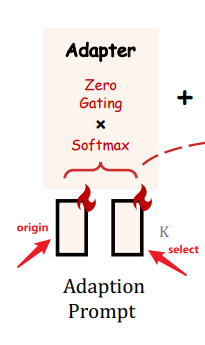
-
核心操作

-
门控系数g,来控制注意力的重要性(注意力分数的影响程度)
- 首先令g = 0,消除之前的prompt的影响程度
- 然后增加其幅度,以提供更多的指令语义给LLaMA模型。
- 这两个步骤需要分开,softmax。原因是,保证两部分的相互独立,不会受到之前的adaptive prompt的影响
- g一般分开取不同值与多头注意力一起
文章链接:https://arxiv.org/pdf/2303.16199.pdf
Paper3
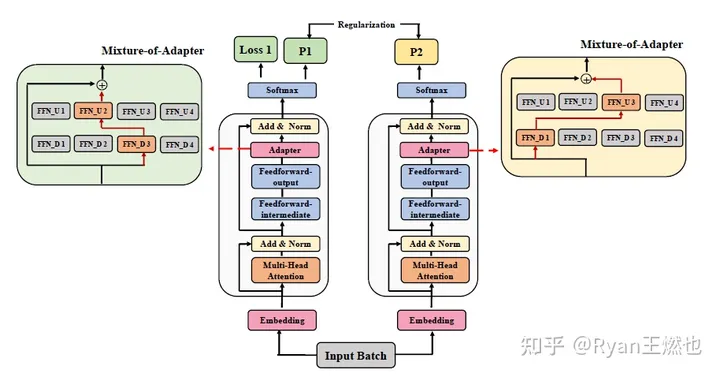
AdaMix
multi-view learning, mixture-of-experts的再利用**, 在adapter中设置了多个降维和升维通路**
- 训练过程中,adapter内进行随机路由;
- 推理过程中,则通过Averaging weights得到一个综合的降维升维通路
这种方式允许adapter进行multi-view learning,又不会增加相比单路adapter更多的参数。
Prefix Tuning
Optimizing Continuous Prompts for Generation
解决的问题:大模型进行微调的代价很大,应该怎么办?
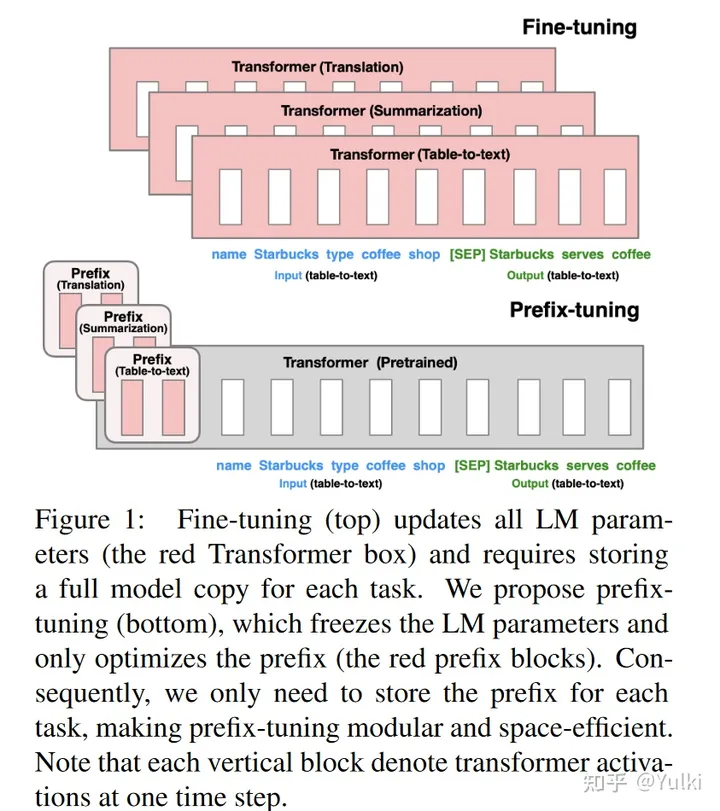
- 考虑生成数据表的文本描述的任务,如图 1 所示,其中任务输入是线性化表(例如,“名称:星巴克 | 类型:咖啡店”),输出是文本描述(例如,“星巴克供应咖啡。”)。
Prefix-tuning将一系列连续的特定于任务的向量添加到输入中,我们称之为Prefix(前缀)。- Transformer 可以将前缀视为一系列“虚拟token”,但与prompt不同,前缀完全由不对应于真实令牌的自由参数组成。
针对不同的任务,是需要微调prefix即可,不用去调Transformer本身的参数,所有参数量大幅度减小。(图中红色的部分是在微调过程中需要进行优化的地方)
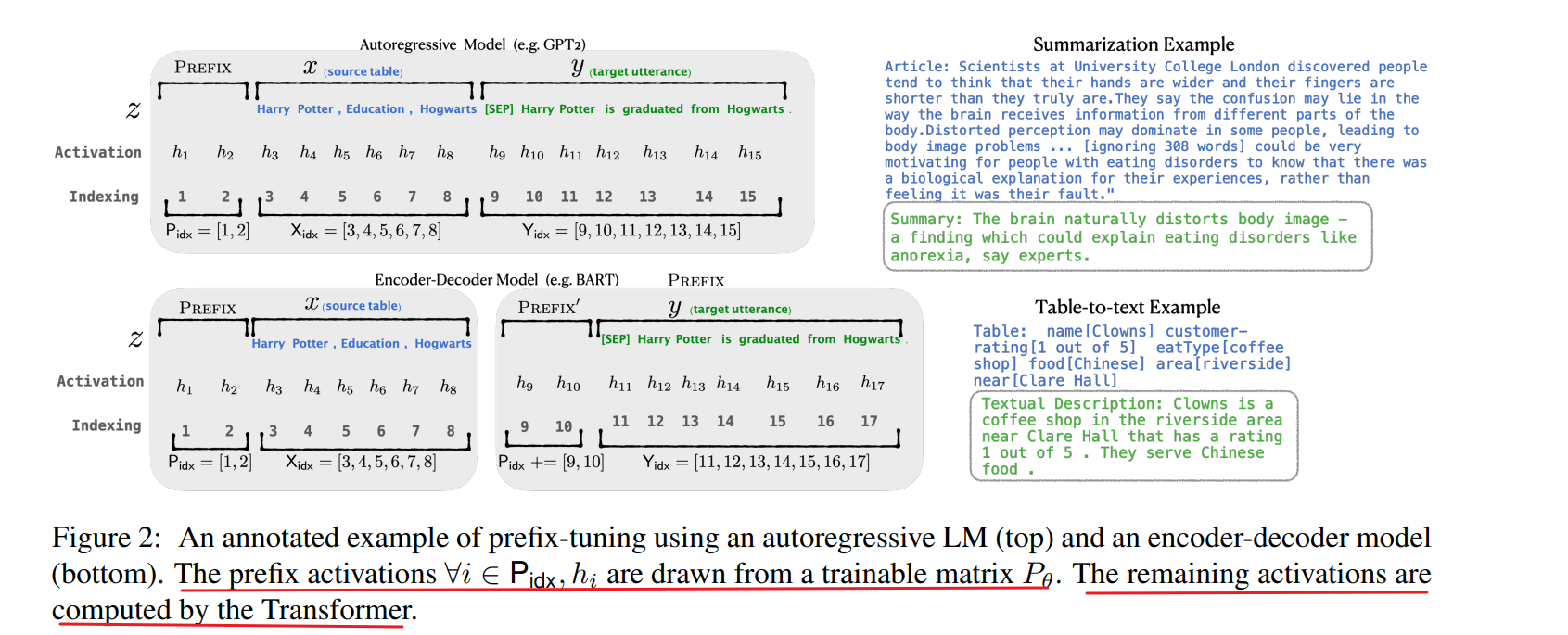
- 前缀的参数P, P θ P_θ Pθ 和 P θ ′ P_θ' Pθ′具有相同的行数(即前缀长度),但列数不同。一旦训练完成,这些重新参数化参数可以被丢弃,只需要前缀 P_θ已保存


Light weight Tuning 简述
轻量级微调。轻量级微调冻结了大部分预训练参数,并使用小的可训练模块修改预训练模型。关键挑战是确定模块的高性能架构和要微调的预训练参数子集。
- 一种研究方法考虑移除参数:通过在模型参数上训练二进制掩码,一些模型权重被消融掉。
- 另一种研究方法考虑插入参数。
- 通过求和将“边缘”网络与预训练模型融合;
- 适配器微调在预训练语言模型的每个层之间插入任务特定的层(适配器)。
与这一系列工作相比,该方法仅微调了LM参数的约3.6%,而我们的方法在保持可比性能的同时,进一步减少了任务特定参数的30倍,仅微调了0.1%。
Prompt Tuning 简述
提示是指在任务输入中添加前缀指令和一些示例,并通过语言模型生成输出。GPT-3(Brown等,2020)使用手动设计的提示来适应不同任务的生成,这个框架被称为上下文学习(In Context Learning)。
然而,由于Transformer只能在有限长度的上下文条件下进行(例如,对于GPT-3,上下文窗口为2048个标记),上下文学习无法充分利用比上下文窗口更长的训练集。
- Sun和Lai(2020)也通过关键词提示来控制生成句子的情感或主题。
- 在自然语言理解任务中,先前的研究已经探索了像BERT和RoBERTa这样的模型的提示工程(Liu等,2019; Jiang等,2020; Schick和Schutze,2020)。
- 例如,AutoPrompt(Shin等,2020)搜索一系列离散触发词,并将其与每个输入连接起来,以从掩码语言模型中引出情感或事实知识。
- 与AutoPrompt不同,我们的方法优化连续的前缀,这更具表达力(§7.2);
- 此外,我们专注于语言生成任务。连续向量已被用于引导语言模型;
- 例如,Subramani等(2020)表明,预训练的LSTM语言模型可以通过为每个句子优化一个连续向量来重构任意句子,使得向量具有输入特定性(input Prefix)。
- 相比之下,前缀微调优化了一个适用于该任务的所有实例的
特定前缀(task Prefix)。因此,与先前的工作仅限于句子重构不同,前缀微调可以应用于自然语言生成任务。
Soft Prompt Tuning
https://arxiv.org/pdf/2104.08691.pdf
-
核心:针对不同的任务设计不同的soft pormpt仅添加到embedding层中,仅训练这些参数。其余的参数都保持冻结,类似Prefix-tuning的想法,但是无论是token的长度以及所添加的位置都有一些差别
-
与 GPT-3 使用的离散文本提示不同,
软提示是通过反向传播学习的,并且可以调整以合并来自任意数量的标记示例的信号
引言:
- Prompt的缺点:需要人工设计,并且prompt的有效性受到诸多限制。GPT-3尽管比T5-XXL大了16倍,但是在SuperGLUE的分数上仍落后17.5.
- AutoPrompt:尽管自动设计Prompt的方法比人工设计的要好,但是仍落后于模型的微调。
- Prefix-tuning:冻结模型参数并在调整期间将错误反向传播到编码器堆栈中每个层(包括输入层)之前的前缀激活
作者冻结了整个预训练模型,只允许将每个下游任务的额外 k 个可调标记添加到输入文本中。这种“软提示”经过端到端训练,可以压缩来自完整标记数据集的信号,使我们的方法能够胜过少样本提示,并通过模型调整缩小质量差距。
什么是Prompt Tuning ?
在GPT-3中,提示标记(Prompt Tuning)的表示 P = p 1 , p 2 , . . . , p n P = {p1, p2, . . . , pn} P=p1,p2,...,pn是模型的嵌入表的一部分,由冻结的参数θ参数化。因此,找到最优提示需要通过手动搜索或非可微搜索方法选择提示标记。
提示微调消除了提示P由θ参数化的限制;相反,提示具有自己的专用参数θ,P,可以进行更新。虽然提示设计涉及从固定的冻结嵌入词汇中选择提示标记,但是可以将提示微调视为使用特殊标记的固定提示,其中只有这些提示标记的嵌入可以进行更新。

初始化:
- 从概念上讲,
我们的软提示以与输入之前的文本相同的方式调制冻结网络的行为,因此类似词的表示可能会作为一个很好的初始化点。 - 对于分类任务,将Prompt初始化为它对应的类别。提示越短,必须调整的新参数就越少,因此我们的目标是找到仍然表现良好的最小长度。

尽管这种结构比传统结构更加有效,但作者认为不是仅仅通过使用prompt tuning就能控制冻结的模型的。
T5使用的Span Corruption策略使得模型在训练和输出过程中始终存在哨兵标记,模型从来没有输出过真实完整的文本,这种模式可以通过Fine-tune很容易纠正过来,但是仅通过prompt可能难以消除哨兵的影响。
- Span Corruption:使用现成的预训练 T5 作为我们的冻结模型,并测试其为下游任务输出预期文本的能力
- Span Corruption + Sentinel【哨兵】:我们使用相同的模型,但在所有下游目标前加上一个哨兵,以便更接近预训练中看到的目标
- LM Adaptation:对于按原始方法训练好的T5模型,额外使用LM(语言模型)优化目标进行少量步骤的Finetune,使模型从输出带哨兵的文本转换为输出真实文本,期望T5和 GPT一样生成真实的文本输出。(这是本实验的默认设置)。至多100K step
其实可以看到,无论对哪个变量就行消融,只要模型的规模上去了,效果都差不多
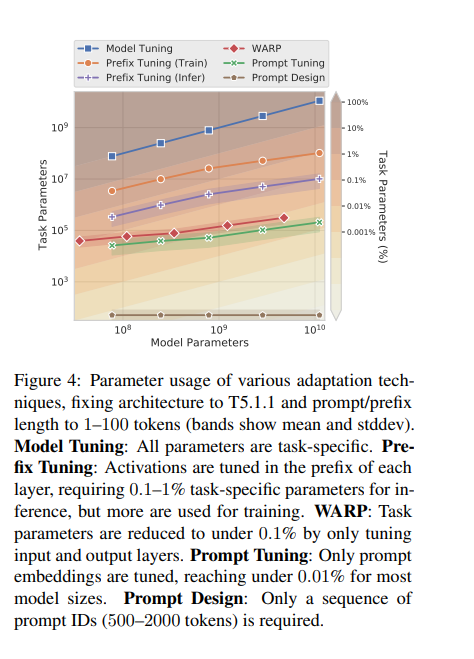
-
prompt tuning只需要在encoder加入prompt,而prefix tuning需要在encoder和decoder都添加
-
只在输入层加入可以防止模型的过拟合,因此prompt tuning可以迁移到别的领域上面
-
连续空间的prompt比离散空间的prompt难以解释
结论:
在SupreGLUE上,Prompt tuning的任务性能可与传统模型调整相媲美,随着模型尺寸的增加,差距会逐渐消失。在Zeor-shot领域迁移,有效提升泛化性。在few-shot上面可以看作,冻结模型的参数,限制为轻量级的参数有效避免过拟合。
- 核心:将下游任务的参数和预训练任务的参数分开
Code
- 代码Demo:https://huggingface.co/docs/peft/task_guides/clm-prompt-tuning