本文将介绍 Chocolate Factory 框架背后的一系列想法和思路。在我们探索和设计框架的过程中,受到了:LangChain4j、LangChain、LlamaIndex、Spring AI、Semantic Kernel、PromptFlow 的大量启发。
欢迎一起来探索:https://github.com/unit-mesh/chocolate-factory 。
顺带一提,在我们的参考架构里,框架/SDK 只是整体参考架构的一小部分。
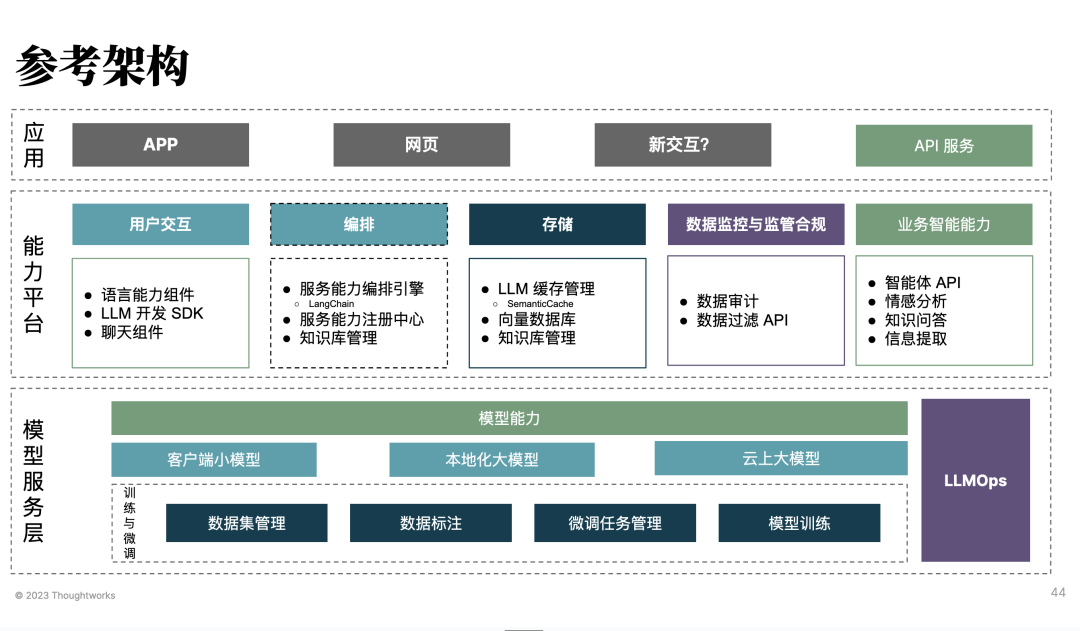
在 SDK 之后,还需要关注于 LLM 应用平台的设计。
为什么开发 JVM 语言的 LLM 开发框架
在过去的几个月里,我们一直在结合已有的 JVM 体系基础设施构建 LLM 应用。诸如于:
在 ArchGuard Co-mate 里,我们探索了架构 Copilot + Agent Tool (架构分析工具)的正确打开方式。
在 AI 辅助编程工具 AutoDev 中,我们给出了市面上最好的开源 IDE 插件的上下文构建模式 —— 构建复杂上下文(语言、框架、规范等)的 Prompt 策略,以及支持不同的大语言模型(除了市面上的大模型,还有内部的 MaaS 平台)。
……
这些尝试是围绕于我们过去的另外一个假设:当大模型成本降低,可靠性上升之后,AIGC 会与业务应用紧密结合。在这时,我们需要致力于:
开发结合 LLM 内部基础设施的 SDK
探索快速构建 RAG (检索增强)相关 PoC (概念证明)的方式
更友好的 prompt 开发与设计工具
简单来说,我们需要一些封装内部基础设施的框架、调试应用,以快速支撑 AI 应用的开发。
诸如于,我们在构建本地化代码搜索时,需要如下的工具:
dependencies {
// 核心库implementation("cc.unitmesh:cocoa-core:0.3.4")
// 代码拆分implementation("cc.unitmesh:code-splitter:0.3.4")
// Elastisearch 向量化存储,普通搜索implementation("cc.unitmesh:store-elasticsearch:0.3.4")
// 本地化的 embedding,用于每次更新代码,重新 embedding => CPUimplementation("cc.unitmesh:sentence-transformers:0.3.4")
}每个模块并不复杂,只是一些基本的 API 与基本的逻辑封装。但是,可以直接与现有的 AI 应用结合,再配套内部的 MaaS(模型即服务平台),就能快速在现有的业务中接入 LLM 能力。
起步:总结 LLM 应用所需要的能力
如先前的文档所说,我们将 LLM 优先的软件架构分为三类:。

通过简单的 prompt 来与大模型进行交互。
结合向量化(Embedding)的方式,来与大模型交互。
自动化规划的方式,基于 workflow 的方式。
在当前,我们优先关注于结合向量化,也就是大部分 RAG 场景下的交互。即基于特定的业务场景,分析用户的意图,自动提供相应的上下文,交由大模型来进行自动化分析。对于这三种类型来说,或者不同场景时,各自的关注度是不一样的。
与大模型的 API 交互。主要会由两部分组成,第一部分是:依赖于 MaaS 平台的标准的 LLM 接口模型封装;第二部分是:支持流式、自定义二次处理结果的交互 API。(第二部分其实是最难的)
文档向量化(Embedding)。主要会由三部分组成,第一部分是:支持不同格式文档的处理,及其拆分模式与策略的代码化设计;第二部分是:不同精度(出于成本考虑)需求的向量化模型接入;第三部分是:支持查询扩展的中间层与多种类型数据库检索,即结合向量数据库和传统数据库。
自动化规划(Flow + Agent)。尽管我们尝试去做更多相关的尝试,但是由于精力有限,并不能给出一个非常精确的结果。所以,在这里就暂时不展开这部分相关的内容。
开发一个框架与过去的东西差别不多。但是,有意思的一点是,由于我们构建的是一个框架,所以当看到新的 RAG 论文,第一反应就是能否交由框架来支持。
抽象:回顾 LLM 的数据处理
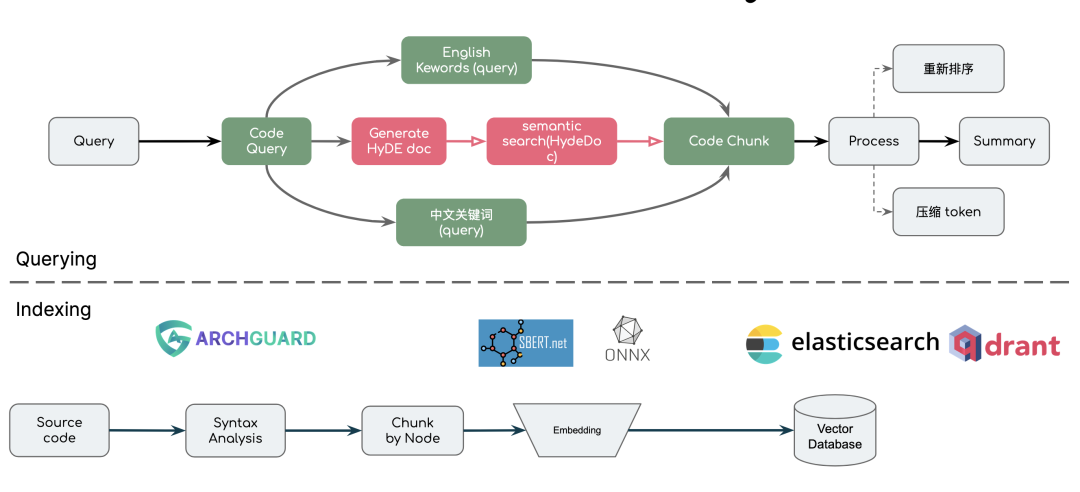
诸如于 LangChain、LlamaIndex 在这方面已经做了非常好的抽象,我们在设计的时候,参考(复制)了大量的相关思想。在 LlamaIndex 的文档上,已经给出了很好的抽象,在这里我们使用我们新开发的 RAGScript (可以直接运行)来表达相关的内容:
rag {indexing {val document = document("filename.text")val chunks = document.split()store.indexing(chunks)}querying {val results = store.findRelevant("Hello World").lowInMiddle()llm.completion {
"// 结合 results 处理 prompt"}}
}上面的代码段非常言简意赅的表达 RAG 的过程。简单来说,一个 RAG 分为 Indexing 和 Querying 两个阶段:
在 Indexing 阶段里,我们关注于如何将数据加工和分解(split),并注入到向量数据库中。
在 querying 阶段里,我们关注于如何加工检索完的数据,再结合 LLM 来处理
而现有的 LangChain、LlamaIndex 已经能提供我们很好的思路。唯一的挑战是,如何结合不同场景去探索合适的应用示例。
原型:从应用 PoC 中迭代抽象接口
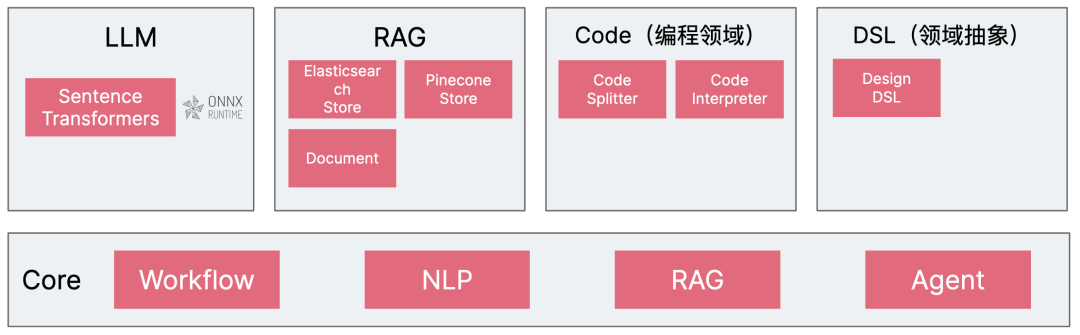
在不同的 LLM 应用开发框架或者 LLM 数据处理引擎里,都有大量的基础设施支持。但是,由于我们的场景往往是多种多样的,所以有时候显得有些不足。诸如于:
本地化向量化(Emdeddbing)模型 SentenceTransformers 的引入,以降低代码向量化的成本。为此,我们需要引入 Onnx Runtime, 以在客户端或者服务端进行向量化操作。
更精准的代码切分。对于框架型代码逻辑解释而言,能提供 interface 等抽象类的拆分,保持类之间的继承关系,以及其它更精准的规则处理,明显会比通用的拆分规则更有实际意义。
同时,为了更好的开发框架,除了结合过往开发 LLM 应用的经验,还得思考一些新的场景作为试验田。诸如于:
交互式的 UI 代码辅助设计场景。
简单场景下的代码解释器。
基于文档的规范查询。
基于自然语言的语义化代码搜索。
长数据场景下的测试用例设计
每种场景之下,对于框架的支持要求是不一样的。对于简单的场景,应该直接由 core 模块来提供所有的能力;对于复杂的场景,需要提供基本的 workflow 支持,以实现快速的应用开发。
除此,在复杂的场景之后,大部分的数据需要经过二次处理,也就是:
实时返回模式。只用于向用户提供快速的反馈。诸如代码生成时,先返回代码;又或者是基于流式的 DSL 来响应数据。
结果二次处理。当模型返回所有的结果时,需要再处理。诸如于,执行用户的代码,以生成的图表。
而在某些场景,我们需要的是长等待时间,即等待所有的用户返回内容。而对于这种不能由框架支持的功能,则稍微显得麻烦一些,我们得考虑通过示例向用户呈现这个过程。
插曲:解释 RAG 实现的 RAGScript
在开发了基本的 Chocolate Factory 功能之后,为了更好的让其他同事参与进来。我们尝试编写一系列的文档和示例,以向其他人解释:如何开发一个基于 LLM 的 RAG 应用?
为此,我们基于已有的 API 能力,构建了 RAGScript,以快速向其他人解释完整的过程。完事的示例代码如下所示:
rag("code") {// 使用 OpenAI 作为 LLM 引擎llm = LlmConnector(LlmType.OpenAI)// 使用 SentenceTransformers 作为 Embedding 引擎embedding = EmbeddingEngine(EngineType.SentenceTransformers)// 使用 Memory 作为 Retrieverstore = Store(StoreType.Memory)indexing {// 从文件中读取文档val document = document("filename.txt")// 将文档切割成 chunkval chunks = document.split()// 建立索引store.indexing(chunks)}querying {// 进行相关性查询val revelant = store.findRelevant("Hello World")// 结合 Lost in the Middle 的长上下文重新排序val results = revelant.lowInMiddle()println(results)}
}当然了,在我们的 RAG 示例中,还提供了代码语义化解释搜索的示例。详细见:https://framework.unitmesh.cc/docs/rag 。
Prompt 调试:LLM 的工程化开发难点
尽管我们开发的是模式二(Co-pilot 型应用)优先的 LLM 应用框架,但是在我们开发示例的过程中,我们依旧会发现对于 Prompt 的调试与编排是最大的挑战。
在 Chocolate Factory 的 DDD 思想的工作流中,我们推荐的实践是:
Apache Velocity Engine 作为模板引擎
构建每个 Workflow 独立的 Context 环境,与变量 resolver。
然而,对于一个大型的组织来说,内部会存在不同的 LLM。对于不同的 LLM 而言,相应的 prompt 编写模式也是有差异的。所以,我们正在思考采用同 PromptFlow 相似的方式,即采用独立的模板文件,结合工作流编排,以适应不同模式的 promtp 差异。如下是 PromptFlow 的模板示例:
system:
You are a helpful assistant.
{% for item in chat_history %}
user:
{{item.inputs.question}}
assistant:
{{item.outputs.answer}}
{% endfor %}
user:
{{question}}再结合 CLI 或者 IDE 可视化的方式进行探索。
总结
总的来说,这篇文章深入探讨了设计 JVM 语言的 LLM 应用开发框架的思考过程,强调了框架的多样性和复杂性,以及如何通过框架和工具来支持各种 LLM 应用场景。我们提供了有用的示例代码和抽象概念,有助于读者更好地理解和开发 LLM 应用。

![[AI Agent学习] MetaGPT源码浅析](https://img-blog.csdnimg.cn/img_convert/322697900ee16441f4327cea4f2926c0.png)