文章目录
-
目录
文章目录
前言
实验准备
一.批量登录 IP 连续的设备
1.1.1 实验代码
1.1.2 代码分段分解
1.1.3 实验结果验证
二.批量登录 IP 不连续的设备
2.2.1 实验代码
2.2.2 代码分段分解
2.2.3 实验结果验证
前言
在生产环境中,我们通常需要登录多个设备进行配置,设备的管理IP少数情况是同一网段的连续IP,然而在多数情况下,设备的管理IP是不连续的,在这种情况下,我们就不能简单的使用for循环来登录设备,我们要额外建立一个文本文件,把需要登录的交换机的管理IP地址全部写进去,然后用for循环配合open()函数来读取该文档中的管理IP地址,从而达到批量登录设备的目的。
实验准备

环境要求:
- 所有交换机配置IP地址如上图
- 所有交换机配置SSH服务,用户名为python,密码为1234,用户权限为15级
- 本地电脑使用SSH远程工具(如:Xsehll)能够正常连接交换机
一.批量登录 IP 连续的设备
1.1.1 实验代码
import paramiko
import time
import getpassdef SSH_Server(ip, username, password):ssh_client = paramiko.SSHClient()ssh_client.set_missing_host_key_policy(paramiko.AutoAddPolicy())ssh_client.connect(hostname=ip, username=username, password=password)print(f"Successfully connected to {ip}")last_octet = int(ip.split(".")[-1])loopback_ip = f"{last_octet}.{last_octet}.{last_octet}.{last_octet}"commend = ssh_client.invoke_shell()commend.send("sys\n")commend.send(f"int loop 1\n")commend.send(f"ip address {loopback_ip} 255.255.255.255\n")commend.send("return\n")commend.send("save\n")commend.send("Y\n")time.sleep(2)output = commend.recv(65535)print(output.decode("ascii"))ssh_client.close()username = input("请输入用户名:")
password = getpass.getpass("请输入密码:")for IP in [12, 13, 14]:ip = f"192.168.223.{IP}"SSH_Server(ip, username, password)1.1.2 代码分段分解
关于SSH连接的paramiko模块的有关代码此处不再赘述与前文几乎一致,下面重点讲述使用for循环批量登录设备(SW2~SW4)。
for IP in [12, 13, 14]:ip = f"192.168.223.{IP}"SSH_Server(ip, username, password)- 使用
for循环遍历列表[12, 13, 14],每次循环生成一个新的 IP 地址192.168.223.{IP}。 - 调用
SSH_Server函数,使用生成的 IP 地址、用户输入的用户名和密码连接到远程服务器,并执行相应的配置命令
1.1.3 实验结果验证
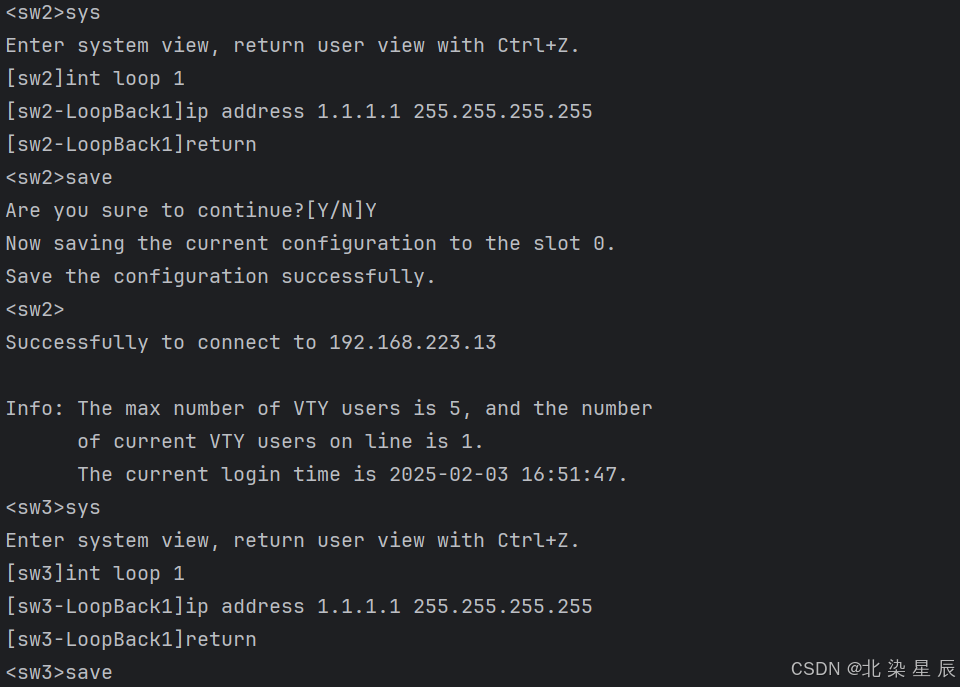
二.批量登录 IP 不连续的设备
实验准备:
在本地电脑创建一个名为ip_list的txt文件,写入交换机的IP地址,注意该文件需要和python代码文件处于同一目录下。

2.2.1 实验代码
import paramiko
import time
import getpassdef SSH_Server(ip, username, password):ssh_client = paramiko.SSHClient()ssh_client.set_missing_host_key_policy(paramiko.AutoAddPolicy())ssh_client.connect(hostname=ip, username=username, password=password)print(f"Successfully connected to {ip}")commend = ssh_client.invoke_shell()commend.send("sys\n")commend.send("undo stp enable\n")commend.send("Y\n")time.sleep(2)output = commend.recv(65535)print(output.decode("ascii"))ssh_client.close()username = input("请输入用户名:")
password = getpass.getpass("请输入密码:")with open("ip_list","rt") as file:for ip in file.readlines():SSH_Server(ip.strip(),username,password)
2.2.2 代码分段分解
上述代码稍作修改,由原先的创建换回口改为关闭交换机默认开启的stp服务,下面重点讲解如何使用open()函数读取IP从而实现批量登录IP不同的交换机(SW2和SW5)。
with open("ip_list", "rt") as file:open("ip_list", "rt"):使用open函数打开名为ip_list的文件。其中,第一个参数"ip_list"是要打开的文件名;第二个参数"rt"表示以文本模式(t)进行只读操作(r)。文本模式是默认模式,所以也可以简写为"r"。with...as语句:这是 Python 中的上下文管理器,它会自动处理文件的打开和关闭操作。当代码块执行完毕或发生异常时,会自动关闭文件,避免手动调用file.close()可能出现的资源泄漏问题。file是文件对象,后续可以通过该对象对文件进行读取等操作。
for ip in file.readlines():file.readlines():调用文件对象的readlines方法,该方法会读取文件中的所有行,并将每一行作为一个元素存储在列表中返回。列表中的每个元素是一个字符串,且行末的换行符\n会被保留。for ip in...:使用for循环遍历file.readlines()返回的列表。每次循环,变量ip会依次指向列表中的每个元素,即文件中的每一行(包含换行符)。
SSH_Server(ip.strip(), username, password)ip.strip():调用字符串对象的strip方法,该方法会移除字符串首尾的空白字符(包括空格、制表符、换行符等),返回一个新的字符串。因为readlines方法返回的每行字符串可能包含换行符,使用strip方法可以确保传递给SSH_Server函数的 IP 地址是纯净的,不包含多余的空白字符。SSH_Server(ip.strip(), username, password):调用之前定义的SSH_Server函数(在你之前提供的代码中有定义),将处理后的 IP 地址、用户名和密码作为参数传递给该函数,尝试通过 SSH 连接到对应的服务器并执行相应的配置操作。
2.2.3 实验结果验证




















