开局一张图,其他全靠吹
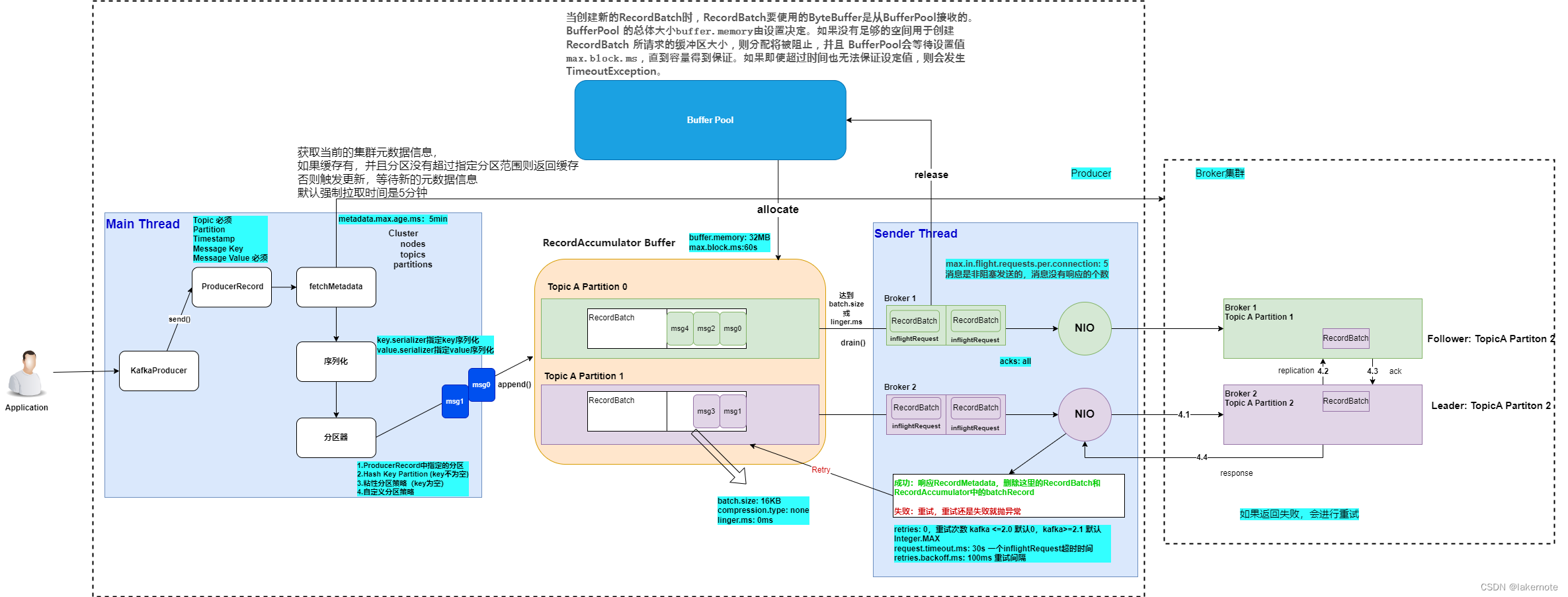
发送消息流程如下:
1.初始化流程
-
指定bootstrap.servers,地址的格式为
host:port。它会连接bootstrap.servers参数指定的所有Broker,Producer启动时会发起与这些Broker的连接。因此,如果你为这个参数指定了1000个Broker连接信息,那么很遗憾,你的Producer启动时会首先创建与这1000个Broker的TCP连接。- 在实际使用过程中,我并不建议把集群中所有的Broker信息都配置到bootstrap.servers中,通常你指定3~4台就足以了。因为Producer一旦连接到集群中的任一台Broker,就能拿到整个集群的Broker信息,故没必要为bootstrap.servers指定所有的Broker。
props.put("bootstrap.servers", "localhost:9092");
-
指定Key和Value的序列化方式。
-
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
-
-
指定acks配置,默认值是all(版本3.x)
props.put("acks", "all");- 设置为0,表示生产端发送消息后立即返回,不等待broker端的响应结果。通常此时生产端吞吐量最高,消息发送的可靠性最低。
- 设置为1,表示leader副本成功写入PageCache就会响应Producer,而无需等待ISR(同步副本)集合中的其他副本写入成功。这种方案提供了适当的持久性,保证了一定的吞吐量。
- 设置成all或-1,表示不仅要等leader副本成功写入,还要求ISR中的其他副本成功写入,才会响应Producer。这种方案提供了最高的持久性,但也提供了最差的吞吐量。
-
producer = new KafkaProducer<>(props);- 从配置中获取必要的参数,如
transactionalId和clientId。 - 根据
clientId创建日志记录上下文(LogContext),用于日志记录。 - 配置度量(Metrics)相关信息,包括度量标签、度量配置、度量报告器等。
- 创建度量上下文(MetricsContext)和度量实例(Metrics)。
- 初始化分区器(Partitioner)。
- 配置并初始化键(key)和值(value)的序列化器(Serializer)。
- 配置并初始化拦截器(Interceptors)。
- 配置集群资源监听器(ClusterResourceListeners)。
- 设置最大请求大小(maxRequestSize)、内存大小(totalMemorySize)和压缩类型(compressionType)等参数。
- 配置最大阻塞时间(maxBlockTimeMs)和交付超时时间(deliveryTimeoutMs)。
- 初始化API版本(apiVersions)和事务管理器(transactionManager)。
- 创建记录累加器(RecordAccumulator),用于累积记录以进行批量发送。
- 解析并验证引导服务器地址(addresses)。
- 如果提供了元数据(metadata),则使用提供的元数据,否则创建新的元数据实例,并通过引导服务器地址进行引导。
- 初始化错误度量传感器(errors)。
- 创建并启动IO线程(ioThread)来处理消息发送。
- 注册应用程序信息,用于JMX度量和监控。
- 如果在初始化过程中发生任何错误,将调用关闭方法以避免资源泄漏,并向上抛出Kafka异常。
- 从配置中获取必要的参数,如
2.发送消息流程
在消息发送的过程中,涉及到了两个线程——
main线程和Sender线程。在main线程中创建了一个双端队列RecordAccumulator。main线程将消息发送给RecordAccumulator,Sender线程不断从RecordAccumulator中拉取消息发送到Kafka Broker。
- 构造消息记录ProducerRecord 对象,对象包含了四个属性:Topic,partition,key,value;topic 和 value 是必须的,key 和 partition 是可选的。
- 同步获取Kafka集群信息(Cluster)。
- 如果缓存有,并且分区没有超过指定分区范围则返回缓存
- 否则触发更新,等待从broker获取新的元数据信息
- 默认强制拉取时间是metadata.max.age.ms: 5分钟
- 使用键序列化器(keySerializer)将消息的键序列化为字节数组,使用值序列化器(valueSerializer)将消息的值序列化为字节数组。
- 计算数据发送到那个分区,如果指定了 key,那么相同 key 的消息会发往同一个分区,如果实现了自定义分区器,那么就会走自定义分区器进行分区路由。
- 如果有Key值,则使用Key值的Hash值来分配分区
murmurhash(key) % 主题分区总数。 - 老版本:如果没有key值,则以Round-Robin的方式分配分区。
- 新版本:如果没有key值,则以粘性分区的方式分配分区
- 如果有Key值,则使用Key值的Hash值来分配分区
- 创建一个
TopicPartition对象,表示要发送消息的主题和分区。 - 判断消息的大小是否超过了我们设置的阈值。
- 异步发送时,给每一条消息都绑定他的回调函数
- 把消息放入记录累加器(accumulator)(32M的一个内存)*,*然后有accumulator把消息封装成为一个批次一个批次的去发送。
- 如果批次满了或者新创建出来一个批次, 唤醒sender线程,他才是真正发送数据的线程,发送的时候并不是来一个消息就发送一个消息,这样的话吞吐量比较低,并且频繁的进行网络请求。消息是按照批次来发送的或者等待时间来发的的.
参考
- https://www.clairvoyant.ai/blog/unleash-kafka-producers-architecture-and-internal-workings
- 尚硅谷 Kafka