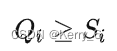文章目录
- 1. 概述
- 1.1. 消息队列
- 1.2. 应用场景
- 1.3. 工作模式
- 1.4. 基础结构
- 1.4.1. 结构组件
- 1.4.2. 数据同步
- 1.4.3. ACK机制
- 1.4.4. 分区机制
- 1.4.4.1. 使用Partition Key写入
- 1.4.4.2. 轮询写入 - 默认规则
- 1.4.4.3. 指定Partition写入
- 1.4.5. Offset偏移量
- 1.4.5.1. 消息顺序性
- 1.4.5.2. Coordinator协调者
- 1.4.5. ConsumerGroup消费者组
- 1.4.6. Rebalance机制
- 1.4.7. 数据一致性
- 1.4.7.1. Replicas副本机制
- 1.4.7.2. Leader选举
- 1.4.7.3. 可靠性保证
- 1.5 ZK目录结构
- 1.5.1. /brokers
- 1.5.1.1. /brokers/ids
- 1.5.1.2. /brokers/topics
- 1.5.2. /consumers
- 1.5.2.1. /consumers/{groupId}/ids
- 1.5.2.2. /consumers/{groupId}/owner
- 1.5.2.3. /consumers/{groupId}/offset
- 1.5.3. /admin
- 1.5.3.1. /admin/reassign_partitions
- 1.5.3.2. /admin/preferred_replica_election
- 1.5.3.3. /admin/delete_topics
- 1.5.4. /controller
- 1.5.5. /controller_epoch
- 2、服务安装
- 2.1. 单机部署
- 2.2. 伪集群部署
- 2.3. 集群操控脚本
- 2.5. 客户端命令行操作
- 2.5.1. Topic
- 2.5.2. Producer
- 2.5.3. Consumer
- 2.5.4. Consumer group
- 2.5.5. 操作案例
- 2.5.5.1. Topic
- 2.5.5.2. Producer + Consumer
- 2.5.5.3. Consumer group
- 2.5.4. 分区与副本调整
- 2.5.4.1. 分区扩容
- 2.5.4.2. 副本扩容
- 2.5.5. 消息积压清理
- 2.5.6. 重选选举Leader主分区
- 2.6. 报错记录
- 2.6.1. 创建topic时报错
- 2.6.2. 使用工具时直接返回参数列表
- 2.6.3. 未知的选项
- 2.6.4. 重置offset时异常
- 2.6.5. json格式文件工具
- 2.6.6. Leader重新选举报错
- 3、Python连接Kafka
- 3.1. 生产者
- 3.2. 消费者
- 3.3. 执行结果
1. 概述
Kafka是Apache基金会开发的一个开源流处理平台,由Scala和Java编写,Kafka是一个开源的分布式事件流平台,主要应用于大数据实时处理领域。
1.1. 消息队列
目前企业中常见的消息队列产品主要有RabbitMQ、ActivceMQ、RocketMQ、Kafka等。在大数据场景下主要采用Kafka作为消息队列,在JavaEE开发中主要采用RabbitMQ、ActivceMQ、RocketMQ作为消息队列进行使用。
1.2. 应用场景
传统消息队列的主要应用场景有:缓存/消峰、解耦合、异步通信。
-
缓存/消峰:有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致情况。
-
解耦合:允许独立的扩展或修改两边处理过程,只考虑遵守Kafka接口约束规则即可。
-
异步通信:允许用户将消息放入队列,并不需要立即处理消息,等待需要时进行处理即可。
1.3. 工作模式
-
点对点模式:消费者主动拉取数据,消息收到后清除队列中消息;
-
发布/订阅模式:存在多个topic主题,消费者消费数据后不做删除操作,每个消费者相互独立,都可以消费到所需消息。
1.4. 基础结构

1.4.1. 结构组件
- Broker:Kafka服务实例或服务节点,多个Broker构成了Kafka Cluster;
- Producer:生产者,写入消息的角色,将消息写入Broker的Topic Partition Leader副本内;
- Consumer:消费者,读取消息的角色,从Broker的Topic Partition Leader读取生产者写入的消息;
- Consumer Group:消费者组,一个或多个消费者构成一个消费组,不同的消费组可以订阅同一个主题的消息且互不影响;
- ZooKeeper:Kafka Cluster使用ZK来管理集群的Broker、Topic、Partition等元数据,以及控制器的选举;
- Topic:消息主题(逻辑概念),每一个消息都属于某个主题,Kafka通过主题来区分不同的消息;
- Partition:分区,一个Topic可以划分多个分区,一个分区只属于一个主题;
- Replica:副本,一个分区可以拥有多个副本来提高数据可靠性;
- Leader & Follower:分区角色,当某个Topic划分为多个分区时,单个分区拥有多个副本,这些副本需要进行消息同步保证数据一致性,主副本提供读写能力,从副本不提供读写,仅仅作为主副本的备份及时同步数据即可;
- Offset:偏移量(类比TCP协议分段),分区中的每一条消息都有一个所在分区的偏移量,这个偏移量唯一标识了该消息在当前这个分区的位置,并保证在这个分区的顺序性,不可保证跨分区的顺序性。
1.4.2. 数据同步
以一次数据生产者发送消息的流程进行介绍数据复制过程。

流程如下:
- 生产者Producer向Kafka cluster集群中Broker的Topic Partition Leader发送消息请求,写入消息;
- Topic Partition Leader收到后,存储完成,并将消息同步到其他Topic Partition Follower;
- Follower同步并存储完成后返回ACK至Leader处,当Leader收集到所有Follower的存储确认后,向Producer返回消息写入完成ACK;
- 消费者Consumer此时就可以向Topic Partition Leader发送消费请求,消费存储好的数据。
1.4.3. ACK机制
在前述流程中Kafka Cluster的ACK响应机制分为三种:
-
ack=0:生产者Producer向Partition Leader发送消息请求后立即返回ACK,此时消息有可能还未落盘;写入消息吞吐量最高,但数据可靠性最低;
-
ack=1:生产者Producer向Partition Leader发送消息请求后等待Leader写入成功后返回ACK,此时只有Leader分区存储完成,Follower未存储消息;写入消息吞吐量偏高,但消息还未同步给Follower,若Leader异常则会发生数据丢失问题,因此数据可靠性偏低;
-
ack=-1:生产者Producer向Partition Leader发送消息请求后,等待Leader和ISR中的Follower都存储完成后返回ACK;写入消息吞吐量较前两种类型更低,但数据可靠性最高,极端情况也会存在数据丢失的风险(当ISR中的Follower均异常时,此时ack=-1系效果等于ack=1,因此数据可靠性最高的场景为:ack=-1 + ISR follower num >= 2)。
1.4.4. 分区机制
Kafka中Topic被分成多个Partition分区,Topic是一个逻辑概念,而Partition是最小存储单元,每个Partition都是一个单独的log文件,每条消息都会以追加的形式写入到此log文件内,因此Producer或Consumer都可以进行并发请求,显著提升I/O性能。

1.4.4.1. 使用Partition Key写入
Producer发送消息时,可以指定Partition Key(任意值,如UserID),将Key传递到HASH函数,再与该Topic的Partition总数进行取余可得到分区号,此消息因此写入所得编号的Partition内。
- 优点:使用此方法得到的分区编号可以使得相同UserID的消息存储在同一个分区内;
- 缺点:如果该UserID产生的消息特别多,那么此分区会异常繁忙,发生数据倾斜问题。
1.4.4.2. 轮询写入 - 默认规则
如果没有使用Partition Key,Kafka默认使用轮询的方式来决定写入哪个Partition,因此消息会均衡的写入各个Partition。
1.4.4.3. 指定Partition写入
Kafka 支持自定义规则,一个Producer可以使用自己的分区指定规则。
1.4.5. Offset偏移量
Topic Partition中的每条记录都会被分配一个唯一的序号,称为Offset(偏移量)。Offset是一个递增的、不可变的数字,由Kafka自动维护。当一条记录写入Partition的时候,它就被追加到log文件的末尾,并被分配一个序号,作为Offset。在消息消费的时候对于一个消费组来说,在一个分区上也会设置一个Offset(消费组的Offset)。

1.4.5.1. 消息顺序性
一个Topic如果有多个Partition的话,那么从Topic来看消息是无序的,而从Partition来看内部消息有序,跨Partition无序,因此若需要Topic得消息有序,则需要配置该Topic为单个Partition即可。
1.4.5.2. Coordinator协调者
Offset偏移量如何进行存储?一个集群上可能有成百上千个消费组,如何进行分配?
实际上Kafka创建一个内部Topic用来存储Offset偏移量信息,名称为**__consumer_offsets**,这时某个消费组如何找到自己被那个Broker代理?
服务端会通过消费组的HASH对__consumer_offsets的分区数(offsets.topic.num.partitions默认是50,offsets.topic.replication.factor默认为1)进行取模操作,其取值即为Partition编号,这样就拿到了这个消费组的Offset是存在于那个Partition上,然后获取__consumer_offsets topic的该编号Partition的元数据信息,其中Leader就是这个消费组的代理节点即Coordinator(协调者)。
[root@master kafka_cluster]# sh kafka-1/bin/kafka-topics.sh --bootstrap-server 127.0.0.1:9092 --describe --topic __consumer_offsets
Topic: __consumer_offsets TopicId: B2x90fF5TDOzlyvKQcqGNA PartitionCount: 50 ReplicationFactor: 1 Configs: compression.type=producer,cleanup.policy=compact,segment.bytes=104857600Topic: __consumer_offsets Partition: 0 Leader: 2 Replicas: 2 Isr: 2~ # 以下内容省略
在一个消费节点启动之后会先从服务端获取该消费组的Coordinator,即发起Findcoordinator请求,然后获取本消费节点处理的分区当前消费的Offset位置,即发起OffsetFetch请求。才可以知道从各个分区应该从哪个位置开始拉取消息数据。
1.4.5. ConsumerGroup消费者组
- ConsumerGroup下可以有一个或多个Consumer,Consumer可以是一个进程,也可以是一个线程;
- Group.id是一个字符串,唯一标识一个ConsumerGroup;
- ConsumerGroup下订阅的Topic下的每个分区只能分配给某个Group下的一个Consumer(当然该分区还可以被分配给其他Group)。
1.4.6. Rebalance机制
Kafka集群模式下,一个Topic有多个Partition,对于消费方来说可以有多个Consumer同时消费这些Partition,为保证Partition和Consumer的均衡性,提升Topic的并发能力,Rebalance规定了一个ConsumerGroup下的所有Consumer如何分配订阅Topic的每个Partition。
Rebalance机制场景:
- ConsumerGroup组内成员数量发生变化;
- Consumer消费超时;
- Group订阅Topic数量发生变化;
- Group订阅Topic下Partition数量发生变化。
1.4.7. 数据一致性
从Producer向Broker发送消息、Topic Partition与Replicas及其Leader选举几个角度介绍数据传输可靠性。
- AR:Assigned Replicas,所有的副本;
- ISR:In-Sync Replicas,所有和主副本保持同步的副本集合(Follower在replica.lag.time.max.ms时间范围内同步到Leader的LEO位置即可);
- OSR:Out-of-Sync Replicas,所有和主副本未保持一致的副本集合;
AR = ISR + OSR
- LEO:Log End Offset,下一个消息将要写入的Offset偏移位置,在LEO之前的消息都已完成写入日志,每个副本都有一个自己的LEO位置;
- HW:High Watermark,所有与主副本保持同步的副本中,最小的LEO就是HW,意味着在这之前的消息都已经被所有的ISR副本写入到日志中,即使主副本异常后其中一个ISR副本成为主副本时消息也不会发生丢失问题。
1.4.7.1. Replicas副本机制
Kafka从0.8.0版本引入副本机制,每个Partition可以自定义设置副本数量(默认配置数量为3),多个副本中有一个为Leader,其余为Follower,Follower定期向Leader请求数据同步,当Leader异常时可以重新选举出新的Leader,提高Kafka的数据冗余。
Replicas副本机制为Partition分区的机制,并非Topic主题!
1.4.7.2. Leader选举
每个Partition的Leader都会维护一个ISR列表(Follower副本的Broker编号),只有与Leader同步完成的副本Follower才能加入到ISR列表中,由参数replica.lag.time.max.ms控制(默认10s),只有在ISR列表内的Follower才可以成为Leader(默认配置unclean.leader.election.enable=false,不能从非ISR的副本列表里选择Leader)。因此当Leader异常后,会从ISR列表中选择第一个Follower作为新Leader,以此保证Kafka的消息数据可靠性。
1.4.7.3. 可靠性保证
- ACK机制:acks=all(或request.required.acks=-1),同时producer.type=sync
- 副本数量:设置replication.factor>=3,并且 min.insync.replicas>=2;
- 分区副本选举:关闭不完全的Leader 选举(unclean.leader.election.enable=false)且保持offsets.topic.replication.factor > 1;
1.5 ZK目录结构

[root@master ~]# vim /kafka_cluster/kafka-1/config/server.properties
# 测试场景中配置ZK连接位置如下,则ZK中存储的Kafka元数据均位于/kafka路径下
zookeeper.connect=localhost:2181/kafka
1.5.1. /brokers
当一个Broker启动时,会向ZK注册自己持有的Topic和Partitions信息。
> ls /kafka/brokers
[ids, seqid, topics]
1.5.1.1. /brokers/ids
每个Broker的配置文件中都需要指定一个数字类型的id(全局不可重复),此节点为临时 Znode(EPHEMERAL)。
> ls /kafka/brokers/ids
[0, 1, 2]
> get -s /kafka/brokers/ids/0
{"listener_security_protocol_map": {"PLAINTEXT": "PLAINTEXT" # 明文显示},"endpoints": ["PLAINTEXT://master:9092"],"jmx_port": -1, # jmx端口号"features": {},"host": "master", # 主机名或ip地址"timestamp": "1691651715646", # broker初始启动时的时间戳"port": 9092, # broker的服务端端口号,由server.properties中参数port确定"version": 5 # 版本编号默认为1,递增
}
cZxid = 0x300000071
ctime = Thu Aug 10 15:15:15 CST 2023
mZxid = 0x300000071
mtime = Thu Aug 10 15:15:15 CST 2023
pZxid = 0x300000071
cversion = 0
dataVersion = 1
aclVersion = 0
ephemeralOwner = 0x100233882bf0008 # 临时节点标识
dataLength = 196
numChildren = 0
1.5.1.2. /brokers/topics
包含各Topic的Partition状态信息,此节点为临时Znode(EPHEMERAL)。
> ls /kafka/brokers/topics
[__consumer_offsets, hello_test]
> ls /kafka/brokers/topics/hello_test
[partitions]
> get -s /kafka/brokers/topics/hello_test
{"removing_replicas": {},"partitions":{"1":[0,2],"0":[1,0]}, # 同步副本组BrokerId列表(ISR)"topic_id": "hQ7vPPgRQF2XEwhRSxO7nA","adding_replicas": {},"version": 3
}
cZxid = 0x200000077
ctime = Tue Aug 08 17:45:47 CST 2023
mZxid = 0x200000077
mtime = Tue Aug 08 17:45:47 CST 2023
pZxid = 0x200000078
cversion = 1
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 128
numChildren = 1> ls /kafka/brokers/topics/hello_test/partitions
[0, 1]
> ls /kafka/brokers/topics/hello_test/partitions/0
[state]
> get -s /kafka/brokers/topics/hello_test/partitions/0/state
{"controller_epoch": 3, # Kafka集群中的中央控制器选举次数"leader": 1, # 该Partition选举Leader的BrokerId"version": 1, # 版本编号默认为1"leader_epoch": 3, # 该Partition Leader选举次数"isr": [0,1] # ISR列表
}
cZxid = 0x20000007c
ctime = Tue Aug 08 17:45:47 CST 2023
mZxid = 0x30000007b
mtime = Thu Aug 10 15:15:21 CST 2023
pZxid = 0x20000007c
cversion = 0
dataVersion = 4
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 74
numChildren = 0
1.5.2. /consumers
每个Consumer都有唯一的id,用来标记消费者信息,该目录下仅展示使用ZK进行消费的 Consumers,如果之间指定Kafka节点进行消费,不会在此展示。
> ls /consumers
[console-consumer-84155, console-consumer-32194, wolves_report, console-consumer-9761, wolves_v2_gdt, console-consumer-63530, wolves, wolves_feedback, wolves_kuaishou, console-consumer-62629, ftrl1, console-consumer-56068, wolves_tuia]
> ls /consumers/wolves_report
[ids, owners, offsets]
注意事项:
使用kafka-console-consumer.sh命令创建的消费者并不会在Zookeeper的/consumers路径下创建消费者组信息,因为该命令使用的是新的消费者API,它使用了Kafka集群的元数据来管理消费者组信息,而不是使用Zookeeper。
新的消费者API不再需要将消费者组信息写入到Zookeeper中,因为Kafka集群本身就足够强大,可以自己管理消费者组信息。因此,使用kafka-console-consumer.sh创建的消费者不会在Zookeeper的/consumers路径下创建消费者组信息,而是在Kafka集群的元数据中进行管理。
Kafka的最新版本已经逐步淘汰了使用Zookeeper作为消费者元数据存储的方式,而是采用内部存储来管理消费者组信息。因此,新版本的Kafka已经不再支持使用--zookeeper参数来指定Zookeeper的连接信息。
如果你想要创建一个在Zookeeper的/consumers路径下的消费者,你需要使用旧的消费者API,而不是使用kafka-console-consumer.sh命令所使用的新的消费者API。
因此以下配置均来自旧版本Kafka。
1.5.2.1. /consumers/{groupId}/ids
> ls /consumers/wolves_report/ids
[wolves_report_node1.tc.wolves.dmp.com-1536837975646-39504764, wolves_report_node1.tc.wolves.dmp.com-1536838003051-182cc752,...]> get /consumers/wolves_report/ids/wolves_report_node1.tc.wolves.dmp.com-1536837975646-39504764 # 旧版本下ZK命令get效果等于新版本ZK命令get -s
{"version":1, # 版本编号默认为1"subscription": # 订阅的Topic列表{"wolves-event":3 # Consumer中Topic消费者线程数},"pattern":"static", # 模式"timestamp":"1537128878487" # Consumer启动时的时间戳
}
cZxid = 0x717782b21
ctime = Mon Sep 17 04:14:38 CST 2022
mZxid = 0x717782b21
mtime = Mon Sep 17 04:14:38 CST 2022
pZxid = 0x717782b21
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x36324802b64ea62
dataLength = 94
numChildren = 0
1.5.2.2. /consumers/{groupId}/owner
> ls /consumers/wolves_report/owners
[wolves-event] # topic> ls /consumers/wolves_report/owners/wolves-event
[0, 1, 2] # partitionId> get /consumers/wolves_report/owners/wolves-event/0
wolves_report_node1.tc.wolves.dmp.com-1536837527210-1310d8f9-0
cZxid = 0x717782ba9
ctime = Mon Sep 17 04:14:40 CST 2022
mZxid = 0x717782ba9
mtime = Mon Sep 17 04:14:40 CST 2022
pZxid = 0x717782ba9
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x26324802b69ea62
dataLength = 62
numChildren = 0
1.5.2.3. /consumers/{groupId}/offset
> ls /consumers/wolves_report/offsets
[wolves-event] # topic> ls /consumers/wolves_report/offsets/wolves-event
[0, 1, 2] # partitionId> get /consumers/wolves_report/offsets/wolves-event/0
48800
cZxid = 0x200e97e36
ctime = Thu Nov 23 17:22:10 CST 2022
mZxid = 0x718665858
mtime = Fri Sep 21 12:02:39 CST 2022
pZxid = 0x200e97e36
cversion = 0
dataVersion = 11910567
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 5
numChildren = 0
1.5.3. /admin
1.5.3.1. /admin/reassign_partitions
用以Partitions重分区,Reassign结束后会删除该目录。
> ls /admin/reassign_partitions
[]
1.5.3.2. /admin/preferred_replica_election
用以Partitions各副本Leader选举,副本选举结束后会删除该目录。
> ls /admin/reassign_partitions
[]
1.5.3.3. /admin/delete_topics
管理已删除的Topics,Broker启动时检查并确保存在。
> ls /admin/delete_topics
[]
1.5.4. /controller
存储Center controller中央控制器所在Kafka broker的信息。
> get -s /kafka/controller
{"version": 2, # 版本编号默认为1"brokerid": 1, # BrokerID"timestamp": "1691722592052", # Broker中央控制器变更时的时间戳"kraftControllerEpoch": -1
}
cZxid = 0x4000000de
ctime = Fri Aug 11 10:56:32 CST 2023
mZxid = 0x4000000de
mtime = Fri Aug 11 10:56:32 CST 2023
pZxid = 0x4000000de
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x10000042fff0009
dataLength = 80
numChildren = 0
1.5.5. /controller_epoch
Kafka集群中第一个Broker第一次启动时该值为1,后续只要集群中Center Controller中央控制器所在Broker变更或挂掉,就会重新选举新的Center Controller,每次Center Controller变更controller_epoch值就会自增1。
> get -s /kafka/controller_epoch
6
cZxid = 0x10000003f
ctime = Tue Aug 08 16:24:00 CST 2023
mZxid = 0x4000000de
mtime = Fri Aug 11 10:56:32 CST 2023
pZxid = 0x10000003f
cversion = 0
dataVersion = 6
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 1
numChildren = 0
2、服务安装
官网下载安装包:https://kafka.apache.org/,根据需求下载对应版本即可,本文以最新版本为例做部署操作说明。
2.1. 单机部署
# 解压安装包并创建软链接
[root@master ~]# tar -xvf kafka_2.12-3.3.1.tgz -C /middleware/
[root@master ~]# cd /middleware/
[root@master middleware]# ln -s kafka_2.12-3.3.1/ kafka
[root@master middleware]# cd kafka
[root@master kafka]# ll
total 64
drwxr-xr-x 3 root root 4096 Sep 30 03:05 bin # 可执行文件
drwxr-xr-x 3 root root 4096 Sep 30 03:05 config # 配置文件
drwxr-xr-x 2 root root 4096 Nov 11 16:49 libs
-rw-rw-r-- 1 root root 14842 Sep 30 03:03 LICENSE
drwxr-xr-x 2 root root 4096 Sep 30 03:05 licenses
-rw-rw-r-- 1 root root 28184 Sep 30 03:03 NOTICE
drwxr-xr-x 2 root root 4096 Sep 30 03:05 site-docs
[root@master kafka]# cd config/
[root@master config]# ll
total 72
-rw-r--r-- 1 root root 906 Mar 3 2020 connect-console-sink.properties
-rw-r--r-- 1 root root 909 Mar 3 2020 connect-console-source.properties
-rw-r--r-- 1 root root 5321 Mar 3 2020 connect-distributed.properties
-rw-r--r-- 1 root root 883 Mar 3 2020 connect-file-sink.properties
-rw-r--r-- 1 root root 881 Mar 3 2020 connect-file-source.properties
-rw-r--r-- 1 root root 2247 Mar 3 2020 connect-log4j.properties
-rw-r--r-- 1 root root 1539 Mar 3 2020 connect-mirror-maker.properties
-rw-r--r-- 1 root root 2262 Mar 3 2020 connect-standalone.properties
-rw-r--r-- 1 root root 1221 Mar 3 2020 consumer.properties
-rw-r--r-- 1 root root 4675 Mar 3 2020 log4j.properties
-rw-r--r-- 1 root root 1925 Mar 3 2020 producer.properties
-rw-r--r-- 1 root root 6848 Mar 3 2020 server.properties # 服务属性
-rw-r--r-- 1 root root 1032 Mar 3 2020 tools-log4j.properties
-rw-r--r-- 1 root root 1169 Mar 3 2020 trogdor.conf
-rw-r--r-- 1 root root 1205 Mar 3 2020 zookeeper.properties# 修改服务配置
[root@master kafka]# cd config/
[root@master kafka]# vim server.properties24 broker.id=0 # 指定broker id,集群内保持有且唯一34 listeners=PLAINTEXT://node1:9092 # 服务监听端口,默认909262 log.dirs=/middleware/kafka/data # 日志存放路径67 num.partitions=1 # 分区数量,默认为1125 zookeeper.connect=master:2181,node1:2181,node2:2181/kafka # ZK集群配置# ZK携带路径原因:携带路径之后kafka信息将保存在ZK中/kafka路径下,后续使用--zokeeper连接时就需要携带此路径,否则无法寻找相关数据[root@master kafka]# cd ../bin/
[root@master bin]# ll
total 140
-rwxr-xr-x 1 root root 1421 Mar 3 2020 connect-distributed.sh
-rwxr-xr-x 1 root root 1394 Mar 3 2020 connect-mirror-maker.sh
-rwxr-xr-x 1 root root 1418 Mar 3 2020 connect-standalone.sh
-rwxr-xr-x 1 root root 861 Mar 3 2020 kafka-acls.sh
-rwxr-xr-x 1 root root 873 Mar 3 2020 kafka-broker-api-versions.sh
-rwxr-xr-x 1 root root 864 Mar 3 2020 kafka-configs.sh
-rwxr-xr-x 1 root root 945 Mar 3 2020 kafka-console-consumer.sh # consumer操作
-rwxr-xr-x 1 root root 944 Mar 3 2020 kafka-console-producer.sh # producer操作
-rwxr-xr-x 1 root root 871 Mar 3 2020 kafka-consumer-groups.sh # consumer groups操作
-rwxr-xr-x 1 root root 948 Mar 3 2020 kafka-consumer-perf-test.sh
-rwxr-xr-x 1 root root 871 Mar 3 2020 kafka-delegation-tokens.sh
-rwxr-xr-x 1 root root 869 Mar 3 2020 kafka-delete-records.sh
-rwxr-xr-x 1 root root 866 Mar 3 2020 kafka-dump-log.sh
-rwxr-xr-x 1 root root 870 Mar 3 2020 kafka-leader-election.sh
-rwxr-xr-x 1 root root 863 Mar 3 2020 kafka-log-dirs.sh
-rwxr-xr-x 1 root root 862 Mar 3 2020 kafka-mirror-maker.sh
-rwxr-xr-x 1 root root 886 Mar 3 2020 kafka-preferred-replica-election.sh
-rwxr-xr-x 1 root root 959 Mar 3 2020 kafka-producer-perf-test.sh
-rwxr-xr-x 1 root root 874 Mar 3 2020 kafka-reassign-partitions.sh
-rwxr-xr-x 1 root root 874 Mar 3 2020 kafka-replica-verification.sh
-rwxr-xr-x 1 root root 9633 Mar 3 2020 kafka-run-class.sh
-rwxr-xr-x 1 root root 1376 Mar 3 2020 kafka-server-start.sh # 开启服务
-rwxr-xr-x 1 root root 997 Mar 3 2020 kafka-server-stop.sh # 关闭服务
-rwxr-xr-x 1 root root 945 Mar 3 2020 kafka-streams-application-reset.sh
-rwxr-xr-x 1 root root 863 Mar 3 2020 kafka-topics.sh # topic操作
-rwxr-xr-x 1 root root 958 Mar 3 2020 kafka-verifiable-consumer.sh
-rwxr-xr-x 1 root root 958 Mar 3 2020 kafka-verifiable-producer.sh
-rwxr-xr-x 1 root root 1722 Mar 3 2020 trogdor.sh
drwxr-xr-x 2 root root 4096 Mar 3 2020 windows
-rwxr-xr-x 1 root root 867 Mar 3 2020 zookeeper-security-migration.sh
-rwxr-xr-x 1 root root 1393 Mar 3 2020 zookeeper-server-start.sh
-rwxr-xr-x 1 root root 1001 Mar 3 2020 zookeeper-server-stop.sh
-rwxr-xr-x 1 root root 968 Mar 3 2020 zookeeper-shell.sh# 确认ZK服务正常启动
[root@master kafka]# sh /middleware/zookeeper/bin/zkCluster.sh start
[root@master kafka]# jps
6720 Jps
6301 QuorumPeerMain# 开启Kafka服务
[root@master kafka]# ./bin/kafka-server-start.sh
USAGE: ./bin/kafka-server-start.sh [-daemon] server.properties [--override property=value]*
[root@master kafka]# ./bin/kafka-server-start.sh -daemon ./config/server.properties# 确认Kafka服务正常启动
[root@master kafka]# jps
7202 Jps
7084 Kafka
6301 QuorumPeerMain
2.2. 伪集群部署
# master配置
[root@master kafka_cluster]# cat kafka-1/config/server.properties | grep -Ev "^$|^#"
broker.id=0
listeners=PLAINTEXT://:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/kafka_cluster/kafka-1/kafka-logs
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.retention.check.interval.ms=300000
zookeeper.connect=localhost:2181/kafka
zookeeper.connection.timeout.ms=18000
group.initial.rebalance.delay.ms=0# node1配置
[root@master kafka_cluster]# cat kafka-2/config/server.properties | grep -Ev "^$|^#"
broker.id=1
listeners=PLAINTEXT://:9093
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/kafka_cluster/kafka-2/kafka-logs
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.retention.check.interval.ms=300000
zookeeper.connect=localhost:2181/kafka
zookeeper.connection.timeout.ms=18000
group.initial.rebalance.delay.ms=0# node2配置
[root@master kafka_cluster]# cat kafka-3/config/server.properties | grep -Ev "^$|^#"
broker.id=2
listeners=PLAINTEXT://:9094
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/kafka_cluster/kafka-3/kafka-logs
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.retention.check.interval.ms=300000
zookeeper.connect=localhost:2181/kafka
zookeeper.connection.timeout.ms=18000
group.initial.rebalance.delay.ms=0# 分别在kafka-1、kafka-2、kafka-3目录下开启服务
[root@master kafka_cluster]# ./kafka-1/bin/kafka-server-start.sh
USAGE: ./bin/kafka-server-start.sh [-daemon] server.properties [--override property=value]*
[root@master kafka]# ./bin/kafka-server-start.sh -daemon ./config/server.properties
2.3. 集群操控脚本
[root@master kafka_cluster]# cat cluster.sh
#!/bin/bashnode_list=`ls -l /kafka_cluster/ | awk '{print$9}' | grep kafka-`case ${1:-help} in
"start")for i in ${node_list[@]}dosu redhat -c "sh /kafka_cluster/$i/bin/kafka-server-start.sh -daemon /kafka_cluster/$i/config/server.properties"echo -e "\033[32m$i Kafka service is STARTED!\033[0m"done;;
"stop")for i in ${node_list[@]}dosu redhat -c "sh /kafka_cluster/$i/bin/kafka-server-stop.sh"echo -e "\033[31m$i Kafka service is STOPPED!\033[0m"done;;
*)echo -e "\033[31mInput ERROR,Please input \"start/stop!\"\033[0m";;
esac# 集群操作脚本使用测试
[root@master kafka_cluster]# chmod 755 cluster.sh
[root@master kafka_cluster]# ln -s /zk_cluster/cluster.sh zk_cluster.sh start
[root@master kafka_cluster]# ./zk_cluster.sh start
# 开启
[root@master kafka_cluster]# ./cluster.sh start
kafka-1 Kafka service is STARTED!
kafka-2 Kafka service is STARTED!
kafka-3 Kafka service is STARTED!# 关闭(先关闭Kafka,等进程全部退出后方可关闭ZK服务,否则Kafka将一直存在,直到被kill -9杀死进程)
[root@master kafka_cluster]# ./cluster.sh stop
kafka-1 Kafka service is STOPPED!
kafka-2 Kafka service is STOPPED!
kafka-3 Kafka service is STOPPED!# 进程验证
[root@master kafka_cluster]# jps
1459988 Kafka
1459253 Kafka
1460099 Jps
1453443 QuorumPeerMain
1459617 Kafka
1453374 QuorumPeerMain
1453529 QuorumPeerMain# 一键修改集群环境变量
[root@master kafka_cluster]# sed -i '$a # Kafka' /etc/profile && sed -i '$a export KAFKA_HOME=/kafka_cluster/kafka-1' /etc/profile && sed -i '$a export PATH=$KAFKA_HOME/bin/:$PATH' /etc/profile && source /etc/profile
2.5. 客户端命令行操作
Kafka可执行目录下存在多个脚本控制文件,常用的有topic、producer、consumer、consumer group四种,其他仅做了解即可。
[root@master kafka_cluster]# cd kafka-1/bin/
[root@master bin]# ll
total 172
-rwxr-xr-x 1 redhat redhat 1423 Jun 5 17:03 connect-distributed.sh
-rwxr-xr-x 1 redhat redhat 1396 Jun 5 17:03 connect-mirror-maker.sh
-rwxr-xr-x 1 redhat redhat 1420 Jun 5 17:03 connect-standalone.sh
-rwxr-xr-x 1 redhat redhat 861 Jun 5 17:03 kafka-acls.sh
-rwxr-xr-x 1 redhat redhat 873 Jun 5 17:03 kafka-broker-api-versions.sh # 用于验证不同版本的Broker和Consumer之间的适配行
-rwxr-xr-x 1 redhat redhat 871 Jun 5 17:03 kafka-cluster.sh
-rwxr-xr-x 1 redhat redhat 864 Jun 5 17:03 kafka-configs.sh # 修改配置,支持操作主题、broker、用户和客户端这3个类型的配置
-rwxr-xr-x 1 redhat redhat 945 Jun 5 17:03 kafka-console-consumer.sh # 通过控制台订阅并接收消息
-rwxr-xr-x 1 redhat redhat 944 Jun 5 17:03 kafka-console-producer.sh # 通过控制台发送消息
-rwxr-xr-x 1 redhat redhat 871 Jun 5 17:03 kafka-consumer-groups.sh # kafka消费者组控制,支持查看与设置offset等操作
-rwxr-xr-x 1 redhat redhat 959 Jun 5 17:03 kafka-consumer-perf-test.sh # 用于对消费消息的性能做测试
-rwxr-xr-x 1 redhat redhat 882 Jun 5 17:03 kafka-delegation-tokens.sh
-rwxr-xr-x 1 redhat redhat 869 Jun 5 17:03 kafka-delete-records.sh
-rwxr-xr-x 1 redhat redhat 866 Jun 5 17:03 kafka-dump-log.sh # 用来查看消息文件的数据,--file参数为将数据读取到一个文件中,包含了消息集合位移范围、数量、创建时间、压缩算法等信息,如果想看每一条的具体信息,可以通过在命令之后添--deep-iteration参数
-rwxr-xr-x 1 redhat redhat 877 Jun 5 17:03 kafka-e2e-latency.sh
-rwxr-xr-x 1 redhat redhat 863 Jun 5 17:03 kafka-features.sh
-rwxr-xr-x 1 redhat redhat 865 Jun 5 17:03 kafka-get-offsets.sh # 查看当前某个topic的offset位置
-rwxr-xr-x 1 redhat redhat 867 Jun 5 17:03 kafka-jmx.sh # 修改JMX
-rwxr-xr-x 1 redhat redhat 870 Jun 5 17:03 kafka-leader-election.sh # Leader分区重新选举
-rwxr-xr-x 1 redhat redhat 863 Jun 5 17:03 kafka-log-dirs.sh
-rwxr-xr-x 1 redhat redhat 881 Jun 5 17:03 kafka-metadata-quorum.sh
-rwxr-xr-x 1 redhat redhat 873 Jun 5 17:03 kafka-metadata-shell.sh
-rwxr-xr-x 1 redhat redhat 862 Jun 5 17:03 kafka-mirror-maker.sh
-rwxr-xr-x 1 redhat redhat 959 Jun 5 17:03 kafka-producer-perf-test.sh # 用于对生产消息的性能做测试
-rwxr-xr-x 1 redhat redhat 874 Jun 5 17:03 kafka-reassign-partitions.sh # 分区重分配工具
-rwxr-xr-x 1 redhat redhat 874 Jun 5 17:03 kafka-replica-verification.sh
-rwxr-xr-x 1 redhat redhat 10884 Jun 5 17:03 kafka-run-class.sh
-rwxr-xr-x 1 redhat redhat 1376 Jun 5 17:03 kafka-server-start.sh # 启动Kafka服务
-rwxr-xr-x 1 redhat redhat 1361 Jun 5 17:03 kafka-server-stop.sh # 停止Kafka服务
-rwxr-xr-x 1 redhat redhat 860 Jun 5 17:03 kafka-storage.sh
-rwxr-xr-x 1 redhat redhat 956 Jun 5 17:03 kafka-streams-application-reset.sh
-rwxr-xr-x 1 redhat redhat 863 Jun 5 17:03 kafka-topics.sh # 主题管理工具,创建、查看、修改和删除等操作
-rwxr-xr-x 1 redhat redhat 879 Jun 5 17:03 kafka-transactions.sh
-rwxr-xr-x 1 redhat redhat 958 Jun 5 17:03 kafka-verifiable-consumer.sh
-rwxr-xr-x 1 redhat redhat 958 Jun 5 17:03 kafka-verifiable-producer.sh
-rwxr-xr-x 1 redhat redhat 1714 Jun 5 17:03 trogdor.sh
drwxr-xr-x 2 redhat redhat 4096 Jun 5 17:03 windows
-rwxr-xr-x 1 redhat redhat 867 Jun 5 17:03 zookeeper-security-migration.sh
-rwxr-xr-x 1 redhat redhat 1393 Jun 5 17:03 zookeeper-server-start.sh # kafka自带zk的服务控制工具
-rwxr-xr-x 1 redhat redhat 1366 Jun 5 17:03 zookeeper-server-stop.sh
-rwxr-xr-x 1 redhat redhat 1019 Jun 5 17:03 zookeeper-shell.sh
2.5.1. Topic
获取参数帮助信息方法:
[root@master bin]# sh kafka-topics.sh --help
常见参数说明:
- –bootstrap-server <String: server to connect to>:连接Kafka Broker主机名称和端口(高版本);
- –zookeeper <String: hosts>:连接ZK服务和端口(低版本);
- –topic <String: topic> :操作的Topic名称;
- –create:创建;
- –delete:删除;
- –alter:修改;
- –list:列表查看;
- –describe:查看详细信息;
- –partitions <Integer: # of partitions>:设置分区数(分区数目客户端命令行操作只能增加不能减少);
- –replication-factor <Integer replication factor>:设置副本数;
- –config <String: name=value>:修改服务配置。
2.5.2. Producer
获取参数帮助信息方法:
[root@master bin]# sh kafka-console-producer.sh --help
常见参数说明:
- –bootstrap-server <String: server to connect to>:连接Kafka Broker主机名称和端口(高版本);
- –bootstrap-server <String: server toconnect to>:连接Kafka Broker主机名称和端口(低版本);
- –producer.config <String: config file>:生产者配置文件关联;
- –zookeeper <String: hosts>:连接ZK服务和端口(低版本);
- –topic <String: topic> :操作的Topic名称;
2.5.3. Consumer
获取参数帮助信息方法:
[root@master bin]# sh kafka-console-consumer.sh --help
常见参数说明:
- –bootstrap-server <String: server to connect to>:连接Kafka Broker主机名称和端口(高版本);
- –zookeeper <String: hosts>:连接ZK服务和端口(低版本);
- –consumer.config <String: config file>:消费者配置文件关联;
- –topic <String: topic> :操作的Topic名称;
- –from-beginning:消费历史信息;
- –whitelist <String: Java regex(String)>:白名单;
- –partition <Integer: partition>:指定分区;
- –offset <String: consume offset>:指定offset(最新为latest);
- –max-messages <Integer: num_messages>:最大消费数量;
2.5.4. Consumer group
获取参数帮助信息方法:
[root@master bin]# sh kafka-consumer-groups.sh --help
常见参数说明:
- –bootstrap-server <String: server to connect to>:连接Kafka Broker主机名称和端口;
- –delete:删除消费者组;
- –delete-offsets:删除到指定offset;
- –describe:查看详细信息;
- –execute:立刻执行;
- –group <String: consumer group>:指定组名;
- –list:列表查看;
- –offsets:指定offset(最新为latest);
- –reset-offsets:重置offset到某个时刻;
- –to-datetime <String: datetime>:恢复到指定时间的offset,时间格式:YYYY-MM-DDTHH:mm:SS.sss;
- –by-duration <String: duration>:恢复到指定时间的offset,时间格式为:PnDTnHnMnS;
- –to-earliest:恢复到当前保留的最早offset;
- –to-latest:恢复到最新的offset;
- –to-offset <Long: offset>:恢复指定的特殊offset;
- –topic <String: topic>:指定topic;
2.5.5. 操作案例
2.5.5.1. Topic
# 查看当前已有的Topic(__consumer_offsets为消费者offset存储topic,详见本文1.4.5.2章节内容)
[root@master kafka_cluster]# sh kafka-1/bin/kafka-topics.sh --bootstrap-server 127.0.0.1:9092 --list
__consumer_offsets# 创建一个名称为hello_test,分区为5,副本为2的Topic
[root@master kafka_cluster]# sh kafka-1/bin/kafka-topics.sh --bootstrap-server 127.0.0.1:9092 --create --topic hello_test --partitions 5 --replication-factor 2
WARNING: Due to limitations in metric names, topics with a period ('.') or underscore ('_') could collide. To avoid issues it is best to use either, but not both.
# 注意:带有句号('.')或下划线('_')的主题可能会发生冲突。为了避免问题,最好使用其中之一,但不要同时使用
Created topic hello_test.
[root@master kafka_cluster]# sh kafka-1/bin/kafka-topics.sh --bootstrap-server 127.0.0.1:9092 --list
__consumer_offsets
hello_test
[root@master kafka_cluster]# sh kafka-1/bin/kafka-topics.sh --bootstrap-server 127.0.0.1:9092 --topic hello_test --describe
Topic: hello_test TopicId: uo-PiyMRQAOQhGumh6Dmpg PartitionCount: 5 ReplicationFactor: 2 Configs: Topic: hello_test Partition: 0 Leader: 1 Replicas: 1,2 Isr: 1,2Topic: hello_test Partition: 1 Leader: 0 Replicas: 0,1 Isr: 0,1Topic: hello_test Partition: 2 Leader: 2 Replicas: 2,0 Isr: 2,0Topic: hello_test Partition: 3 Leader: 1 Replicas: 1,0 Isr: 1,0Topic: hello_test Partition: 4 Leader: 0 Replicas: 0,2 Isr: 0,2
# 表头介绍:
# Topic:主题名称
# TopicId:主题ID
# PartitionCount:分区总数
# ReplicationFactor:副本数
# Configs:主题配置
# 数据列:主题名称、分区编号、Leader分区在哪个Broker、副本分布在哪个Broker、ISR列表# 更新Topic分区为7
[root@master kafka_cluster]# sh kafka-1/bin/kafka-topics.sh --bootstrap-server 127.0.0.1:9092 --alter --topic hello_test --partitions 7
[root@master kafka_cluster]# sh kafka-1/bin/kafka-topics.sh --bootstrap-server 127.0.0.1:9092 --topic hello_test --describe
Topic: hello_test TopicId: uo-PiyMRQAOQhGumh6Dmpg PartitionCount: 7 ReplicationFactor: 2 Configs: Topic: hello_test Partition: 0 Leader: 1 Replicas: 1,2 Isr: 1,2Topic: hello_test Partition: 1 Leader: 0 Replicas: 0,1 Isr: 0,1Topic: hello_test Partition: 2 Leader: 2 Replicas: 2,0 Isr: 2,0Topic: hello_test Partition: 3 Leader: 1 Replicas: 1,0 Isr: 1,0Topic: hello_test Partition: 4 Leader: 0 Replicas: 0,2 Isr: 0,2Topic: hello_test Partition: 5 Leader: 0 Replicas: 0,2 Isr: 0,2Topic: hello_test Partition: 6 Leader: 1 Replicas: 1,2 Isr: 1,2# 删除前面创建好的Topic
[root@master kafka_cluster]# sh kafka-1/bin/kafka-topics.sh --bootstrap-server 127.0.0.1:9092 --delete --topic hello_test
[root@master kafka_cluster]# sh kafka-1/bin/kafka-topics.sh --bootstrap-server 127.0.0.1:9092 --list
__consumer_offsets
2.5.5.2. Producer + Consumer
# 准备环境(3个终端窗口,创建关联topic)
[root@master kafka_cluster]# sh kafka-1/bin/kafka-topics.sh --bootstrap-server 127.0.0.1:9092 --create --topic test001 --partitions 3 --replication-factor 2
Created topic test001.# 1号窗口代表producer,先输入一些数据
[root@master kafka_cluster]# sh kafka-1/bin/kafka-console-producer.sh --bootstrap-server 127.0.0.1:9092 --topic test001
>111
>222
>333
>444
># 2号窗口代表consumer,此时连接后无任何返回
[root@master kafka_cluster]# sh kafka-1/bin/kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 --topic test001# 在1号窗口继续输入
[root@master kafka_cluster]# sh kafka-1/bin/kafka-console-producer.sh --bootstrap-server 127.0.0.1:9092 --topic test001
>111
>222
>333
>444 # consumer连接前输入数据位置
>
>555
>666
>777
>888
># 2号窗口自动输出(不包含连接前数据,如测试内数据111-444)
[root@master kafka_cluster]# sh kafka-1/bin/kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 --topic test001555
666
777
888# 使用3号窗口查看历史数据,需要携带参数--from-beginning
[root@master kafka_cluster]# sh kafka-1/bin/kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 --topic test001 --from-beginning
111
222
333
444555
666
777
888
# 此时不要关闭3号窗口,保留consumer存在,继续进行Consumer group相关操作
2.5.5.3. Consumer group
# 查看消费者组
[root@master kafka_cluster]# sh kafka-1/bin/kafka-consumer-groups.sh --bootstrap-server 127.0.0.1:9092 --list
console-consumer-11605# 查看详细信息
[root@master kafka_cluster]# sh kafka-1/bin/kafka-consumer-groups.sh --bootstrap-server 127.0.0.1:9092 --group console-consumer-11605 --describeGROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
console-consumer-11605 test001 0 - 0 - console-consumer-401f8ac4-932d-4a18-97ea-45677d9d2f2d /9.134.244.180 console-consumer
console-consumer-11605 test001 1 - 9 - console-consumer-401f8ac4-932d-4a18-97ea-45677d9d2f2d /9.134.244.180 console-consumer
console-consumer-11605 test001 2 - 0 - console-consumer-401f8ac4-932d-4a18-97ea-45677d9d2f2d /9.134.244.180 console-consumer
# 表头介绍:
# GROUP:消费者组的名称
# TOPIC:消费者组订阅的主题名称
# PARTITION:主题的分区编号
# CURRENT-OFFSET:消费者组当前的偏移量(offset),即该分区下一个将要被消费的消息的偏移量
# LOG-END-OFFSET:该分区最新一条消息的偏移量
# LAG:消费者组滞后的消息数量,即当前的偏移量与最新一条消息的偏移量之间的差值
# CONSUMER-ID:消费者客户端的唯一标识符
# HOST:消费者客户端所在的主机名称或 IP 地址
2.5.4. 分区与副本调整
# 准备topic
[root@master kafka_cluster]# sh kafka-1/bin/kafka-topics.sh --bootstrap-server 127.0.0.1:9092 --create --topic hello_test --partitions 2 --replication-factor 2
WARNING: Due to limitations in metric names, topics with a period ('.') or underscore ('_') could collide. To avoid issues it is best to use either, but not both.
Created topic hello_test.
[root@master kafka_cluster]# ./kafka-1/bin/kafka-topics.sh --bootstrap-server 127.0.0.1:9092 --topic hello_test --describe
Topic: hello_test TopicId: hQ7vPPgRQF2XEwhRSxO7nA PartitionCount: 2 ReplicationFactor: 2 Configs: Topic: hello_test Partition: 0 Leader: 0 Replicas: 1,0 Isr: 0,1Topic: hello_test Partition: 1 Leader: 0 Replicas: 0,2 Isr: 0,2# 编辑需要修改的topic(注意文件内容为json格式)
[root@master kafka_cluster]# vim topic_change.json
{"topics":[{"topic":"hello_test"}],"version":1}# 使用重新分配分区脚本生成分配计划
[root@master kafka_cluster]# ./kafka-1/bin/kafka-reassign-partitions.sh --bootstrap-server 127.0.0.1:9092 --topics-to-move-json-file ./topic_change.json --generate --broker-list "0,1,2"
Current partition replica assignment # 当前分区配置
{"version":1,"partitions":[{"topic":"hello_test","partition":0,"replicas":[1,0],"log_dirs":["any","any"]},{"topic":"hello_test","partition":1,"replicas":[0,2],"log_dirs":["any","any"]}]}Proposed partition reassignment configuration # 推荐的分区配置
{"version":1,"partitions":[{"topic":"hello_test","partition":0,"replicas":[1,2],"log_dirs":["any","any"]},{"topic":"hello_test","partition":1,"replicas":[2,0],"log_dirs":["any","any"]}]}# 将推荐的分配计划保存在本地新文件内
[root@master kafka_cluster]# vim replication-factor.json
{"version":1,"partitions":[{"topic":"hello_test","partition":0,"replicas":[1,2],"log_dirs":["any","any"]},{"topic":"hello_test","partition":1,"replicas":[2,0],"log_dirs":["any","any"]}]}# 使用重新分配分区脚本执行分配计划
[root@master kafka_cluster]# ./kafka-1/bin/kafka-reassign-partitions.sh --bootstrap-server 127.0.0.1:9092 --reassignment-json-file ./replication-factor.json --execute
Current partition replica assignment{"version":1,"partitions":[{"topic":"hello_test","partition":0,"replicas":[1,0],"log_dirs":["any","any"]},{"topic":"hello_test","partition":1,"replicas":[0,2],"log_dirs":["any","any"]}]}Save this to use as the --reassignment-json-file option during rollback
Successfully started partition reassignments for hello_test-0,hello_test-1 # 成功启动分区标识# 验证分配计划是否执行成功
[root@master kafka_cluster]# ./kafka-1/bin/kafka-reassign-partitions.sh --bootstrap-server 127.0.0.1:9092 --reassignment-json-file ./replication-factor.json --verify
Status of partition reassignment:
Reassignment of partition hello_test-0 is completed. # 重新分配分区完成标识
Reassignment of partition hello_test-1 is completed.Clearing broker-level throttles on brokers 0,1,2
Clearing topic-level throttles on topic hello_test# 查看topic详情
[root@master kafka_cluster]# ./kafka-1/bin/kafka-topics.sh --bootstrap-server 127.0.0.1:9092 --topic hello_test --describe
Topic: hello_test TopicId: hQ7vPPgRQF2XEwhRSxO7nA PartitionCount: 2 ReplicationFactor: 2 Configs: Topic: hello_test Partition: 0 Leader: 1 Replicas: 1,2 Isr: 1,2Topic: hello_test Partition: 1 Leader: 0 Replicas: 2,0 Isr: 0,2
2.5.4.1. 分区扩容
[root@master kafka_cluster]# ./kafka-1/bin/kafka-topics.sh --bootstrap-server 127.0.0.1:9092 --topic hello_test --describe
Topic: hello_test TopicId: hQ7vPPgRQF2XEwhRSxO7nA PartitionCount: 2 ReplicationFactor: 2 Configs: Topic: hello_test Partition: 0 Leader: 1 Replicas: 1,2 Isr: 1,2Topic: hello_test Partition: 1 Leader: 0 Replicas: 2,0 Isr: 0,2# 使用topic脚本可以直接扩容分区,但不支持缩容(缩容需要使用分配计划修改)
[root@master kafka_cluster]# ./kafka-1/bin/kafka-topics.sh --alter --bootstrap-server 127.0.0.1:9092 --topic hello_test --partitions 8
[root@master kafka_cluster]# ./kafka-1/bin/kafka-topics.sh --bootstrap-server 127.0.0.1:9092 --topic hello_test --describe
Topic: hello_test TopicId: hQ7vPPgRQF2XEwhRSxO7nA PartitionCount: 8 ReplicationFactor: 2 Configs: Topic: hello_test Partition: 0 Leader: 1 Replicas: 1,2 Isr: 1,2Topic: hello_test Partition: 1 Leader: 0 Replicas: 2,0 Isr: 0,2Topic: hello_test Partition: 2 Leader: 0 Replicas: 0,2 Isr: 0,2Topic: hello_test Partition: 3 Leader: 1 Replicas: 1,2 Isr: 1,2Topic: hello_test Partition: 4 Leader: 2 Replicas: 2,0 Isr: 2,0Topic: hello_test Partition: 5 Leader: 0 Replicas: 0,1 Isr: 0,1Topic: hello_test Partition: 6 Leader: 1 Replicas: 1,0 Isr: 1,0Topic: hello_test Partition: 7 Leader: 2 Replicas: 2,1 Isr: 2,1
2.5.4.2. 副本扩容
# 生成分配计划
[root@master kafka_cluster]# ./kafka-1/bin/kafka-reassign-partitions.sh --bootstrap-server 127.0.0.1:9092 --topics-to-move-json-file ./topic_change.json --generate --broker-list "1,2"
Current partition replica assignment
{"version":1,"partitions":[{"topic":"hello_test","partition":0,"replicas":[1,2],"log_dirs":["any","any"]},{"topic":"hello_test","partition":1,"replicas":[2,0],"log_dirs":["any","any"]},{"topic":"hello_test","partition":2,"replicas":[0,2],"log_dirs":["any","any"]},{"topic":"hello_test","partition":3,"replicas":[1,2],"log_dirs":["any","any"]},{"topic":"hello_test","partition":4,"replicas":[2,0],"log_dirs":["any","any"]},{"topic":"hello_test","partition":5,"replicas":[0,1],"log_dirs":["any","any"]},{"topic":"hello_test","partition":6,"replicas":[1,0],"log_dirs":["any","any"]},{"topic":"hello_test","partition":7,"replicas":[2,1],"log_dirs":["any","any"]}]}Proposed partition reassignment configuration
{"version":1,"partitions":[{"topic":"hello_test","partition":0,"replicas":[2,1],"log_dirs":["any","any"]},{"topic":"hello_test","partition":1,"replicas":[1,2],"log_dirs":["any","any"]},{"topic":"hello_test","partition":2,"replicas":[2,1],"log_dirs":["any","any"]},{"topic":"hello_test","partition":3,"replicas":[1,2],"log_dirs":["any","any"]},{"topic":"hello_test","partition":4,"replicas":[2,1],"log_dirs":["any","any"]},{"topic":"hello_test","partition":5,"replicas":[1,2],"log_dirs":["any","any"]},{"topic":"hello_test","partition":6,"replicas":[2,1],"log_dirs":["any","any"]},{"topic":"hello_test","partition":7,"replicas":[1,2],"log_dirs":["any","any"]}]}# 保存分配计划
[root@master kafka_cluster]# vim replication-factor.json
{"version":1,"partitions":[{"topic":"hello_test","partition":0,"replicas":[2,1,0],"log_dirs":["any","any","any"]},{"topic":"hello_test","partition":1,"replicas":[1,2,0],"log_dirs":["any","any","any"]},{"topic":"hello_test","partition":2,"replicas":[2,1,0],"log_dirs":["any","any","any"]},{"topic":"hello_test","partition":3,"replicas":[1,2,0],"log_dirs":["any","any","any"]},{"topic":"hello_test","partition":4,"replicas":[2,1,0],"log_dirs":["any","any","any"]},{"topic":"hello_test","partition":5,"replicas":[1,2,0],"log_dirs":["any","any","any"]},{"topic":"hello_test","partition":6,"replicas":[2,1,0],"log_dirs":["any","any","any"]},{"topic":"hello_test","partition":7,"replicas":[1,2,0],"log_dirs":["any","any","any"]}]}# 立即执行
[root@master kafka_cluster]# ./kafka-1/bin/kafka-reassign-partitions.sh --bootstrap-server 127.0.0.1:9092 --reassignment-json-file ./replication-factor.json --execute
Current partition replica assignment{"version":1,"partitions":[{"topic":"hello_test","partition":0,"replicas":[1,2],"log_dirs":["any","any"]},{"topic":"hello_test","partition":1,"replicas":[2,0],"log_dirs":["any","any"]},{"topic":"hello_test","partition":2,"replicas":[0,2],"log_dirs":["any","any"]},{"topic":"hello_test","partition":3,"replicas":[1,2],"log_dirs":["any","any"]},{"topic":"hello_test","partition":4,"replicas":[2,0],"log_dirs":["any","any"]},{"topic":"hello_test","partition":5,"replicas":[0,1],"log_dirs":["any","any"]},{"topic":"hello_test","partition":6,"replicas":[1,0],"log_dirs":["any","any"]},{"topic":"hello_test","partition":7,"replicas":[2,1],"log_dirs":["any","any"]}]}Save this to use as the --reassignment-json-file option during rollback
Successfully started partition reassignments for hello_test-0,hello_test-1,hello_test-2,hello_test-3,hello_test-4,hello_test-5,hello_test-6,hello_test-7# 验证结果
[root@master kafka_cluster]# ./kafka-1/bin/kafka-reassign-partitions.sh --bootstrap-server 127.0.0.1:9092 --reassignment-json-file ./replication-factor.json --verify
Status of partition reassignment:
Reassignment of partition hello_test-0 is completed.
Reassignment of partition hello_test-1 is completed.
Reassignment of partition hello_test-2 is completed.
Reassignment of partition hello_test-3 is completed.
Reassignment of partition hello_test-4 is completed.
Reassignment of partition hello_test-5 is completed.
Reassignment of partition hello_test-6 is completed.
Reassignment of partition hello_test-7 is completed.Clearing broker-level throttles on brokers 0,1,2
Clearing topic-level throttles on topic hello_test# 查看详情
[root@master kafka_cluster]# ./kafka-1/bin/kafka-topics.sh --bootstrap-server 127.0.0.1:9092 --topic hello_test --describeTopic: hello_test TopicId: hQ7vPPgRQF2XEwhRSxO7nA PartitionCount: 8 ReplicationFactor: 3 Configs: Topic: hello_test Partition: 0 Leader: 1 Replicas: 2,1,0 Isr: 1,2,0 Topic: hello_test Partition: 1 Leader: 0 Replicas: 1,2,0 Isr: 0,2,1Topic: hello_test Partition: 2 Leader: 0 Replicas: 2,1,0 Isr: 0,2,1Topic: hello_test Partition: 3 Leader: 1 Replicas: 1,2,0 Isr: 1,2,0Topic: hello_test Partition: 4 Leader: 2 Replicas: 2,1,0 Isr: 2,0,1Topic: hello_test Partition: 5 Leader: 0 Replicas: 1,2,0 Isr: 0,1,2Topic: hello_test Partition: 6 Leader: 1 Replicas: 2,1,0 Isr: 1,0,2Topic: hello_test Partition: 7 Leader: 2 Replicas: 1,2,0 Isr: 2,1,0
2.5.5. 消息积压清理
使用Kafka自带的测试工具进行测试。
# 创建一个测试topic
[root@master kafka_cluster]# sh kafka-1/bin/kafka-topics.sh --bootstrap-server 127.0.0.1:9092 --create --topic test --partitions 5 --replication-factor 2
Created topic test.# 生产者
[root@master kafka_cluster]# sh kafka-1/bin/kafka-producer-perf-test.sh --topic test --num-records=100000000 --producer-props bootstrap.servers=127.0.0.1:9092 batch.size=10000 --throughput -1 --record-size 100
1502928 records sent, 300585.6 records/sec (28.67 MB/sec), 566.8 ms avg latency, 1350.0 ms max latency.
~
100000000 records sent, 555632.726768 records/sec (52.99 MB/sec), 538.13 ms avg latency, 3616.00 ms max latency, 489 ms 50th, 824 ms 95th, 1240 ms 99th, 3300 ms 99.9th. # 传输完成标识,展示了每秒发送的消息数、吞吐量、平均延时,以及几个分位数,重点关注末尾的分位数,3300 ms 99.9th表示99.9%的消息延时都在3300 ms之内
# --num-records=100000000:将要发送的消息数量
# batch.size=10000:批处理大小
# --throughput -1:设置生产者的期望吞吐量。"-1"表示生产者将尽可能快地发送消息
# --record-size 100:每条消息的大小为100字节# 消费者
[root@master kafka_cluster]# sh kafka-1/bin/kafka-consumer-perf-test.sh --topic test --broker-list 127.0.0.1:9092 --messages=100000000 --num-fetch-threads 1 --fetch-size=1000
WARNING: option [threads] and [num-fetch-threads] have been deprecated and will be ignored by the test
start.time, end.time, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec, rebalance.time.ms, fetch.time.ms, fetch.MB.sec, fetch.nMsg.sec
2023-08-30 19:33:27:781, 2023-08-30 19:36:27:457, 9536.7437, 53.0774, 100000014, 556557.4367, 351, 179325, 53.1813, 557646.8089 # 完成标识
# --messages=100000000:指定测试消息的总数
# --num-fetch-threads 1:指定拉取消息的线程数为1个
# --fetch-size=1000:指定每次拉取消息的大小为1000字节# 查看消息积压
[root@master kafka_cluster]# sh kafka-1/bin/kafka-consumer-groups.sh --bootstrap-server 127.0.0.1:9092 --list
perf-consumer-63840
[root@master kafka_cluster]# sh kafka-1/bin/kafka-consumer-groups.sh --bootstrap-server 127.0.0.1:9092 --describe --group perf-consumer-99520GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
perf-consumer-99520 test 0 3596220 4426920 830700 perf-consumer-client-f7810e67-2129-44e4-aabd-1f1789119c04 /9.134.244.180 perf-consumer-client
perf-consumer-99520 test 1 3104236 4129066 1024830 perf-consumer-client-f7810e67-2129-44e4-aabd-1f1789119c04 /9.134.244.180 perf-consumer-client
perf-consumer-99520 test 4 3104522 4129172 1024650 perf-consumer-client-f7810e67-2129-44e4-aabd-1f1789119c04 /9.134.244.180 perf-consumer-client
perf-consumer-99520 test 3 3596115 4426905 830790 perf-consumer-client-f7810e67-2129-44e4-aabd-1f1789119c04 /9.134.244.180 perf-consumer-client
perf-consumer-99520 test 2 5437555 5465005 27450 perf-consumer-client-f7810e67-2129-44e4-aabd-1f1789119c04 /9.134.244.180 perf-consumer-client
# LAG越大积压越多# 恢复到最新的offset,LAG = 0,未消费的数据将直接被放弃消费,从最新offset继续开始进行消费
[root@master kafka_cluster]# sh kafka-1/bin/kafka-consumer-groups.sh --bootstrap-server 127.0.0.1:9092 --group perf-consumer-99520 --reset-offsets --topic test --to-latest --executeGROUP TOPIC PARTITION NEW-OFFSET
perf-consumer-99520 test 0 25377165
perf-consumer-99520 test 1 27216340
perf-consumer-99520 test 4 27214992
perf-consumer-99520 test 3 25377341
perf-consumer-99520 test 2 32609516
[root@master kafka_cluster]# sh kafka-1/bin/kafka-consumer-groups.sh --bootstrap-server 127.0.0.1:9092 --describe --group perf-consumer-99520Consumer group 'perf-consumer-99520' has no active members.GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
perf-consumer-99520 test 0 25377165 25377165 0 - - -
perf-consumer-99520 test 1 27216340 27216340 0 - - -
perf-consumer-99520 test 4 27214992 27214992 0 - - -
perf-consumer-99520 test 3 25377341 25377341 0 - - -
perf-consumer-99520 test 2 32609516 32609516 0 - - -
2.5.6. 重选选举Leader主分区
[root@master kafka_cluster]# sh kafka-1/bin/kafka-topics.sh --bootstrap-server 127.0.0.1:9092 --describe --topic test
Topic: test TopicId: 2_bqk7HcTzWIDNAqkNondQ PartitionCount: 5 ReplicationFactor: 2 Configs: Topic: test Partition: 0 Leader: 1 Replicas: 1,2 Isr: 1,2Topic: test Partition: 1 Leader: 0 Replicas: 0,1 Isr: 0,1Topic: test Partition: 2 Leader: 2 Replicas: 2,0 Isr: 2,0Topic: test Partition: 3 Leader: 1 Replicas: 1,0 Isr: 1,0Topic: test Partition: 4 Leader: 0 Replicas: 0,2 Isr: 0,2# 指定topic与partition
[root@master kafka_cluster]# sh kafka-1/bin/kafka-leader-election.sh --bootstrap-server 127.0.0.1:9092 --topic test --partition 1 --election-type preferred
Valid replica already elected for partitions test-1
# "preferred"或者"unclean"分别表示优先选举副本、或者允许选举副本状态不一致的节点作为Leader# 使用json文件
[root@master kafka_cluster]# cat replica-election.json
{"partitions": [{"topic": "test","partition": 0},{"topic": "test001","partition": 1}]}[root@master kafka_cluster]# sh kafka-1/bin/kafka-leader-election.sh --bootstrap-server 127.0.0.1:9092 --path-to-json-file ./replica-election.json --election-type UNCLEAN
Valid replica already elected for partitions test-1, test-0
2.6. 报错记录
2.6.1. 创建topic时报错
[root@master kafka_cluster]# sh kafka-1/bin/kafka-topics.sh --bootstrap-server 127.0.0.1:9092 --create --topic test --partitions 5 --replication-factor 2
Error while executing topic command : Replication factor: 2 larger than available brokers: 1.
[2023-08-31 11:35:06,656] ERROR org.apache.kafka.common.errors.InvalidReplicationFactorException: Replication factor: 2 larger than available brokers: 1.
出现这样情况是因为kafka的节点只有1个,但是备份却大于1个,查看zk下/kafka/brokers/ids时发现只有[0],ids缺失1和2,重启Kafka服务解决该问题。
2.6.2. 使用工具时直接返回参数列表
这种情况一般都是命令参数使用错误导致,需要查看参数列表重新配置工具参数进行使用。
2.6.3. 未知的选项
[root@master kafka_cluster]# sh kafka-1/bin/kafka-topics.sh --broker-list 127.0.0.1:9092 --topic test --describe
Exception in thread "main" joptsimple.UnrecognizedOptionException: broker-list is not a recognized option~
报错提示:broker-list不是一个可以识别的选项,正确参数为–bootstrap-server。
2.6.4. 重置offset时异常
[root@master kafka_cluster]# sh kafka-1/bin/kafka-consumer-groups.sh --bootstrap-server 127.0.0.1:9092 --group perf-consumer-83143 --reset-offsets --topic test001 --to-latest
WARN: No action will be performed as the --execute option is missing.In a future major release, the default behavior of this command will be to prompt the user before executing the reset rather than doing a dry run. You should add the --dry-run option explicitly if you are scripting this command and want to keep the current default behavior without prompting.Error: Assignments can only be reset if the group 'perf-consumer-83143' is inactive, but the current state is Stable.GROUP TOPIC PARTITION NEW-OFFSET
该报错是因为消费者组有消费者正在消费,没有关闭,把消费者关闭之后,重新移动指定分区的偏移量即可。
[root@master kafka_cluster]# sh kafka-1/bin/kafka-consumer-groups.sh --bootstrap-server 127.0.0.1:9092 --group perf-consumer-83143 --reset-offsets --topic test --to-latest
WARN: No action will be performed as the --execute option is missing.In a future major release, the default behavior of this command will be to prompt the user before executing the reset rather than doing a dry run. You should add the --dry-run option explicitly if you are scripting this command and want to keep the current default behavior without prompting.Error: Executing consumer group command failed due to org.apache.kafka.common.errors.UnknownTopicOrPartitionException: This server does not host this topic-partition.
java.util.concurrent.ExecutionException: org.apache.kafka.common.errors.UnknownTopicOrPartitionException: This server does not host this topic-partition.~
Caused by: org.apache.kafka.common.errors.UnknownTopicOrPartitionException: This server does not host this topic-partition.
UnknownTopicOrPartitionException报错是因为topic或partition不存在。
2.6.5. json格式文件工具
参考文章:JSON数据格式与格式化操作详解
2.6.6. Leader重新选举报错
[root@master kafka_cluster]# sh kafka-1/bin/kafka-leader-election.sh --bootstrap-server 127.0.0.1:9092 --topic test --election-type PREFERRED --all-topic-partitions
Exception in thread "main" kafka.common.AdminCommandFailedException: One and only one of the following options is required: topic, all-topic-partitions, path-to-json-file~
该报错是因为–all-topic-partitions参数只能通过–path-to-json-file引入文件进行重新选举操作。
[root@master kafka_cluster]# sh kafka-1/bin/kafka-leader-election.sh --bootstrap-server 127.0.0.1:9092 --path-to-json-file ./replica-election.json --election-type UNCLEAN
Valid replica already elected for partitions test-1, test-0
3、Python连接Kafka
清理环境,避免现象冲突:
[root@master kafka_cluster]# sh kafka-1/bin/kafka-topics.sh --bootstrap-server 127.0.0.1:9092 --list
__consumer_offsets
下载所需python依赖包:kafka-python
pip install kafka-python
pip list
3.1. 生产者
from kafka import KafkaProducer# 连接kafka
producer = KafkaProducer(bootstrap_servers='9.134.244.180:9092')msg = 'Hello test!'.encode('utf-8')for _ in range(100):# 发送100条消息到topic ceshi,消息内容为utf-8编码的Hello test!producer.send('ceshi',msg)producer.flush(timeout=60) # 重试时间60s
# 关闭连接
producer.close()
运行生产者代码后,查看topic,此时已经创建出来了ceshi topic,代表代码生效,等待代码执行完成即可(提示:进程已结束,退出代码为 0)。
[root@master kafka_cluster]# sh kafka-1/bin/kafka-topics.sh --bootstrap-server 127.0.0.1:9092 --list
__consumer_offsets
ceshi
3.2. 消费者
from kafka import KafkaConsumer# 连接kafka,topic为ceshi,group为ceshi,消费位置从最小开始(包含历史数据)
consumer = KafkaConsumer('ceshi',bootstrap_servers='9.134.244.180:9092',group_id='ceshi',auto_offset_reset='smallest'
)for msg in consumer:recv = '%s:%d:%d:key=%s,value=%s' %(msg.topic,msg.partition,msg.offset,msg.key,msg.value.decode('utf-8'))print(recv)
再执行消费者代码,即可查看到弹出内容:
3.3. 执行结果
ceshi:0:188:key=None,value=Hello test!
~
# 应该弹出100次# 查看消费者组与其消费offset
[root@master kafka_cluster]# sh kafka-1/bin/kafka-consumer-groups.sh --bootstrap-server 127.0.0.1:9092 --list
ceshi
[root@master kafka_cluster]# sh kafka-1/bin/kafka-consumer-groups.sh --bootstrap-server 127.0.0.1:9092 --describe --group ceshiGROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
ceshi ceshi 0 100 100 0 kafka-python-2.0.2-90fcfcc8-3049-4628-9783-b880e6cf8800 /10.99.17.133 kafka-python-2.0.2