一、tf.keras
tf.keras是TensorFlow 2.0的高阶API接口,为TensorFlow的代码提供了新的风格和设计模式,大大提升了TF代码的简洁性和复用性,官方也推荐使用tf.keras来进行模型设计和开发。

1.1 tf.keras中常用模块
如下表所示:

1.2 常用方法
深度学习实现的主要流程:
1.数据获取,
2 数据处理,
3 模型创建与训练,
4 模型测试与评估,
5.模型预测
导入tf.keras
使用 tf.keras,首先需要在代码开始时导入tf.keras
import tensorflow as tf
from tensorflow import keras数据输入
对于小的数据集,可以直接使用numpy格式的数据进行训练、评估模型,对于大型数据集或者要进行跨设备训练时使用tf.data.datasets来进行数据输入。
模型构建
- 简单模型使用Sequential进行构建
- 复杂模型使用函数式编程来构建
- 自定义layers
训练与评估
- 配置训练过程
# 配置优化方法,损失函数和评价指标
model.compile(optimizer=tf.train.AdamOptimizer(0.001),loss='categorical_crossentropy',metrics=['accuracy'])- 模型训练
# 指明训练数据集,训练epoch,批次大小和验证集数据
model.fit/fit_generator(dataset, epochs=10, batch_size=3,validation_data=val_dataset,)- 模型评估
# 指明评估数据集和批次大小
model.evaluate(x, y, batch_size=32)- 模型预测
# 对新的样本进行预测
model.predict(x, batch_size=32)回调函数(callbacks)
回调函数用在模型训练过程中,来控制模型训练行为,可以自定义回调函数,也可使用tf.keras.callbacks 内置的 callback :
ModelCheckpoint:定期保存 checkpoints。 LearningRateScheduler:动态改变学习速率。 EarlyStopping:当验证集上的性能不再提高时,终止训练。 TensorBoard:使用 TensorBoard 监测模型的状态。
模型的保存和恢复
- 只保存参数
# 只保存模型的权重
model.save_weights('./my_model')
# 加载模型的权重
model.load_weights('my_model')- 保存整个模型
# 保存模型架构与权重在h5文件中
model.save('my_model.h5')
# 加载模型:包括架构和对应的权重
model = keras.models.load_model('my_model.h5')二、keras构建模型

2.1 相关的库的导入
在这里使用sklearn和tf.keras完成鸢尾花分类,导入相关的工具包:
# 绘图
import seaborn as sns
# 数值计算
import numpy as np
# sklearn中的相关工具
# 划分训练集和测试集
from sklearn.model_selection import train_test_split
# 逻辑回归
from sklearn.linear_model import LogisticRegressionCV
# tf.keras中使用的相关工具
# 用于模型搭建
from tensorflow.keras.models import Sequential
# 构建模型的层和激活方法
from tensorflow.keras.layers import Dense, Activation
# 数据处理的辅助工具
from tensorflow.keras import utils
2.2 数据展示和划分
利用seborn导入相关的数据,iris数据以dataFrame的方式在seaborn进行存储,我们读取后并进行展示;
将数据划分为训练集和测试集:从iris dataframe中提取原始数据,将花瓣和萼片数据保存在数组X中,标签保存在相应的数组y中;
# 读取数据
iris = sns.load_dataset("iris")
# 展示数据的前五行
iris.head()# 花瓣和花萼的数据
X = iris.values[:, :4]
# 标签值
y = iris.values[:, 4]# 将数据集划分为训练集和测试集
train_X, test_X, train_y, test_y = train_test_split(X, y, train_size=0.5, test_size=0.5, random_state=0)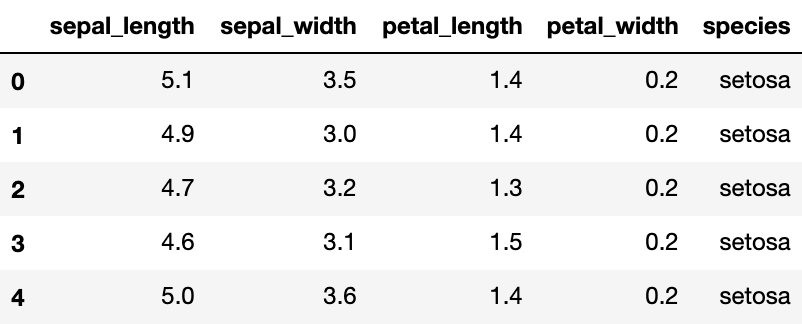
另外,利用seaborn中pairplot函数探索数据特征间的关系:
# 将数据之间的关系进行可视化
sns.pairplot(iris, hue='species')
2.3 sklearn实现
利用逻辑回归的分类器,并使用交叉验证的方法来选择最优的超参数,实例化LogisticRegressionCV分类器,并使用fit方法进行训练:
# 实例化分类器
lr = LogisticRegressionCV()
# 训练
lr.fit(train_X, train_y)# 计算准确率并进行打印
print("Accuracy = {:.2f}".format(lr.score(test_X, test_y)))Accuracy = 0.932.4 tf.keras实现
数据准备
在sklearn中我们只要实例化分类器并利用fit方法进行训练,最后衡量它的性能就可以了,那在tf.keras中与在sklearn非常相似,不同的是:
- 构建分类器时需要进行模型搭建
- 数据采集时,sklearn可以接收字符串型的标签,如:“setosa”,但是在tf.keras中需要对标签值进行热编码,如下所示:

有很多方法可以实现热编码,比如pandas中的get_dummies(),在这里我们使用tf.keras中的方法进行热编码:
# 进行热编码
def one_hot_encode_object_array(arr):# 去重获取全部的类别uniques, ids = np.unique(arr, return_inverse=True)# 返回热编码的结果return utils.to_categorical(ids, len(uniques))#对标签值进行热编码
# 训练集热编码
train_y_ohe = one_hot_encode_object_array(train_y)
# 测试集热编码
test_y_ohe = one_hot_encode_object_array(test_y)
模型搭建
在sklearn中,模型都是现成的。tf.Keras是一个神经网络库,我们需要根据数据和标签值构建神经网络。
神经网络可以发现特征与标签之间的复杂关系。
神经网络是一个高度结构化的图,其中包含一个或多个隐藏层。
每个隐藏层都包含一个或多个神经元。
神经网络有多种类别,该程序使用的是密集型神经网络,也称为全连接神经网络:一个层中的神经元将从上一层中的每个神经元获取输入连接。例如,图 2 显示了一个密集型神经网络,其中包含 1 个输入层、2 个隐藏层以及 1 个输出层,如下图所示:
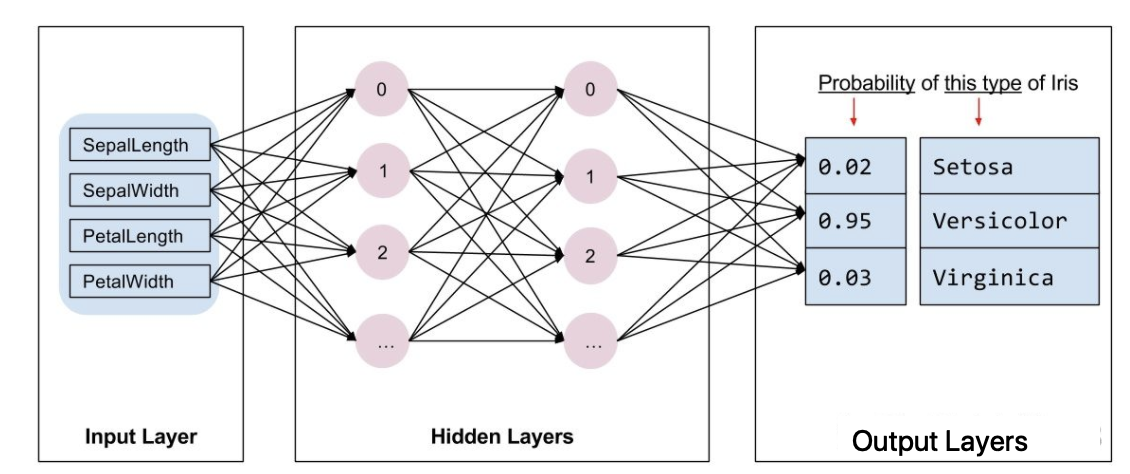
上图 中的模型经过训练并馈送未标记的样本时,它会产生 3 个预测结果:相应鸢尾花属于指定品种的可能性。对于该示例,输出预测结果的总和是 1.0。该预测结果分解如下:山鸢尾为 0.02,变色鸢尾为 0.95,维吉尼亚鸢尾为 0.03。这意味着该模型预测某个无标签鸢尾花样本是变色鸢尾的概率为 95%。
TensorFlow tf.keras API 是创建模型和层的首选方式。通过该 API,您可以轻松地构建模型并进行实验,而将所有部分连接在一起的复杂工作则由 Keras 处理。
tf.keras.Sequential 模型是层的线性堆叠。该模型的构造函数会采用一系列层实例;在本示例中,采用的是 2 个密集层(分别包含 10 个节点)以及 1 个输出层(包含 3 个代表标签预测的节点)。第一个层的 input_shape 参数对应该数据集中的特征数量:
# 利用sequential方式构建模型
model = Sequential([# 隐藏层1,激活函数是relu,输入大小有input_shape指定Dense(10, activation="relu", input_shape=(4,)), # 隐藏层2,激活函数是reluDense(10, activation="relu"),# 输出层Dense(3,activation="softmax")
])通过model.summary可以查看模型的架构:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 10) 50
_________________________________________________________________
dense_1 (Dense) (None, 10) 110
_________________________________________________________________
dense_2 (Dense) (None, 3) 33
=================================================================
Total params: 193
Trainable params: 193
Non-trainable params: 0
_________________________________________________________________ 激活函数可决定层中每个节点的输出形状。这些非线性关系很重要,如果没有它们,模型将等同于单个层。激活函数有很多,但隐藏层通常使用 ReLU。
隐藏层和神经元的理想数量取决于问题和数据集。与机器学习的多个方面一样,选择最佳的神经网络形状需要一定的知识水平和实验基础。一般来说,增加隐藏层和神经元的数量通常会产生更强大的模型,而这需要更多数据才能有效地进行训练。
模型训练和预测
在训练和评估阶段,我们都需要计算模型的损失。这样可以衡量模型的预测结果与预期标签有多大偏差,也就是说,模型的效果有多差。我们希望尽可能减小或优化这个值,所以我们设置优化策略和损失函数,以及模型精度的计算方法:
# 设置模型的相关参数:优化器,损失函数和评价指标
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=["accuracy"])接下来与在sklearn中相同,分别调用fit和predict方法进行预测即可。
# 模型训练:epochs,训练样本送入到网络中的次数,batch_size:每次训练的送入到网络中的样本个数
model.fit(train_X, train_y_ohe, epochs=10, batch_size=1, verbose=1);
- 迭代每个epoch。通过一次数据集即为一个epoch。
- 在一个epoch中,遍历训练 Dataset 中的每个样本,并获取样本的特征 (x) 和标签 (y)。
- 根据样本的特征进行预测,并比较预测结果和标签。衡量预测结果的不准确性,并使用所得的值计算模型的损失和梯度。
- 使用 optimizer 更新模型的变量。
- 对每个epoch重复执行以上步骤,直到模型训练完成。
与sklearn中不同,对训练好的模型进行评估时,与sklearn.score方法对应的是tf.keras.evaluate()方法,返回的是损失函数和在compile模型时要求的指标:
# 计算模型的损失和准确率
loss, accuracy = model.evaluate(test_X, test_y_ohe, verbose=1)
print("Accuracy = {:.2f}".format(accuracy))