小T导读:为满足地震预警数据存储、检索和处理的建设与集成需求,以及响应国家国产软件自主可控的号召,中国地震台网中心决定选用国产数据库 TDengine 来存储和处理地震波形数据。本文将针对 TDengine 3.0 在地震领域的应用展开详细讲解。
关于企业:
中国地震台网中心是作为中国地震局直属的公益一类事业单位,是我国防震减灾工作的业务枢纽和国际交流窗口,是地震监测预报预警、应急响应和信息化工作的国家级业务中心。
项目背景
近年,随着国家对防震减灾要求不断提高,我国先后实施了多个大型地震监测工程项目。随着地震台站密集建设,台站仪器采集汇入中国地震台网中心的地震波形数据也增长了一个数量级。
地震波形数据主要是指由国家地震台站、各省区域地震台网等地震观测网络系统中地震计采集并传回中心的数据,具有典型的时序数据特征,是开展地震监测预警、数据分析与挖掘、地震异常研判等应用的基础材料。
为了满足地震预警数据存储、检索和处理的建设与集成需求,以及响应国家国产软件自主可控的号召,该项目选用国产数据库来存储和处理地震波形数据。
通过竞标,最终由 TDengine 承担该项目。
考虑到运维部署成本性能等等各个方面,数据库需要做好如下方面:
- 高效读写:承载每秒 500 万数据点的海量数据实时汇入,支持即席快速查询。
- 高数据压缩比:尽可能多的保存更多数据,同时减少磁盘存储成本。
- 时序分析:基于时间线的窗口化分析函数或工具。
- 弹性扩展:系统能够支持水平扩展,随着业务规模逐年扩大,弹性扩容以支持更高的数据接入量。
- 安全可靠:系统能够保证多副本存储和高可用,保证在单点故障时不影响正常使用。
- 冷热分离:对于新采集的数据和历史数据有一定归档能力,按照数据冷热程度分离存储。
- 可以对地震专业算法包集成:通过 UDF 方式,将地震专业信号处理算法集成至数据库中。
本文将以中国地震台网中心的项目作为主体展开(该项目用于全国范围的地震数据监控分析)。
业务架构
目前,该项目上使用的是 3.0.6.0 版本的 5 节点集群,单台服务器配置为:48CPU(s), 192GB 内存 ,500GB SSD + 1.2TB *6HDD 硬盘。
业务架构如下:
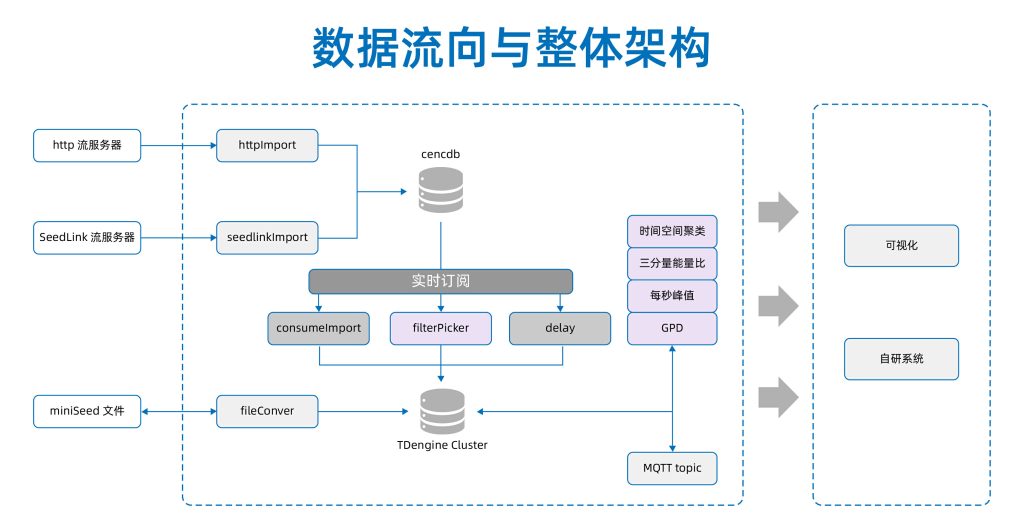
首先,每个地震仪一般会采集两个水平向,一个垂直向共三个通道(分量)的地震动数据,采样频率一般为 100HZ(10毫秒采样一次)。数据包中的数据通过工具解析之后会先过渡写入 cencdb 这个 TDengine 库当中,写入 cencdb 的同时, TDengine 的订阅功能会取出该数据包,并再次进行解析,获取更多层次的数据写入 TDengine 集群当中。
站点的位置由其所属台网代码、台站代码和测点位置号码决定。地震仪每天不间断的持续采集地震动数据,并每隔 0.5秒将数据打成 miniSEED 数据包传输,形成数据流。基于 TDengine “一个设备采集点一张表”的建模思路,每道数据流分别对应一张数据表和一张元数据表。
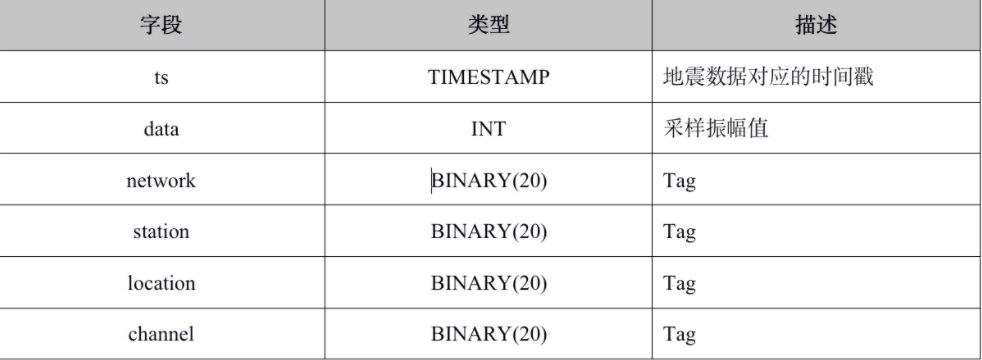
当前,该集群共有约 5.9 万张数据表,代表流入库中的 5.9 万道地震数据流。另外还有 5.9 万张元数据表(上图),存储 5.9 万道数据流中每个数据包的描述信息。
项目运行至今,TDengine 接入的原始数据包每天约 900GB,每秒大概接入超过 5 万个地震数据包,每天总数据量约 5000 亿条。
由于原始数据包已使用 STEM2 算法压缩,TDengine 压缩后的数据库文件与原数据包所占磁盘空间相当。对于常规的 INT 类型数据,TDengine 压缩比可达到 5%-10% 之间,对于 VARCHAR 类型的数据,压缩比可达到 15-20%,极大程度地节约存储成本。
在集群日常负载上,单台数据库服务端 CPU 使用率 40%~50%,内存占用 14%~20%,运行平稳。
具体应用
在地震监测领域,以下这些是比较常见的需求:
1.通过使用 SQL 查询 “XJ_BKO_00_H_H_Z”表,就可以得到该地震仪器垂直分量的振幅数据。
2.对地震数据包内的数据时间,与实际入库时间做差,可以统计到数据包入库的时延。因此,我们对元数据表执行如下 SQL ,就能得到超过 5 秒时延的异常数据用作进一步分析。
3.在地震数据中,地震波传播路径上会出现多个不同的震相。地震学家可以对这些震相的到达时间和振幅特征,对地震事件进行精确定位、震源机制分析等工作。其中在地震信号中准确地识别和捕捉特定震相的行为,便是震相拾取。
我们通过 TDengine 的 UDF (自定义函数)功能,把已经训练好的 GPD 模型直接同 TDengine 的流计算/SQL 结合起来,实现了震相拾取的实时计算。
建流语句:create stream gpd_stream trigger at_once into gpd_stream_stb as select ts, gpd(calc_ts, tbname, ‘detail’) from detail.pick partition by tbname;

4.同样是通过流计算,实现了实时计算上万个台站的每秒最大峰值,对流计算生成的表进行查询。
建流语句: create stream xxxxxxx into max_val_per_seconds_test subtable(concat(‘max_test_val_per_seconds-‘,tbname)) as select ts,max(data) as max_data from data where channel_3th=’Z’ partition by tbname interval(1s) sliding(1s);
可视化
在地震监控领域的可视化中,最重要的就是展示信息的完整性、实时性、可交互性,灵活性。
TDengine 高效的查询能力以及简单易用的 SQL 语句可以很方便的完成上述工作。通过网页展示工具调用 TDengine 的 SQL ,我们完成了展示地震事件的主看板:看板中的地图可以展示台站的每秒峰值记录,点击近期地震事件便可以进行一段时间(例如该地震发生时刻前 1min 和后2min)内的地震数据回放。

另外,由于 TDengine 可以和 Grafana 无缝对接,通过执行 SQL 即可完成数据可视化工作。该项目使用 Grafana 完成了另一部分数据的监控。
该场景是按台网分组,统计最近 5 分钟内的台站可用率。

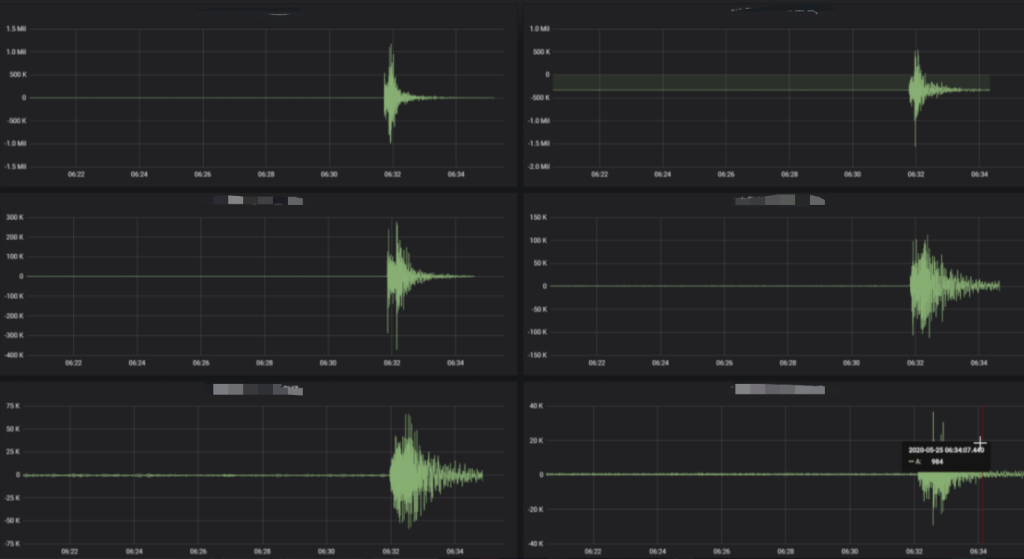
该场景是通过 SQL 查询某站台一段时间内的地震波原始数据,在 Grafana 中绘制出该时间段内该台站的地震波形图。
整体效果
此前,该项目通过程序进行基于 miniseed 文件的处理:简单来说是对 miniseed 数据按照日期、台站等维度进行分片,通过调用 python/C 程序加载 miniseed 文件做分析处理。
切换到 TDengine 之后,有很多变化:
- 不需要再维护繁多的 miniseed 文件,而是将他们解析成时间序列数据,在 TDengine 中分表存储,节省了使用者每次使用数据时解包的时间。
- 通过简单的 SQL 实现了快速的实时查询/展示/分析,降低了数据展示和查询的使用难度。
- 系统整体分布式扩展能力提升,通过增加节点的操作便可以应对未来可能快速增加的台站和数据。
- TDengine 时序数据库系统支持插件式业务函数集成,将成熟业务函数甚至机器学习训练模型以 UDF 方式内置到时序库系统中,进行流式处理,方便创新、扩展业务。
这些便是 TDengine 3.0 在地震领域的应用,在气象、环境、交通等等很多其他领域都会有类似的场景和需求。在人类社会的智能化发展正处于不断演进迭代的过程中,TDengine 将会扮演更多重要的角色。
注:文中所提及的 GPD 模型出自:https://github.com/interseismic/generalized-phase-detection
了解更多 TDengine Database的具体细节,可在GitHub上查看相关源代码。