文章目录
- 一,pandas
- 1.1 pd.Series
- 1.2 pd.date_range
- 1.3 pd_DataFrame
- 1.4浏览数据
- 1.5布尔索引
- 1.6设置值
- 1.7操作
- 1.8合并
- 1.8.1concat()函数
- 1.8.2 merge()函数
一,pandas
1.1 pd.Series
pd.Series 是 Pandas 库中的一个数据结构,用于表示一维标签化的数据。它类似于 Python 中的列表或一维数组,但具有更丰富的功能和灵活性。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
s = pd.Series([1,2,3,np.nan,7,8])
s
0 1.0
1 2.0
2 3.0
3 NaN #np.nan是一个占位符
4 7.0
5 8.0
dtype: float641.2 pd.date_range
pd.date_range 是 Pandas 库中用于生成日期范围的函数。它可以方便地创建一系列连续的日期或时间戳,用于时间序列分析和日期处理。
默认以天为频率所以freq=‘D’
dates = pd.date_range('20231002',periods=7)
dates
DatetimeIndex(['2023-10-02', '2023-10-03', '2023-10-04', '2023-10-05','2023-10-06', '2023-10-07', '2023-10-08'],dtype='datetime64[ns]', freq='D')
dates[1]
Timestamp('2023-10-03 00:00:00', freq='D')
1.3 pd_DataFrame
pd.DataFrame 是 Pandas 库中用于创建和操作二维数据结构的主要对象之一。DataFrame 是一个表格型的数据结构,类似于电子表格或关系型数据库中的表,可以存储和处理具有行和列的数据
data提供数据,index是行索引,columns是列索引
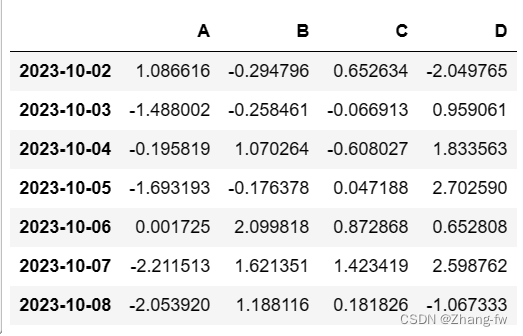
df = pd.DataFrame(data=np.random.randn(7,4),index=dates,columns=list('ABCD'))
df
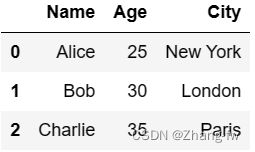
通过字典来创建
data = {'Name': ['Alice', 'Bob', 'Charlie'],'Age': [25, 30, 35],'City': ['New York', 'London', 'Paris']}df = pd.DataFrame(data)
df
1.4浏览数据
df = pd.DataFrame(data=np.random.randn(7,4),index=dates,columns=list('ABCD'))df.head(3) 查看前三行的数据
df.tail(3) 查看后三行的数据
df.index 查看行索引
df.columns 查看列索引
df.values 查看表格的值
df.describe() 查看表格的摘要
df.sort_index(axis=1, ascending=False)
axis=0是行索引1是列索引,ascending=False是降序,True是升序
df.sort_values(by='B', ascending=False)
by='B'是按照B列来排序,ascending=False是降序,True是升序df['A'] 选择单列产生Series,等效于df.A
df[0:3] 通过切片选择行
df.loc[dates[0]] == df.loc['20231002'] 行索引是dates,输出的是第一行的值
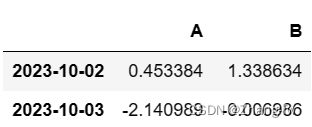
df.loc[[dates[0],dates[1]],['A','B']] 可以选择多行多列的数据来查看
df.iloc[n] 直接获取第n行
df.iloc[3:5,2:4] 直接获取3-4行,2-3列的值
1.5布尔索引
df[df.A>0] 会把A列中大于0的行全部输出
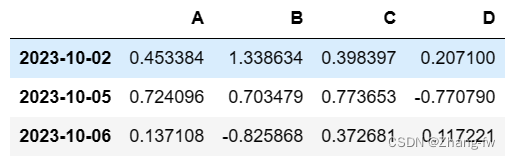
df[(df.A>0) & (df.B<0)] 把A列大于0同时B列小于0的行输出
df.isin() 检查 DataFrame 中的元素是否属于指定的值或列表。
1.6设置值
df.at[dates[0],'A'] = 0 设置指定的元素的值
df.iat[0,1] = 0 设置指定的行列的值
df.reindex(index = dates[0:8],columns=list(df.columns)+['E'])
新加一列E列
df.loc[[dates[0],dates[1]],'E'] = 1 给E列的前两行添加元素
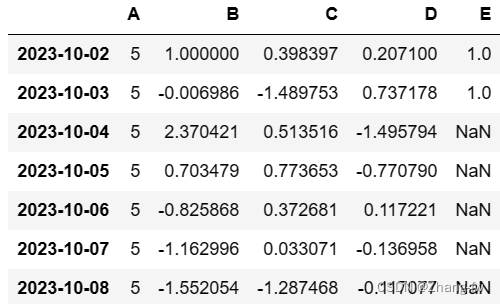
df.dropna(how='any') 删除任何含有Nan的行和列
df.fillna(value = n) 返回一个新对象,把所有的Nan填充成5
pd.isnull(df) 判断每个元素或者行或列是不是Nan
1.7操作
df.mean(axis=n) 求取平均值,n=0是列,n=1是行默认是0
df.apply(function) 用于对表格的行或列应用一个函数(可以是自己定义的),以生成新的数据。
df.
1.8合并
1.8.1concat()函数
pd.concat(objs, axis=0, join='outer', ignore_index=False)
说明
objs 是要连接的 DataFrame 对象的序列,可以是列表、元组或字典。
axis 是指定连接轴的参数,axis=0 表示沿行方向连接,axis=1 表示沿列方向连接,默认为 axis=0。
join 是指定连接方式的参数,join=‘outer’ 表示取并集,join=‘inner’ 表示取交集,默认为 join=‘outer’。
ignore_index 是一个布尔值,表示是否忽略原始索引并生成新的索引,默认为 ignore_index=False。
示例
pieces = [df[:3],df[3:7],df[7:]]
pieces

pd.concat(pieces)

1.8.2 merge()函数
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=True)
left 和 right 是要合并的两个 DataFrame 对象。
how 是合并方式,可以是 ‘inner’(内连接)、‘outer’(外连接)、‘left’(左连接)或 ‘right’(右连接)。默认为 ‘inner’。
on 是用于连接的列名。如果两个 DataFrame 的列名相同,则可以使用 on 参数指定列名进行连接。
left_on 和 right_on 是用于连接的左右 DataFrame 的列名。可以使用这两个参数指定各自 DataFrame 中的列名进行连接。
left_index 和 right_index 是一个布尔值,表示是否使用左右 DataFrame 的索引进行连接。
sort 是一个布尔值,表示是否根据连接键进行排序。
df1 = pd.DataFrame({'A': [1, 2],'B': [3, 4]})df2 = pd.DataFrame({'A': [2, 3],'C': [5, 6]})# 使用列进行内连接
merged_df = pd.merge(df1, df2, on='A', how='inner')
print(merged_df)#执行结果A B C
0 2 4 5