一、新建活动图(泳道图)
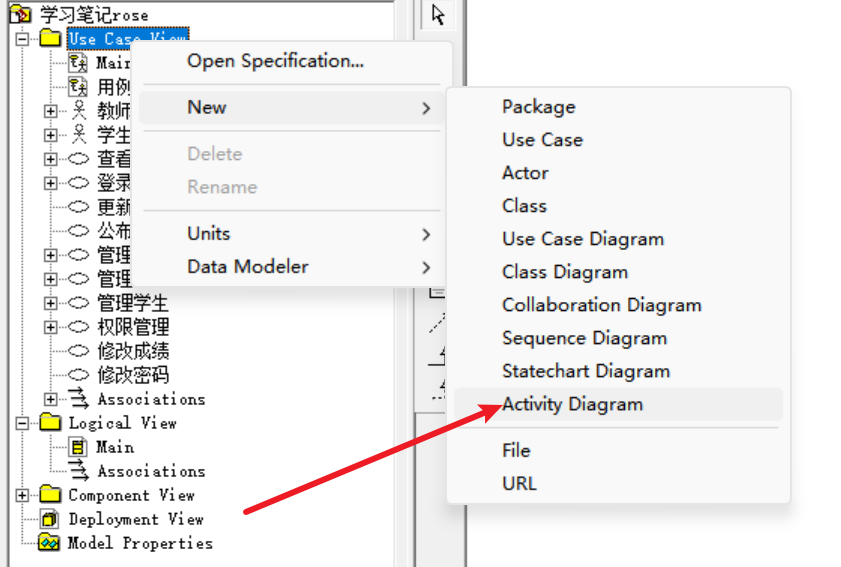
依旧在用例视图里面,新建一个activity diagram;新建好之后,就可以绘制活动图了:
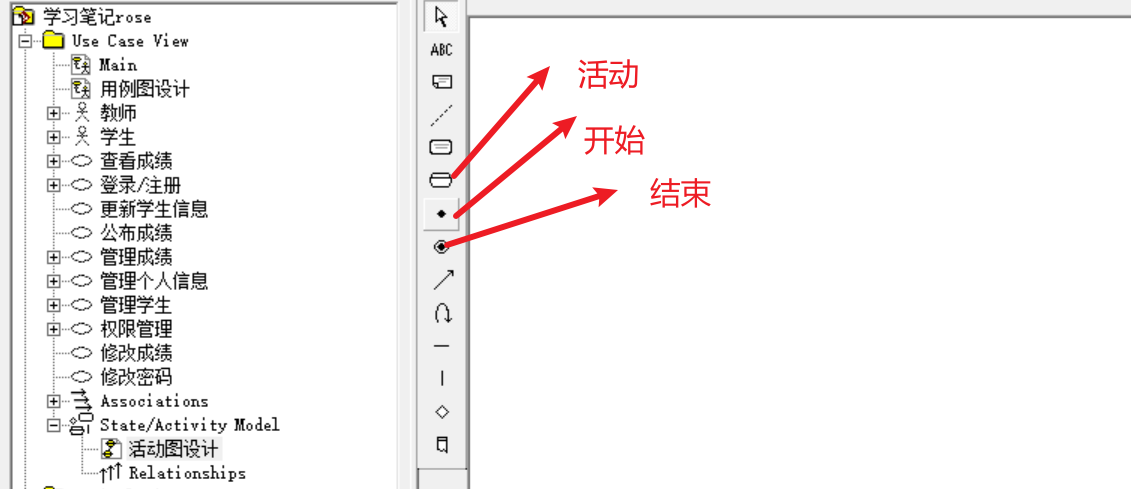
正常每个活动需要一个开始,点击黑点,然后在图中某个位置安放,接着就是新建各种活动:
rose绘制活动的时候,经常会出现这种字体不在同一行的问题,主要是因为文本框长度受限,只需要点一下活动这个框体 然后按住某个角落的黑点,拖动就行,可以选择放大也可以选择缩小。
然后按住某个角落的黑点,拖动就行,可以选择放大也可以选择缩小。
这儿的判断也可以同样的操作去改变文本框
连接好各个活动之后,修改线的横平竖直,这样规范(好看)一点
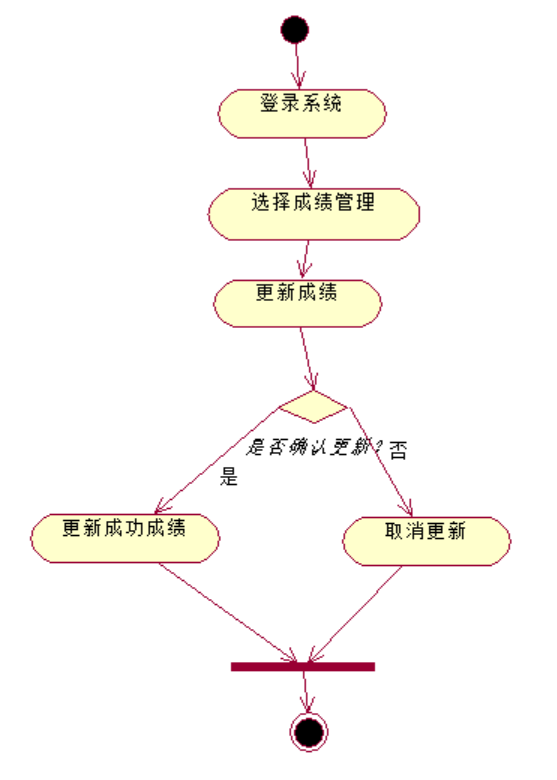
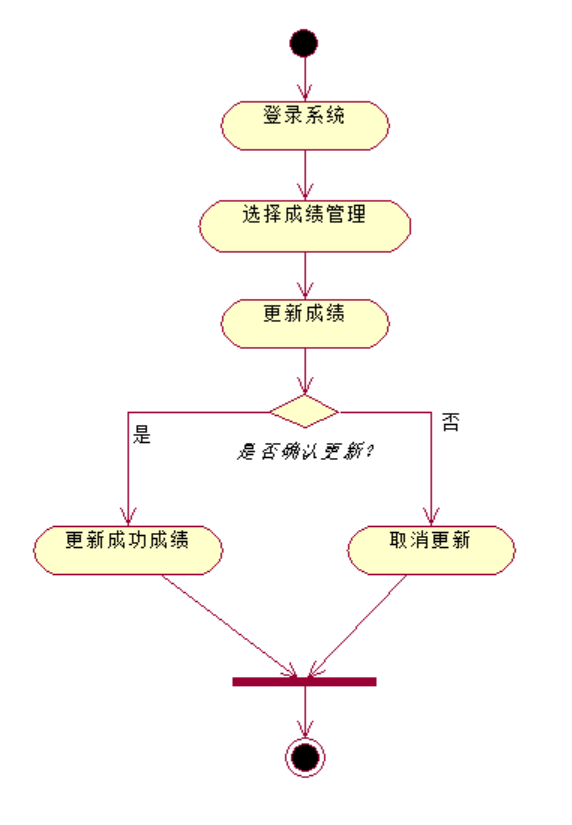
至此,一个简单的活动图就完成了;
复杂一点的情况,就是泳道图的设计;需要加入多个泳道:选择工具台最下方的图标来添加泳道:
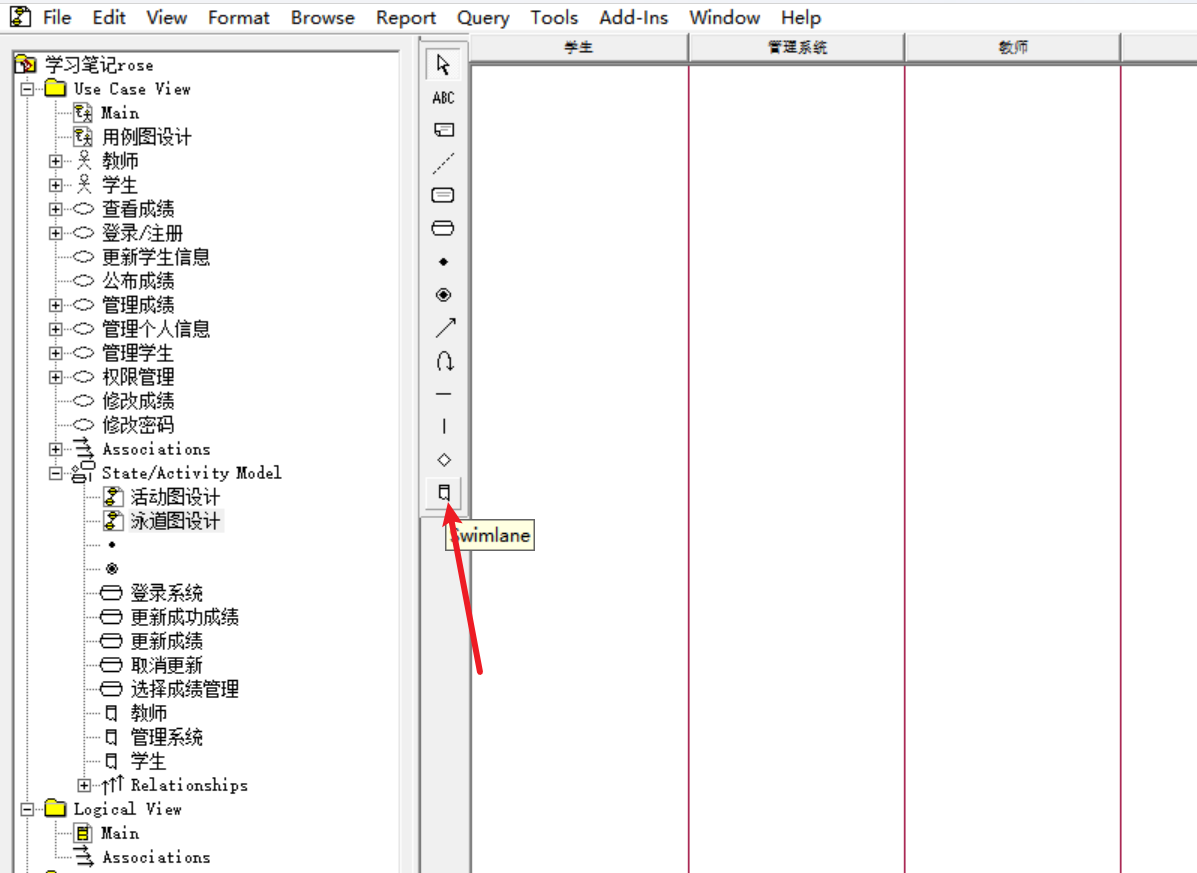
****这儿有个注意点!****有时候,新建另一个活动图,没办法再使用工作台当中的开始图标
这是因为重复了,可以直接在最左边找到开始图标(那个黑点)拖动到右边绘图区域就行了;;;
继续回到泳道图的说明:新建一些泳道好了之后,也可以适当修调整泳道的宽度,点击学生泳道,然后加宽:
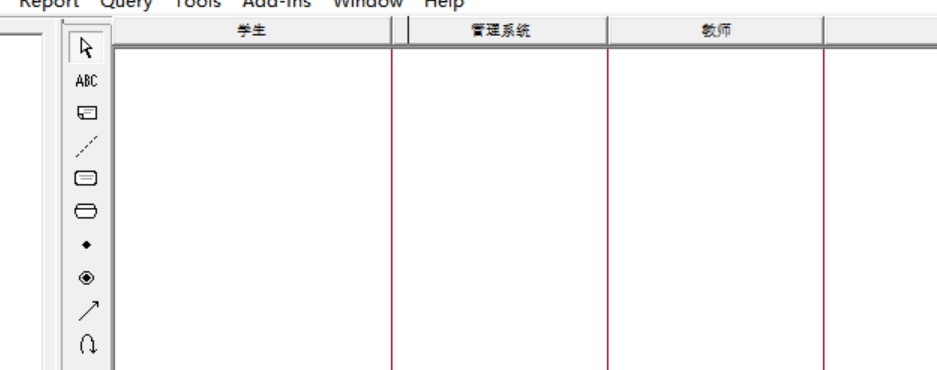
接着继续绘制活动就行:
有个注意点就是,活动按照流程进行,下一个活动图标放置的位置尽量别在上一个活动的水平线上方,平行或者往下放置都行。






