位图
- 一.位图相关面试题
- 二.位图的设计及实现
- 三.C++库中的位图bitset
- 四.位图的优缺点
- 五.位图相关考察题目
一.位图相关面试题
问题:给40亿个不重复的无符号整数,没排过序。给一个无符号整数,如何快速判断一个数是否在这40亿个数中(本题为腾讯/百度等公司出过的一个面试题)
- 暴力遍历,时间复杂度O(N),太慢。
- 排序+⼆分查找。时间复杂度消耗O(N*logN)+O(logN)。深入分析:该思路是否可行,我们先算算40亿个数据大概需要多少内存。1G = 1024MB = 1024 * 1024KB = 1024 * 1024 * 1024Byte约等于10亿多Byte那么40亿个整数约等于16G,说明40亿个数是无法直接放到内存中的,只能放到硬盘文件中。而⼆分查找只能对内存数组中的有序数据进行查找。
- 数据是否在给定的整形数据中,结果是在或者不在,刚好是两种状态,那么可以使用一个二进制比特位来代表数据是否存在的信息,如果⼆进制比特位为1,代表存在,为0代表不存在。那么我们设计一个用位表示数据是否存在的数据结构,这个数据结构就叫位图。
二.位图的设计及实现
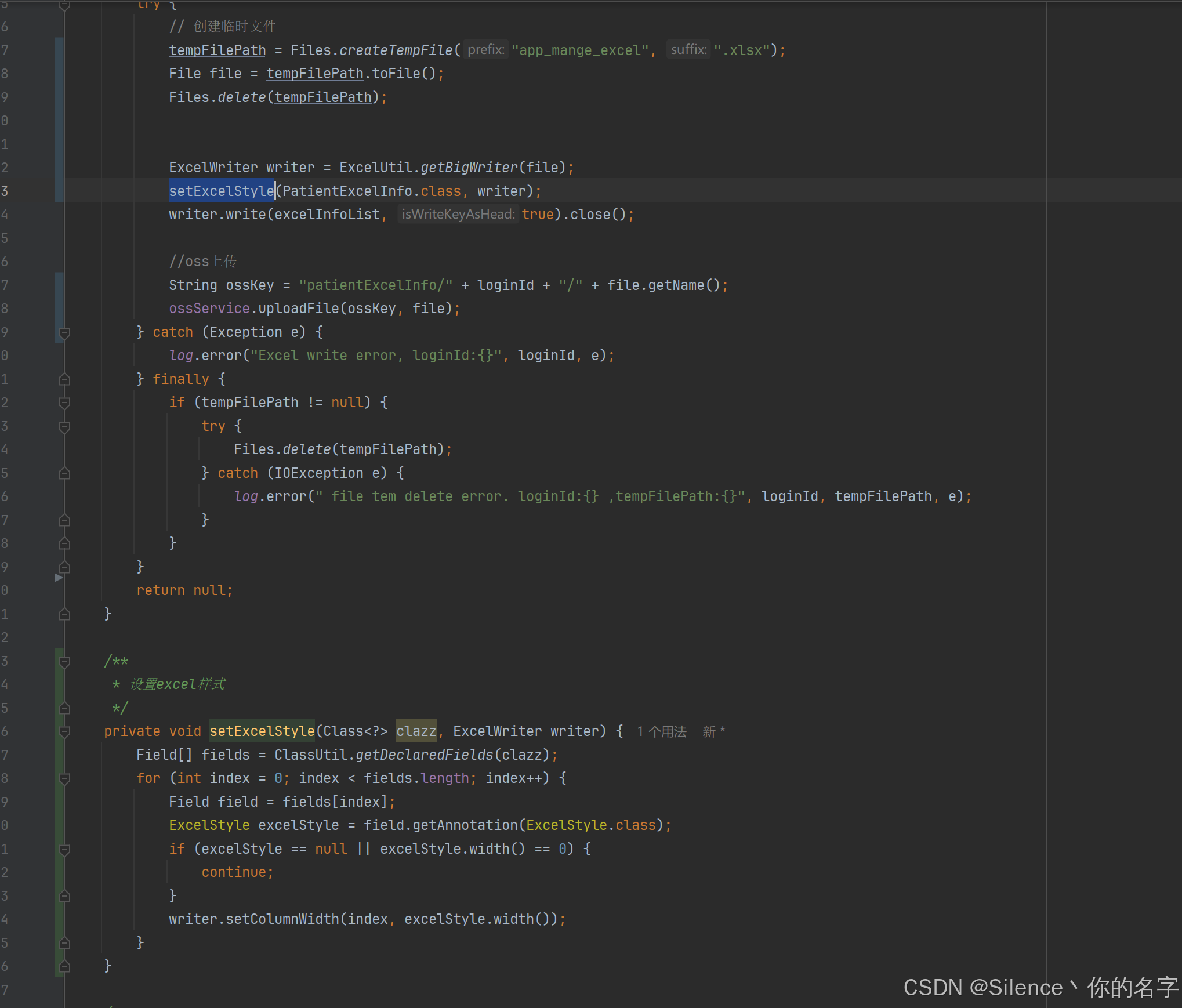
位图本质是一个直接定址法的哈希表,每个整型值映射一个bit位,位图提供控制这个bit的相关接口。

- 实现中需要注意的是,C/C++没有对应位的类型,只能看int/char这样整形类型,我们再通过位运算去控制对应的比特位。比如我们数据存到vector< int >中,相当于每个int值映射对应的32个值,比如第一个整形映射 0 ~ 31 对应的位,第二个整形映射 32 ~ 63 对应的位,后面的以此类推,那么来了一个整形值x,i=x/32;j=x%32;计算出x映射的值在vector的第i个整形数据的第j位。
- 解决给 40 亿个不重复的无符号整数,查找一个数据的问题,我们要给位图开 2 ^ 32 个位,注意不能开 40 亿个位,因为映射是按大小映射的,我们要按数据大小范围开空间,范围是是0 ~ 2 ^ 32 - 1,所以需要开 2 ^ 32 个位。然后从文件中依次读取每个数到位图中,然后就可以快速判断一个值是否在这 40 亿个数中了。
namespace xzy
{//非类型模版参数:N是需要多少比特位template<size_t N>class bitset{public:bitset(){_bs.resize(N / 32 + 1);}//x映射的位标记为1void set(size_t x){size_t i = x / 32;size_t j = x % 32;_bs[i] |= (1 << j);}//x映射的位标记为0void reset(size_t x){size_t i = x / 32;size_t j = x % 32;_bs[i] &= ~(1 << j);}//x映射的位是1返回真//x映射的位是0返回假bool test(size_t x){size_t i = x / 32;size_t j = x % 32;return _bs[i] & (1 << j);}private:vector<int> _bs;};
}int main()
{xzy::bitset<100> bs1;bs1.set(50);bs1.set(30);bs1.set(90);for (size_t i = 0; i < 100; i++){if (bs1.test(i)){cout << i << "->" << "在" << endl;}else{cout << i << "->" << "不在" << endl;}}bs1.reset(90);bs1.set(91);cout << endl << endl;for (size_t i = 0; i < 100; i++){if (bs1.test(i)){cout << i << "->" << "在" << endl;}else{cout << i << "->" << "不在" << endl;}}//开2^32个位的位图//bit::bitset<-1> bs2;//bit::bitset<UINT_MAX> bs3;//bit::bitset<0xffffffff> bs4;return 0;
}
三.C++库中的位图bitset
https://legacy.cplusplus.com/reference/bitset/bitset/
可以看到核心接口还是set/reset/和test,当然后面还实现了一些其他接口,如to_string将位图按位转
成01字符串,再包括operator[]等支持像数组一样控制一个位的实现。

int main()
{std::bitset<10000> bs1;cout << sizeof(bs1) << endl; //1256低层是静态数组array,开的太大容易栈溢出xzy::bitset<100> bs2;cout << sizeof(bs2) << endl; // 16低层是动态数组vector//解决方法:开到堆上面std::bitset<-1>* ptr = new std::bitset<-1>();ptr->set(10);ptr->reset(10);ptr->test(10);return 0;
}
四.位图的优缺点
- 优点:增删查改快,节省空间。
- 缺点:只适用于整形。
五.位图相关考察题目
- 题目:给定100亿个整数,我们只有1G内存,设计算法找到只出现一次的整数?设计算法找到出现次数不超过2次的所有整数?
- 答案:之前我们是标记在不在,只需要一个位即可,这里要统计出现次数不超过2次的,可以每个值用两个位标记即可,00代表出现0次,01代表出现1次,10代表出现2次,11代表出现2次以上。最后统计出所有01和10标记的值即可。
namespace xzy
{template<size_t N>class twobitset{public://00:出现0次//01:出现1次//10:出现2次//11:出现2次以上void set(size_t x){bool bit1 = _bs1.test(x);bool bit2 = _bs2.test(x);if (!bit1 && !bit2) //00->01{_bs2.set(x);}else if (!bit1 && bit2) //01->10{_bs1.set(x);_bs2.reset(x);}else if(bit1 && !bit2) //10->11{_bs2.set(x);}//11不变}//返回0:出现0次//返回1:出现1次//返回2:出现2次//返回3:出现2次以上int getcount(size_t x){bool bit1 = _bs1.test(x);bool bit2 = _bs2.test(x);if (!bit1 && !bit2) //00{return 0;}else if (!bit1 && bit2) //01{return 1;}else if (bit1 && !bit2) //10{return 2;}else //11{return 3;}}private:bitset<N> _bs1;bitset<N> _bs2;};
}int main()
{xzy::twobitset<100> tbs;int a[] = { 5,7,9,2,5,99,5,5,7,5,3,9,2,55,1,5,6,6,6,7,9,8,14,14,10 };for (auto e : a){tbs.set(e);}cout << "只出现一次的整数:";for (size_t i = 0; i < 100; ++i){if (tbs.getcount(i) == 1){cout << i << " ";}}cout << endl;cout << "出现次数不超过2次的所有整数:";for (size_t i = 0; i < 100; ++i){if (tbs.getcount(i) == 1 || tbs.getcount(i) == 2){cout << i << " ";}}return 0;
}
- 问题:给两个文件,分别有100亿个整数,我们只有1G内存,如何找到两个文件交集?
- 答案:把数据读出来,分别放到两个位图,依次遍历,同时在两个位图的值就是交集。
int main()
{int a1[] = { 5,7,9,2,5,99,5,5,7,5,3,9,2,55,1,5,6 };int a2[] = { 5,3,5,99,6,99,33,66 };bitset<100> bs1;bitset<100> bs2;for (auto e : a1){bs1.set(e);}for (auto e : a2){bs2.set(e);}for (size_t i = 0; i < 100; i++){if (bs1.test(i) && bs2.test(i)){cout << i << endl;}}return 0;
}