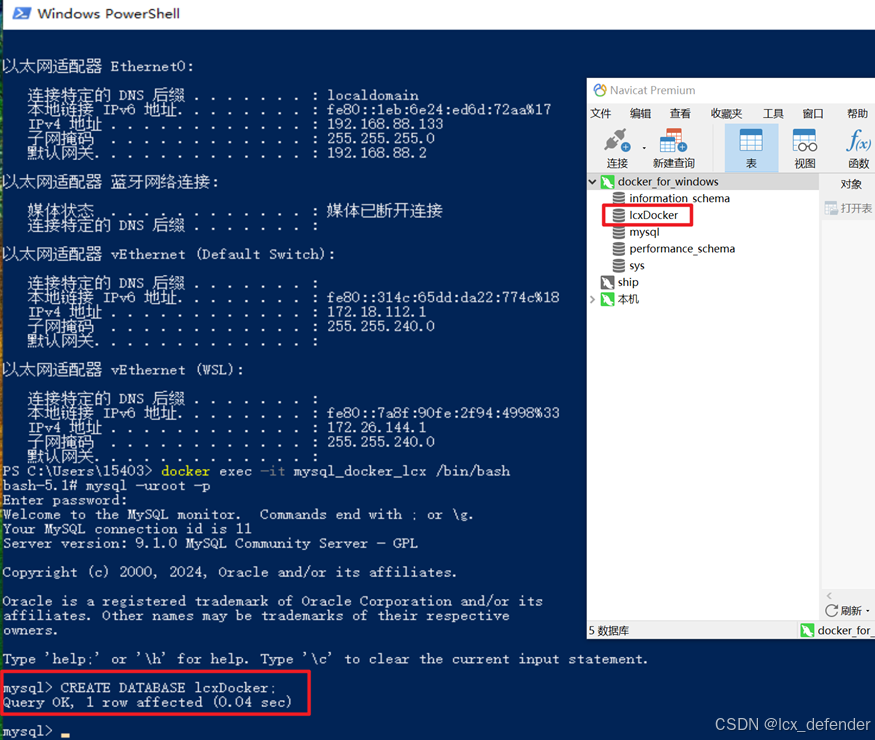
关于docker,Windows上使用Powershell/CMD执行指令,Linux系统直接使用终端执行指令。
docker安装MySQL
拉取MySQL
也可以跳过拉取步骤,直接run,这样本地容器不存在的话,会自动拉取最新/指定的版本。
# 默认拉取最新版本
docker pull mysql
# 拉取指定版本MySQL
docker pull mysql:5.7
安装MySQL
# 这里 \ 是用作换行,实际情况下如果放在一行去写,就可以删掉\
# CentOs上"\"会被识别为换行,Windows上建议把"\"删掉
# [:自己想要的版本]如果是想要拉取最新的版本,可缺省
docker run --name mysql_docker \
--restart=always \
--privileged=true \
-p 3306:3306 \
-e TZ=Asia/Shanghai \
-e MYSQL_ROOT_PASSWORD=lcx108642 \
-e MYSQL_ROOT_HOST=% \
-v /usr/local/mysql/log:/var/log/mysql \
-v /usr/local/mysql/data:/var/lib/mysql \
-v /usr/local/mysql/conf:/etc/mysql/conf \
-v /etc/localtime:/etc/localtime:ro \
-d \
mysql [:自己想要的版本]
docker run:这是 Docker 的命令,用于创建并启动一个新的容器。--name mysql_docker_lcx:为容器指定一个名称,这里名称为mysql_docker_lcx。--restart=always:设置容器的重启策略为always,意味着无论容器因为什么原因退出,Docker 都会自动重启它。--privileged=true:给予容器额外的权限,使其能够访问宿主机的所有设备,并且有能力执行一些需要高级权限的操作。-p 3306:3306:将容器内部的 3306 端口映射到宿主机的 3306 端口,这样可以通过宿主机的 3306 端口访问 MySQL 服务。-e TZ=Asia/Shanghai \:设置mysql服务的时区。-e MYSQL_ROOT_PASSWORD=123456:设置环境变量,指定 MySQL 的 root 用户密码为123456。-e MYSQL_ROOT_HOST=%:设置环境变量,指定 MySQL 的 root 用户允许从任何主机连接。-v /usr/local/mysql/log:/var/log/mysql:挂载宿主机的/usr/local/mysql/log目录到容器的/var/log/mysql目录,用于持久化 MySQL 的日志文件。-v /usr/local/mysql/data:/var/lib/mysql:挂载宿主机的/usr/local/mysql/data目录到容器的/var/lib/mysql目录,用于持久化 MySQL 的数据文件。-v /usr/local/mysql/conf:/etc/mysql/conf:挂载宿主机的/usr/local/mysql/conf目录到容器的/etc/mysql/conf目录,用于持久化 MySQL 的配置文件。-v /etc/localtime:/etc/localtime:ro:挂载宿主机的/etc/localtime文件到容器的/etc/localtime文件,用于同步宿主机的时间设置,ro表示以只读方式挂载。-d:以分离模式(后台模式)运行容器mysql是 Docker Hub 上的官方 MySQL 镜像名称,[:自己指定的版本]为可选项,不包含这个部分默认最新版本。


远程连接MySQL
主机为docker所部署在的虚拟机/服务器的IP地址,密码是mysql服务的密码,端口一般都是默认3306。

Docker安装RabbitMQ
执行如下指令
docker run \
-e RABBITMQ_DEFAULT_USER=root \
-e RABITTMQ_DEFAULT_PASS=123456 \
-v mq-plugins:/plugins \
--name mq \
--hostname mq \
-p 15672:15672 \
-p 5672:5672 \
-d \
rabbitmq[:自己指定版本,缺省为最新]
示例:
docker run \
-e RABBITMQ_DEFAULT_USER=root \
-e RABITTMQ_DEFAULT_PASS=123456 \
-v mq-plugins:/plugins \
--name mq \
--hostname mq \
-p 15672:15672 \
-p 5672:5672 \
-d \
rabbitmq:3.8
-e RABBITMQ_DEFAULT_USER=root:设置环境变量 RABBITMQ_DEFAULT_USER,值为 root。这是 RabbitMQ 的默认用户名,用于登录管理界面或连接到 RabbitMQ 服务器。
-e RABITTMQ_DEFAULT_PASS=123456:设置环境变量 RABITTMQ_DEFAULT_PASS,值为 123456。这是 RabbitMQ 的默认密码,用于登录管理界面或连接到 RabbitMQ 服务器。注意这里有一个拼写错误,应该是 RABBITMQ_DEFAULT_PASS。
-v mq-plugins:/plugins:将 Docker 宿主机上的一个名为 mq-plugins 的卷(volume)挂载到容器的 /plugins 目录。这样可以将自定义的插件放置在这个卷中,RabbitMQ 容器启动时会加载这些插件。
–name mq:为容器指定一个名称,这里指定为 mq。使用这个名称可以在后续的 Docker 命令中方便地引用这个容器。
–hostname mq:设置容器的主机名(hostname)为 mq。这个名称在容器内部的网络通信中会用到。
-p 15672:15672:将容器的 15672 端口映射到宿主机的 15672 端口。RabbitMQ 的管理界面默认使用 15672 端口,这样可以从宿主机访问 RabbitMQ 的管理界面。
-p 5672:5672:将容器的 5672 端口映射到宿主机的 5672 端口。RabbitMQ 的 AMQP 通信默认使用 5672 端口,这样宿主机上的应用程序可以通过这个端口与 RabbitMQ 通信。
-d:以“分离模式”(detached mode)运行容器,即在后台运行容器,不会占用当前的命令行界面。
rabbitmq[:自己指定版本,缺省为最新]:指定要运行的 Docker 镜像名称,这里为 rabbitmq。可以在方括号中指定版本号,如果不指定版本号,则默认使用最新版本的 RabbitMQ 镜像。
开启web管理
# 终端输入指令进入容器,mq替换成自己RabbitMQ容器名称
docker exec -it mq bash
# 执行指令启用
rabbitmq-plugins enable rabbitmq_management
# 查看当前mq的管理账号

打开浏览器,登录管理页面
# xxx.xxx.xxx.xxx换成自己服务器或虚拟机的IP地址
xxx.xxx.xxx.xxx:15672
# 对应下方Username和Password
# RABBITMQ_DEFAULT_USER=root
# RABITTMQ_DEFAULT_PASS=123456

可能存在的问题
1.无法打开管理页面:
尝试执行下列操作
# 终端输入指令进入容器,mq替换成自己RabbitMQ容器名称
docker exec -it mq bash
# 执行指令启用管理
rabbitmq-plugins enable rabbitmq_management
2.无登录用户或显示Not_Authorized
# 查看当前mq的管理账号
rabbitmqctl list_users
# 如果没有则添加用户username并设置密码password
rabbitmqctl add_user username password
# 设置指定用户(username替换自己的用户)为管理员
rabbitmqctl set_user_tags lcx_defender administrator
rabbitmqctl set_permissions -p / lcx_defender ".*" ".*" ".*"