系统设计系列初衷
System Design Primer: 英文文档 GitHub - donnemartin/system-design-primer: Learn how to design large-scale systems. Prep for the system design interview. Includes Anki flashcards.
中文版: https://github.com/donnemartin/system-design-primer/blob/master/README-zh-Hans.md
初衷主要还是为了学习系统设计,但是这个中文版看起来就像机器翻译的一样,所以还是手动做一些简单的笔记,并且在难以理解的地方对照英文版,根据自己的理解在AI的帮助下进行翻译和知识扩展。
数据库
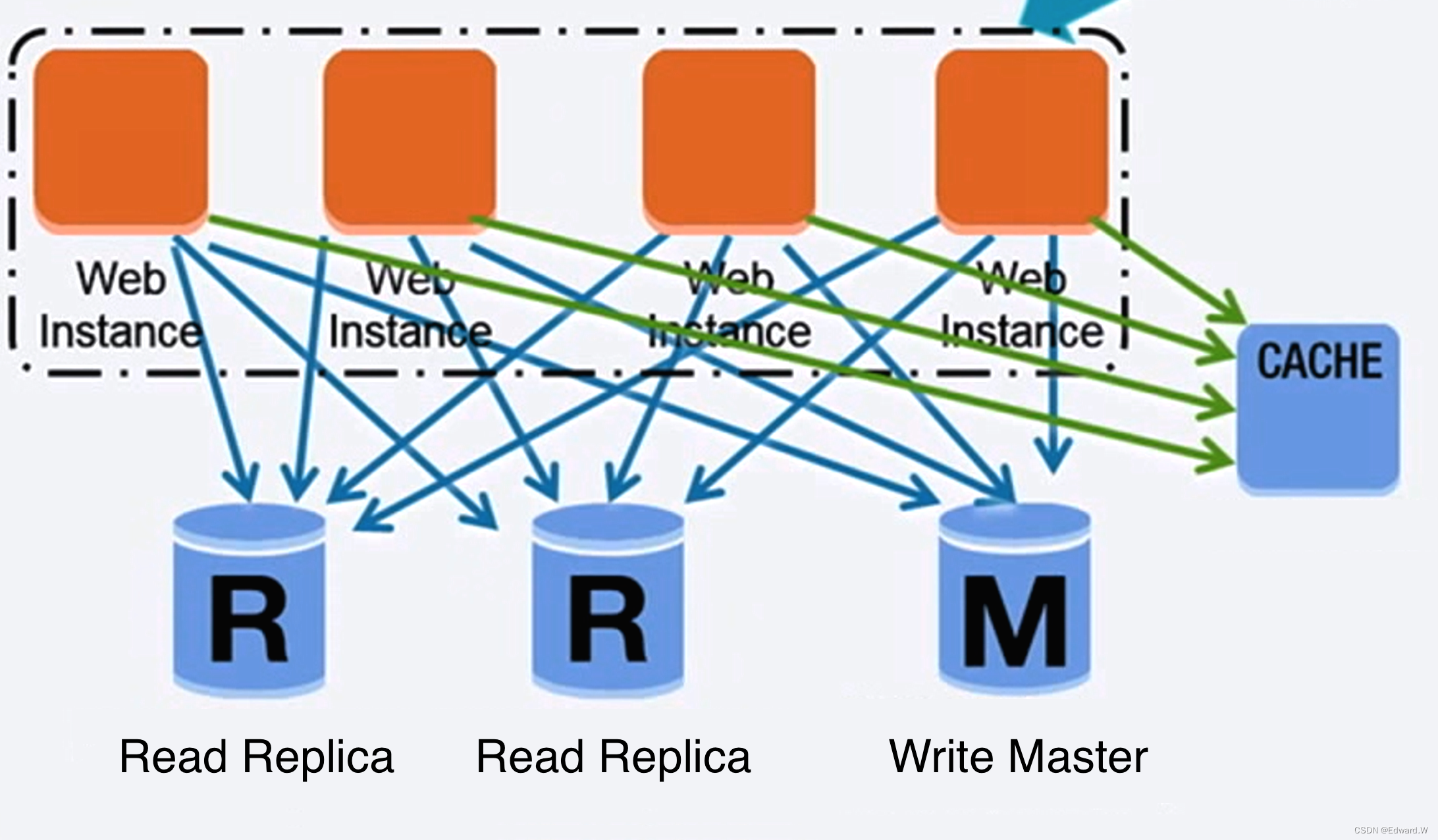
资料来源:扩展你的用户数到第一个一千万
什么是数据库
数据库(DataBase,DB)是一个长期存储在计算机内的、有组织的、有共享的、统一管理的数据集合。它是一个按数据结构来存储和管理数据的计算机软件系统。数据库的概念包含了数据、数据组织、数据存储、数据管理四个方面。数据库具有以下几个特点:
- 数据持久化:数据库中的数据可以长期保存,并且可以在需要时进行查询和修改。
- 数据共享:多个用户和应用程序可以同时访问数据库中的数据,实现数据共享。
- 数据一致性:数据库中的数据保持一致状态,当多个用户同时对数据进行操作时,数据库会确保数据的一致性。
- 数据可扩展性:数据库可以很容易地扩展,增加新的数据和功能。
- 高性能:通过使用索引、缓存等技术,数据库可以提高数据检索和操作的速度。
数据库的类型
数据库主要有以下几种类型:
- 关系型数据库(RDBMS):这种类型的数据库以表格的形式存储数据,表格由行(记录)和列(字段)组成。常见的关系型数据库有 MySQL、Oracle、SQL Server、PostgreSQL 等。关系型数据库的特点是数据结构清晰、易于理解,支持复杂的查询和事务处理,但可能不太适合处理大量的非结构化数据。
- 非关系型数据库(NoSQL):这类数据库主要包括 Key-Value 型(如 Redis、Riak)、列族型(如 Cassandra、HBase)、文档型(如 MongoDB、CouchDB)和图型(如 Neo4j、OrientDB)等。非关系型数据库适合存储结构不规则、半结构化或非结构化的数据,具有较高的横向扩展能力和高性能,但数据一致性可能较低。
- 层次型数据库:这种数据库以树形结构组织数据,其中数据被分为层次结构,每个节点表示一个记录。常见的层次型数据库有 IBM IMS、SAP HANA 等。
- 网络型数据库:这种数据库以图形或网络结构组织数据,数据之间的关系通过节点和边表示。常见的网络型数据库有 Neo4j、OrientDB 等。
- 时序型数据库:这种数据库主要用于存储时间序列数据,如股票行情、气象数据等。常见的时序型数据库有 InfluxDB、OpenTSDB 等。
每种数据库类型都有其适用的场景,需要根据具体需求选择合适的数据库。
关系型数据库管理系统(RDBMS)
像 MYSQL 这样的关系型数据库是一系列以表的形式组织的数据项集合。
事务
事务(transaction)是数据库管理系统(DBMS)中的一个重要概念,它表示为一组逻辑上相关的操作序列。这些操作要么全部完成,要么全部不做,是一个不可分割的工作单位。事务用于保证数据的完整性和一致性,在数据库中执行时,可以是对数据进行增加、修改、删除等操作。
ACID 用来描述关系型数据库事务的特性。
- 原子性 - 每个事务内部所有操作要么全部完成,要么全部不完成。
- 一致性 - 任何事务都使数据库从一个有效的状态转换到另一个有效状态。
- 隔离性 - 并发执行事务的结果与顺序执行事务的结果相同。
- 持久性 - 事务提交后,对系统的影响是永久的。
扩展
关系型数据库扩展包括许多技术:主从复制、主主复制、联合、分片、非规范化和 SQL调优。

资料来源:可扩展性、可用性、稳定性、模式
主从复制
我们将数据库分为主库和从库,主库同时负责读取和写入操作,并复制写入到一个或多个从库中,从库只负责读操作。树状形式的从库再将写入复制到更多的从库中去。如果主库离线,系统可以以只读模式运行,直到某个从库被提升为主库或有新的主库出现。
主从复制的缺点:
- 将从库提升为主库需要执行额外的逻辑。
- 主从数据库的数据一致性问题,存在数据延迟和宕机数据不同步

资料来源:可扩展性、可用性、稳定性、模式
主主复制
两个主库都负责读操作和写操作,写入操作时互相协调。如果其中一个主库挂机,系统可以继续读取和写入。
主主复制的缺点
- 需要添加负载均衡器或者在应用逻辑中做改动,来确定写入哪一个数据库。
- 多数主-主系统要么不能保证一致性(违反 ACID),要么因为同步产生了写入延迟。
- 随着更多写入节点的加入和延迟的提高,如何解决冲突显得越发重要。
- 主主服务器之间的数据一致性同步问题。
数据一致性同步问题可能存在的情况
- 如果主库在将新写入的数据复制到其他节点前挂掉,则有数据丢失的可能。
- 写入会被重放到负责读取操作的副本。副本可能因为过多写操作阻塞住,导致读取功能异常。
- 读取从库越多,需要复制的写入数据就越多,导致更严重的复制延迟。
- 在某些数据库系统中,写入主库的操作可以用多个线程并行写入,但读取副本只支持单线程顺序地写入。
- 复制意味着更多的硬件和额外的复杂度。
联合
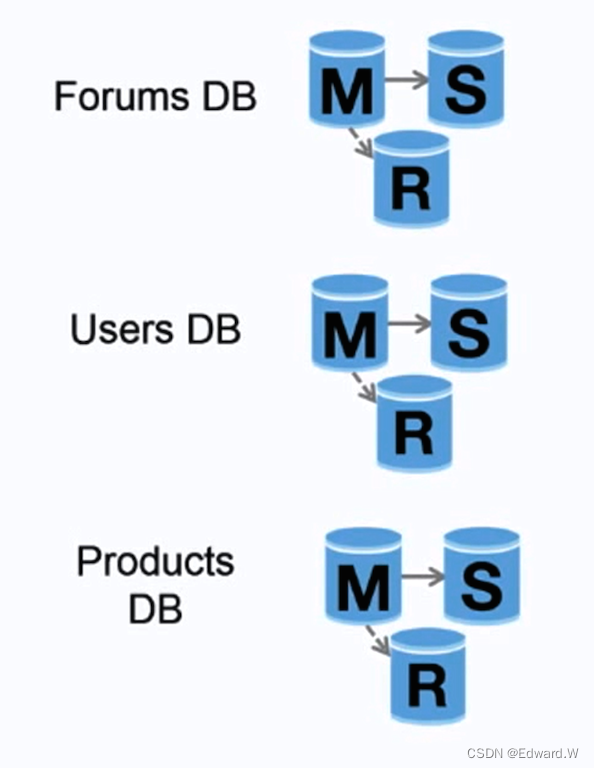
资料来源:扩展你的用户数到第一个一千万
联合(或按功能划分)将数据库按对应功能分割。例如,可以有三个数据库:论坛、用户和产品,而不仅是一个单体数据库,从而减少每个数据库的读取和写入流量,减少复制延迟。较小的数据库意味着更多适合放入内存的数据,进而意味着更高的缓存命中几率。没有只能串行写入的中心化主库,你可以并行写入,提高负载能力。
联合的缺点
- 如果数据库模式需要大量的功能和数据表,联合的效率并不好。
- 需要更新应用程序的逻辑来确定要读取和写入哪个数据库。
- 用 server link 从两个库联结数据更复杂。
- 联合需要更多的硬件和额外的复杂度。
分片

资料来源:可扩展性、可用性、稳定性、模式
分片将数据分配在不同的数据库上,使得每个数据库仅管理整个数据集的一个子集。以用户数据库为例,随着用户数量的增加,越来越多的分片会被添加到集群中。
类似联合的优点,分片可以减少读取和写入流量,减少复制并提高缓存命中率。也减少了索引,通常意味着查询更快,性能更好。如果一个分片出问题,其他的仍能运行,可以使用某种形式的冗余来防止数据丢失。类似联合,没有只能串行写入的中心化主库,可以并行写入,提高负载能力。
常见的做法是用户姓氏的首字母或者用户的地理位置来分隔用户表。
分片的缺点
- 需要修改应用程序的逻辑来实现分片,这会带来复杂的 SQL 查询。
- 分片不合理可能导致数据负载不均衡。例如,被频繁访问的用户数据会导致其所在分片的负载相对其他分片高。
- 再平衡会引入额外的复杂度。基于一致性哈希的分片算法可以减少这种情况。
- 联结多个分片的数据操作更复杂。
- 分片需要更多的硬件和额外的复杂度。
非规范化
非规范化试图以写入性能为代价来换取读取性能。在多个表中冗余数据副本,以避免高成本的联结操作。一些关系型数据库,比如 PostgreSQL 和 Oracle 支持物化视图,可以处理冗余信息存储和保证冗余副本一致。
当数据使用诸如联合和分片等技术被分割,进一步提高了处理跨数据中心的联结操作复杂度。非规范化可以规避这种复杂的联结操作。
在多数系统中,读取操作的频率远高于写入操作,比例可达到 100:1,甚至 1000:1。需要复杂的数据库联结的读取操作成本非常高,在磁盘操作上消耗了大量时间。
非规范化的缺点:
- 数据会冗余。
- 约束可以帮助冗余的信息副本保持同步,但这样会增加数据库设计的复杂度。
- 非规范化的数据库在高写入负载下性能可能比规范化的数据库差。
SQL 调优
SQL 调优是一个范围很广的话题,有很多相关的书可以作为参考。
利用基准测试和性能分析来模拟和发现系统瓶颈很重要。
- 基准测试 - 用 ab 等工具模拟高负载情况。
- 性能分析 - 通过启用如慢查询日志等工具来辅助追踪性能问题。
基准测试和性能分析可能会指引你到以下优化方案。
改进Schema
- 为了实现快速访问,MySQL 在磁盘上用连续的块存储数据。
- 使用
CHAR类型存储固定长度的字段,不要用VARCHAR。CHAR在快速、随机访问时效率很高。如果使用VARCHAR,如果你想读取下一个字符串,不得不先读取到当前字符串的末尾。
- 使用
TEXT类型存储大块的文本,例如博客正文。TEXT还允许布尔搜索。使用TEXT字段需要在磁盘上存储一个用于定位文本块的指针。 - 使用
INT类型存储高达 2^32 或 40 亿的较大数字。 - 使用
DECIMAL类型存储货币可以避免浮点数表示错误。 - 避免使用
BLOBS存储实际对象,而是用来存储存放对象的位置。 VARCHAR(255)是以 8 位数字存储的最大字符数,在某些关系型数据库中,最大限度地利用字节。- 在适用场景中设置
NOT NULL约束来提高搜索性能。
使用正确的index
- 你正查询(
SELECT、GROUP BY、ORDER BY、JOIN)的列如果用了索引会更快。 - 索引通常表示为自平衡的 B 树,可以保持数据有序,并允许在对数时间内进行搜索,顺序访问,插入,删除操作。
- 设置索引,会将数据存在内存中,占用了更多内存空间。
- 写入操作会变慢,因为索引需要被更新。
- 加载大量数据时,禁用索引再加载数据,然后重建索引,这样也许会更快。
避免高成本的join操作
- 有性能需要,可以进行非规范化。
分割数据表
- 将热点数据拆分到单独的数据表中,可以有助于缓存。
调优查询缓存
- 在某些情况下,查询缓存可能会导致性能问题。
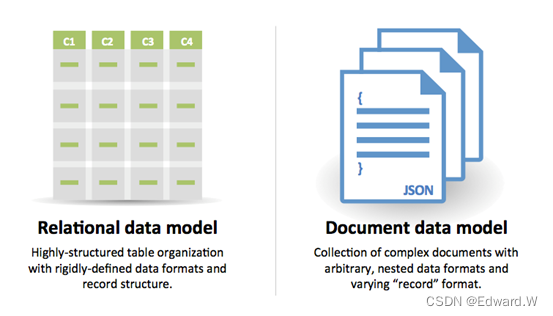
NoSQL
NoSQL 是键-值数据库、文档型数据库、列型数据库或图数据库的统称。数据库是非规范化的,表联结大多在应用程序代码中完成。大多数 NoSQL 无法实现真正符合 ACID 的事务,支持最终一致。
BASE 通常被用于描述 NoSQL 数据库的特性。相比 CAP 理论,BASE 强调可用性超过一致性。
- 基本可用 - 系统保证可用性。
- 软状态 - 即使没有输入,系统状态也可能随着时间变化。
- 最终一致性 - 经过一段时间之后,系统最终会变一致,因为系统在此期间没有收到任何输入。
举例说明BASE特性:
- 基本可用(Basic Availability):基本可用是指系统在面临网络分区、节点故障等异常情况时,仍然能够继续提供服务。例如,在这个电商系统中,当某个节点或网络出现故障时,系统可以将用户请求转发到其他正常的节点上,确保系统仍然可以正常运行。
- 软状态(Soft State):软状态是指系统在面临部分失败时,可以接受数据的不一致性。在 NOSQL 数据库中,通常不保证强一致性。以购物车信息为例,当系统在更新购物车信息时遇到网络分区或其他故障,可能导致部分节点上的购物车信息与另一部分节点上的信息不一致。但是,这种不一致性在一定时间内可以通过系统内部的机制进行修复。例如,通过异步复制、数据补偿等手段,使不同节点上的购物车信息最终达到一致状态。
- 最终一致性(Eventual Consistency):最终一致性是指系统在面临故障恢复后,可以保证数据的一致性。在 NOSQL 数据库中,通常采用乐观锁、版本号等机制来确保最终一致性。以购物车信息为例,当系统检测到购物车信息在不同节点上存在不一致时,可以通过乐观锁机制进行冲突检测,并选择一个优先级较高的版本作为最终结果。同时,系统还可以通过版本号来跟踪数据的变化,当发现数据不一致时,可以通过回滚机制将数据恢复到一致状态。
除了在 SQL 还是 NoSQL 之间做选择,了解哪种类型的 NoSQL 数据库最适合你的用例也是非常有帮助的。我们将在下一节中快速了解下 键-值存储、文档型存储、列型存储和图存储数据库。
键-值存储
抽象模型:哈希表
键-值存储通常可以实现 O(1) 时间读写,用内存或 SSD 存储数据。数据存储可以按字典顺序维护键,从而实现键的高效检索。键-值存储可以用于存储元数据。
键-值存储性能很高,通常用于存储简单数据模型或频繁修改的数据,如存放在内存中的缓存。键-值存储提供的操作有限,如果需要更多操作,复杂度将转嫁到应用程序层面。
键-值存储是如文档存储,在某些情况下,甚至是图存储等更复杂的存储系统的基础。
文档类型存储
抽象模型:将文档作为值的键-值存储
文档类型存储以文档(XML、JSON、二进制文件等)为中心,文档存储了指定对象的全部信息。文档存储根据文档自身的内部结构提供 API 或查询语句来实现查询。请注意,许多键-值存储数据库有用值存储元数据的特性,这也模糊了这两种存储类型的界限。
基于底层实现,文档可以根据集合、标签、元数据或者文件夹组织。尽管不同文档可以被组织在一起或者分成一组,但相互之间可能具有完全不同的字段。
MongoDB 和 CouchDB 等一些文档类型存储还提供了类似 SQL 语言的查询语句来实现复杂查询。DynamoDB 同时支持键-值存储和文档类型存储。
文档类型存储具备高度的灵活性,常用于处理偶尔变化的数据。
列型存储
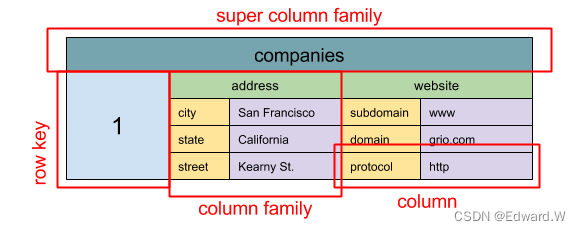
资料来源: SQL 和 NoSQL,一个简短的历史
抽象模型:嵌套的
ColumnFamily<RowKey, Columns<ColKey, Value, Timestamp>>映射
类型存储的基本数据单元是列(名/值对)。列可以在列族(类似于 SQL 的数据表)中被分组。超级列族再分组普通列族。你可以使用行键独立访问每一列,具有相同行键值的列组成一行。每个值都包含版本的时间戳用于解决版本冲突。
Google 发布了第一个列型存储数据库 Bigtable,它影响了 Hadoop 生态系统中活跃的开源数据库 HBase 和 Facebook 的 Cassandra。像 BigTable,HBase 和 Cassandra 这样的存储系统将键以字母顺序存储,可以高效地读取键列。
列型存储具备高可用性和高可扩展性。通常被用于大数据相关存储。
图数据库

资料来源:图数据库
抽象模型: 图
在图数据库中,一个节点对应一条记录,一个弧对应两个节点之间的关系。图数据库被优化用于表示外键繁多的复杂关系或多对多关系。
图数据库为存储复杂关系的数据模型,如社交网络,提供了很高的性能。它们相对较新,尚未广泛应用,查找开发工具或者资源相对较难。许多图只能通过 REST API 访问。
选择SQL还是NOSQL
选取 SQL 的原因:
- 结构化数据
- 严格的模式
- 关系型数据
- 需要复杂的联结操作
- 事务
- 清晰的扩展模式
- 既有资源更丰富:开发者、社区、代码库、工具等
- 通过索引进行查询非常快
选取 NoSQL 的原因:
- 半结构化数据
- 动态或灵活的模式
- 非关系型数据
- 不需要复杂的联结操作
- 存储 TB (甚至 PB)级别的数据
- 高数据密集的工作负载
- IOPS 高吞吐量
适合 NoSQL 的示例数据:
- 埋点数据和日志数据
- 排行榜或者得分数据
- 临时数据,如购物车
- 频繁访问的(“热”)表
- 元数据/查找表
额外参考:
- 数据结构和关系复杂度:如果数据具有复杂的结构和关系,例如涉及到多对多、一对多、一对多或多对多等关系,那么 SQL 数据库可能更适合您,因为 SQL 数据库在处理复杂关系和数据模式方面具有较强的能力。而 NOSQL 数据库通常适用于数据结构较为简单、关系不太复杂的场景。
- 数据读写性能要求:SQL 数据库在读取和写入数据时,通常需要遵循一定的事务处理和数据完整性规则,这可能会导致性能开销。如果您的系统对数据读写性能要求很高,可以考虑使用 NOSQL 数据库,因为它们通常具有更高的读写性能。但是,需要注意的是,NOSQL 数据库在数据一致性方面可能没有 SQL 数据库那么强。
- 数据规模:当数据规模较大时,NOSQL 数据库通常具有更好的横向扩展能力,可以应对海量数据的存储和查询。而 SQL 数据库在处理大规模数据时,可能需要更多的硬件资源和优化策略。因此,在数据规模较大的场景下,可以考虑使用 NOSQL 数据库。
- 数据一致性和事务处理:如果您的系统对数据一致性和事务处理有较高的要求,那么 SQL 数据库可能更适合您。因为 SQL 数据库遵循 ACID(原子性、一致性、隔离性、持久性)原则,能够确保数据的完整性和事务的完整执行。而 NOSQL 数据库通常遵循 BASE(基本可用、软状态、最终一致性)原则,对数据一致性的要求相对较低。
- 系统灵活性和可扩展性:NOSQL 数据库通常具有更高的灵活性和可扩展性,可以更好地适应不断变化的业务需求。而 SQL 数据库通常需要预先定义好数据结构和关系,可能在应对需求变化时较为困难。