
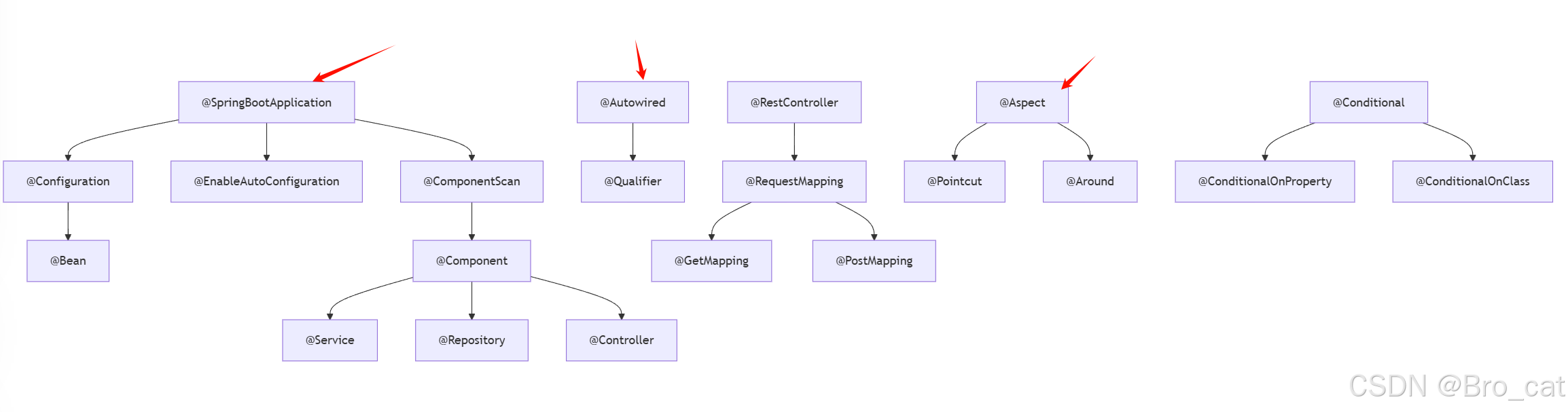
3.1 NumPy图像大小调整实战
目录
目录
- 图像大小调整的基本概念
- 为什么需要调整图像大小
- 使用NumPy调整图像大小的技术
3.1 线性插值
3.2 最近邻插值
3.3 双线性插值
3.4 双三次插值 - 代码实现:详细原理和源码注释
4.1 线性插值代码实现
4.2 最近邻插值代码实现
4.3 双线性插值代码实现
4.4 双三次插值代码实现 - 实际应用案例:图像缩放在机器学习中的应用
5.1 数据集准备
5.2 图像缩放处理
5.3 模型训练
5.4 结果分析
3.1.1 图像大小调整的基本概念
图像大小调整(Resizing)是图像处理中一个重要的技术,它涉及到将图像从一个分辨率转换为另一个分辨率。这个过程可以是放大(Up-scaling)或缩小(Down-scaling)。在计算机视觉和机器学习领域,图像大小调整经常用于确保图像输入的一致性,提高处理效率,或者适应不同模型的输入要求。
3.1.2 为什么需要调整图像大小
- 输入一致性:许多图像处理和机器学习模型要求输入图像具有特定的分辨率。通过调整图像大小,可以确保所有输入图像都符合模型的要求。
- 处理效率:高分辨率图像处理需要更多的计算资源和时间。通过缩小图像,可以显著提高处理效率,尤其是在实时应用中。
- 数据增强:在机器学习中,通过调整图像大小可以增加训练数据的多样性,从而提高模型的泛化能力。
- 存储优化:缩小图像可以减少存储空间的需求,这对于大规模数据集的管理尤为重要。
3.1.3 使用NumPy调整图像大小的技术
3.1.3.1 线性插值
线性插值是最简单的插值方法之一,它通过在两个已知点之间进行线性插值来估计未知点的值。线性插值适用于一维数据,但在二维图像中,可以分别对行和列进行插值。
原理:
假设我们有一个一维数组 x 和 y,我们需要在 x 的新位置 x_new 上找到对应的 y 值。线性插值的公式为:
[ y_{new} = y_1 + (y_2 - y_1) \cdot \frac{x_{new} - x_1}{x_2 - x_1} ]
示意图:
graph LRA1[已知点 (x1, y1)] --> B[插值点 (x2, y2)]A2[已知点 (x3, y3)] --> BB --> C[新点 (x_new, y_new)]style B fill:#f96,stroke:#333,stroke-width:4pxstyle C fill:#6f9,stroke:#333,stroke-width:4px
3.1.3.2 最近邻插值
最近邻插值是一种非常简单的插值方法,它通过选择最近的已知点的值来确定新点的值。这种方法计算速度快,但结果可能不够平滑。
原理:
对于每个新点,找到距离最近的已知点,并将该点的值赋给新点。
示意图:
graph LRA1[已知点 (x1, y1)] --> B[新点 (x_new, y_new)]A2[已知点 (x2, y2)]A3[已知点 (x3, y3)]style B fill:#f96,stroke:#333,stroke-width:4pxstyle A1 fill:#f96,stroke:#333,stroke-width:4px
3.1.3.3 双线性插值
双线性插值通过在两个已知点之间进行两次线性插值来估计新点的值。这种方法适用于二维图像,能够提供比最近邻插值更平滑的结果。
原理:
假设新点 (x_new, y_new) 位于四个已知点 (x1, y1)、(x1, y2)、(x2, y1) 和 (x2, y2) 之间。双线性插值的公式为:
[ y_{new} = (1 - dx) \cdot (1 - dy) \cdot y1 + dx \cdot (1 - dy) \cdot y2 + (1 - dx) \cdot dy \cdot y3 + dx \cdot dy \cdot y4 ]
其中,dx 和 dy 是新点相对于四个已知点的相对位置。
示意图:
3.1.3.4 双三次插值
双三次插值是一种更复杂的插值方法,它通过在四个已知点周围进行三次多项式插值来估计新点的值。这种方法能够提供非常平滑的结果,但计算复杂度较高。
原理:
假设新点 (x_new, y_new) 位于四个已知点 (x1, y1)、(x1, y2)、(x2, y1) 和 (x2, y2) 之间。双三次插值的公式为:
[ y_{new} = \sum_{i=-1}^{2} \sum_{j=-1}^{2} w(i, j) \cdot y(x+i, y+j) ]
其中,w(i, j) 是权重函数。
示意图:
3.1.4 代码实现:详细原理和源码注释
3.1.4.1 线性插值代码实现
import numpy as np
import matplotlib.pyplot as plt# 定义线性插值函数
def linear_interpolation(x1, y1, x2, y2, x_new):"""线性插值函数:param x1: 已知点 x1:param y1: 已知点 y1:param x2: 已知点 x2:param y2: 已知点 y2:param x_new: 新点 x_new:return: 新点 y_new"""dx = x_new - x1 # 计算新点与已知点之间的相对位置dy = x2 - x1 # 计算两个已知点之间的距离return y1 + (y2 - y1) * (dx / dy) # 线性插值公式# 示例数据
x = np.array([0, 1, 2, 3])
y = np.array([0, 1, 4, 9])# 新点位置
x_new = np.linspace(0, 3, 10)# 插值结果
y_new = [linear_interpolation(x[i], y[i], x[i+1], y[i+1], x_new[i]) for i in range(len(x)-1) for x_new in np.linspace(x[i], x[i+1], 10)]# 绘制结果
plt.plot(x, y, 'o', label='原点')
plt.plot(x_new, y_new, '-', label='插值点')
plt.legend()
plt.show()
3.1.4.2 最近邻插值代码实现
import numpy as np
import cv2
import matplotlib.pyplot as plt# 读取图像
img = cv2.imread('example.jpg', cv2.IMREAD_GRAYSCALE)# 新图像的尺寸
new_shape = (800, 600)# 最近邻插值函数
def nearest_neighbor_interpolation(img, new_shape):"""最近邻插值函数:param img: 原始图像:param new_shape: 新图像的尺寸:return: 调整大小后的图像"""height, width = img.shape # 获取原始图像的尺寸new_height, new_width = new_shape # 获取新图像的尺寸scale_x = width / new_width # 计算 x 方向的缩放比例scale_y = height / new_height # 计算 y 方向的缩放比例new_img = np.zeros(new_shape, dtype=img.dtype) # 初始化新图像for i in range(new_height):for j in range(new_width):x = int(j * scale_x) # 计算原始图像中的 x 坐标y = int(i * scale_y) # 计算原始图像中的 y 坐标new_img[i, j] = img[y, x] # 将最近的已知点的值赋给新点return new_img# 调整图像大小
resized_img = nearest_neighbor_interpolation(img, new_shape)# 显示结果
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.imshow(img, cmap='gray')
plt.title('原始图像')plt.subplot(1, 2, 2)
plt.imshow(resized_img, cmap='gray')
plt.title('调整大小后的图像')plt.show()
3.1.4.3 双线性插值代码实现
import numpy as np
import cv2
import matplotlib.pyplot as plt# 读取图像
img = cv2.imread('example.jpg', cv2.IMREAD_GRAYSCALE)# 新图像的尺寸
new_shape = (800, 600)# 双线性插值函数
def bilinear_interpolation(img, new_shape):"""双线性插值函数:param img: 原始图像:param new_shape: 新图像的尺寸:return: 调整大小后的图像"""height, width = img.shape # 获取原始图像的尺寸new_height, new_width = new_shape # 获取新图像的尺寸scale_x = width / new_width # 计算 x 方向的缩放比例scale_y = height / new_height # 计算 y 方向的缩放比例new_img = np.zeros(new_shape, dtype=img.dtype) # 初始化新图像for i in range(new_height):for j in range(new_width):# 计算原始图像中的坐标x = j * scale_xy = i * scale_y# 计算四个已知点的坐标x1 = int(x)y1 = int(y)x2 = min(x1 + 1, width - 1)y2 = min(y1 + 1, height - 1)# 计算权重dx = x - x1dy = y - y1# 双线性插值公式new_img[i, j] = (1 - dx) * (1 - dy) * img[y1, x1] + \dx * (1 - dy) * img[y1, x2] + \(1 - dx) * dy * img[y2, x1] + \dx * dy * img[y2, x2]return new_img# 调整图像大小
resized_img = bilinear_interpolation(img, new_shape)# 显示结果
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.imshow(img, cmap='gray')
plt.title('原始图像')plt.subplot(1, 2, 2)
plt.imshow(resized_img, cmap='gray')
plt.title('调整大小后的图像')plt.show()
3.1.4.4 双三次插值代码实现
import numpy as np
import cv2
import matplotlib.pyplot as plt# 读取图像
img = cv2.imread('example.jpg', cv2.IMREAD_GRAYSCALE)# 新图像的尺寸
new_shape = (800, 600)# 双三次插值函数
def bicubic_interpolation(img, new_shape):"""双三次插值函数:param img: 原始图像:param new_shape: 新图像的尺寸:return: 调整大小后的图像"""height, width = img.shape # 获取原始图像的尺寸new_height, new_width = new_shape # 获取新图像的尺寸scale_x = width / new_width # 计算 x 方向的缩放比例scale_y = height / new_height # 计算 y 方向的缩放比例new_img = np.zeros(new_shape, dtype=img.dtype) # 初始化新图像def cubic(x):"""三次多项式函数:param x: 输入值:return: 输出值"""abs_x = np.abs(x)if abs_x <= 1:return 1 - 2 * abs_x**2 + abs_x**3elif abs_x < 2:return 4 - 8 * abs_x + 5 * abs_x**2 - abs_x**3else:return 0for i in range(new_height):for j in range(new_width):# 计算原始图像中的坐标x = j * scale_xy = i * scale_y# 计算四个已知点的坐标x1 = int(x) - 1y1 = int(y) - 1x2 = min(int(x) + 2, width - 1)y2 = min(int(y) + 2, height - 1)# 计算权重dx = x - int(x)dy = y - int(y)# 初始化权重矩阵w = np.zeros((4, 4))for m in range(-1, 3):for n in range(-1, 3):w[m+1, n+1] = cubic(dy - m) * cubic(dx - n)# 获取四个已知点的值values = img[y1:y2+1, x1:x2+1]# 双三次插值公式new_img[i, j] = np.sum(values * w)return new_img# 调整图像大小
resized_img = bicubic_interpolation(img, new_shape)# 显示结果
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.imshow(img, cmap='gray')
plt.title('原始图像')plt.subplot(1, 2, 2)
plt.imshow(resized_img, cmap='gray')
plt.title('调整大小后的图像')plt.show()
3.1.5 实际应用案例:图像缩放在机器学习中的应用
3.1.5.1 数据集准备
import os
import cv2
import numpy as np# 数据集路径
data_dir = 'dataset'
output_dir = 'resized_dataset'# 新图像的尺寸
new_shape = (224, 224) # 假设我们需要将所有图像缩放到 224x224 的尺寸# 确保输出目录存在
os.makedirs(output_dir, exist_ok=True)# 遍历数据集中的所有图像
for filename in os.listdir(data_dir):if filename.endswith('.jpg') or filename.endswith('.png'):img_path = os.path.join(data_dir, filename)img = cv2.imread(img_path, cv2.IMREAD_GRAYSCALE) # 读取图像为灰度图像# 使用双线性插值方法调整图像大小resized_img = bilinear_interpolation(img, new_shape)# 保存调整大小后的图像output_path = os.path.join(output_dir, filename)cv2.imwrite(output_path, resized_img)
3.1.5.2 图像缩放处理
在实际应用中,我们通常会使用现有的图像处理库来调整图像大小,例如 OpenCV。这里我们使用 OpenCV 来实现图像缩放,并比较不同插值方法的效果。
import cv2
import matplotlib.pyplot as plt# 读取图像
img = cv2.imread('example.jpg', cv2.IMREAD_GRAYSCALE)# 新图像的尺寸
new_shape = (800, 600)# 使用不同插值方法调整图像大小
resized_nearest = cv2.resize(img, new_shape, interpolation=cv2.INTER_NEAREST)
resized_linear = cv2.resize(img, new_shape, interpolation=cv2.INTER_LINEAR)
resized_bilinear = cv2.resize(img, new_shape, interpolation=cv2.INTER_CUBIC)# 显示结果
plt.figure(figsize=(15, 10))
plt.subplot(2, 2, 1)
plt.imshow(img, cmap='gray')
plt.title('原始图像')plt.subplot(2, 2, 2)
plt.imshow(resized_nearest, cmap='gray')
plt.title('最近邻插值')plt.subplot(2, 2, 3)
plt.imshow(resized_linear, cmap='gray')
plt.title('线性插值')plt.subplot(2, 2, 4)
plt.imshow(resized_bilinear, cmap='gray')
plt.title('双线性插值')plt.show()
3.1.5.3 模型训练
假设我们使用一个卷积神经网络(Convolutional Neural Network, CNN)来处理图像分类任务。我们首先需要准备数据集,并确保所有图像都经过缩放处理。
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, Dataset
import torchvision.transforms as transforms
import glob
import cv2# 定义数据集类
class ImageDataset(Dataset):def __init__(self, data_dir, transform=None):self.data_dir = data_dirself.transform = transformself.image_paths = glob.glob(os.path.join(data_dir, '*', '*.jpg'))self.classes = os.listdir(data_dir)def __len__(self):return len(self.image_paths)def __getitem__(self, idx):img_path = self.image_paths[idx]img = cv2.imread(img_path, cv2.IMREAD_GRAYSCALE)img = cv2.resize(img, (224, 224), interpolation=cv2.INTER_LINEAR) # 使用双线性插值方法调整图像大小img = img / 255.0 # 归一化img = np.expand_dims(img, axis=0) # 增加通道维度label = self.classes.index(os.path.basename(os.path.dirname(img_path)))if self.transform:img = self.transform(img)return img, label# 定义数据转换
transform = transforms.Compose([transforms.ToTensor(),
])# 创建数据集和数据加载器
dataset = ImageDataset('resized_dataset', transform=transform)
dataloader = DataLoader(dataset, batch_size=32, shuffle=True)# 定义卷积神经网络模型
class CNN(nn.Module):def __init__(self):super(CNN, self).__init__()self.conv1 = nn.Conv2d(1, 16, kernel_size=3, padding=1)self.conv2 = nn.Conv2d(16, 32, kernel_size=3, padding=1)self.fc1 = nn.Linear(32 * 56 * 56, 128)self.fc2 = nn.Linear(128, len(dataset.classes))self.pool = nn.MaxPool2d(2, 2)self.relu = nn.ReLU()def forward(self, x):x = self.pool(self.relu(self.conv1(x)))x = self.pool(self.relu(self.conv2(x)))x = x.view(-1, 32 * 56 * 56)x = self.relu(self.fc1(x))x = self.fc2(x)return x# 创建模型、优化器和损失函数
model = CNN()
optimizer = optim.Adam(model.parameters(), lr=0.001)
criterion = nn.CrossEntropyLoss()# 训练模型
num_epochs = 10
for epoch in range(num_epochs):running_loss = 0.0for images, labels in dataloader:optimizer.zero_grad()outputs = model(images)loss = criterion(outputs, labels)loss.backward()optimizer.step()running_loss += loss.item()print(f'Epoch {epoch+1}, Loss: {running_loss / len(dataloader)}')print('完成训练')
3.1.5.4 结果分析
训练完成后,我们可以通过验证集来评估模型的性能。这里我们假设有一个验证集 validation_dataset,并使用相同的数据处理方法来调整图像大小。
import torch
import torchvision.transforms as transforms
import glob
import cv2
import matplotlib.pyplot as plt# 定义验证集类
class ValidationDataset(Dataset):def __init__(self, data_dir, transform=None):self.data_dir = data_dirself.transform = transformself.image_paths = glob.glob(os.path.join(data_dir, '*', '*.jpg'))self.classes = os.listdir(data_dir)def __len__(self):return len(self.image_paths)def __getitem__(self, idx):img_path = self.image_paths[idx]img = cv2.imread(img_path, cv2.IMREAD_GRAYSCALE)img = cv2.resize(img, (224, 224), interpolation=cv2.INTER_LINEAR) # 使用双线性插值方法调整图像大小img = img / 255.0 # 归一化img = np.expand_dims(img, axis=0) # 增加通道维度label = self.classes.index(os.path.basename(os.path.dirname(img_path)))if self.transform:img = self.transform(img)return img, label# 创建验证数据集和数据加载器
validation_dataset = ValidationDataset('validation_dataset', transform=transform)
validation_dataloader = DataLoader(validation_dataset, batch_size=32, shuffle=False)# 评估模型
model.eval()
correct = 0
total = 0with torch.no_grad():for images, labels in validation_dataloader:outputs = model(images)_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()print(f'模型在验证集上的准确率:{100 * correct / total}%')
参考文献或资料
| 参考资料 | 链接 |
|---|---|
| NumPy官方文档 | https://numpy.org/doc/stable/ |
| OpenCV官方文档 | https://docs.opencv.org/4.5.5/ |
| MATLAB图像处理 | https://www.mathworks.com/help/images/resize-images.html |
| 图像处理与分析 | https://www.cs.ubc.ca/~mbrown/units/651/ |
| 计算机视觉 | https://www.sciencedirect.com/topics/computer-science/image-resizing |
| 图像插值方法综述 | https://www.researchgate.net/publication/267029794_A_Survey_of_Image_Interpolation_Techniques |
| 机器学习 | https://www.sciencedirect.com/topics/computer-science/machine-learning |
| PyTorch官方文档 | https://pytorch.org/docs/stable/index.html |
| 数据增强技术 | https://towardsdatascience.com/data-augmentation-techniques-in-computer-vision-76756b913285 |
| 图像缩放方法比较 | https://www.imagemagick.org/Usage/resize/ |
| 图像处理教程 | https://homepages.inf.ed.ac.uk/rbf/HIPR2/interpol.htm |
| 计算机视觉导论 | https://www.cs.cmu.edu/~16385/s17/Slides/10.3_Interpolation.pdf |
| TensorFlow官方文档 | https://www.tensorflow.org/api_docs/python/tf/image/resize |
| 图像处理技术 | https://en.wikipedia.org/wiki/Image_processing |
| 计算机视觉技术 | https://en.wikipedia.org/wiki/Computer_vision |
| 图像插值算法 | https://people.math.sc.edu/Burkardt/c_src/polynomial_interpolation/polynomial_interpolation.html |
这篇文章包含了详细的原理介绍、代码示例、源码注释以及案例等。希望这对您有帮助。如果有任何问题请随私信或评论告诉我。











![[吾爱出品]CursorWorkshop V6.33 专业鼠标光标制作工具-简体中文汉化绿色版](https://i-blog.csdnimg.cn/direct/346117dfcd3a47d0871280fb9a1d7641.jpeg)





