0. 需求
周末给孩子买了一本教辅书,书上有配套的音频文件,可以通过微信扫描播放,但是平时孩子在家没有手机,怎么办呢?家中领导要求把它下载下了,放到蓝牙音箱上,那么说干就干。
1. 页面分析
音频的页面是一个播放器,网址是:
https://www.*************.cn/erweima/player.html?bqcg_id=2375,bqcg_id是对应不同的章节重2375-2399。每个章节分别有两个音频。|
通过网站代码分析,找到了mp3文件的地址:
https://h*******de1.*********.aliyuncs.com/wapaudio/61010/1-1.mp3
看网址,音频资源是放到阿里云盘中,本来想着直接在直接从这个地址上下载就行,但是当输入这个地址时,显示:

显然,这是阿里不想让你直接下。
那么我们可不可以让python模拟一个浏览器,把需要的文件下到本地呢?
答案当然是可以的。这就相当于一个爬虫嘛!
爬虫,我还是比较熟悉的,前几天才刚刚学习了爬虫和刑法的关系:
但是,还是可以试试这个技术行不行,特别是只是对爬虫有了解,编写代码能力一般的人,如何利用ChatGPT写一个代码,解决这个平时生活中可能遇到的小小问题。
2. 代码实现
这次选择一个国内套壳的ChatGPT来实现,版本3.5
提出需求:
你好,你是一位python程序员,帮我编写脚本,从网站上批量下载文件
网页的地址是: https://www.********.cn/erweima/player.html?bqcg_id={ID}
其中{ID}取值从2375到2399 每个页面中有两个mp3文件,文件地址为:
https://hld******e1.o**************ai.aliyuncs.com/wapaudio/61010/{编号}-1.mp3
https://hld******e1.o**************ai.aliyuncs.com/wapaudio/61010/{编号}-2.mp3
其中{编号}取值为从1到25
也就是{ID}取值为2375时,{编号}取值为1
{ID}取值为2376时,{编号}取值为2 依次类推
现在请你编写脚本,将所有的文件下载到一个文件夹中。
每个文件下载间隔10秒。
很快,ChatGPT给出了答案:
好的,我已经了解你的需求了。请尝试以下代码:
import requestsimport time# 设置请求头部,避免被防火墙拦截HEADERS = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}# 文件下载保存路径FILE_PATH = "downloaded_files"def download_mp3_file(url, file_name):"""下载MP3文件:param url: MP3文件地址:param file_name: 文件名:return:"""# 发送 GET 请求并下载文件response = requests.get(url, headers=HEADERS)if response.status_code == 200:with open(file_name, 'wb') as f:f.write(response.content)print(f"成功下载文件:{file_name}")else:print(f"下载文件失败:{file_name}")if __name__ == '__main__':for id in range(2375, 2400):for num in range(1, 26):# 构造文件地址mp3_url_1 = f"https://hld******e1.o**************ai.aliyuncs.com/wapaudio/61010/{num}-1.mp3"mp3_url_2 = f"https://hld******e1.o**************ai.aliyuncs.com/wapaudio/61010/{num}-2.mp3"# 构造文件名file_name_1 = f"{FILE_PATH}/{id}_{num}_1.mp3"file_name_2 = f"{FILE_PATH}/{id}_{num}_2.mp3"# 下载两个MP3文件,进程睡眠10秒download_mp3_file(mp3_url_1, file_name_1)download_mp3_file(mp3_url_2, file_name_2)time.sleep(10)脚本中,我使用requests库来发送 GET 请求并下载文件,然后使用time库让进程休眠10秒钟,避免请求频繁被防火墙拦截。
此外,我采用了f-string技术来构造文件地址和文件名。你可以将代码拷贝到本地,并将文件保存为mp3_downloader.py,使用Python解释器运行即可。在运行过程中,请确保当前目录下存在一个名为downloaded_files的文件夹,因为所有下载的文件都会被保存在这个文件夹里面。
很显然是不行,下载失败:
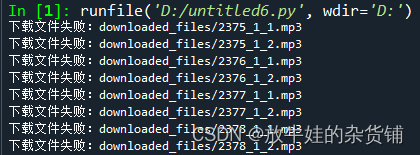
给ChatGPT提醒:
下载失败,因为当访问链接:https://hld******e1.o**************ai.aliyuncs.com/wapaudio/61010/1-1.mp3时,浏览器返回:
This XML file does not appear to have any style information associated with it. The document tree is shown below.
<Error>
<Code>AccessDenied</Code>
<Message>You are denied by bucket referer policy.</Message>
<RequestId>646AC95511D2913233E98BCC</RequestId>
<HostId>hld******e1.o**************ai.aliyuncs.com</HostId>
<BucketName>hld******e1</BucketName>
<EC>0003-00000501</EC>
</Error>
ChatGPT:
这个错误提示是由于阿里云的反爬虫机制对你的请求进行了拦截。如果服务器检测到你的请求头不符合其规则,就会返回这个错误信息。
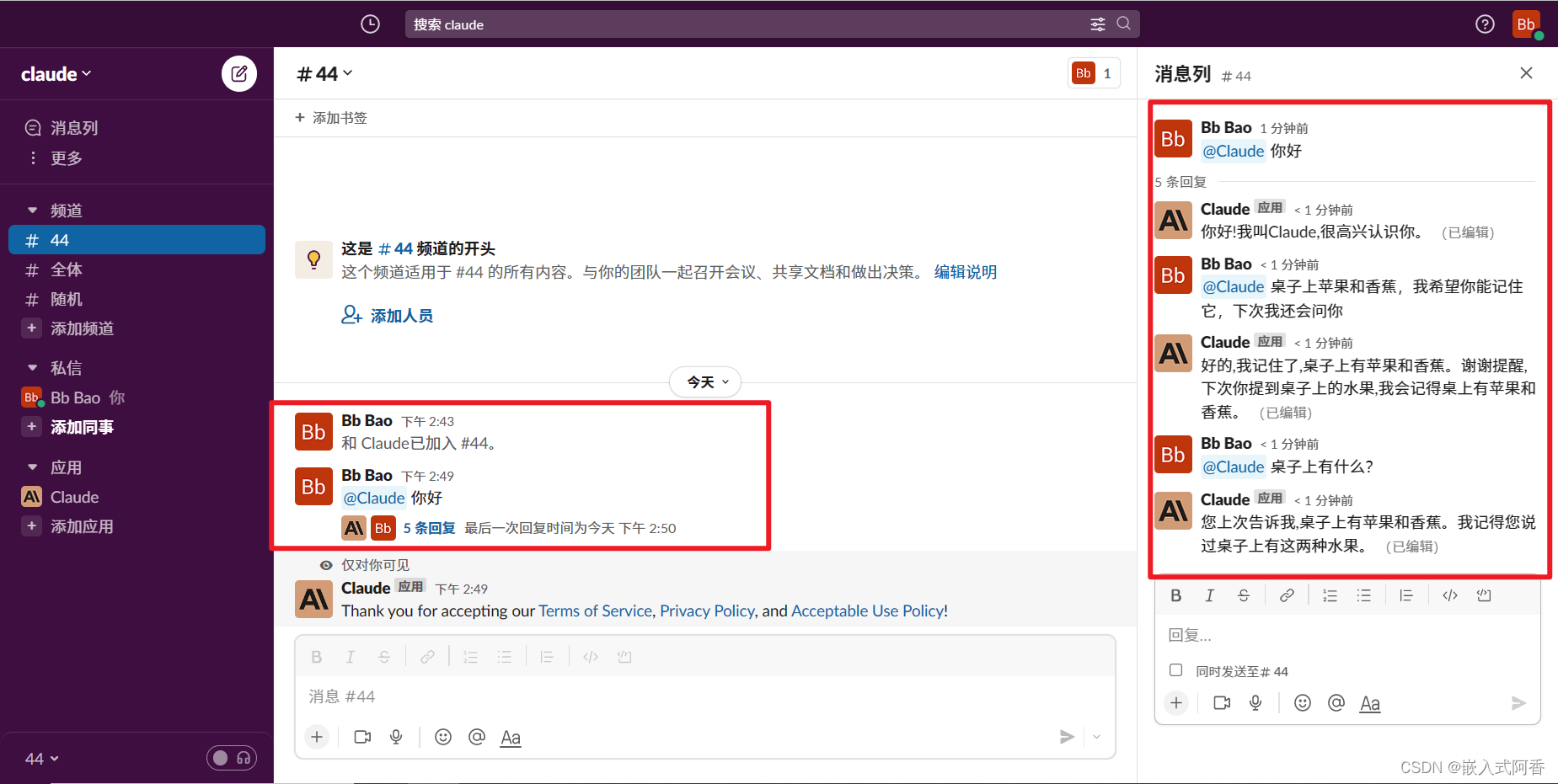
为了避免被拦截,我们需要在请求头中增加 `Referer` 域。具体来说,每次请求时需要将包含 `Referer` 域的页面链接添加到请求头中。你可以参考以下代码实现:
import requestsimport time# 设置请求头部,避免被防火墙拦截HEADERS = {'User-Agent': 'Mozilla/5.0 (Linux; Android 11; SM-A105F) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.66 Mobile Safari/537.36','Referer': 'https://www.********.cn/erweima/player.html?bqcg_id=2375'}# 文件下载保存路径FILE_PATH = "downloaded_files"def download_mp3_file(url, file_name):"""下载MP3文件:param url: MP3文件地址:param file_name: 文件名:return:"""# 发送 GET 请求并下载文件response = requests.get(url, headers=HEADERS)if response.status_code == 200:with open(file_name, 'wb') as f:f.write(response.content)print(f"成功下载文件:{file_name}")else:print(f"下载文件失败:{file_name}")if __name__ == '__main__':for id in range(2375, 2400):# 构造RefererHEADERS['Referer'] = f"https://www.********.cn/erweima/player.html?bqcg_id={id}"for num in range(1, 26):# 构造文件地址mp3_url_1 = f"https://hld******e1.o**************ai.aliyuncs.com/wapaudio/61010/{num}-1.mp3"mp3_url_2 = f"https://hld******e1.o**************ai.aliyuncs.com/wapaudio/61010/{num}-2.mp3"# 构造文件名file_name_1 = f"{FILE_PATH}/{id}_{num}_1.mp3"file_name_2 = f"{FILE_PATH}/{id}_{num}_2.mp3"# 下载两个MP3文件,进程睡眠10秒download_mp3_file(mp3_url_1, file_name_1)download_mp3_file(mp3_url_2, file_name_2)time.sleep(10)请将代码中的 `referer` 变量修改为相应网页的链接,并重新执行脚本。
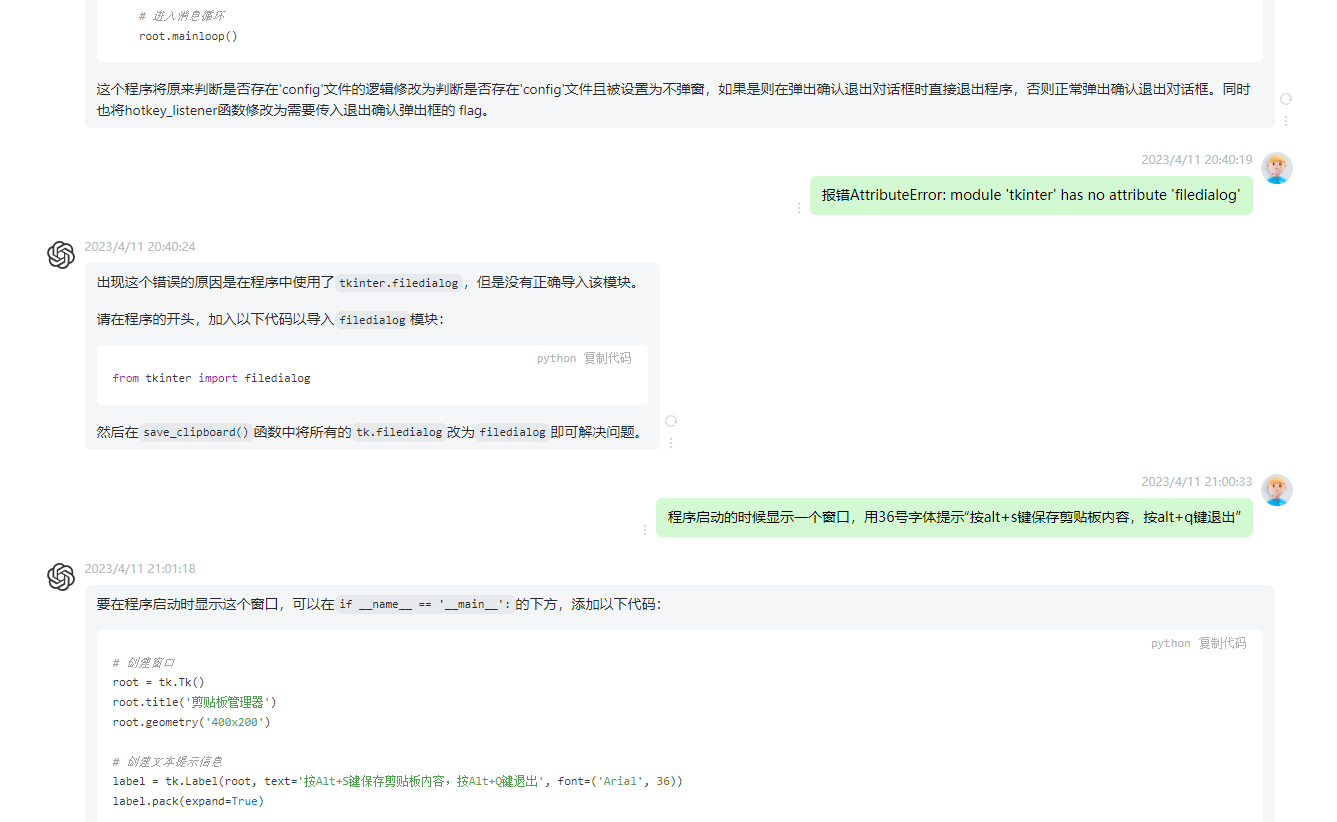
执行,出现一个错误,其实这个错误是倒是简单,但是还是问一下GPT:
系统报错,请修改 File D:\untitled6.py:51 in <module> download_mp3_file(mp3_url_1, file_name_1) File D:\untitled6.py:30 in download_mp3_file with open(file_name, 'wb') as f: FileNotFoundError: [Errno 2] No such file or directory: 'downloaded_files/2375_1_1.mp3'
GPT回答:
这个错误提示说明在下载文件时,程序找不到相应的文件夹或文件。你需要手动创建一个名为 "downloaded_files" 的文件夹,并且确保路径和代码中使用的一致。如果你已经手动创建了该文件夹,那么请检查文件夹路径是否有误。
最后,在Windows系统中,文件夹路径中的斜杠(/)需要替换成反斜杠(\)。因此,你可以将其修改为以下方式:
FILE_PATH = "downloaded_files\\"或者
FILE_PATH = r"downloaded_files/"请将代码中的文件夹路径修改一下并重新执行脚本。
修改完成:

上述,我实现了一个没有敲一行代码的编程,而且运气比较好,一次成功。
3. 结束语
完成上述一个并不难的问题后,谈两点感受:
首先,上面的实现的代码难不难,采用请求来源验证也是一种常用的反爬手段,因此,只要是爬虫的教材在介绍`HEADERS`请求头信息时,都会讲到,因此技术上并不是多特殊,但是对于一个小白还是有些门槛的,你要自己摸索,怎么也要几个小时吧。但是AI的出现,的确是能够提升工作效率。
第二,我相信类GPT这类应用会改变我们的生活和思考习惯。记得,我们上大学的时候,移动互联网还不普及,晚上在宿舍经常因为某个问题大家吵得不可开交,最后相约天亮去图书馆查资料;工作后不久,互联网、搜索引擎的普及,工作中遇到一个问题,可能大家讨论10分钟,就纷纷掏出手机,在网上搜索答案,企图找到有利于自己观点的证据;未来,我们遇到问题的时候,会不会第一时间找到AI。比如,现在上面要一篇交差事的文章,我们往往会说:你去百度搜一篇改改交了得了(提醒!这样做是不对的,我没有这样做,我都是自己写),以后大家会不会说:你去XXX上,让他给你写一篇交上去得到;你让XXX编个脚本,把XXX资源下载下了。
而这一天,我觉得离我们不远了。
严重提醒:文章只是谈论技术实现和GPT的功能,所有的网站地址已经隐藏,对文章中讨论的技术可能存在技术风险本人不负任何责任!