DEFORMABLE DETR: DEFORMABLE TRANSFORMERS FOR END-TO-END OBJECT DETECTION
- 摘要
- 1 介绍
- 2 相关工作
- 3 重新审视 Transformers 和 DETR
- 4 方法
- 4.1 用于端到端目标检测的可变形transformer
- 4.2 Deformable Detr的其他改进和变型
- 5 实验
- 5.1 和DETR 比较
- 5.2 消融实验
- 5.3 与最先进方法的比较
- 6 结论
FOR END-TO-END OBJECT DETECTION)
摘要
DETR最近被提出,旨在消除目标检测中许多手工设计组件的需要,同时表现出良好的性能。然而,它在收敛速度较慢和特征空间分辨率有限方面存在问题,这是由于Transformer注意模块在处理图像特征图时的局限性。为了减轻这些问题,我们提出了Deformable DETR,其注意模块仅关注围绕参考点的一小组关键采样点。Deformable DETR可以在比DETR少10倍的训练时期内实现更好的性能(特别是在小目标上)。对COCO基准的大量实验证明了我们方法的有效性。代码已发布在https://github.com/fundamentalvision/Deformable-DETR。
1 介绍
现代目标检测器使用许多手工设计的组件(Liu等,2020),例如锚点生成、基于规则的训练目标分配、非极大值抑制(NMS)后处理等。它们不是完全端到端的。最近,Carion等人(2020)提出了DETR,以消除对这些手工设计组件的需求,并构建了第一个完全端到端的目标检测器,实现了非常有竞争力的性能。DETR利用了一个简单的架构,将卷积神经网络(CNNs)和Transformer(Vaswani等,2017)编码器-解码器组合在一起。他们充分利用了Transformer的多功能和强大的关系建模能力,以替代手工制定的规则,在适当设计的训练信号下实现了这一目标。
尽管DETR具有有趣的设计和良好的性能,但它也存在一些问题:(1)DETR需要比现有的目标检测器更长的训练周期才能收敛。例如,在COCO(Lin等,2014)基准测试中,DETR需要500个周期才能收敛,这大约比Faster R-CNN(Ren等,2015)慢10到20倍。 (2)DETR在检测小目标方面性能相对较低。现代目标检测器通常利用多尺度特征,其中小目标是从高分辨率特征图中检测的。与此同时,高分辨率特征图会导致DETR的复杂度不可接受。上述问题主要归因于Transformer组件在处理图像特征图方面的不足。在初始化时,注意模块将几乎均匀的关注权重分配给特征图中的所有像素。需要较长的训练周期来学习关注权重以便聚焦在稀疏的有意义的位置上。另一方面,Transformer编码器中的注意权重计算与像素数量呈二次计算关系。因此,处理高分辨率特征图具有非常高的计算和内存复杂度。
在图像领域,可变形卷积(Deformable Convolution)是一种强大且高效的机制,可以聚焦于稀疏的空间位置。它自然地避免了上述提到的问题。然而,它缺乏元素关系建模机制,这是DETR成功的关键。
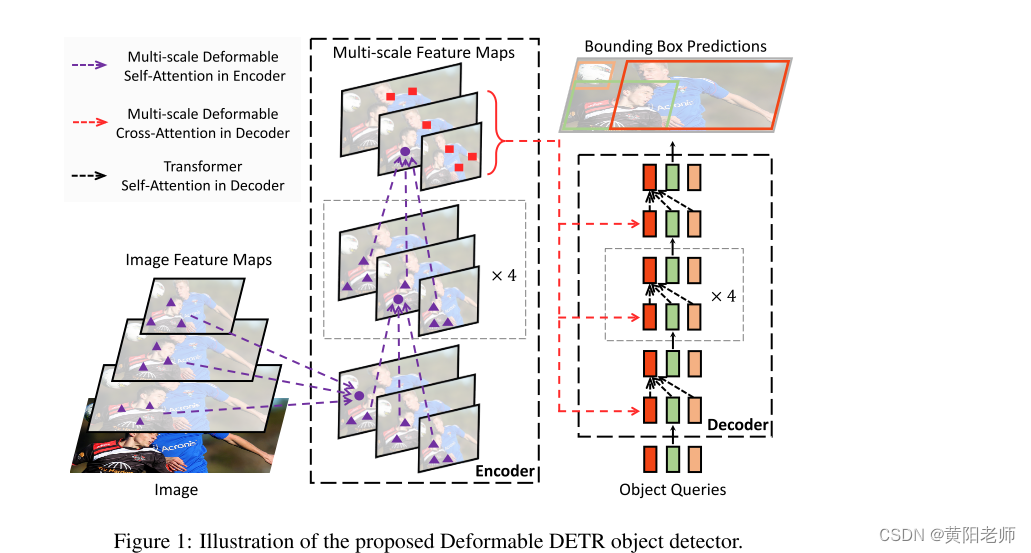
在本论文中,我们提出了Deformable DETR,它缓解了DETR的收敛速度慢和高复杂性的问题。它结合了可变形卷积的稀疏空间采样和Transformer的关系建模能力。我们提出了可变形注意模块,它作为所有特征图像素中杰出关键元素的预过滤器,关注一小组采样位置。该模块可以自然地扩展到聚合多尺度特征,无需FPN(特征金字塔网络)的帮助。在Deformable DETR中,我们利用(多尺度)可变形注意模块替换了处理特征图的Transformer注意模块,如图1所示。
Deformable DETR为我们提供了利用各种端到端目标检测器变种的可能性,这要归功于其快速的收敛速度以及计算和内存的高效性。我们探索了一种简单而有效的迭代边界框细化机制,以提高检测性能。我们还尝试了一个两阶段的Deformable DETR,其中区域提议也是由Deformable DETR的变种生成的,然后输入解码器进行迭代边界框细化。
在COCO基准测试上进行的大量实验证明了我们方法的有效性。与DETR相比,Deformable DETR在需要的训练时期较少的情况下可以取得更好的性能(尤其是对于小目标)。提出的两阶段Deformable DETR的变种可以进一步提高性能。代码已发布在https://github.com/fundamentalvision/Deformable-DETR。
2 相关工作
高效的注意力机制。Transformers(Vaswani等人,2017)涉及自注意力和交叉注意力机制。 Transformers 最为人所知的一个问题是,在大量关键元素的情况下,其时间和内存复杂度非常高,这在许多情况下限制了模型的可扩展性。最近,已经进行了许多努力来解决这个问题(Tay等人,2020b),这