在《大语言模型之七- Llama-2单GPU微调SFT》和《大语言模型之十三 LLama2中文推理》中我们都提到了LoRA(低秩分解)方法,之所以用低秩分解进行参数的优化的原因是为了减少计算资源。
我们以《大语言模型之四-LlaMA-2从模型到应用》一文中的图3 LLama-2 图例过程为例说明内存的消耗。首先是有32层的Transformer,它们每层的内存占用如下图:

图中有六个大矩阵是打了勾的,原始的LLama2中矩阵的维度是4096*4096,单精度是float(4字节),那么一个矩阵的消耗将是64MB,七个矩阵大约是448MB,共计三十二层,那么总计消耗的内存将约16GB,在训练的时候还要计算梯度和学习率,需要的内存量将是翻倍的大小。例如参数量为1750亿Bloom的,其推理需要约350GB内存。
所以有没有什么办法能够减少内存和算力的需求进行微调呢?降低精度(混合精度、单精度)和量化是一些方法,最新的研究通过微调部分参数来达到精调模型。传统的迁移学习会冻结模型所有权重参数,然后添加额外的迁移学习层来实现迁移学习的任务,这种方法的缺点是
由此针对大语言模型的PEFT的方法被提出来,这里主要是介绍LoRA方法,因为在《大语言模型之十三 LLama2中文推理》合并模型使用的就是这种方法。
LoRA是微软开源的方法,原始paper,其核心思想是减少冗余信息,
矩阵的秩度量的就是矩阵的行列之间的相关性。为了求矩阵A的秩,我们是通过矩阵初等变换把A化为阶梯型矩阵,若该阶梯型矩阵有r个非零行,那A的秩rank(A)就等于r。 如果矩阵的各行或列是线性无关的,矩阵就是满秩的,也就是秩等于行数。
如果X是一个m行n列的数值矩阵,rank(X)是X的秩,假如rank (X)远小于m和n,则我们称X是低秩矩阵(上一篇博客的LoRA采用的方法中,原矩阵是40964096,将其分为409664和64*4096的两个矩阵,这两个矩阵的秩远小于原矩阵 )。低秩矩阵每行或每列都可以用其他的行或列线性表出,可见它包含大量的冗余信息。利用这种冗余信息,可以对缺失数据进行恢复,也可以对数据进行特征提取。
LoRA
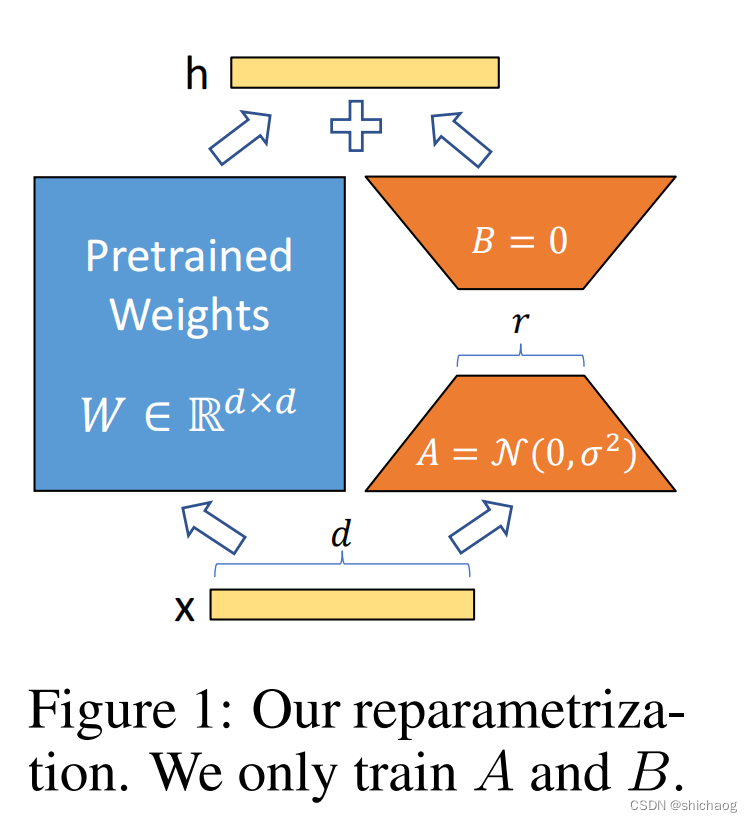
微软的LoRA方法的核心思想如下图所示,预训练的权重用 W W W表示,而需要新训练的矩阵用 A A A和 B B B表示,各层的输出最终变为:
h = W 0 x + Δ W x = W 0 x + B A x h=W_0x+\Delta Wx=W_0 x+BAx h=W0x+ΔWx=W0x+BAx
在《大语言模型之十三 LLama2中文推理》基座模型和LoRA 微调模型merge的操作就是实现上述公式的功能。
在大语言模型之十三 LLama2中文推理》中各层Attention的 W q , W k , W v W_q, W_k,W_v Wq,Wk,Wv的维度是 4096 ∗ 4096 4096*4096 4096∗4096,而A和B的权重参数量分别是 4096 ∗ 64 4096*64 4096∗64和 64 ∗ 4096 64*4096 64∗4096,即采用了秩为64(为什么选择这个秩?)的子矩阵训练。
代码对应的二者实现如下:
def regular_forward_matmul(x,W):h = x @ W
return hdef lora_forward_matmul(x, W, W_A, W_B):h = x @ W # regular matrix multiplicationh += x @ *(W_A @ W_B) * alpha # use scaled LoRA weights
return h
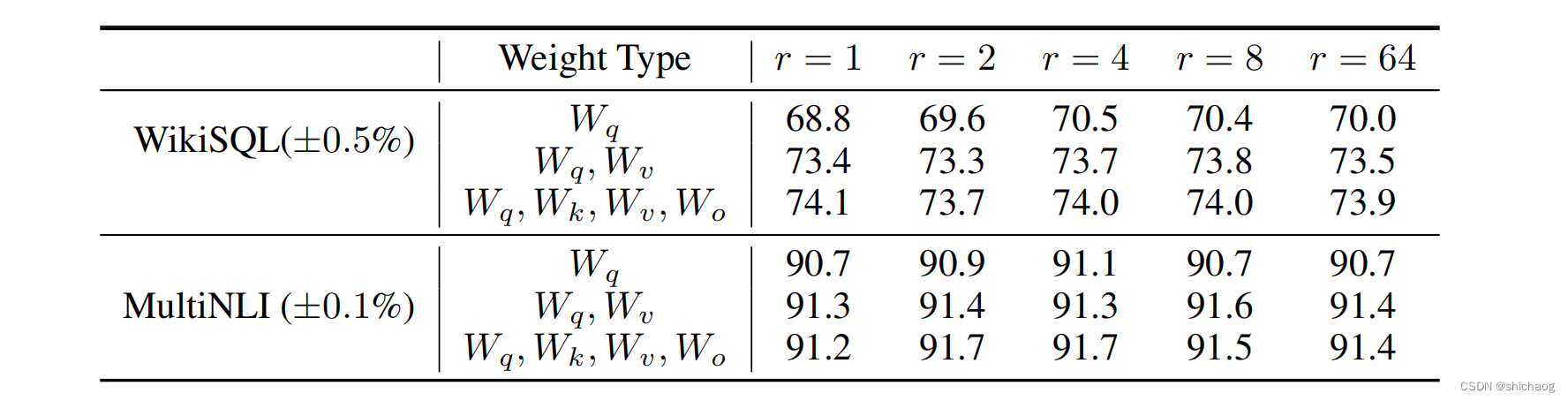
B A BA BA矩阵使用了秩和alpha两个超参数进行了缩放,其目的是控制 B A BA BA矩阵对原始的权重 W 0 W_0 W0的影响,LoRA论文做了很多实验尝试不同的秩r,如下图所示,这表明可以采用秩很小的矩阵,而且q/k/v也并不需要都进行重训练,尽管上一篇博客对所有参数都进行了重新训练(这也意味着单GPU重训练内存是不够的)。
在《大语言模型之七- Llama-2单GPU微调SFT》中使用参数如下,其只对q和v权重进行了跟新,而k是freeze的,另外秩等于8,参数量从4096*4096变为了8*4096*2,这也极大减少了参数量。
from peft import LoraConfig, get_peft_model# LoRA attention dimension 64, 8
lora_r = 8# Alpha parameter for LoRA scaling 16,32
lora_alpha = 32# Dropout probability for LoRA layers 0.1 0.05
lora_dropout = 0.1peft_config = LoraConfig(r=lora_r,lora_alpha=lora_alpha,target_modules=["q_proj","v_proj"],lora_dropout=lora_dropout,bias="none",task_type="CAUSAL_LM"
)LoraConfig
LoraConfig用于设置微调语言模型的LoRA adapter,通过重新参数化一层矩阵参数的权重,以提高计算性能。
LoraConfig对象的参数如下:
- lora_alpha 这是LoRA更新矩阵的标定因子,lora_alpha值越高,权重更新越积极,lora_alpha的其他值可以是8、32或64。
- lora_dropout 这是LoRA层的dropout率。Dropout技术和常规训练中是一个技术,用于防止过拟合。 常选择的值为0.0, 0.2, or 0.5。Dropout越大越有助于防止过拟合,越小越有助于学习更复杂的模式。
- r:跟新矩阵的秩,存储关于层矩阵权重的更多信息。常取 32, 128, or 256.
- Bias:指示bias是否参与微调训练,常取“trainable” or “fixed”,bias有时对模型性能表现比较重要。
- task_type:LoRA adapter采用的类型,“NLI”(natural language inference) or “MT”(machine translation).其影响LoRA adapter对预训练模型采取的方法。
- target_modules:指示应用于LoRA更新矩阵的模块,[“attention”, “dense_final”] or [“query_key_value”, “dense”, “dense_h_to_4h”].
参数的最佳值取决于特定的语言模型和下游任务,可以通过试验不同的参数取值,以获得最优的性能。
看懂这篇博客以及《大语言模型之七- Llama-2单GPU微调SFT》那么就可以在《大语言模型之十三 LLama2中文推理》所述合并的模型基础上进行微调训练。




![练[BJDCTF2020]EasySearch](https://img-blog.csdnimg.cn/img_convert/fd76e2bd0f3b7135b9b21a79bd79cd22.png)