简介
在实际的生产中,为了解决Mysql的单点故障已经提高MySQL的整体服务性能,一般都会采用「主从复制」。
主从复制开始前有个前提条件:两边的数据要一样,主必须开启二进制日志
dump thread 线程
基于位置点
从是否需要开启二进制日志?
不需要
IO线程是如何知道从二进制日志的那个位置开始读取二进制日志?
master.info会记录上次IO线程已经读取到了master的二进制日志什么位置 --》会记录一个编号和二进制文件的名字
SQL线程如何知道从中间日志那个位置开始读取中继日志?
relay-log.info 记载着上次执行到的位置
master是否会允许任何一台机器过来同步?
需要授权
mysql> CREATE USER 'repl'@'%.example.com' IDENTIFIED BY 'password';
mysql> GRANT REPLICATION SLAVE ON *.* TO 'repl'@'%.example.com';
原理
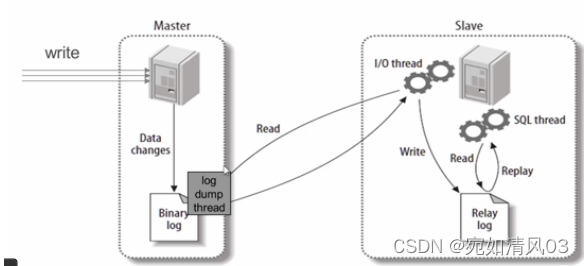
1.首先在master上开启二进制日志
2.master上数据发生变化,进行DML操作的时候,会产生二进制日志
3.master上的dump线程会通知slave上的IO线程来拿二进制日志,IO线程拿到二进制日志后会写入到slave上的中继日志,然后SQL线程会去读取新产生的中继日志,重演二进制日志里的操作,从而达到slave和master上的数据一模一样,实现数据的一致性。
作用
高可用;负载均衡;备份
模式
异步
常见的主从复制
缺点:有延迟,会丢失数据
半同步
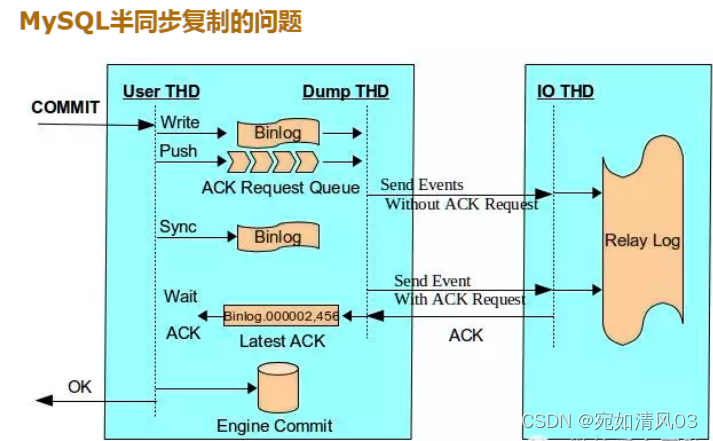
半同步主从复制,salve会返回一个ack确认包给master,比异步主从复制多了这一步骤。
如果ack确认包在10秒钟内没有送达,master会启用异步模式
同步
组复制
参考:https://www.cnblogs.com/kevingrace/p/10260685.html
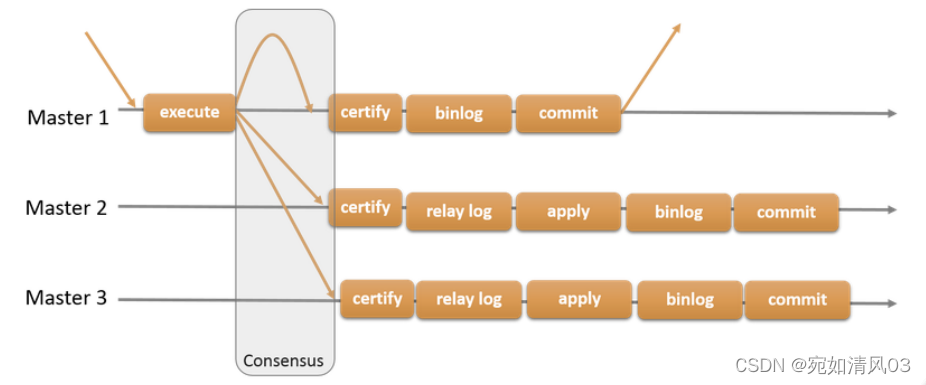
组复制是MySQL5.7版本出现的新特性,它提供了高可用、高扩展、高可靠的MySQL集群服务。MySQL组复制分单主模式和多主模式,mysql 的复制技术仅解决了数据同步的问题,如果 master 宕机,意味着数据库管理员需要介入,应用系统可能需要修改数据库连接地址或者重启才能实现。(这里也可以使用数据库中间件产品来避免应用系统数据库连接的问题,例如 mycat 和 atlas 等产品)。组复制在数据库层面上做到了,只要集群中大多数主机可用,则服务可用,也就是说3台服务器的集群,允许其中1台宕机。
组复制的两种模式
- 在单主模式下, 组复制具有自动选主功能,每次只有一个 server成员接受更新;
- 在多主模式下, 所有的 server 成员都可以同时接受更新;


最低3台,最多9台
组复制原理
组由多个服务器构成,通过传递消息进行交互,通信层保证原子消息传递。MGR构建于此通信层抽象之上,并实现了多主更新复制协议。组中的每个服务器独立地执行事务,但是所有读写事务只有在得到组的批准后才会提交。只读事务在组内不需要协调,因此立即提交。对于任何读写事务,当事务准备好在始发服务器处提交时,服务器以原子方式广播写入值(更改的行)和对应的写入集(更新的行的唯一标识符),然后将该事务加入全局事务列表。最终所有服务器都以相同的顺序接收并应用相同的事务集,所以它们在组内保持一致。
多实例
mysql多实例,简单理解就是在一台服务器上,mysql服务开启多个不同的端口(如3306、3307),运行多个服务进程。这些 mysql 服务进程通过不同的 socket来监听不同的数据端口,进而互不干涉的提供各自的服务。
多实例:就是多个运行起来的mysqld进程,每个进程里运行自己的库,各自为各自的库提供服务。
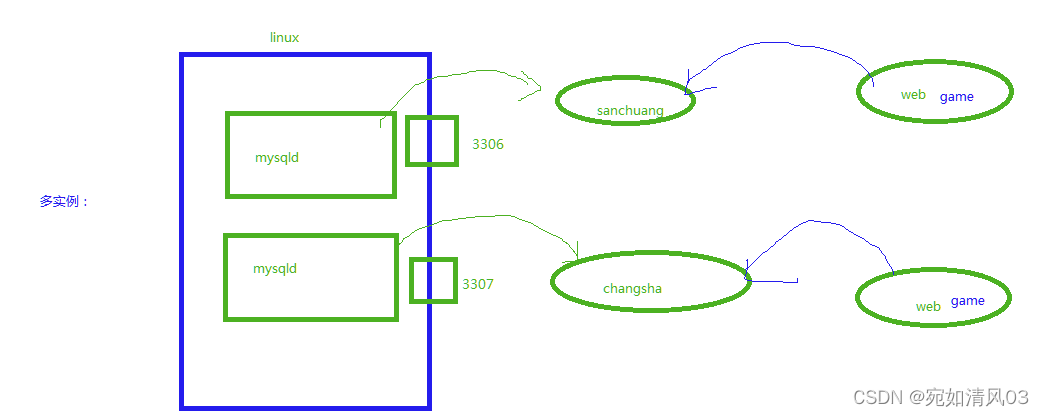
一个实例就是运行一个mysqld的进程
优点:数据分开,不相互影响,省钱
缺点:共用一台linux系统,资源会存在竞争关系
架构
主主复制
参考:https://blog.csdn.net/kk185800961/article/details/51103400
https://www.jianshu.com/p/469279c1ad39
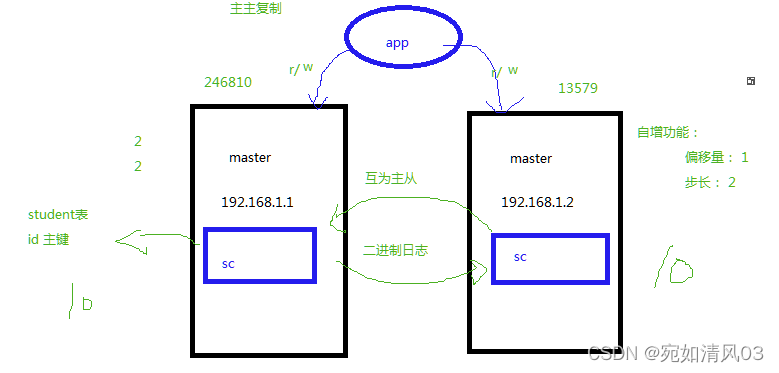
互为主从,相互同步
避免数据冗余
2台主机都是master,业务数据同时往2台机器上写,机器的使用率会提升
给写入的表设置不同的起始值相同的偏移量
若主主双方都操作,最好设置auto-increment-offset 和 auto-increment-increment,以避免冲突。若只在其中一个库操作,可不需要设置
一主多从,再级联
但是当我们需要实现级联同步时,即以这样的一个模式,A>B>C实现三级同步时,AB库除了需要设置log-bin参数还需要添加一个参数:log-slave-updates
log-slave-updates参数默认时关闭的状态,如果不手动设置,那么bin-log只会记录直接在该库上执行的SQL语句,由replication机制的SQL线程读取relay-log而执行的SQL语句并不会记录到bin-log,那么就无法实现上述的三级级联同步。
开启二进制日记
GTID的主从复制
参考:https://blog.51cto.com/u_13434336/2178937
https://blog.csdn.net/wzy0623/article/details/91047395
什么是GTID?
全局事务标识符GTID的全称为Global Transaction Identifier,是在整个复制环境中对一个事务的唯一标识。它是MySQL 5.6加入的一个强大特性,目的在于能够实现主从自动定位和切换,而不像以前需要指定文件和位置。使用GTID复制时,主库上提交事务时创建事务对应的GTID,从库在应用中继日志时用GTID识别和跟踪每个事务。在启动新从库或因故障转移到新主库时可以使用GTID来标识复制的位置,极大地简化了这些任务。由于GTID的复制完全基于事务,因此只要在主库上提交的所有事务也在从库上提交,两者之间的一致性就得到保证。GTID支持基于语句或基于行的复制格式,但为了获得最佳效果,MySQL建议使用基于行的格式。GTID始终保留在主库和从库上,这意味着可以通过检查其二进制日志来确定应用于任何从库的任何事务的来源。而且,一旦在给定库上提交了具有给定GTID的事务,则该库将忽略具有相同GTID的任何后续事务。因此,在主库上提交的事务只会在从库上应用一次,这也有助于保证一致性。
1、全局唯一,一个事务对应一个GTID
2、替代传统的binlog+pos复制;使用master_auto_position=1自动匹配GTID断点进行复制
3、MySQL5.6开始支持
4、在传统的主从复制中,slave端不用开启binlog;但是在GTID主从复制中,必须开启binlog
5、slave端在接受master的binlog时,会校验GTID值
6、为了保证主从数据的一致性,多线程同时执行一个GTID
优点:
1.可以很方便的进行故障转移,记录master最后事务的GTID值。比如master:A,slave:B,C。当A挂了后,B执行了所有A传过来的事务。当C连接到B后,在自己的binlog找到最后一次A传过来的GTID。然后C将这个GTID发送给B,B获取到这个GTID,就开始从这个GTID的下一个GTID开始发送事务给C。这种自我寻找复制位置的模式减少事务丢失的可能性以及故障恢复的时间。
2.slave不会丢失master的任何修改(开启了log_slave_updates)
缺点:
1.备份时更加麻烦,需要额外加一个参数 --set-gtid=on
2.主从复制出现错误,没有办法跳过错误
延迟备份
可以快速的恢复数据
比使用全备+二进制日志恢复更加快些