目前不少文章用到了孟德尔随机化+meta分析,今天咱们也来介绍一下,孟德尔随机化+meta其实主要就是meta分析的过程,提取了孟德尔随机化文章的结果,实质上就是个meta分析,不过多个孟德尔随机化随机化的结果合并更加加强了结果的可靠性。有部分人可能对meta分析不是很了解,咱们今天先来介绍一下meta分析基础,为下一讲孟德尔随机化+meta分析做准备。
R语言进行进行meta分析咱们就做最基本的部分就行,不必搞得太复杂。咱们先导入数据和R包。很多R包都能做,咱们随便选个meta包就可以了。
library(meta)
bc<-read.csv("E:/r/test/senlintu1.csv",sep=',',header=TRUE)
names(bc)
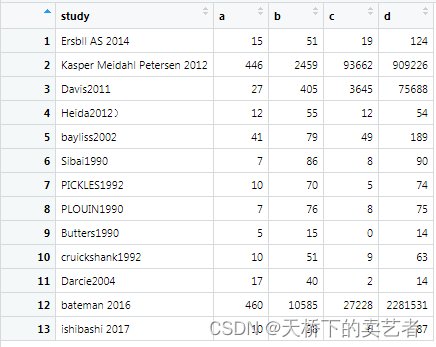
这是一个很简单的数据,stud表示研究名称,a为实验组阳性人数,b为实验组总人数,c为对照组阳性人数,d为对照组总人数(公众号回复:森林图数据1,可以获得数据)。
咱们先来看下函数格式event.e就是实验组阳性人数,n.e,实验组总人数,event.c对照组阳性人数,n.c对照组总人数,data就是你的数据,studlab填入其他的项目,method这里选"Inverse"倒方差的方法就可以了,sm这里填入结果类型,如果你需要的是OR的结果就填入OR
metabin(event.e, n.e, event.c, n.c, data,studlab = paste(), sm, method = "Inverse")
先生成meta分析结果,就按顺序把结果填进去就可以了
out<-metabin(event.e=a, n.e=b,event.c=c,n.c=d,data=bc,sm="OR",studlab = paste(study),method = "Inverse")
直接填进去也是可以的,这样方便点
out<-metabin(a,b,c,d,data=bc,sm="OR",studlab = paste(study),method = "Inverse")
解析结果
summary(out)
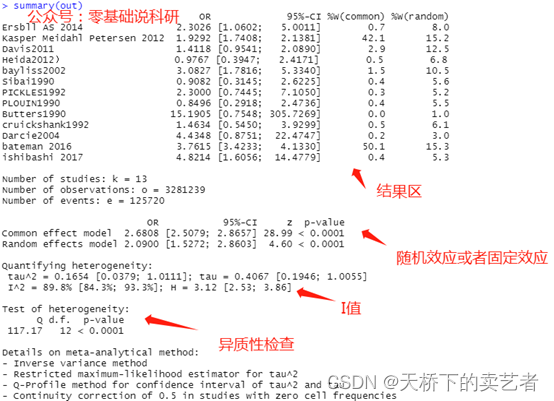
我简单解析一下,这类教程网络多得是,可以百度一下。先看异质性,如果有异质性应需用随机效应模型,否则可选用固定效应模型。我们这里选择随机效应模型。
我这里异质性I89.9%挺大的,我们可以使用剔除法来观察剔除单个观察后的异质性,我这里随便举例,假如我剔除第一个
先加个ID
bc$id<-1:13
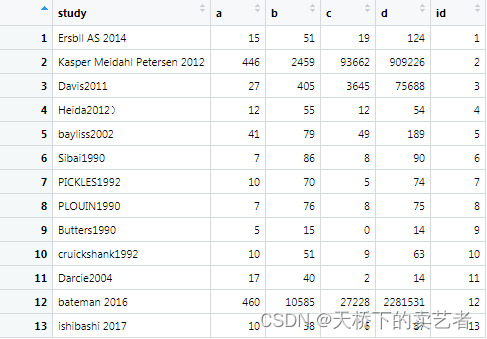
删除第一项我们可以使用亚组函数subset来控制,使得subset=id>2就可以了
out<-metabin(a,b,c,d,data=bc,sm="OR",studlab = paste(study),method = "Inverse",common=F,subset=id>2)
summary(out)

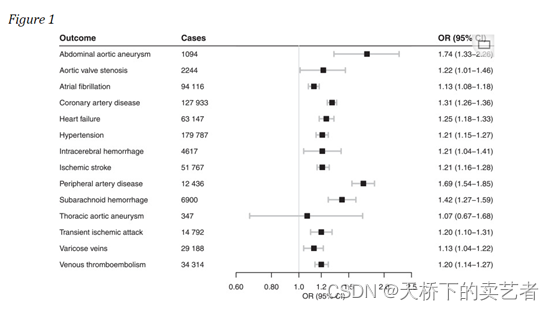
可以看到异质性较前下降了一点,接下来就可以绘制森林图了
out<-metabin(a,b,c,d,data=bc,sm="OR",studlab = paste(study),method = "Inverse",common=F)forest(out)
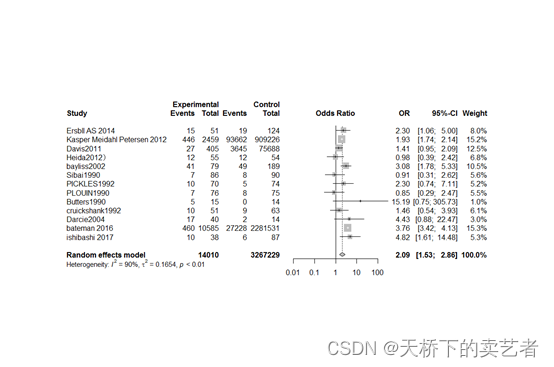
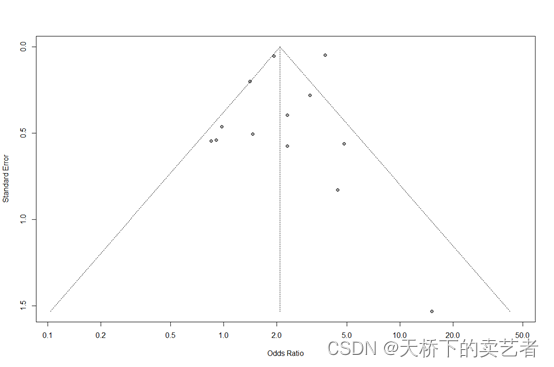
所有结果都可以在图上找到,结果主要是看最后的综合结果,我这里的OR是2.09.接下来做偏倚检查,主要是漏斗图和Egger法
漏斗图,比较理想的漏斗图应该是散点对称分布
funnel(out)
Egger法,P值大于0.05说明没有偏倚,还给出了参考文献
metabias(out,method.bias="Egger")

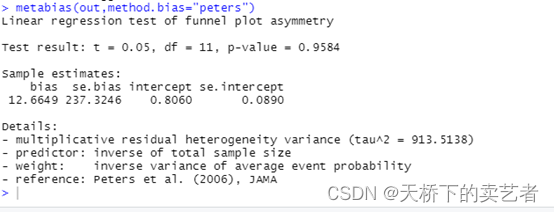
这里还有一个peters法,参考文献是篇JAMA的文章,应该也是蛮靠谱的
metabias(out,method.bias="peters")
这里简单的介绍了一下meta分析的操作,肯定没有别人专门将meta分析的详细,如果想进行孟德尔随机化+meta分析最好去补一补meta分析的知识。