watermark
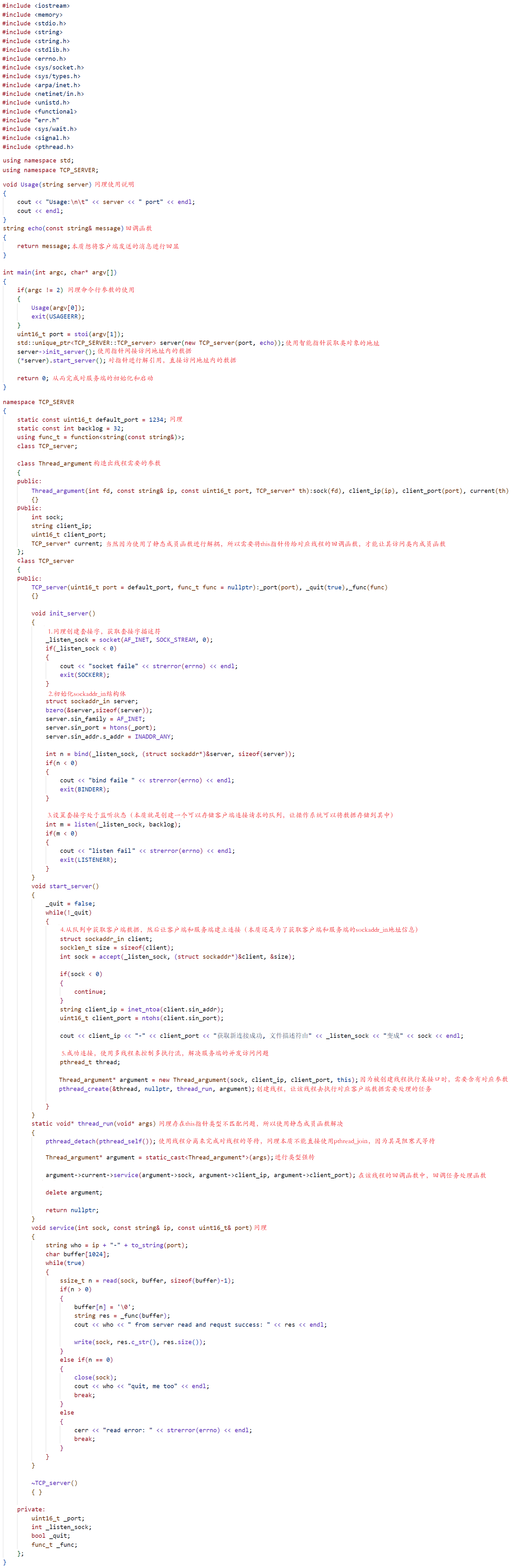
时间语义和 watermark
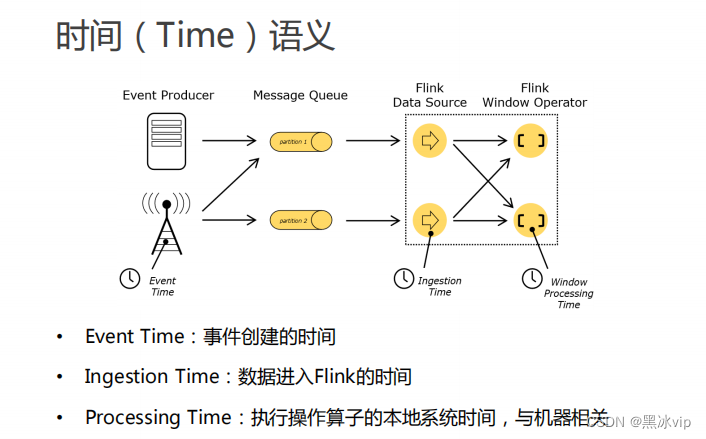
注意:数据进入flink的时间:如果用这个作为时间语义就不存在问题,但是开发中往往会用处理时间
作为时间语义这里就需要考虑延时的问题。
如上图,数据从kafka中获取出来,从多个分区中获取,这时候时间肯定有乱序,这时候就需要使用事
件时间。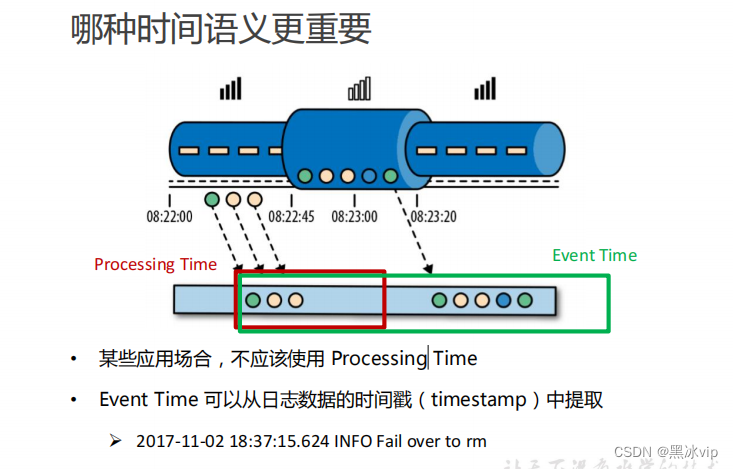
场景:游戏连续过五关,给予奖励
地铁里面玩游戏,连过三关断网了,二分钟过了八关。这时候是用处理时间还是事件时间呢?
处理时间的优势:牺牲一定的数据准确性,没有延迟
package com.atguigu.apitest.window;/**import com.atguigu.apitest.beans.SensorReading;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.timestamps.AscendingTimestampExtractor;
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.OutputTag;public class WindowTest3_EventTimeWindow {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();//默认为当前机器的cpu的最大核数//env.setParallelism(1);env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);env.getConfig().setAutoWatermarkInterval(100);// socket文本流DataStream<String> inputStream = env.socketTextStream("localhost", 7777);// 转换成SensorReading类型,分配时间戳和watermarkDataStream<SensorReading> dataStream = inputStream.map(line -> {String[] fields = line.split(",");return new SensorReading(fields[0], new Long(fields[1]), new Double(fields[2]));})// 乱序数据设置时间戳和watermark.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<SensorReading>(Time.seconds(2)) {@Overridepublic long extractTimestamp(SensorReading element) {return element.getTimestamp() * 1000L;}});OutputTag<SensorReading> outputTag = new OutputTag<SensorReading>("late") {};// 基于事件时间的开窗聚合,统计15秒内温度的最小值SingleOutputStreamOperator<SensorReading> minTempStream = dataStream.keyBy("id").timeWindow(Time.seconds(15)).allowedLateness(Time.minutes(1)).sideOutputLateData(outputTag).minBy("temperature");minTempStream.print("minTemp");minTempStream.getSideOutput(outputTag).print("late");env.execute();}
}
sensor_1,1547718199,35.8
sensor_6,1547718201,15.4
sensor_7,1547718202,6.7
sensor_10,1547718205,38.1
sensor_1,1547718207,36.3
sensor_1,1547718211,32.8
sensor_1,1547718212,37.1注意:第一个窗口是[1547718195,1547718210);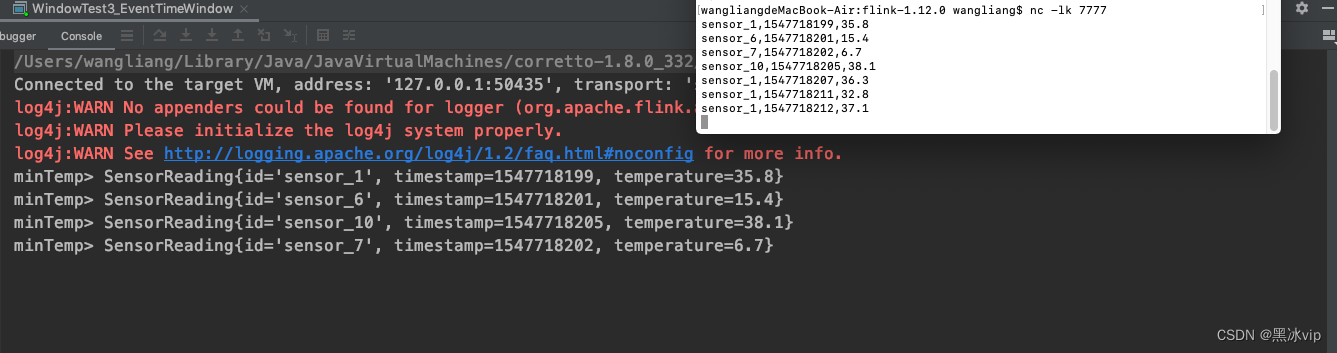
sensor_1,1547718213,33
sensor_1,1547718224,32.1
sensor_1,1547718225,31.6
sensor_1,1547718226,21.2
sensor_1,1547718227,33.6第二个窗口大小:第一个窗口是[1547718210,1547718225);
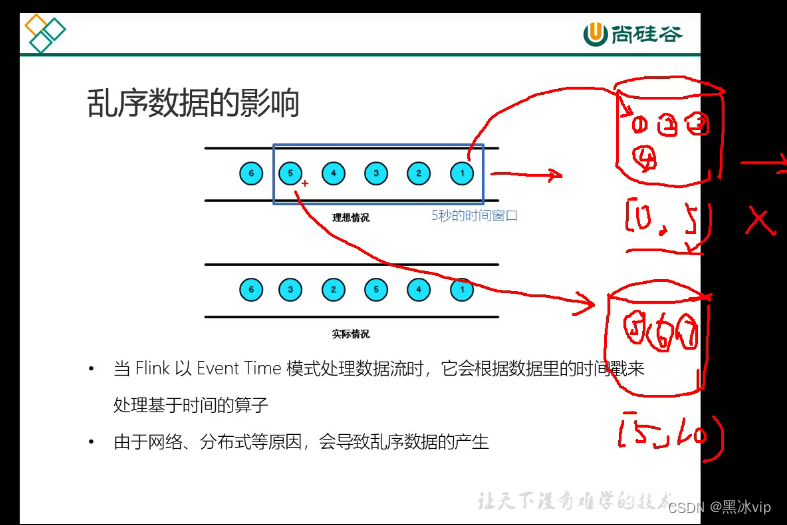
1.理想状态:来一条数据处理一条,每条数据代表对时间推进;如图到5之后就将【0,5)的窗口关闭并输出;2.乱序状态:原因:网络延迟、分布式、分区导致乱序数据产生;网络延迟和分布式处理造成的乱序都是几十毫秒和几百毫秒的范围的差距;这将回造成大多数延迟数据集中在几十毫秒和几百毫秒的范围内;3.解决方案:将时间事件放慢
flink的三重保证:1.设置watermaker将几百毫秒的数据全部输出;2.先输出一个近似的结果,但是不要关闭窗口后面延迟的时间还需要更新;3.当延时时间到了,窗口就关闭了;兜底方案使用侧输出流保证数据不丢失;注意:数据流中的 Watermark 用于表示 timestamp 小于 Watermark 的数据都已经到
达了,因此,window 的执行也是由 Watermark 触发的。
6 3 2 5 4 1
比如设置3秒的watermaker:
到达5:说明2秒之前的数据都到齐了,后面2,3都可以输出
到达6:说明3秒之前的数据都到齐了,大于等于3秒的数据才能输出意义:watermark 用来让程序自己平衡延迟和结果正确性:如果设置太大延迟太高,设置太
小数据就不准确,需要通过具体的业务场景去平衡这个值;
watermark 用来让程序自己平衡延迟和结果正确性:如果设置太大延迟太高,设置太小,乱序数据
没有搞定,数据就不准确,需要通过具体的业务场景去平衡这个值;如何找到watermaker:首先要了解乱序程度;
解决方案:通过机器学习构建一个模型,构建当前业务模型中的延迟状态的分布情况;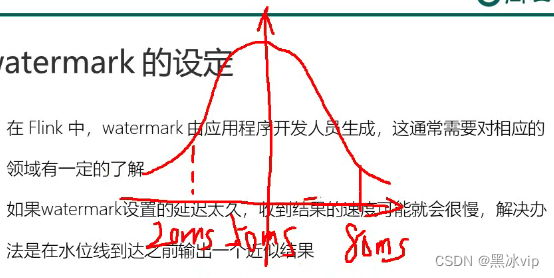
如图:大部分的延时数据都20ms和80ms之间的范围中,这时候设置80ms就搞定大部分乱序数据;
这时候还有很少的数据,如果对数据准确性要求比较高,这时候就需要设置窗口迟到机制去保证
数据的准备性;最后还有网络延迟的数据还是没有输出这时候就需要添加侧输出流作为兜底方案。watermark 生成问题

默认:来一条生产一条watermaker,如果短时间数据量比较大,会造成watermaker都一样造成资
源浪费;周期性添加watermaker:每隔一段时间更新一下watermaker
周期性时间缺点:实时性不好;数据过于分散会造成资源浪费;如何选择:看数据的分布,过于集中使用周期性生成模式,数据稀疏,使用默认的模型;

状态编程
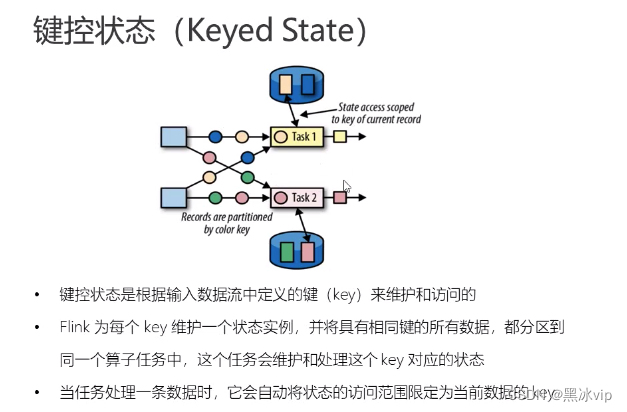

需求:我们可以利用 Keyed state,实现这样一个需求: 检测传感器的温度值,如果连续的两个温度差值超过 10 度,就输出报警
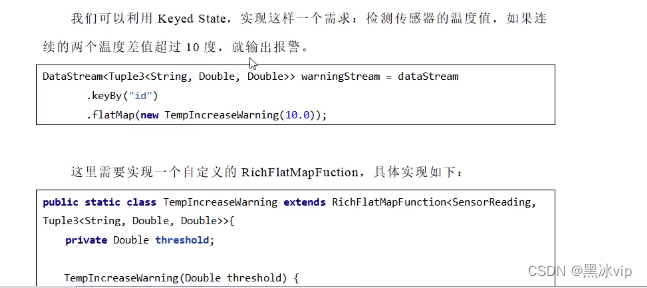
package com.atguigu.apitest.state;/*** Copyright (c) 2018-2028 尚硅谷 All Rights Reserved* <p>* Project: FlinkTutorial* Package: com.atguigu.apitest.state* Version: 1.0* <p>* Created by wushengran on 2020/11/10 16:33*/import com.atguigu.apitest.beans.SensorReading;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.RichFlatMapFunction;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;/*** @ClassName: StateTest3_KeyedStateApplicationCase* @Description:* @Author: wushengran on 2020/11/10 16:33* @Version: 1.0*/
public class StateTest3_KeyedStateApplicationCase {public static void main(String[] args) throws Exception{StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);// socket文本流DataStream<String> inputStream = env.socketTextStream("localhost", 7777);// 转换成SensorReading类型DataStream<SensorReading> dataStream = inputStream.map(line -> {String[] fields = line.split(",");return new SensorReading(fields[0], new Long(fields[1]), new Double(fields[2]));});// 定义一个flatmap操作,检测温度跳变,输出报警SingleOutputStreamOperator<Tuple3<String, Double, Double>> resultStream = dataStream.keyBy("id").flatMap(new TempChangeWarning(10.0));resultStream.print();env.execute();}// 实现自定义函数类public static class TempChangeWarning extends RichFlatMapFunction<SensorReading, Tuple3<String, Double, Double>>{// 私有属性,温度跳变阈值private Double threshold;public TempChangeWarning(Double threshold) {this.threshold = threshold;}// 定义状态,保存上一次的温度值private ValueState<Double> lastTempState;@Overridepublic void open(Configuration parameters) throws Exception {lastTempState = getRuntimeContext().getState(new ValueStateDescriptor<Double>("last-temp", Double.class));}@Overridepublic void flatMap(SensorReading value, Collector<Tuple3<String, Double, Double>> out) throws Exception {// 获取状态Double lastTemp = lastTempState.value();// 如果状态不为null,那么就判断两次温度差值if( lastTemp != null ){Double diff = Math.abs( value.getTemperature() - lastTemp );if( diff >= threshold )out.collect(new Tuple3<>(value.getId(), lastTemp, value.getTemperature()));}// 更新状态lastTempState.update(value.getTemperature());}@Overridepublic void close() throws Exception {lastTempState.clear();}}
}
sensor_1,1547718206,36.3
sensor_1,1547718206,37.9
sensor_1,1547718206,48
sensor_6,1547718201,15.4
sensor_6,1547718201,35
sensor_1,1547718226,36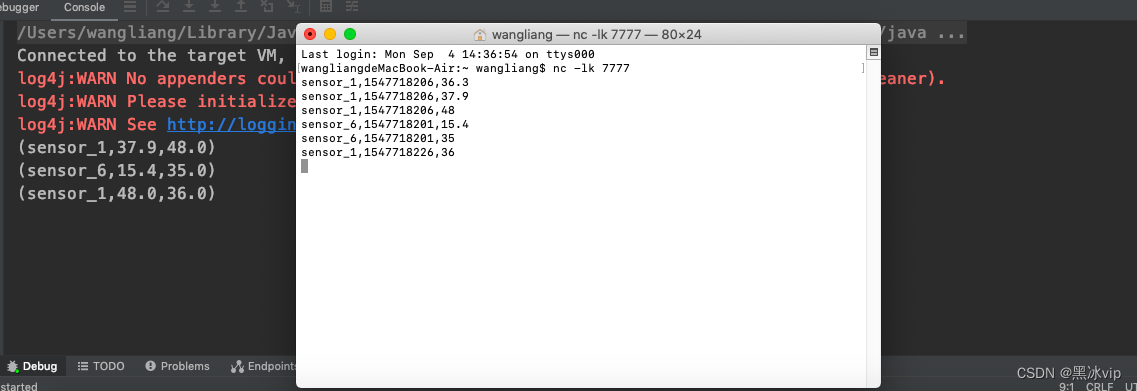
状态后端

状态后端: 1.本地的状态管理(如何存,上下文配置,怎么存,怎么写) 2.做快照容错,如何恢复数据
1. 测试环境:MemoryStateBackend
2. 生产环境:FsStateBackend
3. 数据非常大时候:RocksDBStateBackendstate.backend: filesystem //默认使用FsStateBackend
tate.checkpoints.dir: hdfs://namenode-host:port/flink-checkpoints
//配置一个checkpoint的hdfs的存储路径jobmanager.execution.failover-strategy: region //区域化重启state.backend.incremental: false //增量添加checkpoint