Aurora中的策略模式和模板模式
在aurora中为了方便以后的扩展使用了策略模式和模板模式实现图片上传和搜索功能,能够在配置类中设置使用Oss或者minio上传图片,es或者mysql文章搜索。后续有新的上传方式或者搜索方式只需要编写对应的实现类即可,其它代码无需更改,做到解耦的效果。
什么是策略模式
策略模式(Strategy Pattern)属于对象的行为模式。其用意是针对一组算法,将每一个算法封装到具有共同接口的独立的类中,从而使得它们可以相互替换。策略模式使得算法可以在不影响到客户端的情况下发生变化。其主要目的是通过定义相似的算法,替换if else 语句写法,并且可以随时相互替换。
策略模式主要由这三个角色组成,环境角色(Context)、抽象策略角色(Strategy)和具体策略角色(ConcreteStrategy)。
- 环境角色(Context):持有一个策略类的引用,提供给客户端使用。
- 抽象策略角色(Strategy):这是一个抽象角色,通常由一个接口或抽象类实现。此角色给出所有的具体策略类所需的接口。
- 具体策略角色(ConcreteStrategy):包装了相关的算法或行为。

什么是模板模式
模板模式(Template Pattern)中,一个抽象类公开定义了执行它的方法的方式/模板。它的子类可以按需要重写方法实现,但调用将以抽象类中定义的方式进行。 这种类型的设计模式属于行为型模式。定义一个操作中的算法的骨架,而将一些步骤延迟到子类中。
模板模式主要由抽象模板(Abstract Template)角色和具体模板(Concrete Template)角色组成。
- 抽象模板(Abstract Template): 定义了一个或多个抽象操作,以便让子类实现。这些抽象操作叫做基本操作,它们是一个顶级逻辑的组成步骤;定义并实现了一个模板方法。这个模板方法一般是一个具体方法,它给出了一个顶级逻辑的骨架,而逻辑的组成步骤在相应的抽象操作中,推迟到子类实现。顶级逻辑也有可能调用一些具体方法。
- 具体模板(Concrete Template): 实现父类所定义的一个或多个抽象方法,它们是一个顶级逻辑的组成步骤;每一个抽象模板角色都可以有任意多个具体模板角色与之对应,而每一个具体模板角色都可以给出这些抽象方法(也就是顶级逻辑的组成步骤)的不同实现,从而使得顶级逻辑的实现各不相同。
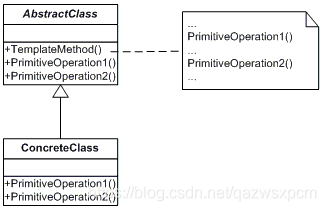
这篇文章把这两个模式讲的很好 https://www.cnblogs.com/xuwujing/p/9954263.html
图片上传
策略模式的应用
图片上传中有两种上传策略Oss和Minio。在上传图片的时候,如果用户配置了Oss那么就选择Oss上传,否则就选择Minio上传。虽然可以用if else判断,但是每次增加新的上传方式就需要在原方法中更改,这样处理会导致难以维护。通过分析我们可以发现Oss和Minio的实现功能都是上传图片,所以我们可以用策略模式把这两个功能的上传功能抽象成一个策略类接口,再分别实现Oss和Minio的上传策略,然后定义环境角色根据配置选择具体的策略上传图片。
模板模式的应用
进一步分析两种上传策略的步骤都是
- 根据文件流和配置生成图片在对象存储中的路径
- 判断图片是否存在
- 不存在则上传图片
- 返回图片路径
所以可以定义一个抽象的模板类执行这些步骤,让不同的上传策略实现自己的上传方法和生成路径方法
Tips
- 图片上传时,前台传递的参数是一个MultipartFile类型的,调用getInputStream()可以得到图片的输入流,进一步上传给云存储
- 环境对象将所有的策略实现类保存在map中,根据yml中配置的上传方式选择对应的策略上传
@Value("${upload.mode}")private String uploadMode;@Autowired// 每个策略类 都会以 @Service("ossUploadStrategyImpl") 的方式命名,然后被自动注入到map中private Map<String, UploadStrategy> uploadStrategyMap;public String executeUploadStrategy(MultipartFile file, String path) {return uploadStrategyMap.get(getStrategy(uploadMode)).uploadFile(file, path);}
文章搜索
文章搜素中有两种搜索模式 Es 和 Mysql。同样用策略模式将这两中模式的搜索功能抽象成一个接口,分别实现搜索策略,然后定义环境角色根据配置选择具体的策略搜索文章。
需要的搜索功能是:根据输入的单词,在文章的标题和内容中找到相应的位置并高亮显示。
Es搜索逻辑
首先构造搜索条件:
// 查询条件NativeSearchQueryBuilder nativeSearchQueryBuilder = new NativeSearchQueryBuilder();BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();boolQueryBuilder.must(QueryBuilders.boolQuery().should(QueryBuilders.matchQuery("articleTitle", keywords)).should(QueryBuilders.matchQuery("articleContent", keywords))).must(QueryBuilders.termQuery("isDelete", FALSE)).must(QueryBuilders.termQuery("status", PUBLIC.getStatus()));nativeSearchQueryBuilder.withQuery(boolQueryBuilder);// 高亮显示条件 在关键词前后加上PRE_TAG POST_TAGHighlightBuilder.Field titleField = new HighlightBuilder.Field("articleTitle");titleField.preTags(PRE_TAG);titleField.postTags(POST_TAG);HighlightBuilder.Field contentField = new HighlightBuilder.Field("articleContent");contentField.preTags(PRE_TAG);contentField.postTags(POST_TAG);contentField.fragmentSize(50);nativeSearchQueryBuilder.withHighlightFields(titleField, contentField);
使用elasticsearchRestTemplate根据搜索条件查询
SearchHits<ArticleSearchDTO> search = elasticsearchRestTemplate.search(nativeSearchQueryBuilder.build(), ArticleSearchDTO.class);
将结果转为List返回
return search.getSearchHits().stream().map(hit -> {ArticleSearchDTO article = hit.getContent();List<String> titleHighLightList = hit.getHighlightFields().get("articleTitle");if (CollectionUtils.isNotEmpty(titleHighLightList)) {article.setArticleTitle(titleHighLightList.get(0));}List<String> contentHighLightList = hit.getHighlightFields().get("articleContent");if (CollectionUtils.isNotEmpty(contentHighLightList)) {article.setArticleContent(contentHighLightList.get(contentHighLightList.size() - 1));}return article;}).collect(Collectors.toList());
Mysql搜索逻辑
构造搜索条件 && 搜索
List<Article> articles = articleMapper.selectList(new LambdaQueryWrapper<Article>().eq(Article::getIsDelete, FALSE).eq(Article::getStatus, PUBLIC.getStatus()).and(i -> i.like(Article::getArticleTitle, keywords).or().like(Article::getArticleContent, keywords)));
对搜索结果高亮处理截取后返回
return articles.stream().map(item -> {boolean isLowerCase = true;String articleContent = item.getArticleContent();int contentIndex = item.getArticleContent().indexOf(keywords.toLowerCase());if (contentIndex == -1) {contentIndex = item.getArticleContent().indexOf(keywords.toUpperCase());if (contentIndex != -1) {isLowerCase = false;}}if (contentIndex != -1) {int preIndex = contentIndex > 15 ? contentIndex - 15 : 0;String preText = item.getArticleContent().substring(preIndex, contentIndex);int last = contentIndex + keywords.length();int postLength = item.getArticleContent().length() - last;int postIndex = postLength > 35 ? last + 35 : last + postLength;String postText = item.getArticleContent().substring(contentIndex, postIndex);if (isLowerCase) {articleContent = (preText + postText).replaceAll(keywords.toLowerCase(), PRE_TAG + keywords.toLowerCase() + POST_TAG);} else {articleContent = (preText + postText).replaceAll(keywords.toUpperCase(), PRE_TAG + keywords.toUpperCase() + POST_TAG);}} else {return null;}isLowerCase = true;int titleIndex = item.getArticleTitle().indexOf(keywords.toLowerCase());if (titleIndex == -1) {titleIndex = item.getArticleTitle().indexOf(keywords.toUpperCase());if (titleIndex != -1) {isLowerCase = false;}}String articleTitle;if (isLowerCase) {articleTitle = item.getArticleTitle().replaceAll(keywords.toLowerCase(), PRE_TAG + keywords.toLowerCase() + POST_TAG);} else {articleTitle = item.getArticleTitle().replaceAll(keywords.toUpperCase(), PRE_TAG + keywords.toUpperCase() + POST_TAG);}return ArticleSearchDTO.builder().id(item.getId()).articleTitle(articleTitle).articleContent(articleContent).build();}).filter(Objects::nonNull).collect(Collectors.toList());
Tips
Es搜索为什么会比Mysql快呢?
- 基于分词后的全文检索,对于模糊搜索Mysql的索引会失效,而es会使用单词字典树结合倒排索引能够快速找到文章位置
- 进行精确检索,有些时候可能mysql要快一些,当mysql的非聚合索引引用上了聚合索引,无需回表,则速度上可能更快;es还是通过FST找到倒排索引的位置比获取文档id列表,再根据文档id获取文档并根据相关度进行排序。但是es还有个优势,就是es即天然的分布式能够在大量数据搜索时可以通过分片降低检索规模,并且可以通过并行检索提升效率,用filter时,更是可以直接跳过检索直接走缓存。