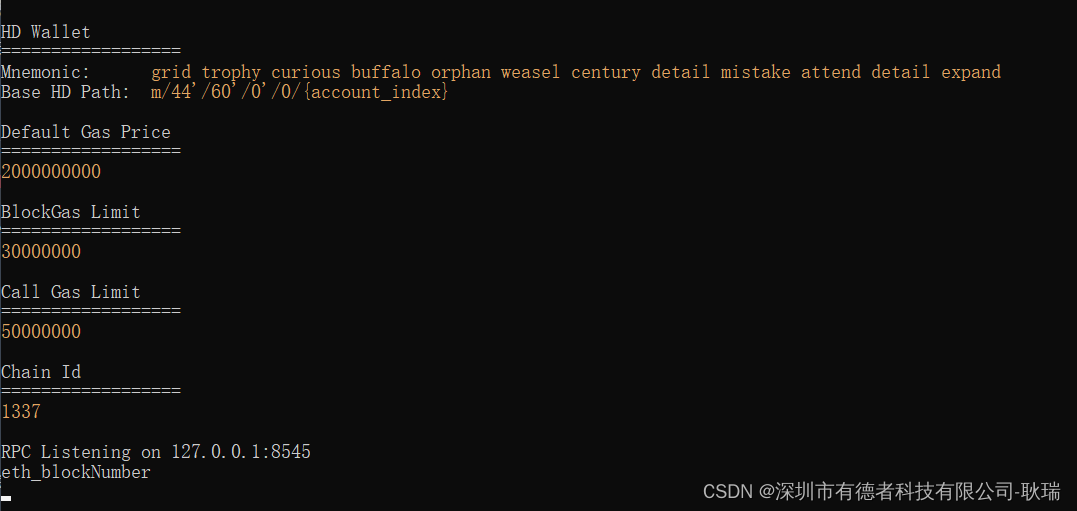
AI视野·今日CS.NLP 自然语言处理论文速览
Tue, 3 Oct 2023 (showing first 100 of 110 entries)
Totally 100 papers
👉上期速览✈更多精彩请移步主页

Daily Computation and Language Papers
| It's MBR All the Way Down: Modern Generation Techniques Through the Lens of Minimum Bayes Risk Authors Amanda Bertsch, Alex Xie, Graham Neubig, Matthew R. Gormley 最小贝叶斯风险 MBR 解码是一种选择机器学习系统输出的方法,它不是基于概率最高的输出,而是基于多个候选中风险期望误差最低的输出。这是一种简单但功能强大的方法,在推理时会产生额外的成本,MBR 为各种任务的指标提供了可靠的多点改进,而无需任何额外的数据或培训。尽管如此,MBR 在 NLP 工作中的应用并不频繁,而且对该方法本身的了解也很有限。我们首先介绍该方法和最新文献。我们表明,最近几种不引用 MBR 的方法可以写成 MBR 的特殊情况,这种重新表述为这些方法的性能提供了额外的理论依据,解释了以前仅凭经验得出的一些结果。 |
| Who is ChatGPT? Benchmarking LLMs' Psychological Portrayal Using PsychoBench Authors Jen tse Huang, Wenxuan Wang, Eric John Li, Man Ho Lam, Shujie Ren, Youliang Yuan, Wenxiang Jiao, Zhaopeng Tu, Michael R. Lyu 大语言模型法学硕士最近展示了他们非凡的能力,不仅在自然语言处理任务方面,而且在临床医学、法律咨询和教育等不同领域。法学硕士不再仅仅是应用程序,而是能够满足不同用户请求的助手。这缩小了人类和人工智能代理之间的区别,引发了关于法学硕士的个性、气质和情感的潜在表现的有趣问题。在本文中,我们提出了一个框架 PsychoBench,用于评估法学硕士的不同心理方面。 PsychoBench 包含临床心理学中常用的十三个量表,并将这些量表进一步分为四个不同的类别:人格特质、人际关系、动机测试和情绪能力。我们的研究检查了五种流行的模型,即 texttt text davinci 003 、 ChatGPT、GPT 4、LLaMA 2 7b 和 LLaMA 2 13b。此外,我们采用越狱方法来绕过安全调整协议并测试法学硕士的内在本质。 |
| Compressing LLMs: The Truth is Rarely Pure and Never Simple Authors Ajay Jaiswal, Zhe Gan, Xianzhi Du, Bowen Zhang, Zhangyang Wang, Yinfei Yang 尽管取得了非凡的成就,现代大型语言模型法学硕士仍面临着过高的计算和内存占用。最近,一些工作在 LLM 的无训练和无数据压缩剪枝和量化方面取得了巨大成功,实现了 50 60 稀疏性,并将位宽度减少到每个权重 3 或 4 位,与未压缩基线相比,困惑度下降可以忽略不计。由于最近的研究工作集中在开发日益复杂的压缩方法上,我们的工作退后一步,重新评估现有 SoTA 压缩方法的有效性,这些方法依赖于一个相当简单且受到广泛质疑的指标,即使对于密集的 LLM 来说也是如此。我们引入了知识密集型压缩LLM BenchmarK LLM KICK,这是一系列精心策划的任务,旨在重新定义压缩LLM的评估协议,这些任务与其密集的对应项具有显着的一致性,并且困惑无法捕捉到其真实能力的微妙变化。 LLM KICK 揭示了当前 SoTA 压缩方法的许多优点和不幸的困境 所有剪枝方法都会遭受显着的性能下降,有时在稀疏度很小的情况下,例如 25 30 ,并且在知识密集型任务上无法实现 N M 稀疏性 当前的量化方法比剪枝更成功,即使在 geq 50 稀疏度下,修剪后的 LLM 在上下文检索和摘要系统等中也具有鲁棒性。 LLM KICK 旨在全面访问压缩的 LLM 语言理解、推理、生成、上下文检索、上下文摘要等能力。我们希望我们的研究能够促进更好的 LLM 压缩方法的开发。 |
| UltraFeedback: Boosting Language Models with High-quality Feedback Authors Ganqu Cui, Lifan Yuan, Ning Ding, Guanming Yao, Wei Zhu, Yuan Ni, Guotong Xie, Zhiyuan Liu, Maosong Sun 根据人类反馈进行强化学习 RLHF 已成为使大型语言模型 LLM 与人类偏好保持一致的关键技术。在 RLHF 实践中,偏好数据在连接人类倾向和法学硕士方面发挥着至关重要的作用。然而,人类对 LLM 输出的偏好的多样化、自然主义数据集的稀缺给 RLHF 以及开源社区内的反馈学习研究带来了巨大的挑战。当前的偏好数据集,要么是专有的,要么是大小和种类有限,导致 RLHF 在开源模型中的采用有限,并阻碍了进一步的探索。在这项研究中,我们提出了 ULTRAFEEDBACK,这是一个大规模、高质量和多样化的偏好数据集,旨在克服这些限制并促进 RLHF 的发展。为了创建 ULTRAFEEDBACK,我们编译了来自多个来源的各种指令和模型以生成比较数据。我们精心设计注释指令并使用 GPT 4 以数字和文本形式提供详细的反馈。 ULTRAFEEDBACK 建立了一个可重复且可扩展的偏好数据构建管道,为未来的 RLHF 和反馈学习研究奠定了坚实的基础。利用ULTRAFEEDBACK,我们训练了各种模型来证明其有效性,包括奖励模型UltraRM、聊天语言模型UltraLM 13B PPO和批评模型UltraCM。实验结果表明,我们的模型优于现有的开源模型,在多个基准测试中实现了最佳性能。 |
| RA-DIT: Retrieval-Augmented Dual Instruction Tuning Authors Xi Victoria Lin, Xilun Chen, Mingda Chen, Weijia Shi, Maria Lomeli, Rich James, Pedro Rodriguez, Jacob Kahn, Gergely Szilvasy, Mike Lewis, Luke Zettlemoyer, Scott Yih 检索增强语言模型 RALM 通过从外部数据存储访问长尾和最新知识来提高性能,但构建起来具有挑战性。现有方法要么需要对 LM 预训练进行昂贵的检索特定修改,要么使用数据存储的事后集成,从而导致性能不佳。我们推出检索增强双指令调优 RA DIT,这是一种轻量级微调方法,通过对任何法学硕士进行检索功能改造,提供了第三种选择。我们的方法通过两个不同的微调步骤进行操作:1 更新预训练的 LM 以更好地使用检索到的信息,而 2 另一个更新检索器以返回更相关的结果,这是 LM 的首选。通过对需要知识利用和上下文感知的任务进行微调,我们证明每个阶段都会产生显着的性能改进,并且使用两者会带来额外的收益。我们的最佳模型 RA DIT 65B 在一系列知识密集型零射击和少射击学习基准中实现了最先进的性能,显着优于现有的 RALM 方法,平均在 0 射击设置中达到 8.9,在 5 射击设置中平均达到 1.4 |
| Improving Dialogue Management: Quality Datasets vs Models Authors Miguel ngel Medina Ram rez, Cayetano Guerra Artal, Mario Hern ndez Tejera 面向任务的对话系统 TODS 对于用户使用自然语言与机器和计算机交互至关重要。其关键组件之一是对话管理器,它通过提供最佳响应来引导对话朝着用户的良好目标发展。之前的工作提出了基于规则的系统 RBS 、强化学习 RL 和监督学习 SL 作为正确对话管理的解决方案,换句话说,选择用户输入的最佳响应。然而,这项工作认为,DM 未能实现最大性能的主要原因在于数据集的质量,而不是迄今为止所使用的模型,这意味着数据集错误(如标签错误)是对话管理失败的很大一部分原因。我们研究了最广泛使用的数据集 Multiwoz 2.1 和 SGD 中的主要错误,以证明这一假设。为此,我们设计了一个合成对话生成器来完全控制数据集中引入的错误的数量和类型。 |
| BTR: Binary Token Representations for Efficient Retrieval Augmented Language Models Authors Qingqing Cao, Sewon Min, Yizhong Wang, Hannaneh Hajishirzi 检索增强解决了大型语言模型中的许多关键问题,例如幻觉、陈旧性和隐私泄露。然而,由于要处理大量检索到的文本,运行检索增强语言模型 LM 速度缓慢且难以扩展。我们引入了二进制标记表示 BTR ,它使用 1 位向量来预先计算段落中的每个标记,从而显着减少推理过程中的计算量。尽管可能会损失准确性,但我们的新校准技术和培训目标可以恢复性能。结合离线和运行时压缩,仅需要 127GB 磁盘空间即可编码维基百科中的 30 亿个令牌。 |
| On the Generalization of Training-based ChatGPT Detection Methods Authors Han Xu, Jie Ren, Pengfei He, Shenglai Zeng, Yingqian Cui, Amy Liu, Hui Liu, Jiliang Tang ChatGPT 是最流行的语言模型之一,它在各种自然语言任务上取得了惊人的性能。因此,也迫切需要检测由人类书写生成的 ChatGPT 文本。广泛研究的方法之一是训练分类模型来区分两者。然而,现有的研究也表明,经过训练的模型在测试过程中可能会出现分布变化,即它们无法有效地预测从未见过的语言任务或主题生成的文本。在这项工作中,我们的目标是对这些方法在由多种因素(包括提示、文本长度、主题和语言任务)引起的分布转移下的泛化行为进行全面的研究。为了实现这一目标,我们首先收集包含人类和 ChatGPT 文本的新数据集,然后对收集的数据集进行广泛的研究。 |
| Generating Explanations in Medical Question-Answering by Expectation Maximization Inference over Evidence Authors Wei Sun, Mingxiao Li, Damien Sileo, Jesse Davis, Marie Francine Moens 医疗问答系统在帮助医护人员寻找问题答案方面发挥着重要作用。然而,仅通过医学 QA 系统提供答案是不够的,因为用户可能需要解释,即用自然语言进行更多分析性陈述,描述支持答案的元素和上下文。为此,我们提出了一种新方法,为医学 QA 系统预测的答案生成自然语言解释。由于高质量的医学解释需要额外的医学知识,因此我们的系统从医学教科书中提取知识,以在解释生成过程中提高解释的质量。具体来说,我们设计了一种期望最大化方法,可以对这些文本中发现的证据进行推断,提供一种有效的方法来将注意力集中在冗长的证据段落上。在两个数据集 MQAE diag 和 MQAE 上进行的实验结果证明了我们的文本证据推理框架的有效性。 |
| Knowledge Crosswords: Geometric Reasoning over Structured Knowledge with Large Language Models Authors Wenxuan Ding, Shangbin Feng, Yuhan Liu, Zhaoxuan Tan, Vidhisha Balachandran, Tianxing He, Yulia Tsvetkov 大语言模型法学硕士在知识密集型任务中被广泛采用,并凭借其知识能力取得了令人印象深刻的表现。虽然法学硕士在原子或线性多跳 QA 任务上表现出了出色的性能,但它们是否能够在具有交织约束的知识丰富的场景中进行推理仍然是一个尚未充分探索的问题。在这项工作中,我们提出了对结构化知识的几何推理,其中知识片段以图结构连接,模型需要填充缺失的信息。这种几何知识推理需要具有处理结构化知识、不确定性推理、验证事实以及在发生错误时回溯的能力。我们提出了 Knowledge Crosswords,这是一个多空白 QA 数据集,其中每个问题都由代表不完整实体网络的几何约束的自然语言问题组成,其中法学硕士的任务是在满足所有事实约束的同时找出缺失的实体。知识填字游戏包含2,101个单独的问题,涵盖各个知识领域,并进一步分为三个难度级别。我们进行了大量的实验,以评估知识填字游戏基准上现有的法学硕士激励方法。我们还提出了两种新方法:分阶段提示和验证全部,以增强法学硕士回溯和验证结构化约束的能力。我们的结果表明,虽然基线方法在解决较简单的问题时表现良好,但在解决困难问题时表现不佳,但我们提出的“全部验证”在很大程度上优于其他方法,并且在解决困难问题时更加稳健。 |
| LEEC: A Legal Element Extraction Dataset with an Extensive Domain-Specific Label System Authors Xue Zongyue, Liu Huanghai, Hu Yiran, Kong Kangle, Wang Chenlu, Liu Yun, Shen Weixing 作为自然语言处理的关键任务,元素提取在法律领域具有重要意义。从司法文书中提取法律要素有助于增强法律案件的解释和分析能力,从而促进下游在各个法律领域的广泛应用。然而,现有的元素提取数据集因其对法律知识的访问受限和标签覆盖范围不足而受到限制。为了解决这一不足,我们引入了更全面、大规模的犯罪分子提取数据集,包括 15,831 份司法文件和 159 个标签。该数据集的构建主要分为两个步骤:第一,由我们的法律专家团队根据前期法律研究设计标签系统,识别出刑事案件中影响量刑结果的关键驱动因素和过程;第二,运用法律知识,根据法律知识对司法文书进行标注。标签系统和注释指南。法律要素提取数据集 LEEC 代表了中国法律体系最广泛且特定领域的法律要素提取数据集。利用带注释的数据,我们采用了各种 SOTA 模型来验证 LEEC 对于文档事件提取 DEE 任务的适用性。 |
| SPELL: Semantic Prompt Evolution based on a LLM Authors Yujian Betterest Li, Kai Wu 即时工程是增强经过训练的神经网络模型性能的新范例。为了优化文本样式提示,现有方法通常对文本的一小部分逐级进行单独操作,这要么破坏流畅性,要么无法全局调整提示。由于大型语言模型LLM具有逐个标记生成连贯文本的强大能力,我们是否可以利用LLM来改进提示基于此动机,在本文中,将经过训练的LLM视为文本生成器,我们尝试设计一种黑盒进化算法用于自动优化文本,即基于 LLM 的 SPELL Semantic Prompt Evolution 。所提出的方法在不同的文本任务中使用不同的 LLM 和进化参数进行评估。实验结果表明SPELL确实可以快速改善提示效果。 |
| Improving Emotional Expression and Cohesion in Image-Based Playlist Description and Music Topics: A Continuous Parameterization Approach Authors Yuelyu Ji, Yuheng Song, Wei Wang, Ruoyi Xu, Zhongqian Xie, Huiyun Liu 基于图像的平台中的文本生成,特别是音乐相关内容,需要精确控制文本样式并融入情感表达。然而,现有方法通常需要帮助控制生成文本中外部因素的比例,并且依赖于离散输入,缺乏所需文本生成的连续控制条件。本研究提出了受控文本生成 CPCTG 的连续参数化来克服这些限制。我们的方法利用语言模型 LM 作为风格学习器,整合语义凝聚力 SC 和情感表达比例 EEP 考虑因素。 |
| Label Supervised LLaMA Finetuning Authors Zongxi Li, Xianming Li, Yuzhang Liu, Haoran Xie, Jing Li, Fu lee Wang, Qing Li, Xiaoqin Zhong 大型语言模型法学硕士最近的成功引起了学术界和工业界的广泛关注。通过微调,我们已经做出了大量努力来增强开源 LLM 的零样本和少样本泛化能力。目前,流行的方法是指令调整,它通过在自然语言指令的指导下生成响应来训练法学硕士完成现实世界的任务。值得注意的是,这种方法在序列和标记分类任务中可能表现不佳。与文本生成任务不同,分类任务的标签空间有限,其中精确的标签预测比生成多样化且类似人类的响应更受欢迎。先前的研究表明,指令调整的 LLM 无法超越 BERT,这促使我们探索利用 LLM 的潜在表示进行监督标签预测的潜力。在本文中,我们介绍了法学硕士的标签监督适应,其目的是使用判别标签来微调模型。我们使用基于 LLaMA 2 7B(规模相对较小的 LLM)的标签监督 LLaMA LS LLaMA 来评估这种方法,并且可以在单个 GeForce RTX4090 GPU 上进行微调。我们从最终的 LLaMA 层中提取潜在表示并将其投影到标签空间中以计算交叉熵损失。该模型通过低秩适应 LoRA 进行微调,以最大限度地减少这种损失。值得注意的是,在没有复杂的即时工程或外部知识的情况下,LS LLaMA 在规模上远远超过了法学硕士十倍,并且与 BERT Large 和 RoBERTa Large 等稳健的基线相比,在文本分类方面表现出了一致的改进。此外,通过从解码器中删除因果掩码,LS unLLaMA 在命名实体识别 NER 中实现了最先进的性能。 |
| appjsonify: An Academic Paper PDF-to-JSON Conversion Toolkit Authors Atsuki Yamaguchi, Terufumi Morishita 我们推出了 appjsonify,一个基于 Python 的学术论文 PDF 到 JSON 转换工具包。它使用多种基于视觉的文档布局分析模型和基于规则的文本处理方法来解析 PDF 文件。 appjsonify 是一个灵活的工具,允许用户轻松配置处理管道来处理他们希望处理的特定格式的纸张。 |
| Quantifying the Plausibility of Context Reliance in Neural Machine Translation Authors Gabriele Sarti, Grzegorz Chrupa a, Malvina Nissim, Arianna Bisazza 确定语言模型是否能够以人类合理的方式使用上下文信息对于确保其在现实世界环境中的安全采用非常重要。然而,上下文何时以及哪些部分影响模型生成的问题通常是单独解决的,并且当前的合理性评估实际上仅限于少数人为基准。为了解决这个问题,我们引入了上下文依赖的合理性评估 PECoRe,这是一个端到端的可解释性框架,旨在量化语言模型生成中的上下文使用情况。我们的方法利用模型内部结构来对比识别生成文本中的上下文敏感目标标记,并将它们链接到证明其预测合理的上下文线索。我们使用 PECoRe 来量化上下文感知机器翻译模型的合理性,将模型基本原理与多个话语层面现象的人类注释进行比较。 |
| Target-Aware Contextual Political Bias Detection in News Authors Iffat Maab, Edison Marrese Taylor, Yutaka Matsuo 媒体偏见检测需要全面整合来自多个新闻来源的信息。新闻中的句子级政治偏见检测也不例外,并且已被证明是一项具有挑战性的任务,需要考虑上下文来理解偏见。受人类表现出不同程度的写作风格这一事实的启发,导致在不同的本地和全球背景下产生各种各样的陈述,之前媒体偏见检测的工作提出了利用这一事实的增强技术。尽管取得了成功,但我们观察到这些技术通过过度概括偏差上下文边界而引入噪声,从而影响性能。为了缓解这个问题,我们提出了使用偏差敏感、目标感知的数据增强方法来更仔细地搜索上下文的技术。对众所周知的 BASIL 数据集的综合实验表明,当与 BERT 等预训练模型相结合时,我们的增强技术可以带来最先进的结果。 |
| Automated Evaluation of Classroom Instructional Support with LLMs and BoWs: Connecting Global Predictions to Specific Feedback Authors Jacob Whitehill, Jennifer LoCasale Crouch 为了向教师提供有关其教学的更具体、更频繁和可操作的反馈,我们探索如何使用大型语言模型法学硕士来估计课堂评估评分系统 CLASS(一种广泛使用的观察协议)的教学支持领域分数。我们设计了一种机器学习架构,它使用 Meta s Llama2 的零样本提示和/或经典的词袋 BoW 模型,对使用 OpenAI s Whisper 自动转录的教师语音的个别话语进行分类,以判断是否存在 11 项教学支持行为指标。然后,在整个 15 分钟的观察会话中汇总这些话语水平判断,以估计全局 CLASS 分数。对幼儿和学前班教室的两个 CLASS 编码数据集进行的实验表明,使用所提出的方法 Pearson R 高达 0.46 的自动 CLASS 教学支持估计精度接近高达 R 0.55 的人类评分者可靠性 2 LLM 在此任务中产生的精度比 BoW 稍高3 最好的模型通常结合从 LLM 和 BoW 中提取的特征。 |
| Text Data Augmentation in Low-Resource Settings via Fine-Tuning of Large Language Models Authors Jean Kaddour, Qi Liu 大型语言模型法学硕士的上下文学习能力使它们能够推广到具有相对较少标记示例的新下游任务。然而,它们需要部署大量的计算资源。或者,如果使用足够的标记示例进行微调,较小的模型也可以解决特定任务。然而,获得这些例子的成本很高。为了追求两全其美,我们通过微调教师法学硕士研究微调训练数据的注释和生成,以提高更小模型的下游性能。 |
| GraphText: Graph Reasoning in Text Space Authors Jianan Zhao, Le Zhuo, Yikang Shen, Meng Qu, Kai Liu, Michael Bronstein, Zhaocheng Zhu, Jian Tang 大型语言模型法学硕士已经获得了吸收人类知识并促进与人类和其他法学硕士进行自然语言交互的能力。然而,尽管取得了令人瞩目的成就,法学硕士在图机器学习领域并没有取得重大进展。出现这种限制的原因是图表封装了不同的关系数据,这使得将它们转换为法学硕士可以理解的自然语言变得具有挑战性。在本文中,我们用一个新颖的框架 GraphText 弥补了这一差距,该框架将图形翻译成自然语言。 GraphText 为每个图派生一个图语法树,其中封装了节点属性和节点间关系。遍历树会产生图形文本序列,然后由 LLM 处理该序列,将图形任务视为文本生成任务。值得注意的是,GraphText 具有多种优势。它引入了训练自由图推理,即使没有对图数据进行训练,带有 ChatGPT 的 GraphText 也可以通过上下文学习 ICL 实现与监督训练的图神经网络相当甚至超越的性能。此外,GraphText 为交互式图形推理铺平了道路,允许人类和法学硕士使用自然语言与模型无缝通信。 |
| Towards human-like spoken dialogue generation between AI agents from written dialogue Authors Kentaro Mitsui, Yukiya Hono, Kei Sawada 大型语言模型法学硕士的出现使得在两个代理之间生成自然的书面对话成为可能。然而,从这些书面对话中生成类似人类的口头对话仍然具有挑战性。口语对话有几个独特的特征,它们经常包括私下谈话和笑声,轮流的流畅程度显着影响对话的流畅性。本研究提出 CHATS CHatty Agents Text to Speech 是一种基于离散令牌的系统,旨在根据书面对话生成口头对话。我们的系统可以同时为说话者侧和听者侧生成语音,仅使用说话者侧的转录,从而消除了对反向通道或笑声转录的需要。此外,CHATS 有助于自然轮流,在没有重叠的情况下,它确定每次话语后适当的沉默持续时间,并且在重叠的情况下,它根据下一个话语的音素序列启动重叠语音的生成。 |
| Back to the Future: Towards Explainable Temporal Reasoning with Large Language Models Authors Chenhan Yuan, Qianqian Xie, Jimin Huang, Sophia Ananiadou 时间推理是一项至关重要的 NLP 任务,它提供对文本数据中时间敏感上下文的细致入微的理解。尽管法学硕士的最新进展已经证明了它们在时间推理方面的潜力,但主要焦点还是时间表达和时间关系提取等任务。这些任务主要是为了提取直接和过去的时间线索并进行简单的推理过程而设计的。在考虑复杂的推理任务(例如事件预测)时,仍然存在很大的差距,这需要对事件进行多步时间推理并预测未来时间戳。现有方法的另一个显着限制是它们无法提供推理过程的说明,从而阻碍了可解释性。在本文中,我们介绍了可解释时间推理的第一个任务,即根据上下文预测事件在未来时间戳的发生,这需要对多个事件进行多重推理,并随后为其预测提供清晰的解释。我们的任务对法学硕士的复杂时间推理能力、未来事件预测能力和可解释性(人工智能应用的关键属性)进行了全面评估。为了支持这项任务,我们使用新颖的知识图指令生成策略,提出了第一个可解释时间推理 ExpTime 的多源指令调整数据集,其中 26k 源自时间知识图数据集及其时间推理路径。基于该数据集,我们提出了第一个基于 LlaMA2 基础的开源 LLM 系列 TimeLlaMA,具有指令跟踪能力以进行可解释的时间推理。 |
| Reasoning on Graphs: Faithful and Interpretable Large Language Model Reasoning Authors Linhao Luo, Yuan Fang Li, Gholamreza Haffari, Shirui Pan 大型语言模型法学硕士在复杂任务中表现出了令人印象深刻的推理能力。然而,他们在推理过程中缺乏最新的知识和经验幻觉,这可能导致错误的推理过程并降低他们的表现和可信度。知识图谱 KG 以结构化格式捕获大量事实,为推理提供了可靠的知识来源。然而,现有的基于知识图谱的LLM推理方法仅将知识图谱视为事实知识库,而忽视了其结构信息对于推理的重要性。在本文中,我们提出了一种称为图 RoG 推理的新颖方法,该方法将 LLM 与 KG 相结合,以实现忠实且可解释的推理。具体来说,我们提出了一个规划检索推理框架,其中 RoG 首先生成以知识图谱为基础的关系路径作为忠实的计划。然后使用这些计划从 KG 中检索有效的推理路径,供法学硕士进行忠实的推理。此外,RoG不仅可以从KG中提取知识,通过训练来提高LLM的推理能力,而且还可以在推理过程中与任意LLM无缝集成。 |
| Tool-Augmented Reward Modeling Authors Lei Li, Yekun Chai, Shuohuan Wang, Yu Sun, Hao Tian, Ningyu Zhang, Hua Wu 奖励建模又名偏好建模有助于使大型语言模型与人类偏好保持一致,特别是在根据人类反馈 RLHF 进行强化学习的背景下。虽然传统的奖励模型 RM 表现出了卓越的可扩展性,但它们经常在算术计算、代码执行和事实查找等基本功能上遇到困难。在本文中,我们提出了一种名为 name 的工具增强偏好建模方法,通过授权 RM 访问外部环境(包括计算器和搜索引擎)来解决这些限制。这种方法不仅促进了工具利用和奖励分级之间的协同作用,而且还增强了解释能力和评分可靠性。我们的研究深入研究了外部工具与 RM 的集成,使它们能够与不同的外部源交互,并以自回归方式构建任务特定的工具参与和推理轨迹。我们在广泛的领域验证了我们的方法,结合了七个不同的外部工具。我们的实验结果表明,八项任务的偏好排名总体提高了 17.7。此外,我们的方法在零样本评估中的 TruthfulQA 任务上比 Gopher 280B 好 7.3。在人类评估中,与四项不同任务的基线相比,经过 Themis 训练的 RLHF 的平均获胜率为 32。此外,我们还提供与工具相关的 RM 数据集的全面集合,其中包含来自七个不同工具 API 的数据,总计 15,000 个实例。 |
| Language Model Decoding as Direct Metrics Optimization Authors Haozhe Ji, Pei Ke, Hongning Wang, Minlie Huang 尽管语言建模取得了显着的进步,但当前的主流解码方法仍然难以生成在不同方面与人类文本保持一致的文本。特别是,基于采样的方法产生较少重复的文本,这些文本在话语中通常是分离的,而基于搜索的方法以增加重复为代价保持主题连贯性。总体而言,这些方法无法在广泛的方面实现整体协调。在这项工作中,我们将语言模型的解码构建为优化问题,其目标是将预期性能与同时通过所需方面的多个指标测量的人类文本严格匹配。所得的解码分布具有分析解决方案,该解决方案通过由这些指标定义的序列级能量函数来缩放输入语言模型分布。最重要的是,我们证明这种诱导分布保证可以改善人类文本的困惑度,这表明可以更好地逼近人类文本的潜在分布。为了便于从这种全局标准化分布中进行易于处理的采样,我们采用了采样重要性重采样技术。 |
| ARN: A Comprehensive Framework and Dataset for Analogical Reasoning on Narratives Authors Zhivar Sourati, Filip Ilievski, Pia Sommerauer 类比推理是人类的主要能力之一,与创造力和科学发现相关。通过提出各种基准和评估设置,这种能力在自然语言处理 NLP 以及认知心理学中得到了广泛的研究。然而,认知心理学和 NLP 中类比推理的评估之间存在很大差距。我们的目标是通过计算调整与叙事背景下的认知心理学类比推理相关的理论并开发大规模的评估框架来弥补这一点。更具体地说,我们提出了基于系统映射匹配叙事的任务,并发布了叙事 ARN 数据集上的类比推理。为了创建数据集,我们设计了一个受认知心理学理论启发的框架,该理论涉及类比推理,利用叙述及其组成部分来形成不同抽象级别的映射。然后利用这些映射来创建类比和非类比干扰项对,其中包含超过 1000 个查询叙述、类比和干扰项的三元组。我们涵盖了四类远近类比和远近干扰项,使我们能够从不同的角度研究模型中的类比推理。在这项研究中,我们评估了不同的大型语言模型法学硕士在此任务上的表现。我们的结果表明,当高阶映射不伴随低阶映射远类比时,LLM 很难识别高阶映射,并且当所有映射同时存在近类比时,LLM 会表现出更好的性能。 |
| EALM: Introducing Multidimensional Ethical Alignment in Conversational Information Retrieval Authors Yiyao Yu, Junjie Wang, Yuxiang Zhang, Lin Zhang, Yujiu Yang, Tetsuya Sakai 人工智能人工智能技术应遵守人类规范,以更好地服务我们的社会,并避免传播有害或误导性信息,特别是在对话式信息检索 CIR 中。以前的工作,包括方法和数据集,在考虑人类规范方面并不总是成功或足够稳健。为此,我们引入了一个集成道德一致性的工作流程,以及用于高效数据筛选的初始道德判断阶段。为了满足 CIR 中的道德判断需求,我们提出了 QA ETHICS 数据集,该数据集改编自 ETHICS 基准,它通过统一场景和标签含义作为评估工具。然而,每种情况仅考虑一种伦理概念。因此,我们引入 MP ETHICS 数据集来评估多种伦理概念下的场景,例如正义和道义论。此外,我们提出了一种新方法,可以在二元和多标签道德判断任务中实现最佳性能。我们的研究提供了一种将道德一致性引入 CIR 工作流程的实用方法。 |
| Resolving Knowledge Conflicts in Large Language Models Authors Yike Wang, Shangbin Feng, Heng Wang, Weijia Shi, Vidhisha Balachandran, Tianxing He, Yulia Tsvetkov 大型语言模型法学硕士经常会遇到知识冲突,即法学硕士内部参数知识与提示上下文中提供的非参数信息之间出现差异的情况。在这项工作中,我们询问当出现知识冲突时,法学硕士的需求是什么,以及现有的法学硕士是否满足这些需求。我们假设法学硕士应该 1 识别知识冲突,2 查明冲突的信息片段,3 在冲突的情况下提供不同的答案或观点。为此,我们引入了知识冲突(KNOWLEDGE CONFLICT),这是一个评估框架,用于模拟情境知识冲突并定量评估法学硕士实现这些目标的程度。知识冲突包括多样化、复杂的知识冲突情境、来自不同实体和领域的知识、两种综合的冲突产生方法以及反映现实知识冲突的难度逐渐增加的设置。知识冲突框架的大量实验表明,虽然法学硕士在识别知识冲突的存在方面表现良好,但他们很难确定具体的冲突知识并在冲突信息中产生具有不同答案的响应。为了应对这些挑战,我们提出了新的基于教学的方法,以增强法学硕士的能力,以更好地实现这三个目标。 |
| All Languages Matter: On the Multilingual Safety of Large Language Models Authors Wenxuan Wang, Zhaopeng Tu, Chang Chen, Youliang Yuan, Jen tse Huang, Wenxiang Jiao, Michael R. Lyu 安全是开发和部署大型语言模型法学硕士的核心。然而,以前的安全基准仅涉及一种语言的安全性,例如预训练数据中的主要语言,例如英语。在这项工作中,我们为法学硕士建立了第一个多语言安全基准 XSafety,以响应法学硕士在实践中的全球部署。 XSafety 涵盖跨多个语系的 10 种语言的 14 种常用安全问题。我们利用 XSafety 对 4 个广泛使用的 LLM 的多语言安全性进行了实证研究,包括封闭 API 和开源模型。实验结果表明,所有法学硕士对非英语查询的不安全响应明显多于英语查询,这表明有必要为非英语语言开发安全一致性。此外,我们提出了几种简单有效的提示方法,通过唤起安全知识和提高安全对齐的跨语言泛化来提高 ChatGPT 的多语言安全性。我们的提示方法可以将非英语查询的不安全响应比例从 19.1 显着降低到 9.7。 |
| TADIS: Steering Models for Deep-Thinking about Demonstration Examples Authors Tianci Xue, Ziqi Wang, Yixia Li, Yun Chen, Guanhua Chen 指令调整已被证明可以显着提高对未见过的任务的零样本泛化能力。通过在微调过程中纳入额外的上下文(例如任务定义、示例),大型语言模型法学硕士取得了比以前更高的性能。然而,最近的工作报告称,欺骗性任务示例可以实现与正确任务示例几乎相同的性能,这表明输入标签对应关系没有以前想象的那么重要。我们对这种反直觉的观察很感兴趣,怀疑模型与人类有着同样的能力错觉。因此,我们提出了一种名为 TADIS 的新颖方法,引导法学硕士对演示示例进行深入思考,而不仅仅是观看。为了减轻模型能力的错觉,我们首先要求模型验证所显示示例的正确性。然后,以验证结果为条件,引出模型以获得更好的答案。我们的实验结果表明,TADIS 在域内和域外任务上始终优于竞争基线,在域外和域内数据集上分别提高了 2.79 和 4.03 平均 ROUGLE L。尽管存在生成的示例,但并非所有思维标签都是准确的,TADIS 可以显着提高零样本和少量样本设置中的性能。这也表明我们的方法可以大规模采用,以提高模型的指令跟随能力,而无需任何体力劳动。 |
| Enable Language Models to Implicitly Learn Self-Improvement From Data Authors Ziqi Wang, Le Hou, Tianjian Lu, Yuexin Wu, Yunxuan Li, Hongkun Yu, Heng Ji 大型语言模型法学硕士在开放式文本生成任务中表现出了卓越的能力。然而,这些任务固有的开放性本质意味着模型响应的质量始终存在改进的空间。为了应对这一挑战,人们提出了各种方法来提高法学硕士的表现。人们越来越关注让法学硕士能够自我提高其回答质量,从而减少对收集多样化和高质量培训数据的大量人工注释工作的依赖。近年来,基于提示的方法因其有效性、效率和便利性而在自我改进方法中得到了广泛的探索。然而,这些方法通常需要明确且彻底的书面评估标准作为法学硕士的输入。手动导出并提供所有必要的准则以及现实世界复杂的改进目标(例如,变得更有帮助、危害更少)是昂贵且具有挑战性的。为此,我们提出了一种隐式自我改进 PIT 框架,该框架隐式地从人类偏好数据中学习改进目标。 PIT 仅需要用于训练奖励模型的偏好数据,无需额外的人工操作。具体来说,我们根据人类反馈 RLHF 重新制定强化学习的训练目标,而不是最大化给定输入的响应质量,而是最大化以参考响应为条件的响应的质量差距。通过这种方式,PIT 被隐式地训练,其改进目标是更好地符合人类偏好。 |
| No Offense Taken: Eliciting Offensiveness from Language Models Authors Anugya Srivastava, Rahul Ahuja, Rohith Mukku |
| (Dynamic) Prompting might be all you need to repair Compressed LLMs Authors Duc N.M Hoang, Minsik Cho, Thomas Merth, Mohammad Rastegari, Zhangyang Wang 大型语言模型法学硕士虽然对 NLP 具有变革性,但也带来了巨大的计算需求,强调了对高效、免训练压缩的需求。值得注意的是,困惑度作为压缩模型功效基准的可靠性是有问题的,因为我们使用 LLaMA 7B 和 OPT 6.7b 的测试揭示了几个实际下游任务的性能显着下降,强调了作为性能指标的困惑度与现实世界之间的差异表现。对资源密集型压缩后再训练之间权衡的调查凸显了快速驱动恢复作为轻量级适应工具的前景。然而,现有的研究主要局限于困惑度评估和简单任务,未能对提示的可扩展性和普遍性提供明确的信心。我们通过两种关键方式应对这种不确定性。首先,我们发现 LLM 压缩中幼稚提示的漏洞是过度依赖每个输入的单一提示。作为回应,我们提出了推理时间动态提示 IDP,这是一种根据每个单独输入的上下文从一组精选提示中自主选择的机制。其次,我们深入研究了为什么提示可能是 LLM 压缩后您所需要的全部内容。我们的研究结果表明,压缩不会无可挽回地消除 LLM 模型知识,而是会取代它,从而需要新的推理路径。 IDP 有效地重新定向了这条路径,使模型能够利用其固有但已移位的知识,从而恢复性能。 |
| Melody-conditioned lyrics generation via fine-tuning language model and its evaluation with ChatGPT Authors Zhe Zhang, Karol Lasocki, Yi Yu, Atsuhiro Takasu 我们利用字符级语言模型从符号旋律生成音节级歌词。通过微调字符级预训练模型,我们将语言知识集成到音节级 Transformer 生成器的波束搜索中。 |
| Application of frozen large-scale models to multimodal task-oriented dialogue Authors Tatsuki Kawamoto, Takuma Suzuki, Ko Miyama, Takumi Meguro, Tomohiro Takagi 在本研究中,我们使用现有的大型语言模型ENnhanced to See Framework LENS Framework来测试多模态任务导向对话的可行性。 LENS 框架被提出作为一种解决计算机视觉任务的方法,无需额外的训练,并且具有预训练模型的固定参数。我们使用了多模态对话MMD数据集,这是一个来自时尚领域的面向多模态任务的对话基准数据集,并且为了进行评估,我们使用了基于ChatGPT的G EVAL,它只接受文本模态,并安排处理多模态数据。与之前研究中基于 Transformer 的模型相比,我们的方法在流畅性方面绝对提升了 10.8,在实用性方面提升了 8.8,在相关性和连贯性方面提升了 5.2。结果表明,使用具有固定参数的大规模模型而不是使用从头开始在数据集上训练的模型可以提高多模式任务导向对话的性能。同时,我们证明大型语言模型法学硕士对于面向多模式任务的对话是有效的。 |
| Error Norm Truncation: Robust Training in the Presence of Data Noise for Text Generation Models Authors Tianjian Li, Haoran Xu, Philipp Koehn, Daniel Khashabi, Kenton Murray 众所周知,文本生成模型很容易受到训练数据错误的影响。随着大量网络爬取数据的广泛使用变得越来越普遍,我们如何增强在大量噪声网络爬取文本上训练的模型的鲁棒性在我们的工作中,我们提出了错误范数截断ENT,这是一种鲁棒的增强方法截断噪声数据的标准训练目标。与仅使用负对数似然损失来估计数据质量的方法相比,我们的方法通过考虑非目标标记的分布提供了更准确的估计,这经常被以前的工作所忽视。通过语言建模、机器翻译和文本摘要的综合实验,我们表明,与标准训练和以前的软截断和硬截断方法相比,为文本生成模型配备 ENT 可以提高生成质量。此外,我们还表明,我们的方法提高了模型针对机器翻译中两种最有害的噪声类型的鲁棒性,当向数据中添加多达 50 个噪声时,与 MLE 基线相比,BLEU 点增加了 2 以上 |
| Towards LogiGLUE: A Brief Survey and A Benchmark for Analyzing Logical Reasoning Capabilities of Language Models Authors Man Luo, Shrinidhi Kumbhar, Ming shen, Mihir Parmar, Neeraj Varshney, Pratyay Banerjee, Somak Aditya, Chitta Baral 逻辑推理对于人类来说是基础,但在人工智能领域提出了巨大的挑战。最初,研究人员使用知识表示和推理 KR 系统,该系统无法扩展并且需要大量的手动工作。最近,大型语言模型LLM的出现证明了克服正式知识表示KR系统的各种限制的能力。因此,人们越来越有兴趣使用法学硕士通过自然语言进行逻辑推理。本文旨在通过简要回顾该领域的最新进展,重点介绍逻辑推理数据集、任务以及利用法学硕士进行推理所采用的方法,旨在了解法学硕士在逻辑推理方面的熟练程度。为了提供全面的分析,我们编制了一个名为 LogiGLUE 的基准测试。其中包括 24 个不同的数据集,涵盖演绎、溯因和归纳推理。我们已将这些数据集标准化为 Seq2Seq 任务,以便于未来研究的直接训练和评估。利用 LogiGLUE 作为基础,我们训练了一个指令微调语言模型,从而产生了 LogiT5。我们研究单任务训练、多任务训练和思想链知识蒸馏微调技术,以评估模型在不同逻辑推理类别中的性能。 |
| TRAM: Benchmarking Temporal Reasoning for Large Language Models Authors Yuqing Wang, Yun Zhao 关于时间的推理对于理解自然语言描述的事件的细微差别至关重要。先前关于该主题的研究范围有限,其特点是缺乏标准化基准,无法对不同研究进行一致的评估。在本文中,我们介绍了 TRAM,这是一个由 10 个数据集组成的时间推理基准,涵盖事件的各个时间方面,如顺序、算术、频率和持续时间,旨在促进大型语言模型法学硕士的时间推理能力的综合评估。我们使用流行的 LLM(例如 GPT 4 和 Llama2)在零样本和少量样本学习场景中进行了广泛的评估。此外,我们采用基于 BERT 的模型来建立基线评估。我们的研究结果表明,这些模型在时间推理任务中仍然落后于人类的表现。我们希望 TRAM 能够推动法学硕士时间推理能力的进一步进步。 |
| Necessary and Sufficient Watermark for Large Language Models Authors Yuki Takezawa, Ryoma Sato, Han Bao, Kenta Niwa, Makoto Yamada 近年来,大型语言模型LLM在各种NLP任务中取得了令人瞩目的表现。它们可以生成与人类编写的文本没有区别的文本。法学硕士如此出色的表现增加了其被用于恶意目的的风险,例如生成虚假新闻文章。因此,有必要开发区分法学硕士撰写的文本与人类撰写的文本的方法。水印是实现这一目标的最强大的方法之一。尽管现有的水印方法已成功检测法学硕士生成的文本,但它们显着降低了生成文本的质量。在本研究中,我们提出了必要和充分水印 NS Watermark,用于将水印插入到生成的文本中,而不会降低文本质量。更具体地说,我们得出了对生成的文本施加的最小约束,以区分文本是法学硕士还是人类编写的。然后,我们将 NS Watermark 表述为一个约束优化问题,并提出了一种有效的算法来解决它。通过实验,我们证明 NS Watermark 可以生成比现有水印方法更自然的文本,并且可以更准确地区分法学硕士编写的文本和人类编写的文本。 |
| Natural Language Models for Data Visualization Utilizing nvBench Dataset Authors Shuo Wang, Carlos Crespo Quinones 将自然语言转换为语法正确的数据可视化命令是自然语言模型的重要应用,可用于许多不同的任务。一项密切相关的工作是将自然语言转换为 SQL 查询,而 SQL 查询又可以通过来自引用Zhong 2017qr 的自然语言查询提供的附加信息转换为可视化。为了推动这一研究领域的进展,我们构建了自然语言翻译模型,以一种名为 Vega Zero 的语言构建简化版本的数据和可视化查询。在本文中,我们探索了这些基于序列到序列转换器的机器学习模型架构的设计和性能,使用大型语言模型(例如 BERT)作为编码器来预测来自自然语言查询的可视化命令,并将可用的 T5 序列到序列模型应用于 |
| Parameter-Efficient Tuning Helps Language Model Alignment Authors Tianci Xue, Ziqi Wang, Heng Ji 将大型语言模型法学硕士与人类偏好保持一致对于安全和有用的法学硕士至关重要。之前的工作主要采用强化学习RLHF和直接偏好优化DPO与人类反馈进行对齐。然而,它们也有某些缺点。其中一个限制是,它们只能在训练时将模型与一种偏好对齐,例如,当偏好数据更喜欢详细响应时,它们无法学习生成简洁的响应,或者对数据格式有某些限制,例如,DPO 仅支持成对偏好数据。为此,先前的工作结合了可控生成来进行对齐,使语言模型学习多种偏好,并在推理过程中根据要求提供具有不同偏好的输出。可控生成还在数据格式方面提供了更大的灵活性,例如,它支持逐点偏好数据。具体来说,它在训练和推理过程中针对不同的偏好使用不同的控制令牌,使得 LLM 在需要时表现不同。目前的可控生成方法要么使用特殊的令牌,要么使用手工制作的提示作为控制令牌,并与 LLM 一起对其进行优化。由于控制令牌通常比 LLM 轻得多,因此这种优化策略可能无法有效优化控制令牌。为此,我们首先使用参数有效调整,例如提示调整和低秩适应来优化控制令牌,然后微调模型以实现可控生成,与之前的工作类似。 |
| Injecting a Structural Inductive Bias into a Seq2Seq Model by Simulation Authors Matthias Lindemann, Alexander Koller, Ivan Titov 强归纳偏差可以从少量数据中进行学习,并有助于在训练分布之外进行泛化。 Transformer 等流行的神经架构本身缺乏针对 seq2seq NLP 任务的强结构归纳偏差。因此,他们在训练分布之外的系统泛化方面遇到了困难,例如即使对大量文本进行了预先训练,也可以推断出更长的输入。我们展示了如何通过预训练来模拟合成数据的结构转换,从而将结构归纳偏差注入到 seq2seq 模型中。具体来说,我们通过预先训练 Transformer 来模拟给定描述的 FST,从而将有限状态换能器 FST 的归纳偏差注入到 Transformer 中。 |
| Testing the Limits of Unified Sequence to Sequence LLM Pretraining on Diverse Table Data Tasks Authors Soumajyoti Sarkar, Leonard Lausen 存储在数据库中的表以及网页和文章中存在的表占互联网上可用的半结构化数据的很大一部分。然后,开发一种具有大型语言模型法学硕士的建模方法就变得有意义,该方法可用于解决各种表任务,例如语义解析、问答以及分类问题。传统上,存在专门针对每个任务的单独模型。这就提出了一个问题:我们能在多大程度上建立一个统一的模型,该模型在某些表任务上表现良好,而不会显着降低其他任务的性能。为此,我们尝试在预训练阶段创建一种共享建模方法,使用编码器解码器风格的 LLM 来满足不同的任务。我们评估了我们的方法,该方法使用来自表和周围上下文的数据,在不同模型规模的下游任务上不断地预训练和微调 T5 的不同模型系列。通过多项消融研究,我们观察到,具有自我监督目标的预训练可以显着提高模型在这些任务上的性能。作为一项改进的一个例子,我们观察到,专门针对文本问答 QA 并经过表数据训练的指令微调公共模型在涉及表特定 QA 时仍然有改进的空间。 |
| BooookScore: A systematic exploration of book-length summarization in the era of LLMs Authors Yapei Chang, Kyle Lo, Tanya Goyal, Mohit Iyyer 总结超过大型语言模型 LLM 上下文窗口大小的书本长度文档 100K 标记,需要首先将输入文档分成更小的块,然后提示 LLM 合并、更新和压缩块级别摘要。尽管这项任务既复杂又重要,但由于评估现有书籍长度摘要数据集的挑战,它尚未得到有意义的研究,例如,BookSum 存在于大多数公共法学硕士的预训练数据中,而现有的评估方法很难捕获由现代法学硕士总结者。在本文中,我们首次研究了基于 LLM 的书籍长度摘要器的一致性,通过两个提示工作流程实现:1 分层合并块级摘要,2 增量更新运行摘要。我们在 GPT 4 上获得了 1193 个细粒度的人类注释,生成了最近出版的 100 本书的摘要,并识别了法学硕士所犯的八种常见的连贯性错误。由于人工评估既昂贵又耗时,我们开发了一种自动指标 BooookScore,用于衡量摘要中不包含任何已识别错误类型的句子的比例。 BooookScore 与人工注释高度一致,使我们能够系统地评估许多其他关键参数(例如块大小、基础 LLM)的影响,同时节省 15K 和 500 小时的人工评估成本。我们发现,GPT 4 和 Claude 2 等闭源 LLM 生成的摘要比 LLaMA 2 生成的经常重复的摘要具有更高的 BooookScore。增量更新产生的 BooookScore 较低,但比分层合并的详细程度更高,这是人类注释者有时更喜欢的权衡。 |
| TIGERScore: Towards Building Explainable Metric for All Text Generation Tasks Authors Dongfu Jiang, Yishan Li, Ge Zhang, Wenhao Huang, Bill Yuchen Lin, Wenhu Chen 我们提出了 TIGERScore,这是一种经过训练的指标,它遵循 textbf 指令 textbf 指导来执行 textbf 可解释的和 textbf 参考免费评估广泛的文本生成任务。与其他仅提供晦涩难懂的分数的自动评估方法不同,TIGERScore 以自然语言指令为指导,提供错误分析,以查明生成文本中的错误。我们的指标基于 LLaMA,在我们精心策划的指令调整数据集 MetricInstruct 上进行训练,该数据集涵盖 6 个文本生成任务和 23 个文本生成数据集。该数据集由48K四元组组成,形式为指令、输入、系统输出右箭头错误分析。我们通过多种渠道收集系统输出,以涵盖不同类型的错误。为了定量评估我们的指标,我们评估了其与 5 个数据集、2 个保留数据集的人类评分的相关性,并表明 TIGERScore 可以在这些数据集中实现与人类评分的最高整体 Spearman 相关性,并且显着优于其他指标。作为一种无参考指标,其相关性甚至可以超越现有最好的基于参考的指标。为了进一步定性评估我们的指标生成的基本原理,我们对生成的解释进行了人工评估,发现解释的准确度为 70.8。 |
| RoleLLM: Benchmarking, Eliciting, and Enhancing Role-Playing Abilities of Large Language Models Authors Zekun Moore Wang, Zhongyuan Peng, Haoran Que, Jiaheng Liu, Wangchunshu Zhou, Yuhan Wu, Hongcheng Guo, Ruitong Gan, Zehao Ni, Man Zhang, Zhaoxiang Zhang, Wanli Ouyang, Ke Xu, Wenhu Chen, Jie Fu, Junran Peng 大型语言模型法学硕士的出现为角色扮演等复杂任务铺平了道路,角色扮演通过使模型能够模仿各种角色来增强用户交互。然而,最先进的法学硕士的闭源性质及其通用培训限制了角色扮演的优化。在本文中,我们介绍了 RoleLLM,这是一个用于基准测试、引发和增强法学硕士角色扮演能力的框架。 RoleLLM 包括四个阶段 1 100 个角色的角色配置文件构建 2 基于上下文的指令生成 Context Instruct 用于角色特定知识提取 3 使用 GPT RoleGPT 进行角色提示以模仿说话风格 4 角色条件指令调整 RoCIT 用于微调开源模型以及角色定制。通过 Context Instruct 和 RoleGPT,我们创建了 RoleBench,这是第一个系统化、细粒度的角色扮演基准数据集,包含 168,093 个样本。 |
| FELM: Benchmarking Factuality Evaluation of Large Language Models Authors Shiqi Chen, Yiran Zhao, Jinghan Zhang, I Chun Chern, Siyang Gao, Pengfei Liu, Junxian He 评估大型语言模型法学硕士生成的文本的真实性是一个新兴但重要的研究领域,旨在提醒用户潜在的错误并指导更可靠的法学硕士的开发。尽管如此,评估事实性的评估者本身也需要进行适当的评估,以衡量进展并促进进步。这一方向仍在探索中,这对事实评估者的进步造成了重大障碍。为了缓解这个问题,我们引入了大型语言模型事实性评估的基准,称为 felm。在此基准测试中,我们收集法学硕士生成的回复,并以细粒度的方式注释事实标签。与之前主要关注世界知识的真实性的研究相反。来自维基百科的信息,felm 专注于不同领域的事实性,从世界知识到数学和推理。我们的注释基于文本片段,这可以帮助查明特定的事实错误。事实性注释由预定义的错误类型和支持或反驳该陈述的参考链接进一步补充。在我们的实验中,我们研究了几个基于 FLM 的事实性评估器在 felm 上的表现,包括普通的 LLM 和那些通过检索机制和思维过程链增强的 LLM。 |
| Robust Sentiment Analysis for Low Resource languages Using Data Augmentation Approaches: A Case Study in Marathi Authors Aabha Pingle, Aditya Vyawahare, Isha Joshi, Rahul Tangsali, Geetanjali Kale, Raviraj Joshi 情感分析对于理解文本数据中表达的情感起着至关重要的作用。虽然英语和其他西方语言的情感分析研究已广泛开展,但低资源语言的情感分析研究工作还存在很大差距。有限的资源,包括数据集和 NLP 研究,阻碍了该领域的进展。在这项工作中,我们对资源匮乏的印度语马拉地语的数据增强方法进行了详尽的研究。尽管存在用于马拉地语情感分析的特定领域数据集,但在应用于广义和可变长度输入时,它们通常存在不足。为了应对这一挑战,本研究论文提出了四种用于马拉地语情感分析的数据增强技术。本文的重点是扩充现有数据集以弥补资源不足的情况。主要目标是通过利用数据增强策略来增强域和跨域场景中的情感分析模型性能。提出的数据增强方法显示出跨域准确性的显着性能改进。增强方法包括释义、基于 BERT 的回译随机标记替换、命名实体替换以及基于 GPT 的文本和标签生成的伪标签生成。 |
| Evaluating Speech Synthesis by Training Recognizers on Synthetic Speech Authors Dareen Alharthi, Roshan Sharma, Hira Dhamyal, Soumi Maiti, Bhiksha Raj, Rita Singh 现代语音合成系统已得到显着改进,合成语音与真实语音无法区分。然而,对合成语音的有效和全面的评估仍然是一个重大挑战。使用平均意见分数 MOS 进行人工评估是理想的,但由于成本高而效率低下。因此,研究人员开发了诸如单词错误率 WER 之类的辅助自动指标来衡量清晰度。先前的工作重点是基于预先训练的语音识别模型来评估合成语音,然而,这可能是有限的,因为这种方法主要测量语音清晰度。在本文中,我们提出了一种评估技术,涉及在合成语音上训练 ASR 模型并评估其在真实语音上的性能。我们的主要假设是,通过在合成语音上训练 ASR 模型,真实语音的 WER 反映了分布之间的相似性,这是对超出可理解性的合成语音质量的更广泛的评估。 |
| Do the Benefits of Joint Models for Relation Extraction Extend to Document-level Tasks? Authors Pratik Saini, Tapas Nayak, Indrajit Bhattacharya 针对关系三元组提取管道和联合提出了两种不同的方法。联合模型捕获三元组之间的交互,是最近的发展,并且已被证明在句子级提取任务中优于管道模型。文档级提取是一个更具挑战性的设置,其中三元组之间的交互可以是长范围的,并且单个三元组也可以跨越句子。到目前为止,联合模型尚未应用于文档级任务。在本文中,我们在句子级别以及文档级别数据集上对最先进的管道和联合提取模型进行了基准测试。 |
| CebuaNER: A New Baseline Cebuano Named Entity Recognition Model Authors Ma. Beatrice Emanuela Pilar, Ellyza Mari Papas, Mary Loise Buenaventura, Dane Dedoroy, Myron Darrel Montefalcon, Jay Rhald Padilla, Lany Maceda, Mideth Abisado, Joseph Marvin Imperial 尽管东南亚是语言最多样化的国家之一,但东南亚的计算语言学和语言处理研究一直难以与全球北方国家的水平相匹配。因此,开源语料库和开发基本语言处理任务的基线模型等举措是鼓励该领域研究工作增长的重要垫脚石。为了响应这一号召,我们引入了 CebuaNER,这是一种用于宿务语命名实体识别 NER 的新基线模型。宿雾语是菲律宾使用人数第二多的母语,使用者超过 2000 万。为了构建模型,我们收集并注释了 4,000 多篇新闻文章,这是该语言中最大的一篇文章,这些文章是从宿务本地在线平台检索的,用于训练条件随机场和双向 LSTM 等算法。 |
| Fewer is More: Trojan Attacks on Parameter-Efficient Fine-Tuning Authors Lauren Hong 1 , Ting Wang 1 1 Stony Brook University 参数高效的微调 PEFT 可以使预先训练的语言模型 PLM 有效适应特定任务。通过仅调整最少的额外参数集,PEFT 即可实现与完全微调相当的性能。然而,尽管 PEFT 被广泛使用,但其安全隐患在很大程度上仍未得到探索。在本文中,我们进行了一项试点研究,揭示了 PEFT 对木马攻击表现出独特的脆弱性。具体来说,我们提出了 PETA,这是一种新颖的攻击,它通过双层优化来考虑下游适应,上层目标将后门嵌入到 PLM 中,而下层目标则模拟 PEFT 以保留 PLM 的任务特定性能。通过对各种下游任务和触发器设计的广泛评估,我们证明了 PETA 在攻击成功率和不受影响的干净准确性方面的有效性,即使受害者用户使用未受污染的数据对后门 PLM 执行 PEFT 也是如此。此外,我们凭经验为 PETA 的功效提供了可能的解释,双层优化本质上使后门和 PEFT 模块正交,从而在整个 PEFT 中保留后门。 |
| Faithful Explanations of Black-box NLP Models Using LLM-generated Counterfactuals Authors Yair Gat, Nitay Calderon, Amir Feder, Alexander Chapanin, Amit Sharma, Roi Reichart NLP 系统预测的因果解释对于确保安全和建立信任至关重要。然而,现有方法通常无法有效或高效地解释模型预测,并且通常是特定于模型的。在本文中,我们解决了模型不可知的解释,提出了两种反事实 CF 近似的方法。第一种方法是 CF 生成,其中提示大型语言模型 LLM 更改特定文本概念,同时保持混淆概念不变。虽然这种方法被证明非常有效,但在推理时应用 LLM 成本高昂。因此,我们提出了第二种基于匹配的方法,并提出了一种在训练时由 LLM 指导并学习专用嵌入空间的方法。该空间忠实于给定的因果图,并有效地用于识别近似 CF 的匹配。在从理论上证明需要近似 CF 才能构建忠实的解释之后,我们对我们的方法进行了基准测试并解释了多个模型,包括具有数十亿参数的 LLM。我们的实证结果证明了 CF 生成模型作为模型不可知解释器的出色性能。此外,我们的匹配方法需要更少的测试时间资源,也提供了有效的解释,超越了许多基线。我们还发现 Top K 技术普遍改进了每种测试方法。最后,我们展示了法学硕士在构建模型解释新基准方面的潜力,并随后验证了我们的结论。 |
| A Novel Computational and Modeling Foundation for Automatic Coherence Assessment Authors Aviya Maimon, Reut Tsarfaty 连贯性是写得好的文本的一个基本属性,指的是文本单元相互关联的方式。在生成式人工智能时代,连贯性评估对于许多 NLP 任务的总结、生成、长篇问答等至关重要。然而,在 NLP 中,连贯性是一个定义不明确的概念,没有正式的定义或评估指标,无法进行大规模自动和系统的连贯性评估。为了弥合这一差距,在这项工作中,我们采用了 citet Reinhart 1980 的形式语言学定义,即如何使话语连贯,包括三个条件:内聚性、一致性和相关性,并将这些条件形式化为各自的计算任务。我们假设在所有这些任务上训练的模型将学习一致性检测所需的特征,并且所有任务的联合模型将超过在每个任务上单独训练的模型的性能。在人类评定的连贯性评分的两个基准上,一个包含 500 个自动生成的短篇故事,另一个包含 4k 现实世界文本,我们的实验证实,与特定于任务的模型相比,对所提出的任务进行联合训练可以在每个任务上带来更好的性能,并且与强基线相比,在评估整体一致性方面表现更好。 |
| A Task-oriented Dialog Model with Task-progressive and Policy-aware Pre-training Authors Lucen Zhong, Hengtong Lu, Caixia Yuan, Xiaojie Wang, Jiashen Sun, Ke Zeng, Guanglu Wan 预训练的对话模型 PCM 近年来取得了可喜的进展。然而,用于面向任务的对话 TOD 的现有 PCM 不足以捕获 TOD 相关任务的顺序性质,也不足以学习对话策略信息。为了缓解这些问题,本文提出了一种具有两个策略感知预训练任务的任务渐进式 PCM。该模型通过三个阶段进行预训练,根据TOD系统的任务逻辑逐步采用TOD相关任务。全局策略一致性任务旨在捕获多轮对话策略顺序关系,基于行为的对比学习任务旨在捕获具有相同对话策略的样本之间的相似性。 |
| Nine-year-old children outperformed ChatGPT in emotion: Evidence from Chinese writing Authors Siyi Cao, Tongquan Zhou, Siruo Zhou ChatGPT 已被证明在生成复杂的、类似人类的文本方面具有显着的能力,最近的研究表明,它在心理理论任务中的表现可与 9 岁儿童的表现相媲美。然而,ChatGPT 的中文书写能力是否超过 9 岁儿童仍不确定。 |
| GrowLength: Accelerating LLMs Pretraining by Progressively Growing Training Length Authors Hongye Jin, Xiaotian Han, Jingfeng Yang, Zhimeng Jiang, Chia Yuan Chang, Xia Hu 大型语言模型法学硕士不断发展的复杂性和复杂性带来了前所未有的进步,但它们同时需要大量的计算资源并产生巨大的成本。为了缓解这些挑战,本文引入了一种新颖、简单且有效的方法,称为“growlength”,以加速法学硕士的预训练过程。我们的方法在整个预训练阶段逐步增加训练长度,从而降低计算成本并提高效率。例如,它从 128 的序列长度开始,逐渐扩展到 4096。这种方法使模型能够在有限的时间范围内处理更多数量的令牌,从而可能提高其性能。换句话说,效率增益来自于使用较短序列优化资源利用的训练。我们对各种最先进的法学硕士进行的广泛实验表明,使用我们的方法训练的模型不仅收敛速度更快,而且与使用现有方法训练的模型相比,还表现出卓越的性能指标。 |
| Colloquial Persian POS (CPPOS) Corpus: A Novel Corpus for Colloquial Persian Part of Speech Tagging Authors Leyla Rabiei, Farzaneh Rahmani, Mohammad Khansari, Zeinab Rajabi, Moein Salimi 简介 词性词性标注是将单词分类为各自词性(例如动词或名词)的过程,在各种自然语言处理应用中至关重要。词性标注对于机器翻译、问答、情感分析等应用来说是一项至关重要的预处理任务。然而,现有的波斯语词性标注语料库主要由正式文本组成,例如每日新闻和报纸。因此,在这些语料库上训练的智能 POS 工具、机器学习模型和深度学习模型可能无法以最佳方式处理社交网络分析中的口语文本。方法 本文介绍了一种新颖的语料库,即口语波斯语 POS CPPOS ,专门设计用于支持口语波斯语文本。该语料库包括从 Telegram、Twitter 和 Instagram 上的政治、社会和商业等各个领域收集的正式和非正式文本,超过 52 万个标记标记。在从这些社交平台收集帖子一年后,进行了特殊的预处理步骤,包括社交文本的规范化、句子标记化和单词标记化。然后,语言专家团队对标记和句子进行手动注释和验证。这项研究还定义了用于注释数据和执行注释过程的 POS 标记指南。结果 为了评估 CPPOS 的质量,使用构建的语料库训练了各种深度学习模型,例如 RNN 系列。与另一个名为 Bijankhan 的著名波斯语 POS 语料库以及在 Bijankhan 上训练的波斯语 Hazm POS 工具的比较表明,我们在 CPPOS 上训练的模型优于它们。 |
| Siamese Representation Learning for Unsupervised Relation Extraction Authors Guangxin Zhang, Shu Chen 无监督关系提取 URE 旨在从开放域纯文本中发现命名实体对之间的潜在关系,而无需关系分布的先验信息。现有的URE模型利用对比学习,吸引正样本并排斥负样本以促进更好的分离,取得了不错的效果。然而,关系中细粒度的关系语义会产生虚假的负样本,破坏了固有的层次结构并阻碍了性能。为了解决这个问题,我们提出了用于无监督关系提取的连体表示学习(Siamese Representation Learning for Unsupervised Relation Extraction),这是一种新颖的框架,可以简单地利用正对进行表示学习,具有有效优化实例的关系表示并保留关系特征空间中的层次信息的能力。 |
| SELF: Language-Driven Self-Evolution for Large Language Model Authors Jianqiao Lu, Wanjun Zhong, Wenyong Huang, Yufei Wang, Fei Mi, Baojun Wang, Weichao Wang, Lifeng Shang, Qun Liu 大型语言模型法学硕士在不同领域展示了卓越的多功能性。然而,自主模型开发是实现人类水平学习和推进自主人工智能的基石,其道路在很大程度上仍然未知。我们引入了一种创新方法,称为“自我进化与语言反馈”。这种方法使法学硕士能够经历持续的自我进化。此外,SELF 采用基于语言的反馈作为一种多功能且全面的评估工具,精确定位响应细化的领域并增强自我进化训练的稳定性。从元技能学习开始,自我获得基础元技能,重点是自我反馈和自我完善。这些元技能至关重要,通过使用自我管理的数据进行永久训练的循环来指导模型随后的自我进化,从而增强其内在能力。给定未标记的指令,SELF 使模型能够自动生成和交互式细化响应。随后对合成的训练数据进行过滤并用于迭代微调,从而增强模型的功能。代表性基准的实验结果证实,SELF 可以在不需要人工干预的情况下逐步提高其固有能力,从而表明自主模型进化的可行途径。此外,SELF 可以采用在线自我完善策略来产生高质量的响应。 |
| From Language Modeling to Instruction Following: Understanding the Behavior Shift in LLMs after Instruction Tuning Authors Xuansheng Wu, Wenlin Yao, Jianshu Chen, Xiaoman Pan, Xiaoyang Wang, Ninghao Liu, Dong Yu 大型语言模型法学硕士取得了显着的成功,在不同的任务中展示了强大的指令跟踪能力。指令微调对于使法学硕士能够符合用户意图并有效遵循指令至关重要。在这项工作中,我们研究指令微调如何修改预训练模型,重点关注指令识别和知识进化两个角度。为了研究法学硕士的行为转变,我们采用了一套局部和全局解释方法,包括基于梯度的输入输出归因方法以及解释自注意力和前馈层中的模式和概念的技术。我们的研究结果揭示了指令微调的三个重大影响 1 它使法学硕士能够更好地识别用户提示中的指令部分,从而促进高质量的响应生成并解决在预训练模型中观察到的中间问题的丢失 2 它对齐存储在前馈层具有面向用户的任务,在语言层面上表现出最小的变化。 3 它通过自注意力机制促进了单词与指令动词的关系的学习,特别是在中下层,表明对指令单词的识别得到了增强。这些见解有助于更深入地了解法学硕士在指令微调后的行为变化,并为未来旨在解释和优化法学硕士各种应用的研究奠定基础。 |
| It HAS to be Subjective: Human Annotator Simulation via Zero-shot Density Estimation Authors Wen Wu, Wenlin Chen, Chao Zhang, Philip C. Woodland 人工注释器模拟 HAS 可作为数据注释和系统评估等人工评估的经济高效替代品。由于不同的认知过程和主观解释,人类评估过程中的人类感知和行为表现出固有的可变性,在建模时应考虑到这一点,以更好地模仿人们感知和与世界互动的方式。本文介绍了一种新颖的元学习框架,该框架将 HAS 视为零射击密度估计问题,该框架结合了人类可变性,并允许为未标记的测试输入有效生成类似人类的注释。在此框架下,我们提出了两个新的模型类,条件整数流和条件 softmax 流,分别解释序数和分类注释。 |
| Enhancing Representation Generalization in Authorship Identification Authors Haining Wang 作者身份识别可确定来源未公开的文本的作者身份。作者身份识别技术之所以能够如此可靠地发挥作用,是因为作者的风格得到了正确的捕捉和体现。尽管现代作者身份识别方法多年来已经取得了显着的发展,并且已被证明在区分作者风格方面是有效的,但跨领域的风格特征的概括尚未得到系统的审查。所提出的工作解决了增强作者身份识别中风格表征的泛化的挑战,特别是当训练样本和测试样本之间存在差异时。对实证研究进行了全面回顾,重点关注各种文体特征及其在代表作者风格方面的有效性。还探讨了主题、体裁和写作风格的语体等影响因素,以及减轻其影响的策略。虽然一些文体特征(例如字符 n 克和功能词)已被证明是稳健且具有区分性的,但其他文体特征(例如内容词)可能会引入偏差并阻碍跨领域泛化。使用深度学习模型学习的表示,尤其是那些包含字符 n 元语法和句法信息的表示,在增强表示泛化方面表现出了希望。研究结果强调了选择适当的风格特征来识别作者身份的重要性,特别是在跨领域场景中。 |
| Open-Domain Dialogue Quality Evaluation: Deriving Nugget-level Scores from Turn-level Scores Authors Rikiya Takehi, Akihisa Watanabe, Tetsuya Sakai 现有的对话质量评估系统可以从特定的角度(例如参与度)返回给定系统的分数。然而,为了通过准确定位系统中潜在问题所在来改进对话系统,可能需要更细粒度的评估。因此,我们提出了一种评估方法,其中将回合分解为金块,即与对话行为相关的表达式,并通过利用现有的回合级别评估系统来启用金块级别评估。 |
| Dynamic Demonstrations Controller for In-Context Learning Authors Fei Zhao, Taotian Pang, Zhen Wu, Zheng Ma, Shujian Huang, Xinyu Dai 在上下文学习中,ICL 是自然语言处理 NLP 的一种新范式,其中大型语言模型 LLM 观察少量演示和测试实例作为其输入,并直接进行预测而不更新模型参数。先前的研究表明,ICL 对演示的选择和顺序很敏感。然而,在LLM有限的输入长度内,关于演示次数对ICL性能影响的研究很少,因为人们普遍认为演示次数与模型性能正相关。在本文中,我们发现这个结论并不总是成立。通过试点实验,我们发现增加演示次数并不一定会带来性能的提高。基于这一见解,我们提出了动态演示控制器 D 2 控制器,它可以通过动态调整演示数量来提高 ICL 性能。实验结果表明,D 2 Controller 在 10 个数据集的 8 个不同大小的 LLM 上产生了 5.4 的相对改进。 |
| Measuring Value Understanding in Language Models through Discriminator-Critique Gap Authors Zhaowei Zhang, Fengshuo Bai, Jun Gao, Yaodong Yang 大型语言模型法学硕士的最新进展加剧了人们对其潜在与人类价值观不一致的担忧。然而,由于其复杂性和适应性,评估他们对这些价值观的掌握是复杂的。我们认为,真正理解法学硕士的价值观需要同时考虑“知道什么”和“知道为什么”。为此,我们提出了价值理解测量 VUM 框架,该框架通过测量与人类价值观相关的鉴别器批判差距来定量评估“知道什么”和“知道为什么”。使用 Schwartz 价值调查,我们指定我们的评估值并使用 GPT 4 开发千级对话数据集。我们的评估着眼于 LLM 输出与基线答案相比的价值一致性,以及 LLM 响应与 GPT 相比如何与价值认可的原因相一致4 注释。我们评估了五位具有代表性的法学硕士,并提供了强有力的证据,证明标度法则显着影响“知道什么”,但对“知道为什么”影响不大,而“知道为什么”一直保持较高水平。 |
| AutomaTikZ: Text-Guided Synthesis of Scientific Vector Graphics with TikZ Authors Jonas Belouadi, Anne Lauscher, Steffen Eger 从文本生成位图图形已引起相当多的关注,但对于科学图形,矢量图形通常是首选。鉴于矢量图形通常使用低级图形基元进行编码,因此直接生成它们很困难。为了解决这个问题,我们建议使用 TikZ,一种众所周知的抽象图形语言,可以编译为矢量图形,作为科学图形的中间表示。 TikZ 提供以人为本的高级命令,从而促进任何大型语言模型的条件语言建模。为此,我们引入了 DaTikZ,这是第一个大规模 TikZ 数据集,由 120k 与标题对齐的 TikZ 绘图组成。我们在 DaTikZ 上微调 LLaMA,以及我们的新模型 CLiMA,它通过多模态 CLIP 嵌入增强了 LLaMA。在人类和自动评估中,CLiMA 和 LLaMA 在与人类创建的图形的相似性方面优于商业 GPT 4 和 Claude 2,并且 CLiMA 还改进了文本图像对齐。我们的详细分析表明,所有模型都具有良好的泛化性并且不易被记忆。然而,与人类和我们的模型相比,GPT 4 和 Claude 2 往往会生成更简单的数字。 |
| Gaze-Driven Sentence Simplification for Language Learners: Enhancing Comprehension and Readability Authors Taichi Higasa, Keitaro Tanaka, Qi Feng, Shigeo Morishima 语言学习者应该定期阅读具有挑战性的材料,作为日常学习的一部分。然而,不断查阅词典既耗时又分散注意力。本文提出了一种新颖的凝视驱动句子简化系统,旨在增强阅读理解能力,同时保持对内容的关注。我们的系统结合了为个人学习者量身定制的机器学习模型,结合眼睛注视特征和语言特征来评估句子理解能力。当系统识别出理解困难时,它会通过 GPT 3.5 用更简单的替代方案替换复杂的词汇和语法,从而提供简化版本。我们对 19 名英语学习者进行了一项实验,收集他们阅读英文文本时眼球运动的数据。结果表明,我们的系统能够准确估计句子水平的理解。 |
| Unlocking Bias Detection: Leveraging Transformer-Based Models for Content Analysis Authors Shaina Raza, Oluwanifemi Bamgbose, Veronica Chatrath, Yan Sidyakin, Shardul Ghuge, Abdullah Y Muaad 检测文本中的偏见至关重要,因为它可能会对延续有害的刻板印象、传播错误信息和影响决策产生影响。现有的语言模型通常难以概括其训练数据之外的内容。为了应对这一挑战,我们提出了上下文化双向双变压器 CBDT 分类器,它利用两个互连的变压器网络(上下文变压器和实体变压器)来检测文本中的偏差。不同数据集上的实验结果证明了 CBDT 分类器在准确分类有偏见和无偏见句子以及识别特定有偏见单词和短语方面的优越性。与基线相比,我们的性能提升了大约 2 4。 |
| Red Teaming Game: A Game-Theoretic Framework for Red Teaming Language Models Authors Chengdong Ma, Ziran Yang, Minquan Gao, Hai Ci, Jun Gao, Xuehai Pan, Yaodong Yang 可部署的大语言模型法学硕士必须符合有益无害的标准,从而实现法学硕士输出与人类价值观的一致性。红队技术是实现这一标准的关键途径。现有的工作仅依赖于手动红队设计和启发式对抗提示来进行漏洞检测和优化。这些方法缺乏严格的数学公式,从而限制了在可量化的测量范围内探索不同的攻击策略以及在收敛保证下对 LLM 的优化。在本文中,我们提出了 Red teaming Game RTG,这是一种无需手动注释的通用博弈理论框架。 RTG旨在分析红队语言模型RLM和蓝队语言模型BLM之间的多回合攻防交互。在 RTG 中,我们提出游戏化的 Red 组合 Solver GRTS 以及语义空间的多样性度量。 GRTS 是一种自动化的红队技术,通过元博弈分析解决 RTG 走向纳什均衡,这对应于 RLM 和 BLM 理论上保证的优化方向。 RLM多轮攻击的实证结果表明,GRTS自主发现了多种攻击策略,有效提高了LLM的安全性,优于现有的启发式红队设计。 |
| In-Context Learning in Large Language Models: A Neuroscience-inspired Analysis of Representations Authors Safoora Yousefi, Leo Betthauser, Hosein Hasanbeig, Akanksha Saran, Rapha l Milli re, Ida Momennejad 大型语言模型法学硕士通过利用输入中的任务特定示例进行上下文学习 ICL,表现出显着的性能改进。然而,这种改进背后的机制仍然难以捉摸。在这项工作中,我们研究了 LLM 嵌入和注意力表示在上下文学习中如何变化,以及这些变化如何调节行为的改善。我们采用神经科学启发的技术,例如表征相似性分析 RSA,并提出了参数化探测和测量 Llama 2 70B 和 Vicuna 13B 中相关与不相关信息的注意力比率的新方法。我们设计了三个任务,其条件阅读理解、线性回归和对抗性提示注入之间存在先验关系。我们提出了关于任务表示的预期相似性的假设,以研究嵌入和注意力的潜在变化。我们的分析揭示了嵌入和注意力表征的变化与 ICL 后行为表现的改善之间存在有意义的相关性。 |
| Towards LLM-based Fact Verification on News Claims with a Hierarchical Step-by-Step Prompting Method Authors Xuan Zhang, Wei Gao 虽然大型预训练语言模型法学硕士在各种 NLP 任务中表现出了令人印象深刻的能力,但它们在错误信息领域仍处于探索之中。在本文中,我们研究了使用上下文学习 ICL 进行新闻主张验证的法学硕士,发现仅通过 4 个镜头演示示例,几种提示方法的性能就可以与以前的监督模型相媲美。为了进一步提高性能,我们引入了分层逐步 HiSS 提示方法,该方法指导法学硕士将一项权利要求分为多个子权利要求,然后通过多个问题回答步骤逐步验证每个子权利要求。 |
| RelBERT: Embedding Relations with Language Models Authors Asahi Ushio, Jose Camacho Collados, Steven Schockaert 许多应用程序需要访问有关不同概念和实体如何关联的背景知识。虽然知识图谱知识图谱和大型语言模型法学硕士可以在一定程度上解决这一需求,但知识图谱不可避免地存在不完备性,其关系模式往往过于粗粒度,而法学硕士则效率低下且难以控制。作为替代方案,我们建议从相对较小的语言模型中提取关系嵌入。特别是,我们表明,仅使用少量训练数据,就可以直接对 RoBERTa 等屏蔽语言模型进行微调以实现此目的。由此产生的模型,我们称之为 RelBERT,以令人惊讶的细粒度方式捕获关系相似性,使我们能够在类比基准中设定新的最先进水平。至关重要的是,RelBERT 能够对远远超出模型在训练期间看到的关系进行建模。例如,我们使用仅接受概念之间词汇关系训练的模型,在命名实体之间的关系上获得了强有力的结果,并且我们观察到,尽管没有接受此类示例的训练,RelBERT 仍可以识别形态类比。 |
| Understanding In-Context Learning from Repetitions Authors Jianhao Yan, Jin Xu, Chiyu Song, Chenming Wu, Yafu Li, Yue Zhang 本文探讨了大型语言模型法学硕士情境学习中难以捉摸的机制。我们的工作通过表面重复的镜头检查情境学习,提供了一种新颖的视角。我们定量研究了表面特征在文本生成中的作用,并凭经验建立了 emph 标记共现强化的存在,这是一种基于两个标记的上下文共现来加强两个标记之间关系的原理。通过调查这些特征的双重影响,我们的研究阐明了情境学习的内部运作原理,并阐述了其失败的原因。 |
| AfriSpeech-200: Pan-African Accented Speech Dataset for Clinical and General Domain ASR Authors Tobi Olatunji, Tejumade Afonja, Aditya Yadavalli, Chris Chinenye Emezue, Sahib Singh, Bonaventure F.P. Dossou, Joanne Osuchukwu, Salomey Osei, Atnafu Lambebo Tonja, Naome Etori, Clinton Mbataku 非洲的医生与病人的比例非常低。在非常繁忙的诊所,医生每天可以看诊 30 名患者,与发达国家相比,患者负担很重,但这些过度劳累的临床医生缺乏临床自动语音识别 ASR 等生产力工具。然而,临床 ASR 在发达国家已经成熟,甚至无处不在,临床医生报告的商业临床 ASR 系统的性能总体令人满意。此外,通用领域 ASR 的最新性能正在接近人类准确性。然而,存在一些差距。一些出版物强调了语音到文本算法的种族偏见,并且少数族裔口音的表现明显滞后。据我们所知,没有关于非洲口音的临床 ASR 的公开研究或基准,并且大多数非洲口音的语音数据也不存在。 |
| Investigating the Efficacy of Large Language Models in Reflective Assessment Methods through Chain of Thoughts Prompting Authors Baphumelele Masikisiki, Vukosi Marivate, Yvette Hlope 大型语言模型,例如生成式预训练 Transformer 3(又名)。 GPT 3 的开发目的是通过分析大量文本数据来理解语言,从而使他们能够识别单词之间的模式和联系。虽然法学硕士在各种文本相关任务中表现出了令人印象深刻的表现,但他们在与推理相关的任务中遇到了挑战。为了应对这一挑战,思想链 CoT 提示方法被提出,作为提高法学硕士在复杂推理任务(例如解决数学应用问题和基于逻辑论证推理回答问题)方面的熟练程度的一种手段。这项研究的主要目的是评估四种语言模型对三年级医学生的反思性论文进行评分的效果。 |
| AutoHall: Automated Hallucination Dataset Generation for Large Language Models Authors Zouying Cao, Yifei Yang, Hai Zhao 虽然大型语言模型法学硕士因其强大的语言理解和生成能力而在各个领域获得了广泛的应用,但对法学硕士生成的非事实或幻觉内容的检测仍然很少。目前,幻觉检测的一项重大挑战是对幻觉生成进行耗时且昂贵的手动注释是一项艰巨的任务。为了解决这个问题,本文首先介绍了一种基于现有事实检查数据集自动构建模型特定幻觉数据集的方法,称为 AutoHall。此外,我们提出了一种基于自相矛盾的零资源和黑盒幻觉检测方法。我们对流行的开源闭源法学硕士进行了实验,与现有基线相比,实现了卓越的幻觉检测性能。 |
| SLM: Bridge the thin gap between speech and text foundation models Authors Mingqiu Wang, Wei Han, Izhak Shafran, Zelin Wu, Chung Cheng Chiu, Yuan Cao, Yongqiang Wang, Nanxin Chen, Yu Zhang, Hagen Soltau, Paul Rubenstein, Lukas Zilka, Dian Yu, Zhong Meng, Golan Pundak, Nikhil Siddhartha, Johan Schalkwyk, Yonghui Wu 我们提出了联合语音和语言模型 SLM,这是一种多任务、多语言和双模态模型,它利用了预训练的基础语音和语言模型。 SLM冻结预训练的基础模型以最大程度地保留其能力,并且仅训练具有仅1 156M基础模型参数的简单适配器。这种适应不仅使 SLM 在语音识别 ASR 和语音翻译 AST 等传统任务上取得了强大的性能,而且还引入了零样本指令跟踪的新颖功能,可以在给定语音输入和文本指令的情况下执行更多样化的任务,SLM 能够执行看不见的生成任务,包括使用实时上下文的上下文偏置 ASR、对话生成、语音延续和问题回答等。我们的方法表明,预训练语音和语言模型之间的表征差距可能比人们预期的要窄,并且可以通过简单的适应机制桥接。 |
| Detecting Unseen Multiword Expressions in American Sign Language Authors Lee Kezar, Aryan Shukla 多词表达在许多翻译任务中提出了独特的挑战。为了最终将多词表达检测系统应用于美国手语的翻译,我们构建并测试了两个应用 GloVe 的词嵌入的系统,以确定词位的词嵌入是否可用于预测那些词素组成多词表达式。 |
| Finding Pragmatic Differences Between Disciplines Authors Lee Kezar, Jay Pujara 学术文献在内容语义和结构语用方面都有很大程度的差异。学术文档理解方面的先前工作通过文档摘要和语料库主题建模强调语义,但往往忽略文档组织和流程等语用学。使用跨 19 个学科的学术文档语料库和最先进的语言建模技术,我们学习一组固定的文档部分的领域不可知描述符,并将语料库改造为这些描述符(也称为规范化)。然后,我们分析这些描述符在文档中的位置和顺序,以了解学科和结构之间的关系。我们报告学科内的结构原型、变异性以及学科之间的比较,支持这样的假设:学术界尽管规模、多样性和广度不同,但都共享相似的表达其工作的途径。 |
| The Sem-Lex Benchmark: Modeling ASL Signs and Their Phonemes Authors Lee Kezar, Elana Pontecorvo, Adele Daniels, Connor Baer, Ruth Ferster, Lauren Berger, Jesse Thomason, Zed Sevcikova Sehyr, Naomi Caselli 手语识别和翻译技术有潜力增加聋人手语社区的接触和包容性,但由于缺乏代表性数据,研究进展受到瓶颈。我们引入了美国手语 ASL 建模的新资源,即 Sem Lex 基准。该基准是目前同类产品中最大的,由超过 84,000 个来自聋哑 ASL 手语者制作的独立手语视频组成,这些手语者给予了知情同意并获得了补偿。人类专家将这些视频与其他手语资源(包括 ASL LEX、SignBank 和 ASL Citizen)结合起来,从而实现了手语和语音特征识别的有用扩展。我们提出了一系列利用 ASL LEX 中的语言信息的实验,评估 Sem Lex 基准用于孤立符号识别 ISR 的实用性和公平性。我们使用 SL GCN 模型表明语音特征的识别精度为 85,并且它们作为 ISR 的辅助目标是有效的。学习识别语音特征和光泽度可以使少数镜头 ISR 准确度提高 6 倍,整体 ISR 准确度提高 2 倍。 |
| Exploring Strategies for Modeling Sign Language Phonology Authors Lee Kezar, Riley Carlin, Tejas Srinivasan, Zed Sehyr, Naomi Caselli, Jesse Thomason 与语音一样,符号由离散的、可重组的特征(称为音素)组成。先前的工作表明,能够识别音素的模型在符号识别方面表现得更好,这激发了对手语音素建模策略的更深入探索。在这项工作中,我们学习图卷积网络来识别 ASL LEX 2.0 中发现的 16 种音素类型。具体来说,我们探讨了多任务和课程学习等学习策略如何利用音素类型之间相互有用的信息来促进更好的手语音素建模。 |
| Contextual Biasing with the Knuth-Morris-Pratt Matching Algorithm Authors Weiran Wang, Zelin Wu, Diamantino Caseiro, Tsendsuren Munkhdalai, Khe Chai Sim, Pat Rondon, Golan Pundak, Gan Song, Rohit Prabhavalkar, Zhong Meng, Ding Zhao, Tara Sainath, Pedro Moreno Mengibar 上下文偏差是指自动语音识别 ASR 系统偏向与特定用户或应用场景相关的稀有实体的问题。我们提出基于 Knuth Morris Pratt 模式匹配算法的上下文偏差算法。在束搜索期间,如果将匹配扩展为一组偏置短语,我们会提高标记扩展的分数。我们的方法模拟了通常在加权有限状态传感器 WFST 框架中实现的经典方法,但完全避免了 FST 语言,并仔细考虑了矢量化的张量处理单元 TPU 的内存占用和效率。 |
| Self-Specialization: Uncovering Latent Expertise within Large Language Models Authors Junmo Kang, Hongyin Luo, Yada Zhu, James Glass, David Cox, Alan Ritter, Rogerio Feris, Leonid Karlinsky 最近的工作证明了自对齐的有效性,其中大型语言模型本身通过使用少量人类书面种子自动生成指导数据来对齐以遵循一般指令。在这项工作中,我们不是一般对准,而是专注于专家领域专业化的自对准,例如生物医学,发现它对于提高感兴趣的目标领域中的零射击和少射击性能非常有效。作为初步,我们首先展示专业领域内现有对齐模型的基准结果,这揭示了训练后的通用指令对下游专家领域性能的边际效应。为了解决这个问题,我们探索自我专业化,利用特定领域的未标记数据和一些标记种子来进行自对齐过程。当通过检索增强以减少幻觉并增强对齐的并发性时,自我专业化提供了一种有效且高效的方法,可以从通才、预训练的法学硕士中雕刻出专家模型,其中不同的专业领域最初以叠加的形式组合在一起。我们在生物医学领域的实验结果表明,我们的自专业化模型 30B 大幅优于其基础模型 MPT 30B,甚至超过了基于 LLaMA 65B 的更大流行模型,凸显了其专业化的潜力和实用性,特别是考虑到其在方面的效率 |
| Automatic Prompt Rewriting for Personalized Text Generation Authors Cheng Li, Mingyang Zhang, Qiaozhu Mei, Weize Kong, Michael Bendersky 在大型语言模型法学硕士的推动下,个性化文本生成已成为一个快速发展的研究方向。大多数现有研究侧重于为特定领域设计专门模型,或者需要对法学硕士进行微调以生成个性化文本。我们考虑一个典型的场景,其中生成个性化输出的大型语言模型被冻结,只能通过 API 访问。在这种限制下,人们所能做的就是改进输入文本,即发送给法学硕士的文本提示,这一过程通常是手动完成的。在本文中,我们提出了一种自动修改个性化文本生成提示的新颖方法。所提出的方法采用最先进的多阶段框架生成的初始提示来进行个性化生成,并重写了一些总结和综合个人背景的关键组件。提示重写器采用了一种将监督学习 SL 和强化学习 RL 链接在一起的训练范式,其中 SL 减少了 RL 的搜索空间,而 RL 则有利于重写器的端到端训练。使用来自三个代表性领域的数据集,我们证明重写的提示优于原始提示和仅通过监督学习或强化学习优化的提示。对重写提示的深入分析表明,它们不仅具有人类可读性,而且当资源有限,无法采用强化学习来训练提示重写器时,或者当部署自动提示成本高昂时,它们还能够指导手动修改提示 |
| The Gift of Feedback: Improving ASR Model Quality by Learning from User Corrections through Federated Learning Authors Lillian Zhou, Yuxin Ding, Mingqing Chen, Harry Zhang, Rohit Prabhavalkar, Dhruv Guliani, Giovanni Motta, Rajiv Mathews 自动语音识别 ASR 模型通常在大型转录语音数据集上进行训练。随着语言的发展和新术语的使用,这些模型可能会变得过时和陈旧。在服务器上训练但部署在边缘设备上的模型中,服务器训练数据与实际设备使用情况之间的不匹配可能会导致错误。在这项工作中,我们寻求通过联邦学习 FL 不断学习设备上用户的修正来解决这个问题。我们探索针对模型以前没有遇到过的新术语、学习长尾词并减轻灾难性遗忘的技术。 |
| Multilingual Natural Language ProcessingModel for Radiology Reports -- The Summary is all you need! Authors Mariana Lindo, Ana Sofia Santos, Andr Ferreira, Jianning Li, Gijs Luijten, Gustavo Correia, Moon Kim, Jens Kleesiek, Jan Egger, Victor Alves 放射学报告的印象部分总结了重要的放射学发现,并在向医生传达这些发现方面发挥着关键作用。然而,对于放射科医生来说,准备这些摘要非常耗时且容易出错。最近,已经开发了许多放射学报告总结模型。然而,目前还没有模型可以用多种语言总结这些报告。这样的模型可以极大地改善未来的研究和深度学习模型的开发,该模型融合了来自不同种族背景的患者的数据。在这项研究中,通过微调公开可用的模型,自动生成不同语言的放射学印象,该模型基于多语言文本到文本 Transformer,以总结英语、葡萄牙语和德语放射学报告中的发现结果。在盲测中,两名经过委员会认证的放射科医生表示,系统生成的至少 70 个摘要的质量与相应的人类书面摘要相匹配或超过了相应的人工书面摘要,这表明临床可靠性很高。 |
| Voice2Action: Language Models as Agent for Efficient Real-Time Interaction in Virtual Reality Authors Yang Su 大型语言模型法学硕士经过训练和调整,只需少量示例即可遵循自然语言指令,并且它们被提示为任务驱动的自主代理,以适应各种执行环境来源。然而,由于在线交互效率低下以及 3D 环境中复杂的操作类别,在虚拟现实 VR 中部署代理法学硕士一直具有挑战性。在这项工作中,我们提出了 Voice2Action,一个框架,通过动作和实体提取来分层分析定制的语音信号和文本命令,并将执行任务实时划分为规范的交互子集,并通过环境反馈防止错误。 |
| SocREval: Large Language Models with the Socratic Method for Reference-Free Reasoning Evaluation Authors Hangfeng He, Hongming Zhang, Dan Roth 为了全面评估当前模型的复杂推理能力,以可扩展的方式评估其逐步推理至关重要。已建立的基于参考的评估指标依赖于人类注释的推理链来评估模型派生链。然而,这种黄金标准的人类书面推理链可能并不是独一无二的,而且它们的获取通常是劳动密集型的。现有的无参考推理指标消除了对人工推理链作为参考的需要,但它们通常需要使用人工推理链对数据集进行微调,这使过程复杂化并引发了对不同数据集之间的泛化性的担忧。为了应对这些挑战,我们利用 GPT 4 自动评估推理链质量,从而无需人工制作参考。利用苏格拉底方法,我们设计了定制的提示来增强无参考推理评估,我们将其称为 SocREval 苏格拉底推理评估方法。四个人工注释数据集的实证结果表明,SocREval 显着提高了 GPT 4 的性能,超越了现有的无参考和基于参考的推理评估指标。 |
| GPT-Driver: Learning to Drive with GPT Authors Jiageng Mao, Yuxi Qian, Hang Zhao, Yue Wang 我们提出了一种简单而有效的方法,可以将 OpenAI GPT 3.5 模型转变为自动驾驶车辆的可靠运动规划器。运动规划是自动驾驶的核心挑战,旨在规划安全舒适的驾驶轨迹。现有的运动规划器主要利用启发式方法来预测驾驶轨迹,但这些方法在面对新奇和未见过的驾驶场景时表现出不足的泛化能力。在本文中,我们提出了一种新的运动规划方法,该方法利用了大型语言模型法学硕士固有的强大推理能力和泛化潜力。我们方法的基本见解是将运动规划重新表述为语言建模问题,这是以前未探讨过的观点。具体来说,我们将规划器的输入和输出表示为语言标记,并利用 LLM 通过坐标位置的语言描述生成驾驶轨迹。此外,我们提出了一种新颖的提示推理微调策略来激发法学硕士的数字推理潜力。通过这种策略,法学硕士可以用自然语言描述高精度的轨迹坐标及其内部决策过程。我们在大规模 nuScenes 数据集上评估了我们的方法,并且广泛的实验证实了我们基于 GPT 的运动规划器的有效性、泛化能力和可解释性。 |
| Representation Engineering: A Top-Down Approach to AI Transparency Authors Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann Kathrin Dombrowski, Shashwat Goel, Nathaniel Li, Michael J. Byun, Zifan Wang, Alex Mallen, Steven Basart, Sanmi Koyejo, Dawn Song, Matt Fredrikson, J. Zico Kolter, Dan Hendrycks 在本文中,我们确定并描述了表示工程 RepE 的新兴领域,这是一种利用认知神经科学的见解来提高人工智能系统透明度的方法。 RepE 将群体水平表征(而不是神经元或电路)置于分析的中心,为我们提供了监测和操纵深度神经网络 DNN 中高级认知现象的新方法。我们提供了 RepE 技术的基线和初步分析,表明它们为提高我们对大型语言模型的理解和控制提供了简单而有效的解决方案。我们展示了这些方法如何为广泛的安全相关问题提供动力,包括诚实、无害、权力寻求等,展示了自上而下的透明度研究的前景。 |
| DiffAR: Denoising Diffusion Autoregressive Model for Raw Speech Waveform Generation Authors Roi Benita, Michael Elad, Joseph Keshet 最近已证明扩散模型与高质量语音生成相关。大多数工作都集中在生成频谱图,因此,他们进一步需要后续模型将频谱图转换为波形,即声码器。这项工作提出了一种用于生成原始语音波形的扩散概率端到端模型。所提出的模型是自回归的,顺序生成重叠帧,其中每个帧都以先前生成的帧的一部分为条件。因此,我们的模型可以有效地合成无限的语音持续时间,同时保持高保真合成和时间相干性。我们实现了所提出的无条件和条件语音生成模型,其中后者可以由音素、幅度和音调值的输入序列驱动。直接处理波形具有一些经验优势。具体来说,它允许创建局部声学行为,例如声音炸裂,这使得整体波形听起来更自然。此外,所提出的扩散模型是随机的而不是确定性的,因此,每个推论都会生成略有不同的波形变化,从而实现丰富的有效实现。 |
| GenSim: Generating Robotic Simulation Tasks via Large Language Models Authors Lirui Wang, Yiyang Ling, Zhecheng Yuan, Mohit Shridhar, Chen Bao, Yuzhe Qin, Bailin Wang, Huazhe Xu, Xiaolong Wang 收集大量现实世界交互数据来训练一般机器人策略通常成本高昂,因此激发了模拟数据的使用。然而,由于提出和验证新任务需要人力,现有的数据生成方法通常关注场景级别的多样性,例如对象实例和姿势,而不是任务级别的多样性。这使得在模拟数据上训练的策略难以展示重要的任务级别泛化能力。在本文中,我们建议通过利用大型语言模型LLM基础和编码能力来自动生成丰富的模拟环境和专家演示。我们的方法被称为 GenSim,有两种模式:目标导向生成,其中目标任务被赋予 LLM,LLM 提出一个任务课程来解决目标任务;以及探索性生成,其中 LLM 从先前的任务中引导并迭代地提出新的任务有助于解决更复杂任务的任务。我们使用 GPT4 将现有基准扩展十倍,达到 100 多个任务,并在这些任务上进行监督微调并评估多个 LLM,包括微调的 GPT 和针对机器人模拟任务的代码生成的 Code Llama。此外,我们观察到法学硕士生成的模拟程序在用于多任务策略训练时可以显着增强任务级别的泛化能力。我们进一步发现,通过最小的模拟到真实的适应,在 GPT4 生成的模拟任务上预训练的多任务策略表现出更强的迁移到现实世界中看不见的长期任务,并且比基线高 25 。 |
| Merge, Then Compress: Demystify Efficient SMoE with Hints from Its Routing Policy Authors Pingzhi Li, Zhenyu Zhang, Prateek Yadav, Yi Lin Sung, Yu Cheng, Mohit Bansal, Tianlong Chen 稀疏激活的专家混合 SMoE 已显示出扩大神经网络学习能力的希望,但是,由于将网络层复制为专家的多个副本,因此它们存在内存使用率高等问题,以及常见的专家冗余基于学习的路由策略遭受代表性崩溃。因此,普通的 SMoE 模型内存效率低且不可扩展,特别是对于资源受限的下游场景。在本文中,我们问我们能否通过整合专家信息来制作一个紧凑的 SMoE 模型?将多个专家合并为更少但知识更丰富的专家的最佳方法是什么?我们的试点调查表明,传统的模型合并方法在此类专家合并中无法有效SMoE。潜在的原因是 1 冗余信息掩盖了关键专家的光芒 2 缺少每个专家的适当神经元排列以使所有专家保持一致。为了解决这个问题,我们提出了 M SMoE,它利用路由统计来指导专家合并。具体来说,首先对专家进行神经元排列对齐,最后形成主导专家及其组成员,利用每个专家的激活频率作为合并权重,将每个专家组合并为单个专家,从而减少不显着的影响。专家。此外,我们观察到我们提出的合并促进了合并专家权重空间的低维度,自然为额外压缩铺平了道路。因此,我们的最终方法 MC SMoE 即合并,然后压缩 SMoE,进一步将合并的专家分解为低等级和结构稀疏的替代方案。跨 8 个基准的大量实验验证了 MC SMoE 的有效性。 |
| Avalon's Game of Thoughts: Battle Against Deception through Recursive Contemplation Authors Shenzhi Wang, Chang Liu, Zilong Zheng, Siyuan Qi, Shuo Chen, Qisen Yang, Andrew Zhao, Chaofei Wang, Shiji Song, Gao Huang 最近在大型语言模型方面的突破让法学硕士在法学硕士作为代理领域取得了显着的成功。然而,一个普遍的假设是法学硕士处理的信息始终是诚实的,忽略了人类社会和人工智能生成的内容中普遍存在的欺骗性或误导性信息。这种监督使得法学硕士容易受到恶意操纵,可能导致有害结果。本研究利用复杂的 Avalon 游戏作为测试平台,探索法学硕士在欺骗性环境中的潜力。 《阿瓦隆》充满了错误信息,需要复杂的逻辑,表现为一场思想游戏。受到阿瓦隆游戏中人类递归思维和观点采择功效的启发,我们引入了一种新颖的框架——递归思考 ReCon,以增强法学硕士识别和抵制欺骗性信息的能力。 ReCon 将公式化和细化沉思结合起来,公式化沉思产生最初的思想和言语,而细化沉思则进一步完善它们。此外,我们分别将一阶和二阶透视转换合并到这些过程中。具体来说,第一顺序允许LLM代理人推断其他人的心理状态,第二顺序涉及了解其他人如何感知代理人的心理状态。将 ReCon 与不同的 LLM 集成后,Avalon 游戏的大量实验结果表明,它可以有效地帮助 LLM 识别和操纵欺骗性信息,而无需额外的微调和数据。 |
| Co-audit: tools to help humans double-check AI-generated content Authors Andrew D. Gordon, Carina Negreanu, Jos Cambronero, Rasika Chakravarthy, Ian Drosos, Hao Fang, Bhaskar Mitra, Hannah Richardson, Advait Sarkar, Stephanie Simmons, Jack Williams, Ben Zorn 越来越多的用户被警告要检查人工智能生成的内容的正确性。尽管如此,随着法学硕士和其他生成模型生成更复杂的输出,例如摘要、表格或代码,用户审核或评估输出的质量或正确性变得更加困难。因此,我们看到工具辅助体验的出现,可以帮助用户仔细检查人工智能生成的内容。我们将这些称为联合审计工具。协同审计工具补充了提示工程技术,一种帮助用户构建输入提示,而另一种帮助他们检查输出响应。作为一个具体示例,本文描述了由生成模型支持的电子表格计算协同审计工具的最新研究。我们解释了为什么联合审计经验对于任何生成式人工智能应用都至关重要,因为质量很重要,错误也很严重,这在电子表格计算中很常见。 |
| ScaLearn: Simple and Highly Parameter-Efficient Task Transfer by Learning to Scale Authors Markus Frohmann, Carolin Holtermann, Shahed Masoudian, Anne Lauscher, Navid Rekabsaz 多任务学习 MTL 已显示出相当大的实际好处,特别是在使用预先训练的语言模型 PLM 时。虽然这通常是通过在联合优化过程下同时学习 n 个任务来实现的,但最近的方法(例如 AdapterFusion)将问题分为两个不同的阶段:i 任务学习,其中特定于任务的知识被封装在参数组(例如适配器)中,ii 传输,其中已经学到的知识被用于目标任务。这种关注点分离提供了许多好处,例如促进可重用性、解决涉及数据隐私和社会问题的案例,但另一方面,当前的两阶段 MTL 方法却需要引入大量附加参数。在这项工作中,我们通过利用线性缩放源适配器的输出表示进行迁移学习的有用性来解决这个问题。我们引入了 ScaLearn,这是一种简单且参数效率高的两阶段 MTL 方法,它通过学习最小的缩放参数集来利用源任务的知识,从而能够有效地将知识转移到目标任务。我们在 GLUE、SuperGLUE 和 HumSet 三个基准测试上的实验表明,我们的 ScaLearn 除了能够发挥两阶段 MTL 的优势之外,还始终优于强大的基线,其传输参数数量很少,约为 AdapterFusion 的 0.35。值得注意的是,我们观察到,即使通过统一缩放和层共享进一步减少参数,ScaLearn 仍保持其强大的能力,每个目标任务仅用 8 个传输参数即可实现类似的竞争结果。 |
| uSee: Unified Speech Enhancement and Editing with Conditional Diffusion Models Authors Muqiao Yang, Chunlei Zhang, Yong Xu, Zhongweiyang Xu, Heming Wang, Bhiksha Raj, Dong Yu 语音增强旨在提高语音信号的质量和清晰度,而语音编辑是指根据特定用户需求对语音进行编辑的过程。在本文中,我们提出了一种带有条件扩散模型的统一语音增强和编辑 uSee 模型,以生成的方式同时处理各种任务。具体来说,通过向基于分数的扩散模型提供包括自监督学习嵌入和适当的文本提示在内的多种类型的条件,我们可以实现统一语音增强和编辑模型的可控生成,以对源语音执行相应的操作。我们的实验表明,与其他相关的生成语音增强模型相比,我们提出的 uSee 模型可以在语音去噪和去混响方面实现优异的性能,并且可以在给定所需的环境声音文本描述、信噪比 SNR 和房间脉冲响应 RIR 的情况下执行语音编辑。 |
| Sparse Backpropagation for MoE Training Authors Liyuan Liu, Jianfeng Gao, Weizhu Chen 专家 MoE 模型混合的一个定义特征是它们能够通过专家路由进行稀疏计算,从而实现显着的可扩展性。然而,深度学习的基石反向传播需要密集计算,从而给 MoE 梯度计算带来了挑战。在这里,我们介绍 SparseMixer,一种可扩展的梯度估计器,它弥补了反向传播和稀疏专家路由之间的差距。与典型的 MoE 训练为了稀疏计算和可扩展性而策略性地忽略某些梯度项不同,SparseMixer 为这些项提供可扩展的梯度近似值,从而在 MoE 训练中实现可靠的梯度估计。 SparseMixer 基于数值 ODE 框架,利用中点法(二阶 ODE 求解器)以可忽略的计算开销提供精确的梯度近似值。 |
| Analyzing and Mitigating Object Hallucination in Large Vision-Language Models Authors Yiyang Zhou, Chenhang Cui, Jaehong Yoon, Linjun Zhang, Zhun Deng, Chelsea Finn, Mohit Bansal, Huaxiu Yao 大型视觉语言模型 LVLM 在用人类语言理解视觉信息方面表现出了卓越的能力。然而,LVLM 仍然存在物体幻觉的问题,即生成包含图像中实际不存在的物体的描述的问题。这可能会对许多视觉语言任务产生负面影响,例如视觉摘要和推理。为了解决这个问题,我们提出了一种简单而强大的算法,LVLM Hallucination Revisor LURE,通过重建较少的幻觉描述来事后纠正 LVLM 中的对象幻觉。 LURE基于对物体幻觉的关键因素进行严格的统计分析,包括图像中某些物体与其他物体频繁出现的共现,LVLM解码过程中不确定性较高的不确定物体,以及物体位置幻觉经常出现在图像的后期。生成的文本。 LURE 还可以与任何 LVLM 无缝集成。我们在 6 个开源 LVLM 上评估了 LURE,与之前的最佳方法相比,一般物体幻觉评估指标提高了 23 倍。在 GPT 和人类评估中,LURE 始终名列前茅。 |
| Chinese Abs From Machine Translation |
Papers from arxiv.org
更多精彩请移步主页
pic from pexels.com