近日,业界领先的国产企业级云数仓厂商酷克数据发布了下一代In-Database高级分析和数据科学工具箱HashML,在业内率先实现为企业提供随数仓部署一步到位、开箱即用的AI能力。
在数字经济时代,描述性分析已经非常成熟并被企业广泛采纳。然而,受限于人才缺口和技术门槛,更高价值的预测性分析和决策性分析,目前普及度仍然相对较低。为了应对日益激烈的市场竞争,企业IT部门迫切需要简单易用的高级分析工具产品来实现对业务可持续健康发展的有效支撑。

图1:数据分析的不同层级
数据仓库作为企业数据存储、加工和分析的核心场所,蕴藏着规模庞大的数据资产。然而,通用模型的效果往往只能达到差强人意的“及格线”。只有通过AI算法与应用场景及企业自有数据紧密协同,才能充分释放数据潜力,达到驱动业务健康发展的“优秀线”。以HashData为代表的现代企业数据仓库,为AI模型的训练、部署和推理提供了最佳的数据支撑平台。
为了降低高级分析和AI技术的应用门槛,酷克数据基于HashData打造了下一代In-Database高级分析和数据科学工具箱HashML。
HashML提供了从数据查询处理、高级分析到机器学习、深度学习的一站式多层次数据分析和AI能力。针对近期市场高度关注的大语言模型,HashML也提供了从高质量数据挖掘、模型微调到模型部署和推理的全流程支持。同时,基于HashData内置的分布式并行向量数据存储、索引及检索功能,HashML提供了向量知识库的构建和检索能力,使得知识增强的大语言模型应用开发变得更加简单。
HashML继承了HashData的云原生优势,从模型训练到模型部署都可以做到按需弹性伸缩。同时,HashML也提供了Python和SQL两种语言支持,无论是数据科学社区的Python用户,还是数据库社区的SQL用户,都可以低门槛地上手使用。

图2:HashML主要功能概览
HashML拥有以下三大产品特色:
简单易用:可随HashData数据仓库一起安装部署,做到开箱即用,同时所有模块API的设计,都力求标准化,与数据科学社区流行的第三方库保持一致,最大程度保障易用性。
性能卓越:根据任务的复杂度确定并行处理的并发度,尤其对于较为复杂的深度模型或大语言模型,可以利用多机多卡实现高效的训练和微调,保障作业时效性。
算法丰富:从传统的统计机器学习算法到常见的深度神经网络,和最新的预训练大模型,都能提供良好的支持,同时也针对知识增强的大语言模型应用,提供了向量知识库,能够高效支持海量语义向量数据的存储和检索。
简单易用
标准化接口,低代码开发
简单易用是我们设计HashML时的首要目标,力求帮助企业无门槛使用各种经典和最前沿的AI算法和模型能力,低成本解决实际业务问题。
为了实现这个目标,HashML对编程接口做了高度抽象和标准化。客户只需编写少量代码就可以完成从数据加载到数据处理、模型训练、模型部署和推理预测的全流程工作。例如,针对模型的训练和微调,HashML抽象了统一的fit接口。不论是机器学习模型、深度学习模型还是大语言模型,都可以调用该接口完成模型训练或微调。
rom hashml.models import XGBoost
xgb = XGBoost(dbname='testdb')
xgb.fit(train_tblname='calhouse_train', valid_tblname='calhouse_val', train_config={...})代码示例1:XGBoost模型训练
from hashml.llm import Lora4Llama2
lora = Lora4Llama2(base_model='Llama-2-7b-chat-hf')
lora.fit(train_tblname='nl2sql_train', valid_tblname='nl2sql_val', train_config={...})代码示例2:LLaMA2模型微调
为了方便SQL开发者使用AI能力,HashML还提供了SQL编程语言接口。下图显示了如何通过执行SQL语句完成XGBoost模型的训练。
SELECThashml.xgboost_train('calhouse_train','calhouse_val', '{''objective'':''reg:squarederror'', ''y'':''target'', ''num_workers'':4}');代码示例3:HashML SQL接口
性能卓越
- 多机多卡,弹性伸缩
基于HashData强大的集群资源管理能力,HashML可以根据算法复杂度、数据量大小、访问负载等因素按需分配所需计算资源,为模型训练、部署和推理提供灵活的计算环境。
- 分布式并行数据处理
HashML定义了数据模块,可以帮助开发者高效地完成数据读写、数据分析、数据处理等各种功能。这些功能对于开发机器学习、深度学习模型至关重要,可以高效快捷地完成数据清洗、特征提取、特征变换、样本生成等一系列任务。基于封装良好的编程接口,用户只需要关注数据处理逻辑的实现,仅需少量的代码开发,计算过程就可以由HashData计算引擎以分布式并行处理的方式高效完成。
- 分布式并行模型训练
HashML提供了分布式并行模型训练能力,可以按需将模型训练任务分配给多个Worker执行,同时可以为每个Worker指定所需计算资源(包括CPU核数和GPU卡数)。对于大多数常见的训练任务,数据并行就足以高效完成模型训练。对于参数规模庞大的大语言模型,我们在数据并行的基础上,利用DeepSpeed和Accelerate实现模型并行。另外,得益于HashData对计算资源的统一管理,用户无需费心训练作业具体是在哪些机器上执行,运维工作大幅简化。
- 弹性可伸缩服务部署
HashML提供了弹性可伸缩的模型部署和在线推理功能,旨在简化模型的部署并根据服务负载动态调整模型实例的数量。除了支持单个模型的弹性部署,HashML还支持多个模型的组合部署,这对于需要调用多个模型完成一个业务请求的场景非常有用。用户可以在服务端完成复杂业务逻辑的开发,客户端只需要与服务端进行一次交互就能获得最终的结果,不仅大幅简化了业务开发,同时提高了端到端服务的时效性。
算法丰富
机器学习深度学习全覆盖,前沿算法快速追踪
HashML的另一特色就是算法种类丰富,从经典的统计机器学习算法,到知名的深度学习算法,都提供了很好的支持。同时,通过密切追踪技术发展动态并根据市场需求,HashML也会及时引入前沿算法。例如,针对当前非常热门的大语言模型,HashML通过融合业界主流的开源大语言模型,提供了一套完整的大语言模型应用开发框架,可以低成本、快速地完成从高质量数据挖掘、模型微调到智能应用开发的全流程工作。
机器学习与深度学习
为了满足各种应用场景,HashML内置了对经典机器学习算法的支持,如Logistic Regression、Random Forest、SVM、XGBoost、LightGBM等,还通过支持主流的深度学习框架(如PyTorch),能够支持各种深度学习算法。另外,HashML也允许用户根据需要定制开发新算法。通过对算法开发框架精心封装,使得用户在充分理解算法原理的基础上,只需关注网络结构的定义和实现,用少量代码就能完成新算法的开发和引入。新算法开发完成后,可以自动具备HashML所提供的分布式并行训练和推理能力。
rom hashml.models.torch_base import TorchBaseModel
class _MLPNetwork(nn.Module):def __init__(self, input_size: int, hidden_config: List[int], output_size: int, use_bn: bool = False, use_dropout: bool = False) -> None:super(_MLPNetwork, self).__init__()self._nn = nn.Sequential(*layers)
def forward(self, x: torch.Tensor) -> torch.Tensor:return self._nn(x)
class MLP(TorchBaseModel):def __init__(self, input_size: int, hidden_config: List[int], output_size: int, use_bn: bool = False, use_dropout: bool = False, **kwargs) -> None:self.input_size = input_sizesuper(MLP, self).__init__(**kwargs)def _build_network(self) -> torch.nn.Module:return _MLPNetwork(self.input_size, ...)
if "__main__" == __name__:mlp = MLP(input_size=784, hidden_config=[128], output_size=10, dbname='testdb')mlp.fit(train_tblname='fashionmnist_train', modelname='mlp_0406_1', valid_tblname='fashionmnist_test')代码示例4:自定义神经网络
- 大语言模型
ChatGPT的问世使得大语言模型成为了当前最受关注的研究热点。大语言模型技术的产生与发展不仅重塑了人工智能发展的技术路线,还在很大程度上改变了AI技术在企业的应用范式。HashML顺应技术趋势,提供了对大语言模型的支持,包括模型微调以及知识增强的大语言模型应用开发。HashML对当前业界主流的开源大语言模型都提供了支持,包括ChatGLM、Baichuan、LLaMA-2、Qwen等。基于HashML,可以非常方便地实现百亿级参数大语言模型的私有化部署,并在客户私有环境实现模型微调和智能应用开发。

图3:日益繁荣的开源大语言模型生态
应用案例
HashML助力大语言模型在企业落地应用
- ReQA:检索增强的智能问答
大语言模型使用了大量的文本进行训练从而使人机对话更加智能,但对于特定领域的知识,大语言模型却显得捉襟见肘。基于HashML和大语言模型,可以快速搭建基于向量知识库的检索增强的智能问答系统(ReQA)。
在ReQA中,企业通过调用本地部署的Embedding服务将自有的知识库(包括管理制度、产品手册、技术手册、运维手册、工作规范、流程记录、FAQ等)进行向量化,并存放到HashData形成向量知识库。当回答用户提问时,通过检索向量知识库获得相关信息,作为上下文和问题一起提交给大语言模型,这样大语言模型就能够生成精准的回答,从而有效解决困扰大语言模型的生成“幻觉”问题。ReQA在企业有着非常广泛的应用场景,包括智能客服、销售助手、文档阅读助手等。

图4:检索增强的智能问答实现方案
示范应用1:检索增强的智能问答系统
- ChatData:基于自然语言的交互式数据查询分析
虽然SQL是一种普遍使用的数据库查询语言,但对许多企业员工来说却是一道难以逾越的门槛,这无疑限制了业务部门直接处理数据。
针对这个问题,我们基于HashML和大语言模型开发了ChatData,使得企业每个员工可以无门槛地使用自然语言与权限范围内的数据库进行交互。ChatData大大降低了数据分析和应用的门槛,有利于充分地释放企业数据价值。
在ChatData中,首先利用大量高质量的<查询指令,SQL语句>数据对大语言模型进行微调,使之能够准确地将自然语言表达的用户查询意图转换为正确合法的SQL语句,系统通过执行生成的SQL语句完成数据查询并返回结果。在此基础上用户还可以通过自然语言和系统进行交互,实现对查询结果的可视化。
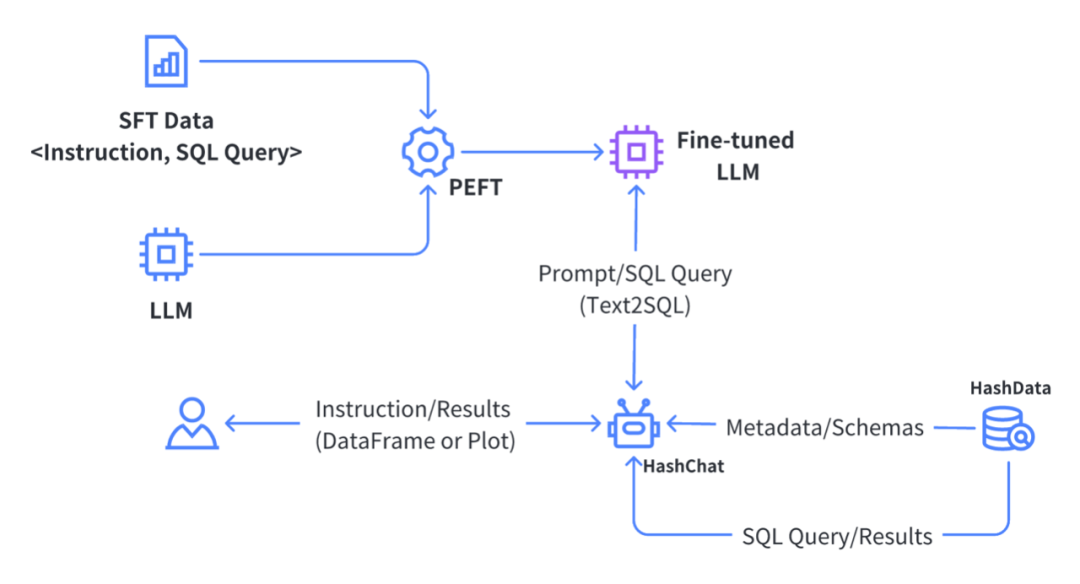
图5:基于自然语言的交互式数据查询分析实现方案
示范应用2:基于自然语言的交互式数据查询分析系统
Data+AI
助力企业数智化升级
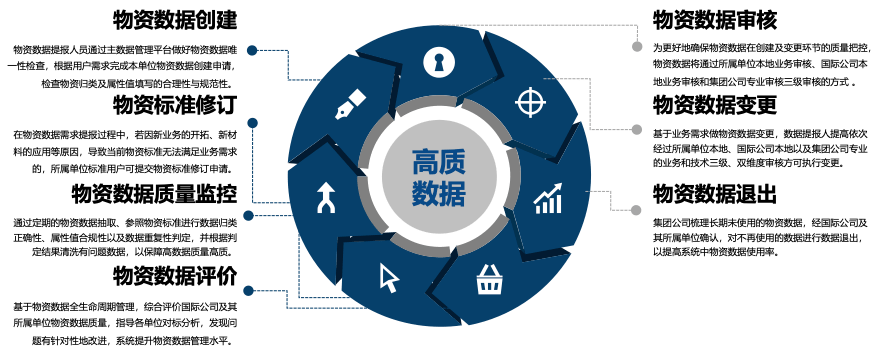
新一代人工智能技术正在加速企业数字化、智能化进程,长远来看,将对企业的研发、生产、经营带来深远影响。企业需要逐场景深入打磨,让AI计算贴近应用场景、贴近企业数据资产,才能实现更好的AI落地。酷克数据打造的下一代高级分析和数据科学工具箱HashML,致力于大幅降低AI技术的应用门槛,为数据科学家、数据工程师、AI应用开发者使用先进的AI技术提供便利。
我们希望以企业数据仓库为依托,结合前沿的AI技术,帮助用户以低成本快速试错,迭代发掘高价值应用场景,推动AI技术在企业规模化落地,产生真正的业务价值。未来,我们将持续迭代完善产品,将HashData打造成强大的企业级数据和AI基础设施,助力千行百业通过分析与智能实现业务价值!