论文题目:Enhanced Training of Query-Based Object Detection via Selective Query Recollection

代码:https://github.com/Fangyi-Chen/SQR

作者在知乎的导读:https://zhuanlan.zhihu.com/p/610347565
导读
传统目标检测方法需要大量手工处理步骤,限制了端到端优化。这篇论文探索了一个引人注目的领域——查询式目标检测。在查询式目标检测中,模型在解码过程的不同阶段表现出不同的预测准确度。这涉及到查询式目标检测中的一个难题:在预测目标目标时,随着解码过程的深入进行,后期解码阶段出现错误的情况,而中间解码阶段则能够准确预测。
论文提出了两个关键问题:一是不同阶段的训练负担分配不均衡,二是解码器的顺序结构导致中间查询的修正会级联到后续阶段,增加了训练的难度。为了解决这些问题,本文引入了"Selective Query Recollection (SQR)"作为一种训练策略,它通过积累中间查询并有选择地将它们提供给后续阶段,以改进训练效果。这种策略成功解决了查询式目标检测中的性能问题,为实现更准确的目标检测技术提供了新思路和方法。
本文贡献
定量研究问题现象:论文首次详细研究了查询式目标检测中的一个重要现象,即模型在解码过程的不同阶段出现不同的预测准确度。本文通过实验和数据分析,定量地表现了这一现象,为进一步的研究提供了基础。
识别训练限制:论文指出,这一被忽视的现象源于两个训练方面的限制:不同阶段的训练负担分配不均衡,以及解码器的顺序结构导致中间查询的修正会级联到后续阶段,增加了训练的难度。
提出有效的训练策略 SQR:为解决上述问题,论文提出了"Selective Query Recollection (SQR)"作为一种训练策略。SQR通过积累中间查询并有选择地将它们提供给后续阶段,改进了模型的训练效果。这种策略在不增加推理计算成本的情况下,显著提高了查询式目标检测的性能。
实验验证:论文通过在多个实验设置下对不同的查询式目标检测模型进行测试,验证了SQR策略的有效性。实验结果表明,SQR显著提高了模型的性能,带来了1.4到2.8的平均精度(AP)提升。
相关工作
目标检测的训练策略: 传统的目标检测方法通常基于密集的先验信息,如锚点或锚点框,用于匹配地面真实目标目标,依赖于它们的IoU值或其他软性评分因子。多阶段模型会逐阶段地迭代地完善边界框和类别。举个例子,Cascade RCNN采用了中间阶段的输出来训练下一阶段,其中IoU阈值逐渐增加,以确保逐步完善目标检测结果。最近的DETR 则将目标检测视为一种集合预测问题,通过匹配一定数量的目标查询来训练模型,并通过多个解码阶段逐步完善查询。
查询式目标检测: 近年来,许多算法开始采用了DETR的思想,将查询式目标检测作为一种新的范式。这些方法包括Deformable DETR、Conditional DETR、Anchor-DETR、DAB-DETR、DN-DETR、Adamixer等。它们引入了不同的变体和改进,如使用可变形注意力模块、解耦查询、使用锚点等,以改善模型的性能和收敛速度。
本文方法
论文希望设计一种训练策略,满足以下期望:
不均匀的监督分配,着重强调后期解码阶段,以改善最终结果。
将多样的早期查询直接引入后期阶段,减轻级联错误的影响。
为此,我们设计了一种简明的训练策略,称为query recollection(QR)。与现有技术相比,它在每个阶段收集中间查询,并沿着原始路径转发它们。Dense Query Recollection (DQR)是一种基本形式,而 Selective Query Recollection (SQR) 是一种高级变体。
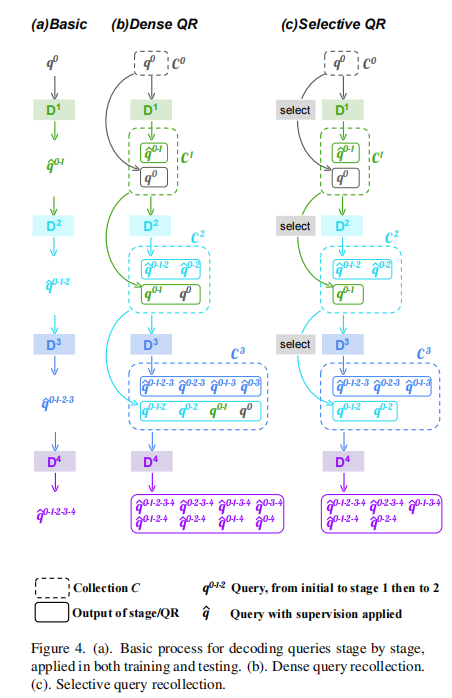
Dense Query Recollection
符号表示:论文使用了一组查询
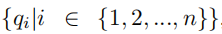
基本路径:论文引入了基本路径的概念,其中查询通过所有解码阶段进行改进。以一个包含 4 个阶段的解码器为例,我们可以表示 为最终查询,它在所有阶段中得到改进。这个基本路径的计算方式是通过级联应用每个阶段的改进,如公式 (3) 和 (4) 所示。
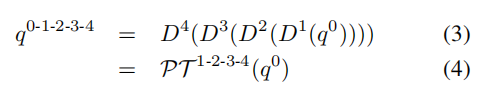
DQR 的形式化:DQR 密集地收集每个中间查询,并将它们独立传递给每个后续阶段。在每个阶段之后,形成一个集合 C,其中查询的数量呈几何级数增长,每个集合都包含前一阶段的查询以及当前阶段生成的一半查询。这种方式确保了每个阶段的监督信号数量成倍增长,如 (6) 所示。
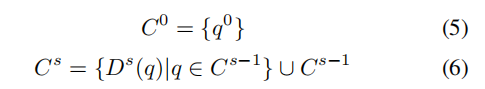
推断过程: 在推断阶段,仅使用基本路径,不影响推断过程。对于标准的 6 阶段解码器,推断路径是:
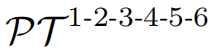
DQR通过在每个阶段紧密收集中间查询(queries)并将它们独立地传递给后续阶段,从而构建了一个集合(collection),其中查询的数量呈几何级数增长。这样可以实现监督信号数量随阶段增加而成倍增长,并且确保先前的查询在后续阶段都可见。
Selective Query Recollection
作者认为 Dense Query Recollection 存在两个问题:计算成本高和跨越太多阶段的查询可能会产生负面影响。因此,Selective Query Recollection 提出了一种更为智能的查询收集方法。SQR根据具体情况选择在每个阶段引入查询,考虑了查询对目标的贡献。这样,SQR能够减少计算负担,同时提高性能。
为了找到更好的Query Recollection方案,作者在第3节中引入的TP衰减率和FP加剧率进行了详细分析。他们发现,大多数更好的替代方案都来自第4和第5阶段,这两个阶段的TP衰减率和FP加剧率分别达到了23.9%和40.8%,接近第1到5阶段的结果,而第1到3阶段仅产生了11.2%和32.4%。这表明来自相邻阶段和相邻阶段之前的查询更有可能带来积极效果。
在每个阶段 Ds 开始之前,从距离最近的两个阶段(Ds-1 和 Ds-2)中收集查询,然后将它们作为Ds 的输入。
SQR的形式化:
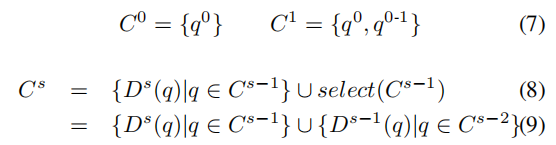
Selective Query Recollection的效果:
Selective Query Recollection 仍然满足预期,监督信号的数量呈现斐波那契数列增长(1,2,3,5,8,13)。与密集查询回收相比,SQR在很大程度上减少了计算负担,并且在精度方面甚至表现出色于密集回收。这验证了作者的假设,即跳过太多阶段的查询可能对远程阶段产生噪声,掩盖了其积极效果。
Recollection 起始阶段:除了从第1阶段开始收集查询,还可以根据实际需求变化起始阶段,从而进一步减少每个集合中的总查询数量,减轻计算负担。这可以视为选择性查询回收的一个超参数。
实验
实验结果
与SOTA的比较,如表格8:
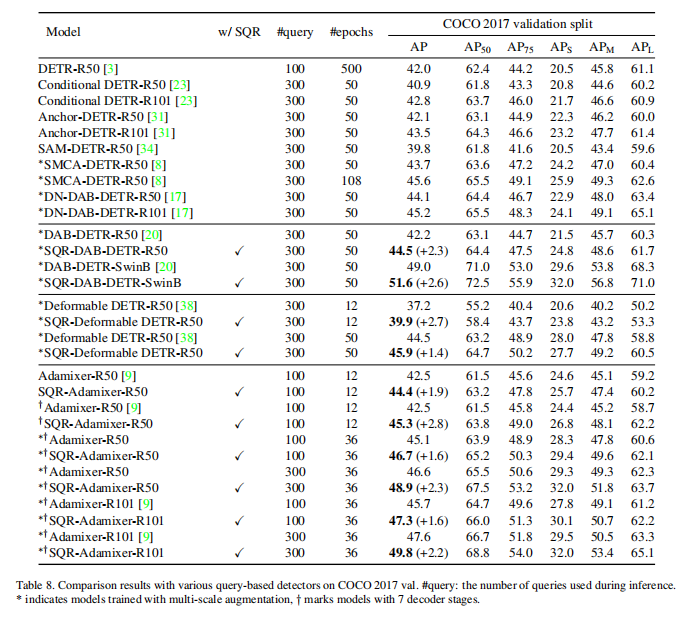
在DAB-DETR上,SQR分别在R50和SwinB下提高了+2.3和+2.6的AP
在Deformable-DETR上,在12e下SQR提高了2.7的AP,在50e下提高了1.4的AP
在R50上的Adamixer中,SQR在基本设置下(100个查询,12e)实现了+1.9的AP
通过添加一个额外的阶段,有/无SQR之间的差距增大了+2.8 AP
消融实验
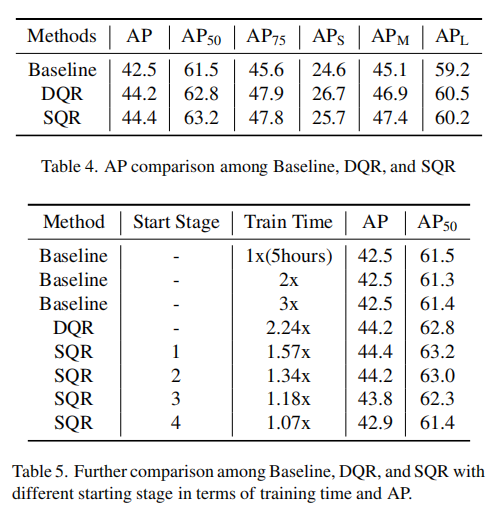
基线与DQR与SQR的比较:表格4显示,无论是DQR还是SQR都大幅提高了基线性能。DQR 达到了 44.2(+1.7 AP),而SQR 达到了稍高的结果 44.4(+1.9 AP)。需要注意的是,SQR远比DQR高效。表格5显示,在相同的训练设置下,SQR减少了大量的训练时间,仍然实现了相等或更高的AP。
SQR的起始阶段变化:作者在表格5中呈现了SQR在改变起始阶段时的性能表现。当查询回收从第1阶段开始时,获得了最佳性能,但计算成本最高。可以看到,从第2阶段开始性能类似于从第1阶段开始,但计算负担适度减少。随着回收开始得更晚,由于从早期阶段回收的查询数量减少,训练重点逐渐平衡,SQR的好处如预期的那样减少。
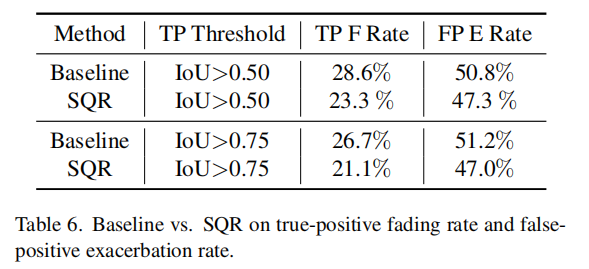
表格6用于验证应用SQR后,TP 衰减率和 FP 加剧率的减小,这是由于训练效果造成的。
结论
在这项工作中,我们研究了基于查询的目标检测器的最佳检测结果并不总是来自最后的解码阶段的现象,有时候可以来自中间解码阶段。我们首先识别了引起这个问题的两个限制,即缺乏训练重点和来自查询序列的级联错误。我们通过选择性查询回收(SQR)作为一种简单而有效的训练策略来解决这个问题。在各种训练设置下,SQR显著提高了Adamixer、DAB-DETR和Deformable-DETR的性能。
☆ END ☆
如果看到这里,说明你喜欢这篇文章,请转发、点赞。微信搜索「uncle_pn」,欢迎添加小编微信「 woshicver」,每日朋友圈更新一篇高质量博文。
↓扫描二维码添加小编↓