1.你认为什么是操作系统,操作系统有哪些功能
os是:管理资源、向用户提供服务、硬件机器的扩展
1.进程线程管理:状态、控制、通信等
2.存储管理:分配回收、地址转换
3.文件管理:目录、操作、磁盘、存取
4.设备管理:设备驱动、分配回收、缓冲技术
5.用户接口:系统命令、编程接口
2.简单linux命令使用:top ps netstat df less grep
top: 性能分析工具,能够实时显示系统中各个进程的资源占用状况,进程
ps:列出运行的进程
netstat:显示网络状态,所有连线的socket
df:显示系统上的文件系统磁盘使用情况统计
less:随机浏览文件,支持翻页和搜索
grep:用于查找文件里符合条件的字符串或正则表达式
tail:看日志最后
3.innodb和myisam区别,统计记录的数量会怎么做
区别:
1.InnoDB中不保存表的具体行数,而MYISAM对是单独存起来的
2.InnoDB是聚集索引,数据文件是和索引绑在一起的,必须要有主键,通过主键索引效率很高。但是辅助索引需要两次查询,先查询到主键,然后再通过主键查询到数据;MyISAM是非聚集索引,数据文件是分离的,索引保存的是数据文件的指针。
3.InnoDB支持外键,而MyISAM不支持。
4.MyISAM类型不支持事务处理等高级处理,而InnoDB类型支持;myisam强调性能
5.InnoDB支持数据行锁定,MyISAM不支持行锁定,只支持锁定整个表;高并发insert,innodb完胜
全量count操作:
myisam中把表的总行数存储在磁盘上,直接返回
innodb一条条读出来,再加起来(因为innodb的事务特性mvcc导致多少行不确定)
myisam更快
count带where筛选:myisam不一定快了
4.tcp是用什么保证可靠性的
TCP协议主要通过以下七点来保证传输可靠性:连接管理,校验和,序列号,确认应答,超时重传,流量控制,拥塞控制。
连接管理 即三次握手和四次挥手。连接管理机制能够建立起可靠的连接,这是保证传输可靠性的前提。
校验和 发送方对发送数据的二进制求和取反,然后将值填充到TCP的校验和字段中,接收方收到数据之后,以相同的方式计算校验和并进行对比。如果结果不符合预期,则将数据包丢弃。
注意:即便二者相等,也并不能确保数据包一定是正确无误的,基于某些巧合,会出现数据包错误,但发送端和接收端的校验和相等的场景。
序列号 TCP将每个字节的数据都进行了编号,这就是序列号。序列号的具体作用如下:能够保证可靠性,既能防止数据丢失,又能避免数据重复。能够保证有序性,按照序列号顺序进行数据包还原。能够提高效率,基于序列号可实现多次发送,一次确认。
确认应答 接收方接收数据之后,会回传ACK报文,报文中带有此次确认的序列号,用于告知发送方此次接收数据的情况。在指定时间后,若发送端仍未收到确认应答,就会启动超时重传。
超时重传 具体来说,超时重传主要有两种场景:数据包丢失:在指定时间后,若发送端仍未收到确认应答,就会启动超时重传,向接收端重新发送数据包。确认包丢失:当接收端收到重复数据(通过序列号进行识别)时将其丢弃,并重新回传ACK报文。
流量控制 接收端处理数据的速度是有限的,如果发送方发送数据的速度过快,就会导致接收端的缓冲区溢出,进而导致丢包……为了避免上述情况的发生,TCP支持根据接收端的处理能力,来决定发送端的发送速度。这就是流量控制。流量控制是通过在TCP报文段首部维护一个滑动窗口来实现的。
拥塞控制 拥塞控制就是当网络拥堵严重时,发送端减少数据发送。拥塞控制是通过发送端维护一个拥塞窗口来实现的。可以得出,发送端的发送速度,受限于滑动窗口和拥塞窗口中的最小值。
拥塞控制方法分为:慢开始,拥塞避免快重传和快恢复
5.如果发现cpu飙升,怎么排查
线上CPU飙升的问题很常见(例如某个活动开始,流量突然飙升时)
线上系统突然运行缓慢,CPU飙升,甚至到100%,以及Full GC次数过多,接着就是各种报警:例如接口超时报警等。

top确认进程 -》 top确认线程 -〉 线程hex -》jstack堆栈信息 -〉 jstat gcutil信息
原因:
1.内存消耗过大,gc次数过多(生成大量对象,导致溢出),也可能system.gc过多
2.耗cpu操作,无限递归等
3.死锁
4.大量进程访问阻塞的接口
5.某个线程进入waiting状态,导致不可用
6.redis怎么实现去重
基于set:SISMEMBER key member
基于bit:Redis 的 bit 可以用于实现比 set 内存高度压缩的计数,它通过一个 bit 1 或 0 来存储某个元素是否存在信息,用userid作为访客偏移,网站访客计数,setbit,getbit,bitcount等
基于hyperloglog:实现超大数据量精确的唯一计数,基于概率论近似计数,12 k左右的内存,实现上亿的唯一计数,而且误差控制在百分之一左右
基于BloomFilter:是利用类似位图或者位集合数据结构来存储数据,利用位数组来简洁的表示一个集合,并且能够快速的判断一个元素是不是已经存在于这个集合。虽然BloomFilter不是100%准确(需要安装插件)
7.如果去重的时候查询redis时网络波动导致查超时怎么办
假设场景:redis 响应变慢,查看日志,发现大量 TimeoutException。
大量TimeoutException,说明当前redis服务节点上已经堆积了大量的连接查询,超出redis服务能力,再次尝试连接的客户端,redis 服务节点直接拒绝,抛出错误。
1.cpu资源竞争,要与上层应用进行资源隔离
2.swap导致redis内存交换磁盘,关闭swap
3.对于网络波动
a.配置文件优化,如timeout时间300s,tcp-keepalive心跳机制60
b.数据备份和容错,主节点和备份节点,用sentinel自动故障检测和转移,保证可用
c.数据aof持久化,避免数据丢失;replication,同步
8.kafka在什么情况下会导致消息丢失
参考https://huaweicloud.csdn.net/637ee65ddf016f70ae4c905f.html?spm=1001.2101.3001.6661.1&utm_medium=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7Eactivity-1-125605128-blog-131979567.235%5Ev38%5Epc_relevant_sort&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7Eactivity-1-125605128-blog-131979567.235%5Ev38%5Epc_relevant_sort&utm_relevant_index=1
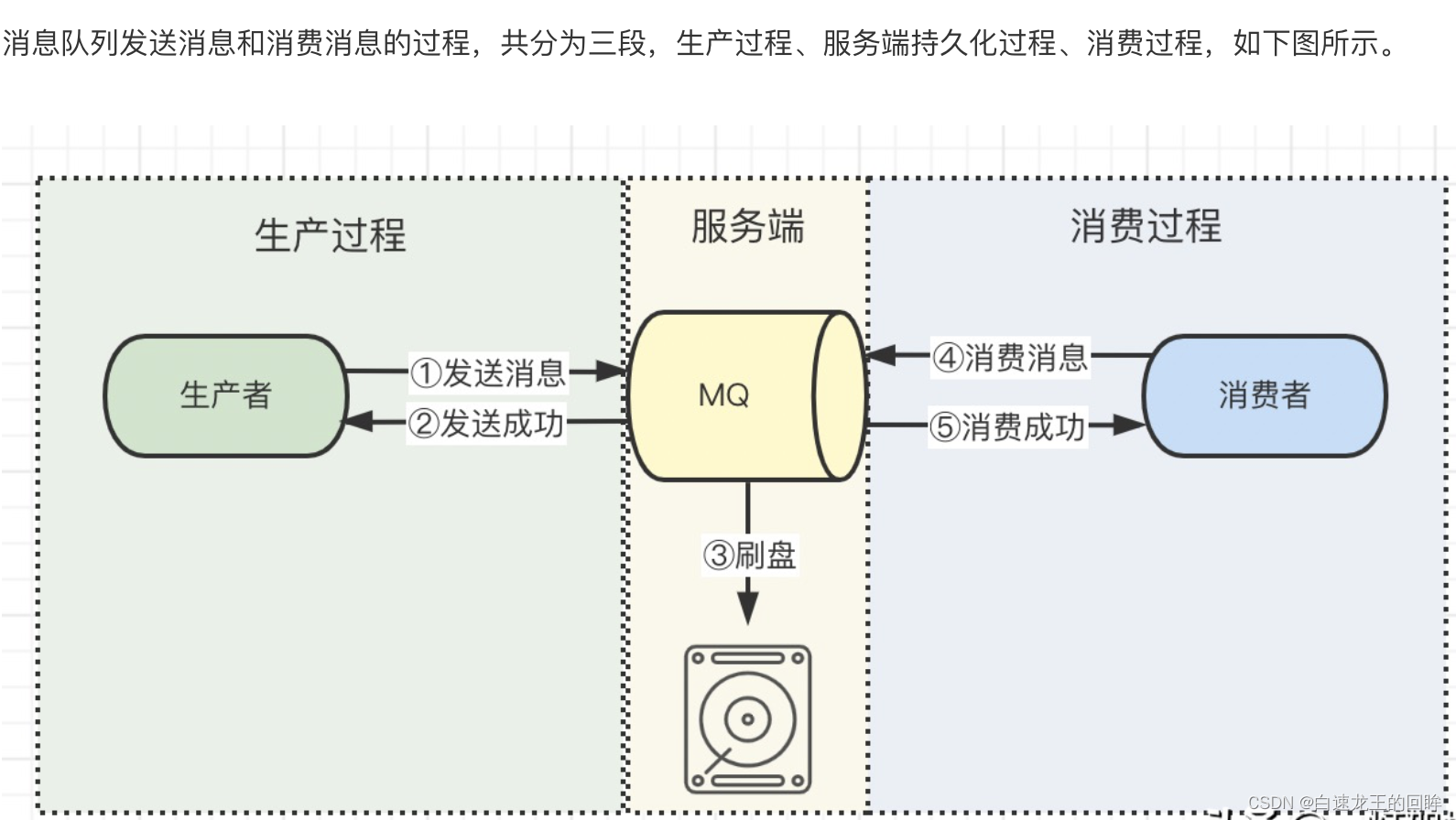
1.生产过程丢失,网络原因,重发解决(try catch;异常消息表异步任务重试;kafka自动重试有次数限制,一般手动)
2.服务端持久化丢失,kafa异步刷盘,broker在刷盘前宕了,丢失了
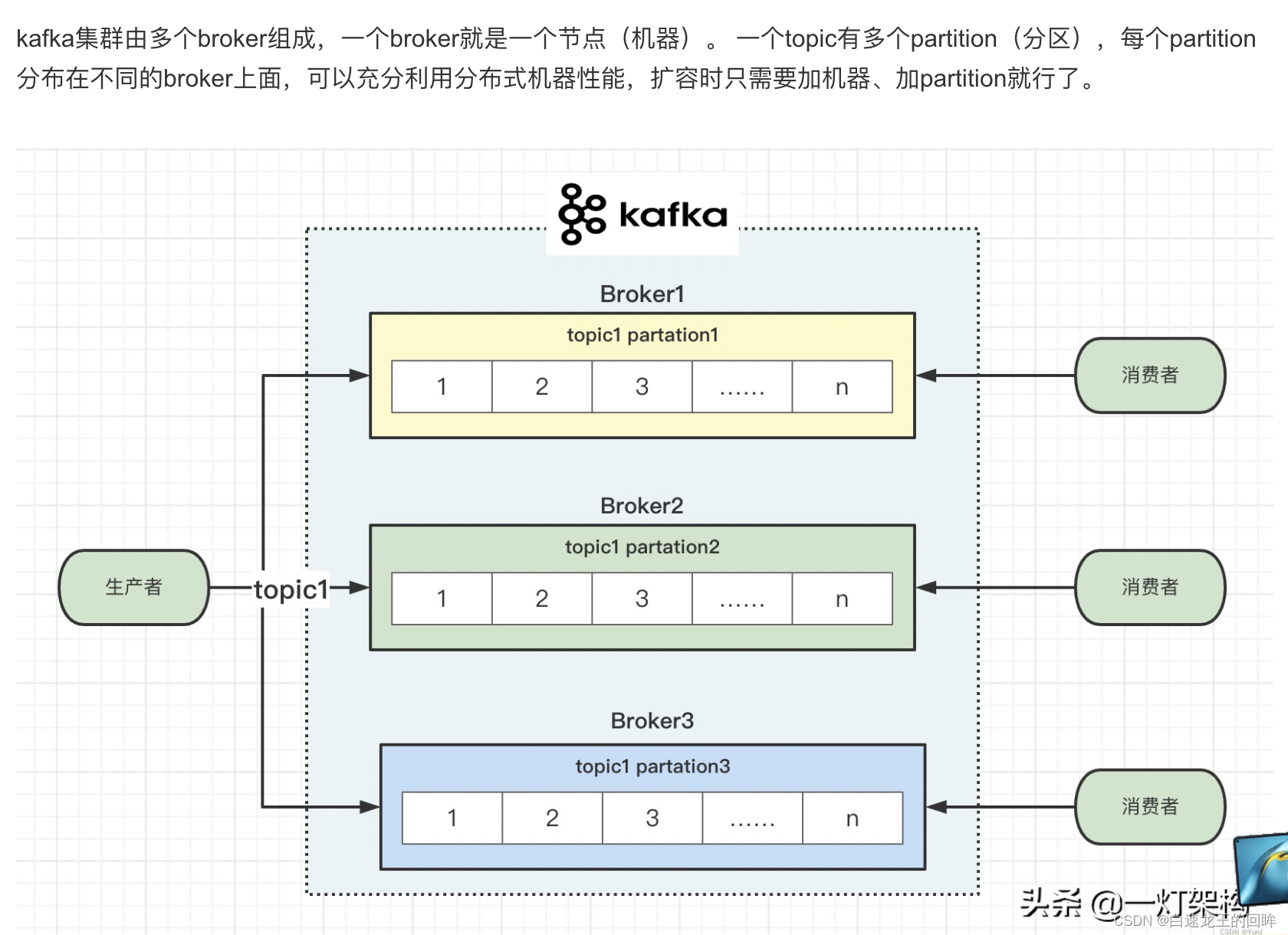
每个partition多副本,leader和follower,加快持久化的性能和安全性,ISR + OSR = AR
3.消费过程丢失,offset的概念,消费者从partition拉取后本地处理完需要commit一下offset说明消费完成,关闭自动commit offset,要处理完逻辑后再commit
9.kafka和rabbitmq有什么区别
1.开发语言,rabiitmq用erlang,kafa用scala和java用于活跃的流式数据,大数据量
2.结构不同,rabbitmq的broker有exchange,biding和queue,kafka的broker有part分区
3.交互式:rabbitmq用push,kafka用pull
4.负载均衡:rabbitmq单独的loadbalncer,kafka用zookeeper对broker和consumer进行管理
5.使用场景:rabbit支持消息可靠传递,支持事务,不支持批量;kafka高吞吐,内部采用消息的批量处理
10.explain参数

id,select_type,type,possible_key, key,key_len,ref,rows_filtered,extra

11.http报文参数有哪些吗?

请求行:方法等
请求头部:kv对
空行
请求数据
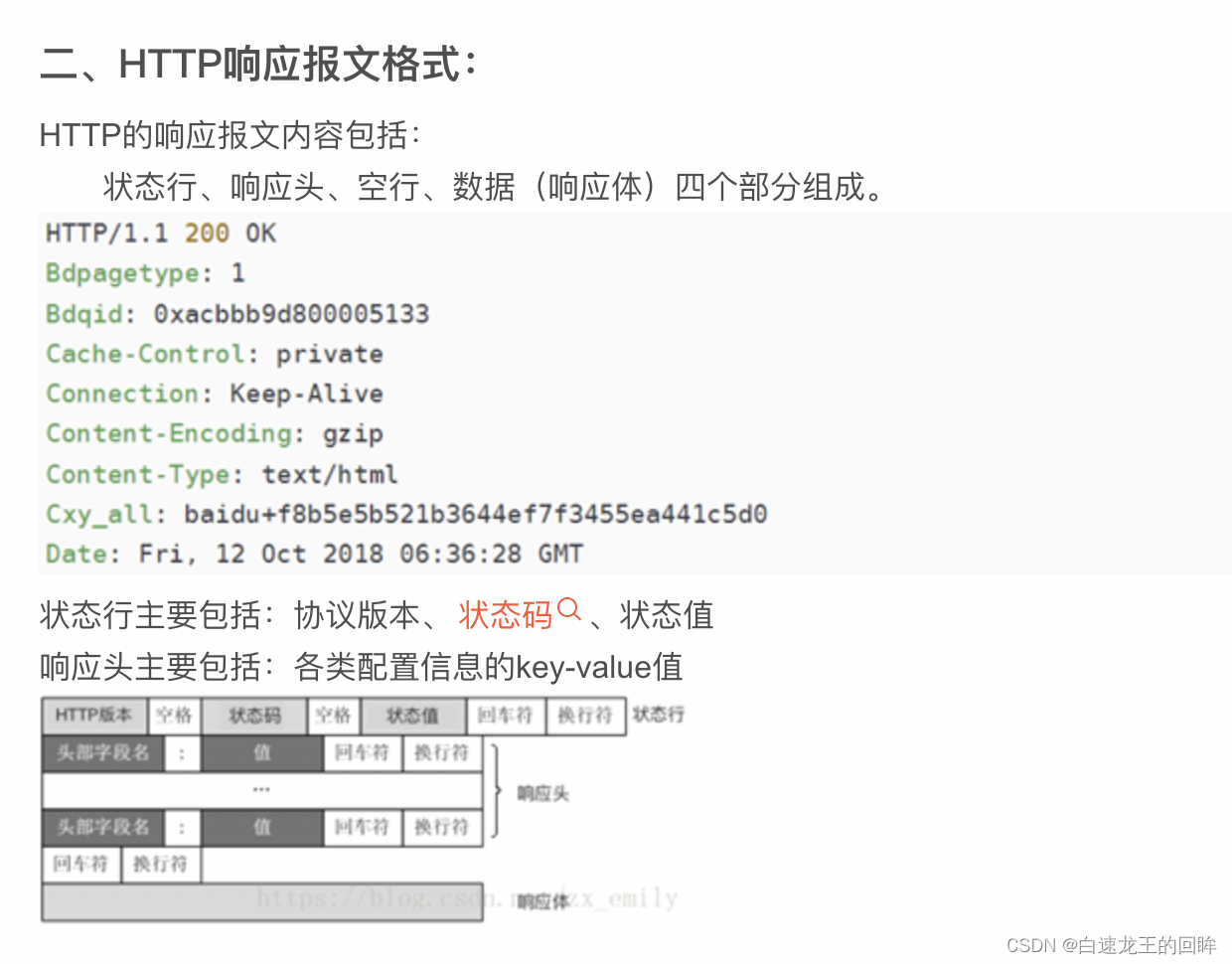
状态行
响应头:kv对
空行
响应体
12.消息队列如何保证可靠性和消息幂等性?
消费者多次受到信息,要保证消费的幂等性

唯一id、分布式锁只有一个消费者,消费清单,消费状态记录
可靠性:
1.异常捕获机制try catch
2.事务机制
3.发送端确认confirm
4.持久化存储
5.消费者ack
6.消息积压的话得进行限流
7.幂等性
13.消息队列优缺点
优点:解耦异步削峰
缺点:可用性降低(挂了)、复杂度上升(重复、丢失、顺序)、一致性
14.接口幂等性如何保证?
参考https://www.21ic.com/article/883663.html
幂等性:它描述了一次和多次请求某一个资源对于资源本身应该具有同样的结果(网络超时等问题除外),使用幂等性最大的优势在于使接口保证任何幂等性操作,免去因重试等造成系统产生的未知的问题
问题:前端重复提交表单,用户恶意进行刷单,接口超时重复提交,消息进行重复消费
影响:改成串行降低效率,业务复杂
get满足,post不满足
实现方法:
1.数据库唯一主键的实现主要是利用数据库中主键唯一约束的特性,一般来说唯一主键比较适用于“插入”时的幂等性,其能保证一张表中只能存在一条带该唯一主键的记录,使用分布式id,雪花id之类
2.数据库乐观锁实现幂等性:多加一个字段作为数据的版本标识,多次更新无影响
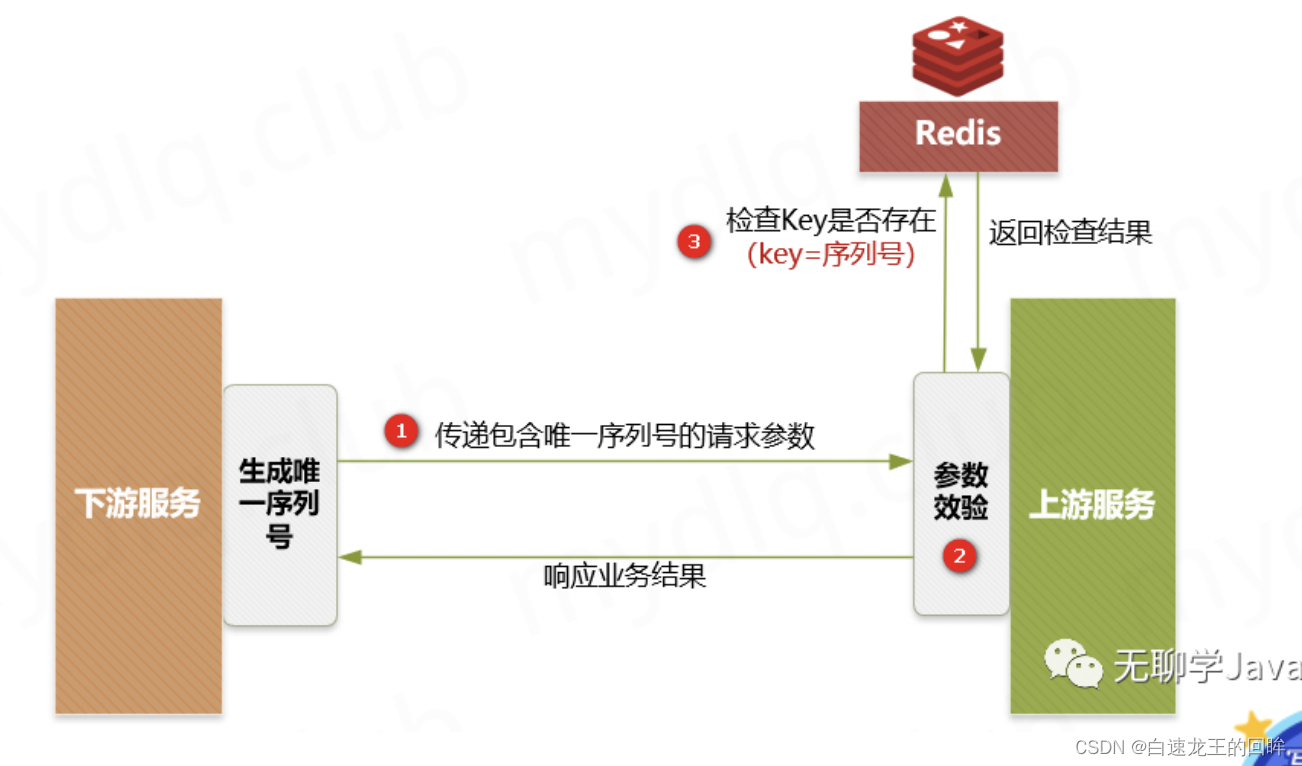
3.防重 Token 令牌实现幂等性:对于点许点击或超时充实,提交订单,调用方在调用接口的时候先向后端请求一个全局 ID(Token),请求的时候携带这个全局 ID 一起请求(Token 最好将其放到 Headers 中),后端需要对这个 Token 作为 Key,用户信息作为 Value 到 Redis 中进行键值内容校验,如果 Key 存在且 Value 匹配就执行删除命令,然后正常执行后面的业务逻辑。如果不存在对应的 Key 或 Value 不匹配就返回重复执行的错误信息,这样来保证幂等操作。
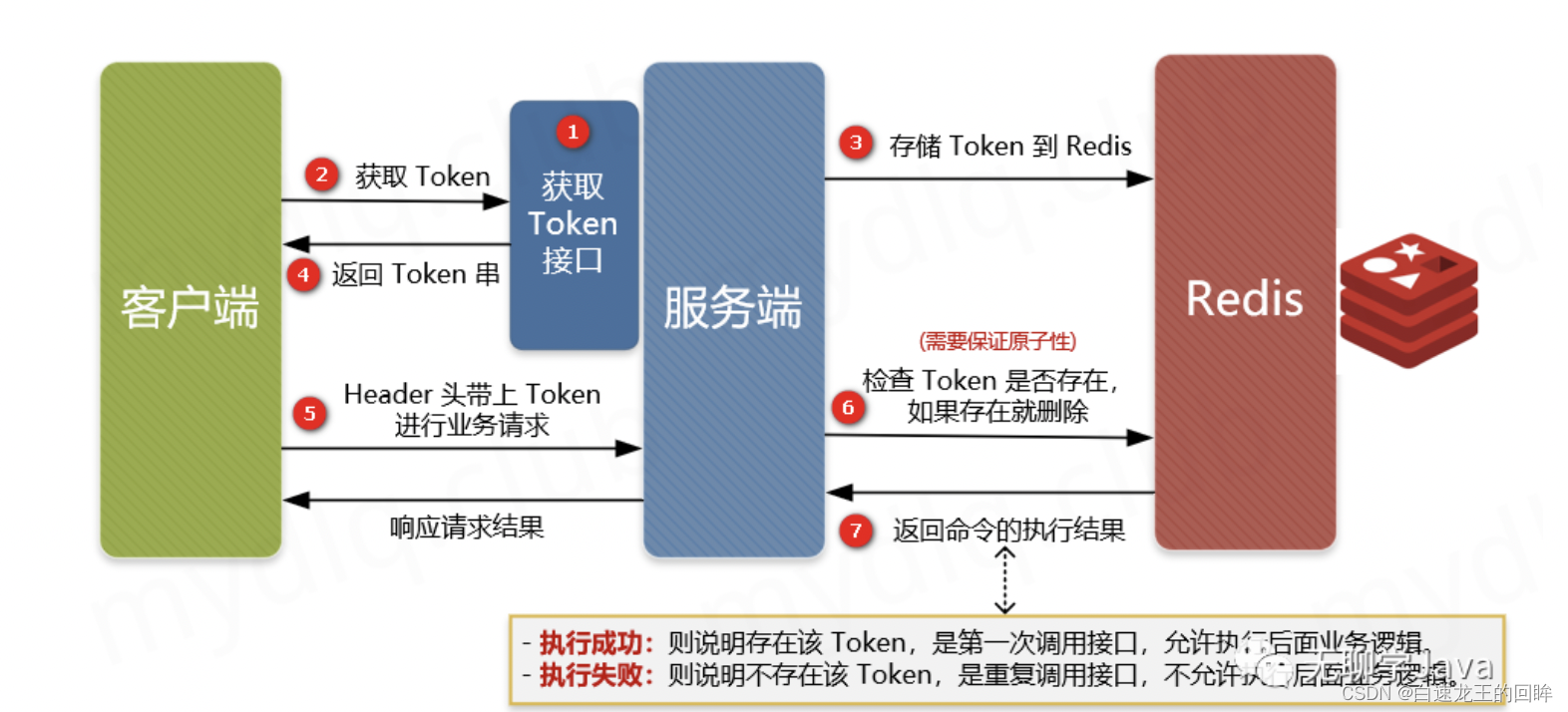
要保持检查and删除的原子性,使用lua脚本
4.下游传递唯一序列号实现幂等性:请求序列号,其实就是每次向服务端请求时候附带一个短时间内唯一不重复的序列号,该序列号可以是一个有序 ID,也可以是一个订单号,redis加上过期时间