主从复制
单点问题:
在分布式系统中,如果某个服务器程序,只有一个节点(也就是一个物理服务器)来部署这个服务器程序的话,那么可能会出现以下问题:
1.可用性问题:如果这个机器挂了,那么意味着怎么服务器也就挂了
2.性能/支持的并发量也是有限的
在分布式系统中,往往会希望多个服务器来部署Redis服务,从而构造一个Redis集群;此时就可以让这个集群给整个分布式提供更加高效/稳定的数据存储服务等;
在分布式系统中,有多个服务器部署Redis,往往有以下几种方式:
1.主从模式
2.主从+哨兵
3.集群
配置主从模式:
在若干个Redis节点中,有“主”节点,也有“从”节点
例如:

从节点必须听主节点,从节点内的数据跟主节点保存同步(从节点就是主节点的副本)~
在原本,只有一个主节点保持大量的数据,引入从节点,可以将主节点上的数据复制出来放到从节点中,后续主节点有任何修改也会同步到从节点上~
主从模式主要是针对“读操作”进行并发了和可用性的提高
而“写操作”只能依赖主节点,主节点只能有一个
在实际业务中,“读操作”往往比“写操作”更加频繁
如果挂了从节点的话,影响并不会很多啊,可以从其他从节点读取数据,效果是一样的;
但如果挂了主节点的话,那么只能读数据,不能写数据了,还有有一定的影响~
因为目前只有一台云服务器,所有需要启动多个Redis服务器进程,配置一个主节点,俩个从节点
主节点默认端口为6379,从节点默认端口分别为6380,6381
1.给从节点设置配置文件
root@iZbp1j57qexhmdoyijkse9Z:/etc/redis# mkdir redis-conf
root@iZbp1j57qexhmdoyijkse9Z:/etc/redis# cd redis-conf/
root@iZbp1j57qexhmdoyijkse9Z:/etc/redis/redis-conf# pwd
/etc/redis/redis-conf
root@iZbp1j57qexhmdoyijkse9Z:/etc/redis/redis-conf# cp /etc/redis/redis.conf ./slave1.conf
root@iZbp1j57qexhmdoyijkse9Z:/etc/redis/redis-conf# cp /etc/redis/redis.conf ./slave2.conf
root@iZbp1j57qexhmdoyijkse9Z:/etc/redis/redis-conf# ls
slave1.conf slave2.conf
在它们的配置文件中修改:
修改端口号



修改其 daemonize 为 yes。



删除它们的进程 重新启动

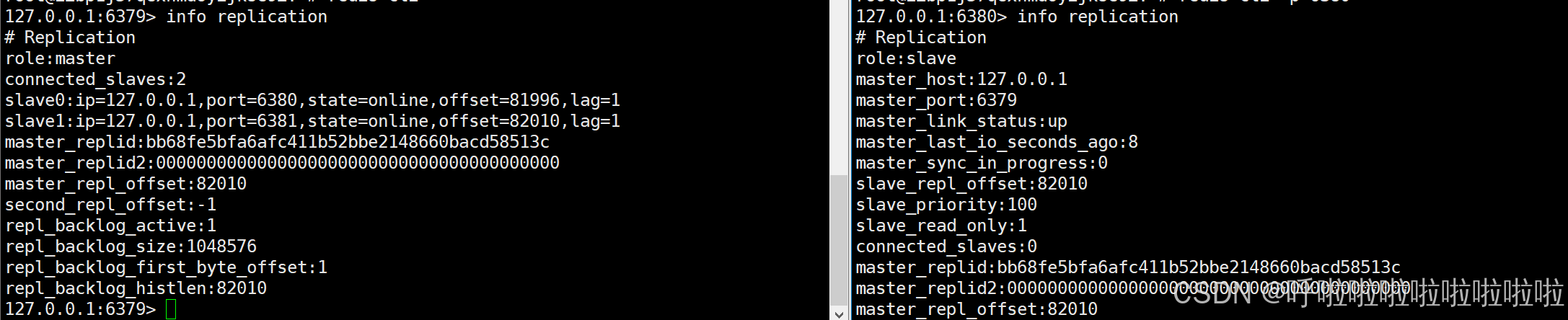
此时用命令 info replication 可以查看它们当前的属性
127.0.0.1:6379> set key 111
OK
127.0.0.1:6379> get key
"111"
127.0.0.1:6379>
root@iZbp1j57qexhmdoyijkse9Z:/etc/redis/redis-conf# redis-cli -p 6380
127.0.0.1:6380> get key
"111"
127.0.0.1:6380> set key 222
(error) READONLY You can't write against a read only replica.
此时主节点插入了数据 从节点也可以查询到,但是从节点不能插入数据
此时我们的结构已经搭建完成
拓扑结构:
若干个节点之间,按照怎么样的方式来进行组织连接:一主一从、一主多从、树状主从结构。
一主一从

这是最简单的结构,用于主节点出现宕机时从节点提供故障转移支持;
如果写数据请求太多的话,会给主节点带来一定的压力;
那么可以关闭主节点的AOF机制,只保留从节点上的AOF,这样既可以保证数据的安全性,也可以避免持久化对主节点的性能影响;
但如果主节点挂了的话,此时没有AOF文件,那么将会丢失数据,进一步进行主从同步,从节点的数据也被删除了~
改进方法:当主节点挂了话,主节点从从节点上获取AOF文件数据
一主多从
在数据量较大的场景下,可以把读命令负载均衡到不同的从节点上分担压力;
同时一些耗时的读命令可以指定⼀台专门的从节点执行,避免破坏整体的稳定性。
但是随之从节点的增加,同步每一条数据,就需要传输多次,导致主节点的负载
树形结构:

树据写入节点 A 之后会同步给 B 和 C 节点,B 节点进一步把数据同步给 D 和 E 节点。当主节点需要挂载等多个从节点时为了避免对主节点的性能干扰,但同步的延时是比刚才长的
原理:
主从节点建立复制流程图:

1.先保存主节点的ip和端口变量等信息
2、建立TCP的网络连接,三次握手,为了验证通信双方是否能够正确的读写数据
3.验证主节点是否能够正常的工作 从节点发送ping命令 主节点返回pong
4.如果主节点设置了 requirepass 参数,则需要密码验证
数据同步:
Redis提供了psync命名完成主从数据的同步
PSYNC 的语法格式 PSYNC replicationid offset
理解下面过程,先了解一下前提概念:
1.replicationid/replid (复制id)
主节点的复制id,主节点重新启动,或者从从节点晋升到主节点的时候,也会生成这个id(即便是同一个主节点,在它重启的时候,生成的id都是不同的)
主节点和从节点建立复制关系的时候,就会从主节点这边获取replicationId
2.offset(偏移量)
这个是主节点和从节点上都会维护的一个参数-------偏移量(整数)
主节点上会收到很多的修改操作的命令,每个命令会占据几个字节,煮鸡蛋会把这些修改命令的字节数都累加起来~
从节点的偏移量就描述了此时从节点这边的数据同步到哪一步~
如果从节点和主节点上的偏移量一致,说明已经同步了~
replid + offset 共同标识了一个 "数据集".
如果两个节点, 他们的 replid 和 offset 都相同, 则这两个节点上持有的数据, 就一定相同.
在 info replication 命令中可以查看到:
psync过程:

1)从节点发送 psync 命令给主节点,replid 和 offset 的默认值分别是 ? 和 -1.
2)主节点根据 psync 参数和自身数据情况决定响应结果:
- 如果回复 +FULLRESYNC replid offset,则从节点需要进行全量复制流程。
- 如果回复 +CONTINEU,从节点进行部分复制流程。
- 如果回复 -ERR,说明 Redis 主节点版本过低,不支持 psync 命令。从节点可以使用 sync 命令进行全量复制
同步过程分为:全量复制和部分复制。
- 全量复制:一般用于初次复制场景,Redis 早期支持的复制功能只有全量复制,它会把主节点全部数据一次性发送给从节点,当数据量较大时,会对主从节点和网络造成很大的开销。
- 部分复制:用于处理在主从复制中因网络闪断等原因造成的数据丢失场景,当从节点再次连上主节点后,如果条件允许,主节点会补发数据给从节点。因为补发的数据远小于全量数据,可以有效避免全量复制的过高开销。
主要就是看offset这里的进度~
如果offset写作-1,就是获取全量数据;
如果写作具体的整数,那么就是从当前偏移量位置获取数据;
全量复制:
当首次主节点进行数据同步的时候或者主节点不方便部分复制的时候;
全量复制流程:

1)从节点发送 psync 命令给主节点进行数据同步,由于是第一次进行复制,从节点没有主节点的运行 ID 和复制偏移量,所以发送 psync ? -1。
2)主节点根据命令,解析出要进行全量复制,回复 +FULLRESYNC 响应。
3)从节点接收主节点的运行信息进行保存。
4)主节点执行 bgsave 进行 RDB 文件的持久化。
5)主节点发送 RDB 文件给从节点,从节点保存 RDB 数据到本地硬盘。
6)主节点将从生成 RDB 到接收完成期间执行的写命令,写入缓冲区中,等从节点保存完 RDB ⽂件后,主节点再将缓冲区内的数据补发给从节点,补发的数据仍然按照 rdb 的⼆进制格式追加写入到收到的 rdb 文件中. 保持主从一致性。
7)从节点清空自身原有旧数据。
8)从节点加载 RDB 文件得到与主节点一致的数据。
9)如果从节点加载 RDB 完成之后,并且开启了 AOF 持久化功能,它会进行 bgrewrite 操作,得到最近的 AOF 文件。
部分复制:
从节点要从主节点这里进行全量复制,全量复制开销很大,有些时候,从节点本身就已经持有主节点大部分数据,所有不需要全量复制;或者出现网络波动的情况,主节点修改的数据无法同步过来,等到网络波动结束,主节点和从节点重新建立连接,那么就需要同步数据~
流程:

1)当主从节点之间出现网络中断时,如果超过 repl-timeout 时间,主节点会认为从节点故障并终端复制连接。
2)主从连接中断期间主节点依然响应命令,但这些复制命令都因网络中断无法及时发送给从节点,所以暂时将这些命令滞留在复制积压缓冲区中。
3)当主从节点网络恢复后,从节点再次连上主节点。
4)从节点将之前保存的 replicationId 和 复制偏移量作为 psync 的参数发送给主节点,请求进行部分复制。
5)主节点接到 psync 请求后,进行必要的验证。随后根据 offset 去复制积压缓冲区查找合适的数据,并响应 +CONTINUE 给从节点。
6)主节点将需要从节点同步的数据发送给从节点,最终完成一致性。
实时复制:
主从节点建立连接之后,主节点会把自己之后收到的修改操作,通过tcp长连接的方式,源源不断的传输给主节点,从节点会根据这些请求同时修改自身的数据,保存主从数据一致性~
这样的长连接,会通过心跳包的方式维护连接状态;
心跳包机制:
主节点:默认每隔10s给从节点发送ping命令,从节点收到返回pong
从节点:默认每隔1s给主节点发送一个特定的请求,就会上报此时从节点复制数据的进度(offset)
如果主节点发现从节点通信延迟超过 repl-timeout 配置的值(默认 60 秒),则判定从节点下线,断开复制客户端连接。从节点恢复连接后,心跳机制继续进行。
哨兵(Sentinel)
在主从模式中,一旦主节点挂了,那么就只剩下从节点了;虽然能够提供读操作,但是不能写入数据,从节点不能自动的升级为主节点,不能替原来主节点对应的角色;通过人工的方式太不靠谱了(人不能一天24个小时盯着机器看),所有此时Redis提供了“哨兵”机制就是为了解决这一问题,让程序保存“高可用”状态~
当主节点出现故障时,Redis Sentinel 能自动完成故障发现和故障转移,并通知应用方,从而实现真正的高可用。
哨兵架构:

每一个哨兵节点都是单独的进程,并且会提供奇数个
Redis哨兵的核心功能就是
这些哨兵会对现有的主从节点建立长连接,定期发送心跳包,借助上述的机制,就可以及时发现某个主机挂了;
如果从节点挂了,那么其实没有关系;
如果主节点挂了,那么哨兵就要发挥它们的作用;
此时一个哨兵发现挂了还不够,需要多个哨兵节点来共同认同这件事,为了防止误判的情况;如果发现主节点确实挂了,那么哨兵们就会在这些从节点中推荐一个新的主节点;挑选出新的主节点之后,哨兵节点就会控制这个新的主节点,执行让其他的从节点转移到新的主节点上面;最后哨兵会通知客户端程序,告知新的主节点是哪个,让后续客户端再进行写操作针对新的主节点进行操作~~~
通过上面的介绍,可以看出 Redis Sentinel 具有以下几个功能:
- 监控: Sentinel 节点会定期检测 Redis 数据节点、其余哨兵节点是否可达。
- 故障转移: 实现从节点晋升(promotion)为主节点并维护后续正确的主从关系。
- 通知: Sentinel 节点会将故障转移的结果通知给应用方。
部署哨兵(基于docker)
由于只有一个云服务器,但是需要6个节点,基于在虚拟机上实现;
docker可以认为是一个“轻量级”的虚拟机;起到了虚拟机这样隔离环境的效果,但是又不会吃很多硬件资源;
略......................
哨兵选举原理:
1.主观下线:
当主节点宕机时,此时主节点和三个哨兵节点的心跳包没有了;
站在哨兵节点的角度上,主节点发生了严重故障,因此三个哨兵节点会把主节点判断为主观下线(SDown);
2.客观下线:
多个哨兵节点认为主节点挂了,那就是挂了,当故障得票数 >= 配置的法定票数
这就是客观下线(ODown)
3.选举出哨兵的leader
此时接下来只需要从剩下的从节点中选一个当主节点出来,但这个工作不需要多个哨兵都参与,只需要选出一个代表(leader),由这个leader负责升级从节点到主节点这个过程;
哨兵之间的选举涉及到Raft算法:
Raft 的领导选举是通过“投票”机制来完成的,每个节点都会投票选举一个领导者。在选举过程中,候选人会向其他节点请求投票,如果得到大多数节点的支持,它就成为新的领导者。
简而言之, Raft 算法的核心就是 "先下手为强". 谁率先发出了拉票请求, 谁就有更大的概率成为 leader.
无论选到谁作为leader都不重要,只需要能选出来一个节点即可~
4) leader 挑选出合适的从节点成为新的主节点
挑选规则:
- 比较优先级. 优先级高(数值小的)的上位. 优先级是配置文件中的配置项( slave-priority 或者 replica-priority ).
- 比较 replication offset 谁复制的数据多, 高的上位.
- 比较 run id , 谁的 id 小 谁上位.
当某个 slave 节点被指定为 master 之后,
1. leader 指定该节点执行 slave no one , 成为 master
2. leader 指定剩余的 slave 节点, 都依附于这个新 master
集群
上述的哨兵模式,虽然提高了系统的可用性,但是真实存储数据的还是主节点和从节点,所有的数据都存储在主从节点上;如果数据量超过了主从节点的内存上,那么就可能出现严重问题了~
所以就可以加入多台机器,可以解决内存不够的情况,引入多组主从节点,从而构成一个更大的整体,称为集群~
例如此时1TB的数据被分块成三份,那么每一组机器只需要存储整个数据全集的 1/3 即可.

数据分片算法
数据可以分层多份,那么要怎么样分,才是最合适的呢?
1.哈希求余
借鉴了哈希表的基本思想,借助hash函数,把一个key映射到一个整数上,再针对数组的长度求余,就可以得到一个数组下标
设有 N 个分片, 使用 [0, N-1] 这样序号进行编号.
N 为 3 的时候, [100, 120] 这 21 个 hash 值的分布 (此处假定计算出的 hash 值是一个简单的整数, 方便肉眼观察)

优点: 简单高效, 数据分配均匀.
但是缺点更加明显,一旦需要扩容,原有的映射规则就会被破坏,此时需要重新计算,重新排列,所有需要大量的搬运

如上图可以看到, 整个扩容一共 21 个 key, 只有 3 个 key 没有经过搬运, 其他的 key 都是搬运过的.
2.一致性哈希算法
在哈希求余算法过程中,每个key属于哪个分片,是交替出现的(这就导致搬运成本大大提高),在一致性哈希算法中,可以将交替出现,改进成连续出现~
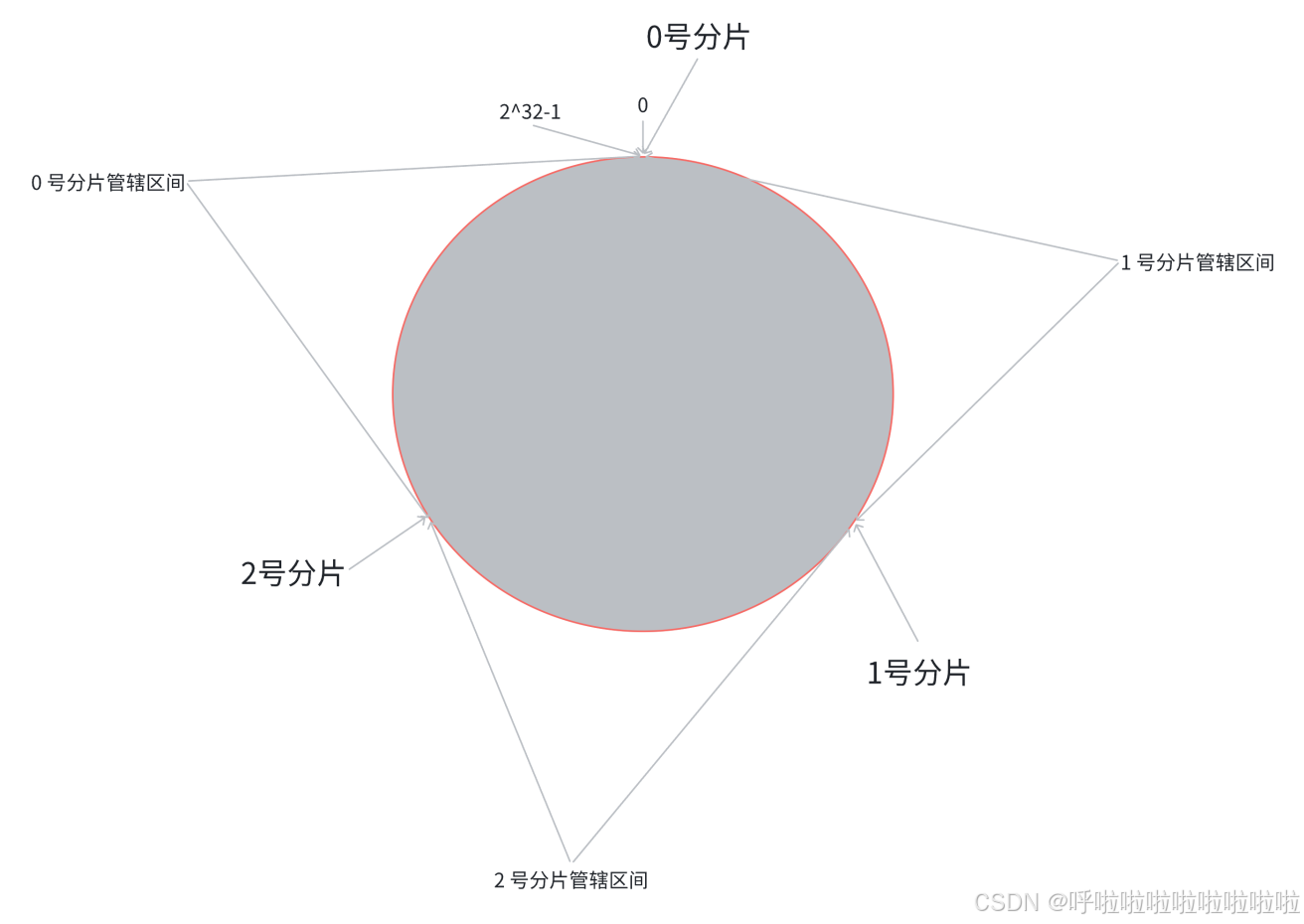
此时,如果新增一块分片,那么只需在环上重新安排一块区间

此时只需将0号分片的数据搬运到3号分片即可,那么1号和2号分片的区间是不变的~
但是由于1号和2号数据不变,那么它们所属的分片上的数据量就不均匀了,有的多有的少,数据倾斜;
3.哈希槽分区算法 (Redis 使用)
为了解决上述搬运成本高和数据分配不均匀的问题,Redis引入了哈希槽算法;
hash_slot = crc16(key) % 16384 crc16 也是一种 hash 算法.
相当于是把整个哈希值, 映射到 16384 个槽位上, 也就是 [0, 16383].
16384 其实是 16 * 1024, 也就是 2^14.然后再把这些槽位比较均匀的分配给每个分片. 每个分片的节点都需要记录自己持有哪些分片.
假设当前有三个分片, 一种可能的分配方式:
• 0 号分片: [0, 5461], 共 5462 个槽位
• 1 号分片: [5462, 10923], 共 5462 个槽位
• 2 号分片: [10924, 16383], 共 5460 个槽位
如果需要进行扩容, 比如新增一个 3 号分片, 就可以针对原有的槽位进行重新分配.
比如可以把之前每个分片持有的槽位, 各拿出一点, 分给新分篇.
⼀种可能的分配方式:
• 0 号分片: [0, 4095], 共 4096 个槽位
• 1 号分片: [5462, 9557], 共 4096 个槽位
• 2 号分篇: [10924, 15019], 共 4096 个槽位
• 3 号分片[4096, 5461] + [9558, 10923] + [15019, 16383], 共 4096 个槽位
搭建集群:
通常集群的搭建都是三个主节点,六个从节点这样的形式

搭建过程复杂略..........
主节点宕机处理流程:
-
自动故障检测
节点间通过 Gossip 协议 定期交换状态信息。若某主节点被多数节点标记为不可达(通过心跳超时判断),集群会触发故障转移。 -
故障转移流程
-
从节点发起竞选。
-
其他主节点投票选出新的主节点。
-
原主节点的槽重新分配给新主节点。
-
客户端自动重定向到新主节点。
-
小结:
主从模式主要是数据冗余和读写分离。主节点处理写,从节点复制数据并处理读,这样可以提高读的吞吐量。但主从模式的问题在于主节点单点故障,这时候就需要哨兵来监控和自动故障转移。哨兵确保当主节点宕机时,能自动选一个从节点升级为主,保证系统的高可用性。不过,主从加哨兵还是单主节点,写操作还是受限于主节点的性能,无法水平扩展。
接下来是集群,它通过分片解决数据量过大和写性能的问题。集群将数据分散到多个主节点,每个节点负责一部分数据,这样写操作可以分布到不同节点,提高了整体性能。同时,每个主节点有对应的从节点,保证高可用。用户可能需要处理大量数据或高并发写入,这时候集群就比主从加哨兵更合适。
对比总结
| 架构 | 核心目标 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 主从模式 | 数据冗余、读写分离 | 简单易用,成本低 | 手动故障恢复,单点写入瓶颈 | 小规模应用,数据备份 |
| 哨兵模式 | 高可用性(自动故障转移) | 自动化故障转移,服务发现 | 无法扩展写性能,不分片 | 中等规模,高可用需求 |
| 集群模式 | 数据分片 + 高可用 + 水平扩展 | 支持大规模数据和高并发,高可用 | 配置复杂,事务受限 | 大数据量、高并发、高可用需求 |
-
主从模式 → 主从 + 哨兵 → 集群模式
随着业务增长,逐步从单点冗余过渡到自动化高可用,最终通过分片解决性能和容量瓶颈。 -
集群模式 是终极方案,但复杂度高,需根据实际需求权衡是否必要。