Redis
Redis 是基于键值对的非关系型数据库。Redis 拥有string、hash、list、set、zset等多种数据结构, redis具有惊人的读写性能, 其优秀的持久化机制是的它在断电和机械故障时也不会发生数据丢失, 可以用于热点数据存放, 还提供了键过期、发布订阅、食物、流水线、LUA脚本等多个高级功能。
1 Redis 数据结构
-
string: 最基本数据类型, 可以存放入二进制、序列化数据、JSON对象、图片等数据-
底层实现:
SDS(Simple Dynamic String) - 动态字符串可修改字符串, 采用预分配冗余空间的方式减少内存的频繁分配。与Java中的ArrayList比较类似, 实质上也是在空间不足时触发扩容机制, 如果 SDS 值大小< 1M , 则增加一倍;反之如果>1M , 则当前空间加1M作为新的空间。
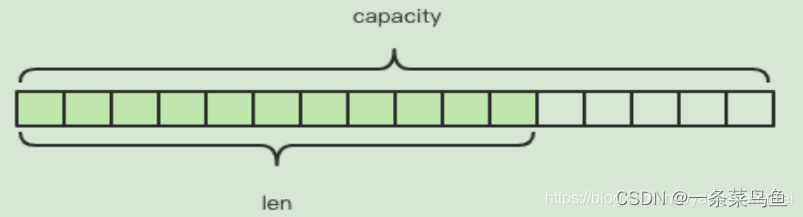
struct sdshdr{//记录buf数组中已使用字节的数量//等于SDS保存字符串的长度4byteint len;//记录 buf数组中未使用字节的数量 4 byteint free;//字节数组,用于保存字符串字节\0结尾的字符串占用了1bytechar buf[]; }
-
-
list: 字符串列表, 按照插入的顺序排序, 元素可以重复, 底层由链表实现。-
底层实现:
ZIPList| LinkedList(双向链表)当元素字符串的长度小于64字节而且元素个数小于512时,采用 zipList;否则采用likedList;
-
ZIPList - 压缩列表: 由连续内存块组成且用于存储小型有序集合或哈希集合的数据结构。主要参数包括: 整个列表占用字节数、偏移量、元素个数、内容列表、结束标志。 优点: 节省空间

struct ziplist<T> {int32 zlbytes; // 整个压缩列表占用字节数int32 zltail_offset; // 最后一个元素距离压缩列表起始位置的偏移量,用于快速定位到最后一个节点int16 zllength; // 元素个数T[] entries; // 元素内容列表,挨个挨个紧凑存储int8 zlend; // 标志压缩列表的结束,值恒为 0xFF }
-
-
-
hash: string 类型 field 和 value 的集合, 适合存放对象-
底层实现:
ZIPList | HashTable当hash对象的键与值的长度都小于64字节时而且键值对的个数小于512个,采用zipList,其它情况,采用hashTable
-
ZIPLIST: 参考上述 -
HashTable - 哈希表① 数组 + 链表 ②数组+红黑树(树化方便查找)
根据Key value而直接进行访问的数据结构。它通过把关键码值映射到表中一个位置来访问记录(类似索引),以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
-
-
-
set: 无序不重复的集合-
底层实现:
INTSet | HashTable当保存的元素都是整形数字,而且元素个数小于配置范围的时候,则使用intset,否则使用hash表。
-
INTSet - 整数集合可变长度的整型数组 - 基于整数数组来实现,并且具备长度可变、有序等特征, 包含: 编码方式、长度、内容等主要属性(可以选择不同位数的整数存储)。
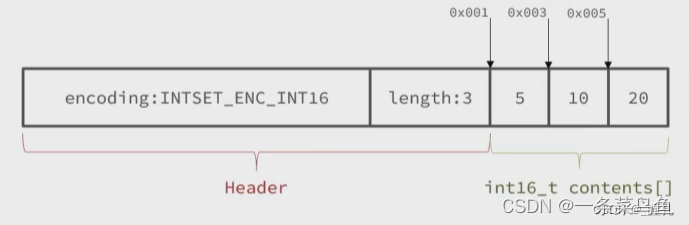
typedef struct intset {uint32_t encoding; /* 编码方式,支持存放16位、32位、64位整数 */uint32_t length; /* 元素个数 */int8_t contents[]; /* 整数数组,保存集合数据 */ } intset;
-
-
-
zset: 与 set 一样都是 String 类型元素的集合, 且不允许重复, 但 zset 每个元素都会关联一个分数, Redis通过分数来为集合汇总的成员进行从小到大的排序。-
底层实现:
ZIPList| SKIPList-
ZIPList: 参考上述 -
SKIPList:一种有序的数据结构,通过在每个节点维护多个指针,从而达到快速访问的目的。 优点: 实现简单、内存消耗少 缺点: 不适合范围查询
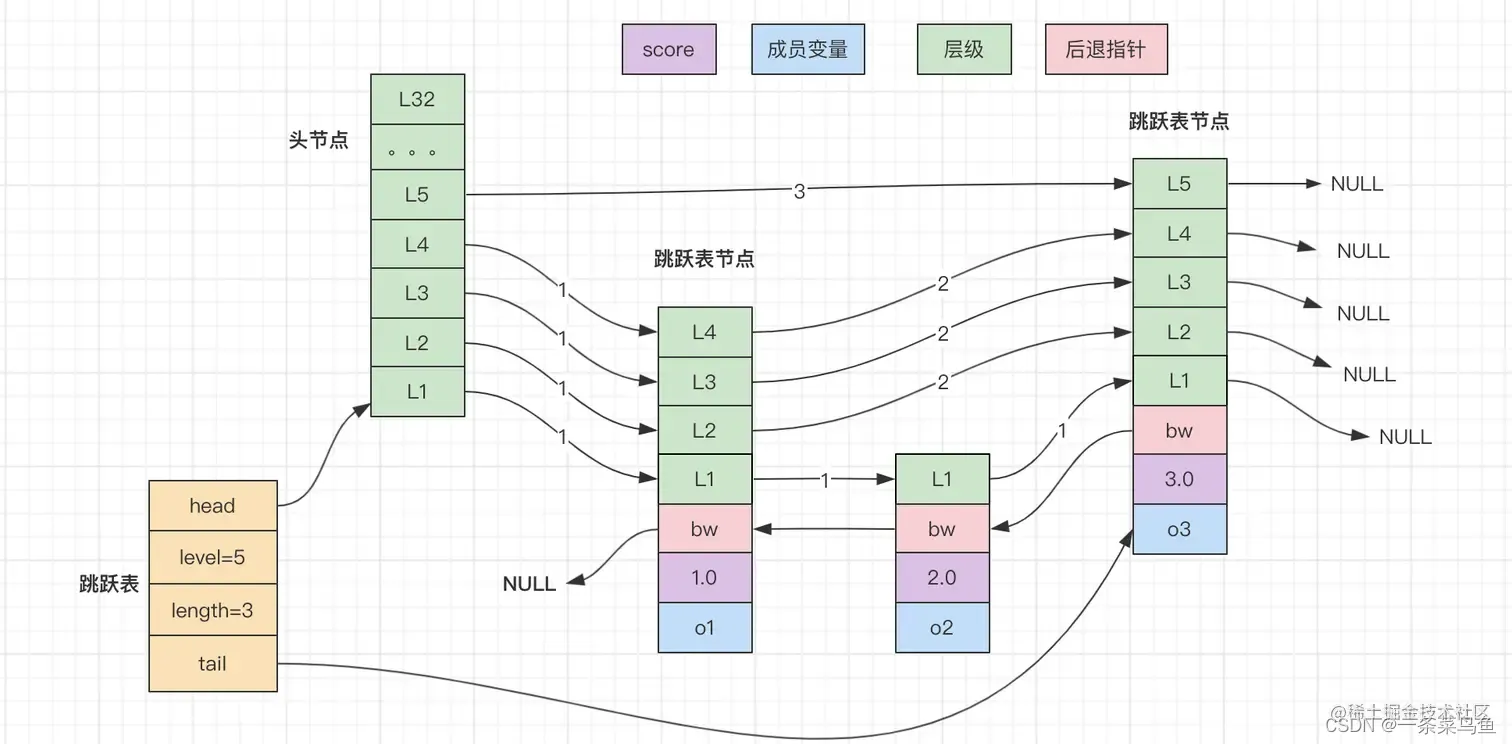
跳跃表 - 跳跃表节点结构定义
typedef struct zskiplist{// 表头节点和表尾节点struct zskiplist *header,*tail;// 表节点个数unsigned long length;// 表节点最大层数int level; }zskiplist;typedef struct zskiplistNode{// 层struct zskiplistLevel{// 前进指针struct zskiplistNode *forward;// 跨度unsigned int span;}level[];// 后退指针struct zskiplistNode *backward;// 分值double score;// 成员对象robj *robj; }zskiplistNode;
-
-
-
四种特殊数据类型: 1)bitmap 2)hyperloglog 3)geo 4)stream
1) zset 与 set 的区别
-
set 无序, zset 有序
-
zset 底层使用压缩列表和跳跃列表( ziplist & skiplist )
set 使用 INTSet 和 HashTable
2 Key 过期策略
-
定期删除-过期 Key 保存在字典, 定期随机抽取20个Key, 删除其中过期的, 如果比例超过1/4, 重复删除步骤。redis 会将每个设置了过期时间的 key 放入到一个独立的字典中,以后会定期遍历这个字典来删除到期的 key。
Redis 默认会每秒进行十次过期扫描(100ms一次),过期扫描不会遍历过期字典中所有的 key,而是采用了一种简单的贪心策略。
1.从过期字典中随机 20 个 key;
2.删除这 20 个 key 中已经过期的 key;
3.如果过期的 key 比率超过 1/4,那就重复步骤 1;
redis默认是每隔 100ms就随机抽取一些设置了过期时间的key,检查其是否过期,如果过期就删除。注意这里是随机抽取的。为什么要随机呢?你想一想假如 redis 存了几十万个 key ,每隔100ms就遍历所有的设置过期时间的 key 的话,就会给 CPU 带来很大的负载。
-
惰性删除-访问时发现 Key 过期, 直接删除不返回任何值在客户端访问这个key的时候,redis对key的过期时间进行检查,如果过期了就立即删除,不会给你返回任何东西。
定期删除可能会导致很多过期key到了时间并没有被删除掉。所以就有了惰性删除。假如你的过期 key,靠定期删除没有被删除掉,还停留在内存里,除非你的系统去查一下那个 key,才会被redis给删除掉。这就是所谓的惰性删除,即当你主动去查过期的key时,如果发现key过期了,就立即进行删除,不返回任何东西。
3 内存淘汰策略
数据的淘汰策略: 当Redis中的内存不够用时,此时在向Redis中添加新的key,那么Redis就会按照某一种规则将内存中的数据删除掉,这种数据的删除规则被称之为内存的淘汰策略。
-
noeviction: 不淘汰任何key,但是内存满时不允许写入新数据,默认策略。
-
volatile-TTL: 对设置了TTL的key,比较key的剩余TTL值,TTL越小越先被淘汰。
-
allkeys -RANDOM: 对全体key,随机进行淘汰。
-
volatile-RANDOM: 对设置了TTL的key,随机进行淘汰。
-
alkeys -LRU: 对全体key,基于LRU算法进行淘汰
-
volatile-LRU: 对设置了TTL的key,基于LRU算法进行淘汰
-
allkeys -LFU: 对全体key,基于LFU算法进行淘汰
-
volatile-LFU: 对设置了TTL的key,基于LFU算法进行淘汰
4 主从同步机制
-
主从同步
-
全量同步
一般发生在第一次连接时, 原理为将当前数据写入到RDB文件后发送给从机读取到丛机的内存中。
-
增量同步
一般发生在第一次之后的链接时, 主机同步期间发生的数据变化会以命令的形式写入缓存中, 当校验到正确的从机ID时获取从机的偏移量,然后从偏移量记录的命令开始将未同步的数据操作命令发送给从机执行, 进而完成数据同步。
-
updating …