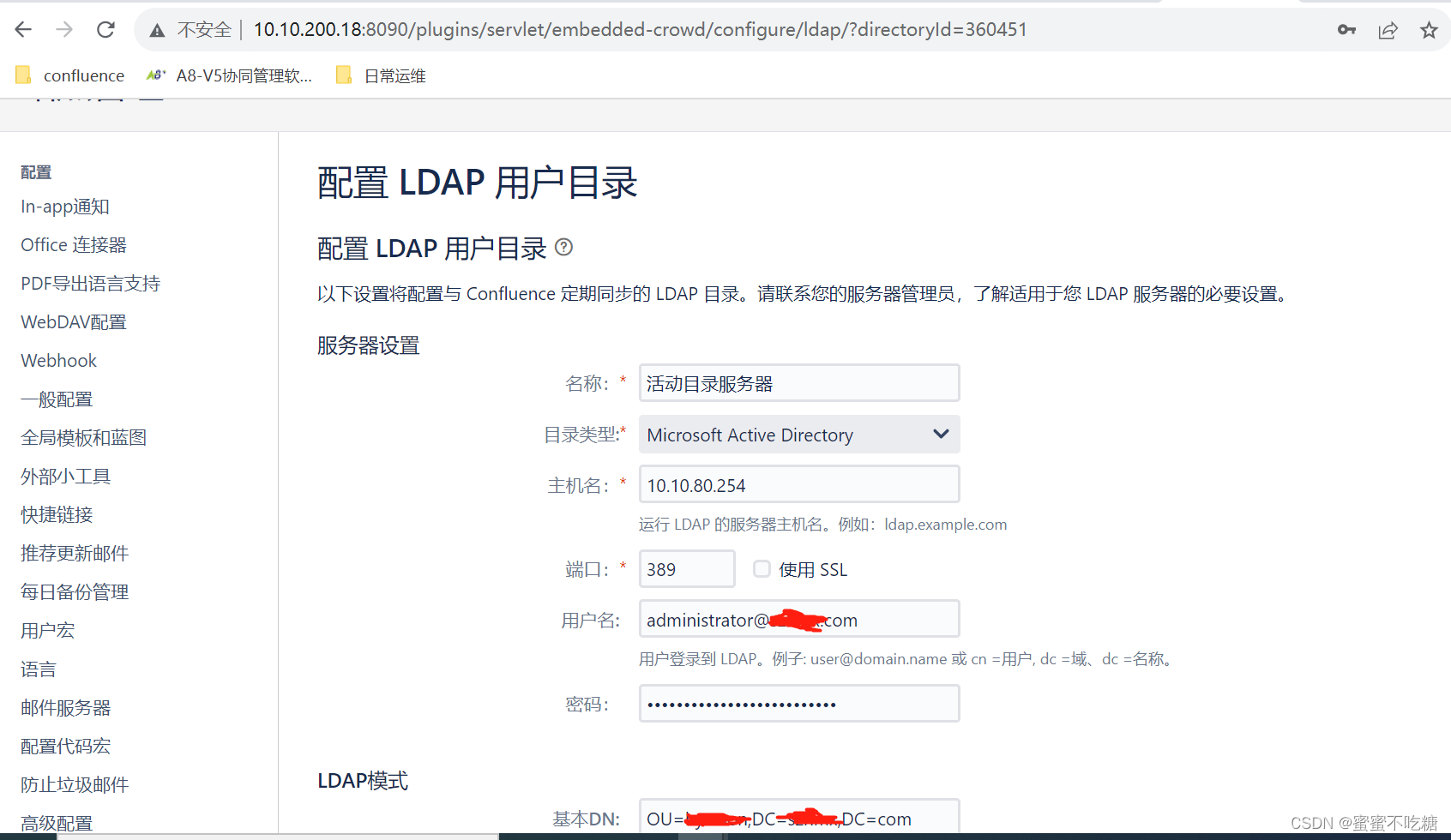
1. 数据预处理和数据集分割
import pandas as pd
from sklearn.model_selection import train_test_split
- 导入所需的Python库
!git clone https://github.com/JeffereyWu/Housing-prices-data.git
- 下载数据集
# Read the data
X = pd.read_csv('/content/Housing-prices-data/train.csv', index_col='Id')
X_test = pd.read_csv('/content/Housing-prices-data/test.csv', index_col='Id')
- 使用Pandas的
read_csv函数从CSV文件中读取数据,分别读取了训练数据(train.csv)和测试数据(test.csv),并将数据的索引列设置为’Id’。
# Remove rows with missing target, separate target from predictors
X.dropna(axis=0, subset=['SalePrice'], inplace=True)
y = X.SalePrice
X.drop(['SalePrice'], axis=1, inplace=True)
- 删除了训练数据中带有缺失目标值(‘SalePrice’)的行。
- 然后,将目标值(房屋销售价格)存储在变量y中,并从特征中删除了目标列,以便在后续的训练中使用特征数据。
# To keep things simple, we'll drop columns with missing values
cols_with_missing = [col for col in X.columns if X[col].isnull().any()]
X.drop(cols_with_missing, axis=1, inplace=True)
X_test.drop(cols_with_missing, axis=1, inplace=True)
- 删除数据中带有缺失值的列。
- 通过遍历每一列,使用
X[col].isnull().any()来检查每列是否包含任何缺失值,如果某列中至少有一个缺失值,就将其列名添加到cols_with_missing列表中。 - 使用
drop方法将这些带有缺失值的列从训练数据X和测试数据X_test中删除。
# Break off validation set from training data
X_train, X_valid, y_train, y_valid = train_test_split(X, y,train_size=0.8, test_size=0.2,random_state=0)
- 使用
train_test_split函数将训练数据X和目标值y分成训练集(X_train和y_train)和验证集(X_valid和y_valid)。 train_size参数指定了训练集的比例(80%),test_size参数指定了验证集的比例(20%),random_state参数用于控制随机分割的种子,以确保每次运行代码时分割结果都一样。
2. 评估不同方法在机器学习模型上的性能
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_absolute_error# function for comparing different approaches
def score_dataset(X_train, X_valid, y_train, y_valid):model = RandomForestRegressor(n_estimators=100, random_state=0)model.fit(X_train, y_train)preds = model.predict(X_valid)return mean_absolute_error(y_valid, preds)
3. 从训练数据和验证数据中选择只包含数值类型特征(列)的子集
drop_X_train = X_train.select_dtypes(exclude=['object'])
drop_X_valid = X_valid.select_dtypes(exclude=['object'])
- 使用Pandas中的
select_dtypes方法,它允许你根据数据类型来筛选数据框中的列。 exclude=['object']参数指定了要排除的数据类型是’object’类型,通常’object’类型表示非数值型数据,例如字符串或类别数据。
print("MAE from Approach 1 (Drop categorical variables):")
print(score_dataset(drop_X_train, drop_X_valid, y_train, y_valid))
MAE from Approach 1 (Drop categorical variables):
17837.82570776256
4. 查看训练数据和验证数据中特定列('Condition2’列)的唯一值
print("Unique values in 'Condition2' column in training data:", X_train['Condition2'].unique())
print("\nUnique values in 'Condition2' column in validation data:", X_valid['Condition2'].unique())
X_train['Condition2'].unique()的部分用于获取训练数据中’Condition2’列中的所有不重复的数值。这可以帮助你了解这一列包含哪些不同的数值或类别。- 输出验证数据中’Condition2’列的唯一值,同样使用了
X_valid['Condition2'].unique()。 - 这可以帮助你了解验证数据中这一列的不同数值或类别,通常用于检查验证数据是否与训练数据具有相似的分布,以确保模型在新数据上的泛化性能。
Unique values in ‘Condition2’ column in training data: [‘Norm’ ‘PosA’ ‘Feedr’ ‘PosN’ ‘Artery’ ‘RRAe’]
Unique values in ‘Condition2’ column in validation data: [‘Norm’ ‘RRAn’ ‘RRNn’ ‘Artery’ ‘Feedr’ ‘PosN’]
如果你现在编写代码来执行以下操作:
- 在训练数据上训练一个有序编码器(ordinal encoder)。
- 使用该编码器来转换训练数据和验证数据。
那么你将会遇到一个错误。
- 如果验证数据包含训练数据中没有出现的值,编码器将会报错,因为这些值没有与之对应的整数标签。
- 验证数据中的’Condition2’列包含了值’RRAn’和’RRNn’,但这些值在训练数据中并没有出现。因此,如果我们尝试使用Scikit-learn中的有序编码器,代码将会抛出错误。
5. 找出哪些列可以进行有序编码(ordinal encoding),哪些列需要从数据集中删除
# Categorical columns in the training data
object_cols = [col for col in X_train.columns if X_train[col].dtype == "object"]# Columns that can be safely ordinal encoded
good_label_cols = [col for col in object_cols if set(X_valid[col]).issubset(set(X_train[col]))]# Problematic columns that will be dropped from the dataset
bad_label_cols = list(set(object_cols)-set(good_label_cols))print('Categorical columns that will be ordinal encoded:', good_label_cols)
print('\nCategorical columns that will be dropped from the dataset:', bad_label_cols)
- 创建了一个名为
object_cols的列表,用于存储训练数据X_train中的所有数据类型为"object"(通常表示字符串或类别型数据)的列。 - 创建了一个名为
good_label_cols的列表,用于存储可以安全进行有序编码的列。这些列的特点是验证数据中的所有唯一值都存在于训练数据的相应列中。通过使用set来比较验证数据和训练数据中的唯一值,可以确定哪些列可以进行有序编码,因为它们的唯一值是一致的。 - 创建了一个名为
bad_label_cols的列表,用于存储需要从数据集中删除的问题列。这些列包含了一些在验证数据中出现但在训练数据中没有出现的唯一值,因此无法进行有序编码,需要在数据预处理中删除。
Categorical columns that will be ordinal encoded: [‘MSZoning’, ‘Street’, ‘LotShape’, ‘LandContour’, ‘Utilities’, ‘LotConfig’, ‘LandSlope’, ‘Neighborhood’, ‘Condition1’, ‘BldgType’, ‘HouseStyle’, ‘RoofStyle’, ‘Exterior1st’, ‘Exterior2nd’, ‘ExterQual’, ‘ExterCond’, ‘Foundation’, ‘Heating’, ‘HeatingQC’, ‘CentralAir’, ‘KitchenQual’, ‘PavedDrive’, ‘SaleType’, ‘SaleCondition’]
Categorical columns that will be dropped from the dataset: [‘Functional’, ‘Condition2’, ‘RoofMatl’]
6. 对数据进行有序编码
from sklearn.preprocessing import OrdinalEncoder# Drop categorical columns that will not be encoded
label_X_train = X_train.drop(bad_label_cols, axis=1)
label_X_valid = X_valid.drop(bad_label_cols, axis=1)# Apply ordinal encoder
ordinal_encoder = OrdinalEncoder()
label_X_train[good_label_cols] = ordinal_encoder.fit_transform(X_train[good_label_cols])
label_X_valid[good_label_cols] = ordinal_encoder.transform(X_valid[good_label_cols])
- 删除不需要进行编码的分类列,
bad_label_cols列表中包含了需要删除的列的名称。 - 使用
fit_transform方法将编码器拟合到训练数据的good_label_cols列上,并将结果存储在label_X_train中。 - 使用
transform方法将同样的编码器应用到验证数据的good_label_cols列上,并将结果存储在label_X_valid中。
print("MAE from Approach 2 (Ordinal Encoding):")
print(score_dataset(label_X_train, label_X_valid, y_train, y_valid))
MAE from Approach 2 (Ordinal Encoding):
17098.01649543379
7. 统计每个分类(categorical)数据列中唯一条目的数量
# Get number of unique entries in each column with categorical data
object_nunique = list(map(lambda col: X_train[col].nunique(), object_cols))
d = dict(zip(object_cols, object_nunique))# Print number of unique entries by column, in ascending order
sorted(d.items(), key=lambda x: x[1])
- 创建了一个名为
object_nunique的列表,用于存储每个分类数据列中唯一条目的数量。 - 它使用
map函数遍历object_cols中的每一列,并对每一列使用X_train[col].nunique()来计算该列的唯一条目数量。 nunique()函数返回该列中不同数值的数量,因此可以用来统计分类数据中的不同类别数量。- 创建了一个字典d,将分类数据列的名称作为键,唯一条目数量作为值。这里使用
zip函数将列名和唯一条目数量一一对应,然后将其转换为字典。 - 使用
sorted函数将字典中的项按照唯一条目数量升序排列,并以列表的形式返回结果。
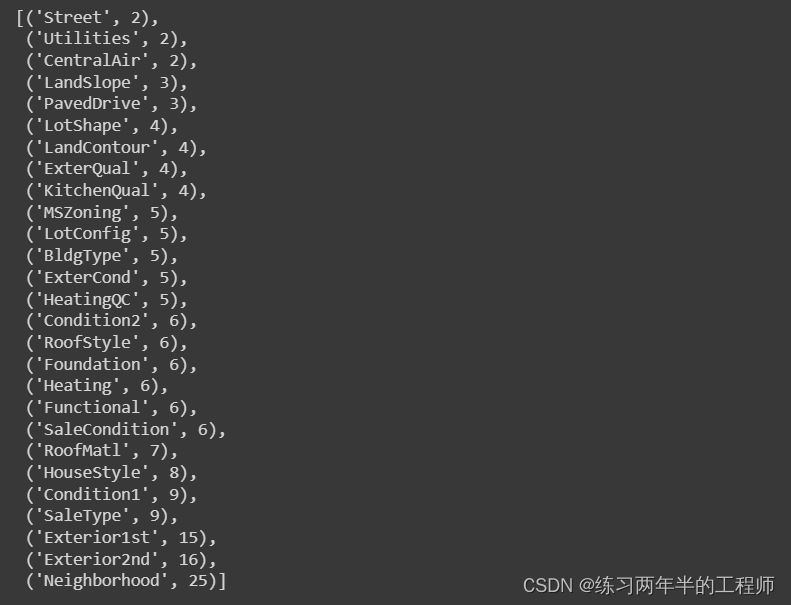
8. 与其对数据集中的所有分类变量进行编码,只为基数(唯一值数量)小于10的列创建独热编码(One-Hot Encoding)
# Columns that will be one-hot encoded
low_cardinality_cols = [col for col in object_cols if X_train[col].nunique() < 10]# Columns that will be dropped from the dataset
high_cardinality_cols = list(set(object_cols)-set(low_cardinality_cols))print('Categorical columns that will be one-hot encoded:', low_cardinality_cols)
print('\nCategorical columns that will be dropped from the dataset:', high_cardinality_cols)
- 遍历
object_cols中的每一列,并使用X_train[col].nunique()来获取每列的唯一值数量,如果唯一值数量小于10,则将该列添加到low_cardinality_cols中。 - 使用集合操作
set(object_cols) - set(low_cardinality_cols)来找出不在low_cardinality_cols中的分类列,然后将这些列的名称存储在high_cardinality_cols中。
Categorical columns that will be one-hot encoded: [‘MSZoning’, ‘Street’, ‘LotShape’, ‘LandContour’, ‘Utilities’, ‘LotConfig’, ‘LandSlope’, ‘Condition1’, ‘Condition2’, ‘BldgType’, ‘HouseStyle’, ‘RoofStyle’, ‘RoofMatl’, ‘ExterQual’, ‘ExterCond’, ‘Foundation’, ‘Heating’, ‘HeatingQC’, ‘CentralAir’, ‘KitchenQual’, ‘Functional’, ‘PavedDrive’, ‘SaleType’, ‘SaleCondition’]
Categorical columns that will be dropped from the dataset: [‘Exterior1st’, ‘Neighborhood’, ‘Exterior2nd’]
9. 执行独热编码(One-Hot Encoding),将低基数(唯一值数量小于10)的分类(categorical)列转换为二进制形式,并将它们与数值特征合并在一起
from sklearn.preprocessing import OneHotEncoderOH_encoder = OneHotEncoder(handle_unknown='ignore', sparse=False)
OH_X_train = pd.DataFrame(OH_encoder.fit_transform(X_train[low_cardinality_cols]))
OH_X_valid = pd.DataFrame(OH_encoder.transform(X_valid[low_cardinality_cols]))# One-hot encoding removed index; put it back
OH_X_train.index = X_train.index
OH_X_valid.index = X_valid.index# Remove categorical columns (will replace with one-hot encoding)
num_X_train = X_train.drop(object_cols, axis=1)
num_X_valid = X_valid.drop(object_cols, axis=1)# Add one-hot encoded columns to numerical features
OH_X_train = pd.concat([num_X_train, OH_X_train], axis=1)
OH_X_valid = pd.concat([num_X_valid, OH_X_valid], axis=1)# Ensure all columns have string type
OH_X_train.columns = OH_X_train.columns.astype(str)
OH_X_valid.columns = OH_X_valid.columns.astype(str)
- 使用
fit_transform方法将独热编码应用到训练数据的low_cardinality_cols列上,并将结果存储在OH_X_train中。接着,使用transform方法将同样的编码器应用到验证数据的low_cardinality_cols列上,并将结果存储在OH_X_valid中。 - 将独热编码后的数据的索引设置为与原始训练数据和验证数据相同,以确保它们可以正确对齐。
- 删除了原始数据中的分类列,因为它们已经被独热编码取代。
- 将独热编码后的数据与原始的数值特征合并在一起,以创建一个包含所有特征的新数据集。
- 确保新数据集中的所有列都以字符串类型表示,以便与其他列一致。这是因为独热编码会生成以0和1表示的二进制列,需要将其列名转换为字符串类型。这样,数据就准备好用于训练机器学习模型了,其中包括数值特征和独热编码后的分类特征。
print("MAE from Approach 3 (One-Hot Encoding):")
print(score_dataset(OH_X_train, OH_X_valid, y_train, y_valid))
MAE from Approach 3 (One-Hot Encoding):
17525.345719178084

![[尚硅谷React笔记]——第3章 React应用(基于React脚手架)](https://img-blog.csdnimg.cn/7f79434fecc242a19c6c1705e32d31ef.png)