Spark
| 1.Spark概述 2.Spark特点 3.RDD概述 |
1. Spark概述
什么是Spark回顾:Hadoop主要解决,海量数据的存储和海量数据的分析计算。 Spark是一种基于内存的快速、通用、可扩展的大数据分析计算引擎。 |
Hadoop与Spark历史
|
Hadoop与Spark框架对比
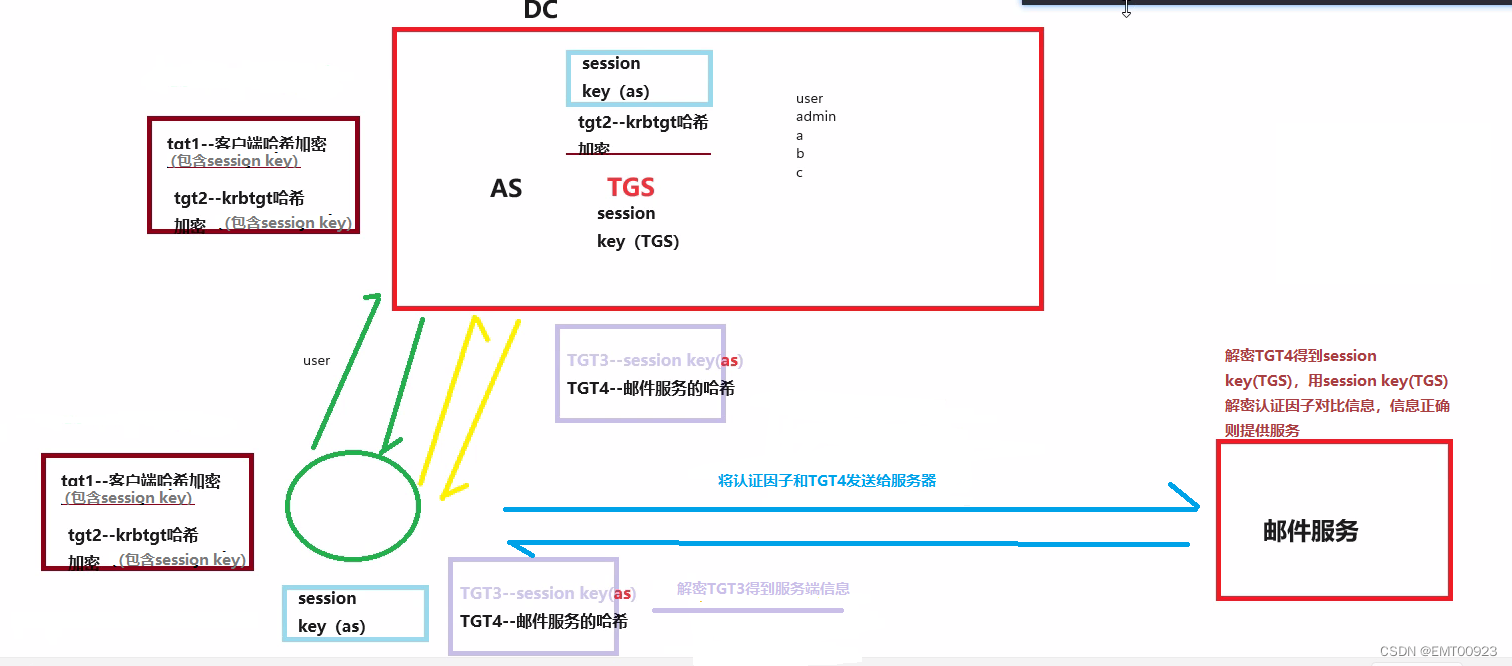
Driver Spark驱动器节点,用于执行Spark任务中的main方法,负责实际代码的执行工作。Driver在Spark作业执行时主要负责: 将用户程序转化为作业(job) 在Executor之间调度任务(task) 跟踪Executor的执行情况 通过UI展示查询运行情况 Executor Spark Executor是集群中工作节点(Worker)中的一个JVM进程,负责在Spark 作业中运行具体任务(Task),任务彼此之间相互独时启动,并且始终伴随着整个Spark 应用的生命周期而存在。如果有Executor节点发生了故障或崩溃,Spark 应用也可以继续执行,会将出错节点上的任务调度到其他Executor节点上继续运行。 Executor有两个核心功能: 负责运行组成Spark应用的任务,并将结果返回给驱动器进程 它们通过自身的块管理器(Block Manager)为用户程序中要求缓存的RDD 提供内存式存储。RDD 是直接缓存在Executor进程内的,因此任务可以在运行时充分利用缓存数据加速运算。 Master & Worker Spark集群的独立部署环境中,不需要依赖其他的资源调度框架,自身就实现了资源调度的功能,所以环境中还有其他两个核心组件:Master和Worker,这里的Master是一个进程,主要负责资源的调度和分配,并进行集群的监控等职责,类似于Yarn环境中的RM, 而Worker呢,也是进程,一个Worker运行在集群中的一台服务器上,由Master分配资源对数据进行并行的处理和计算,类似于Yarn环境中NM。 ApplicationMaster Hadoop用户向YARN集群提交应用程序时,提交程序中应该包含ApplicationMaster,用于向资源调度器申请执行任务的资源容器Container,运行用户自己的程序任务job,监控整个任务的执行,跟踪整个任务的状态,处理任务失败等异常情况。 说的简单点就是,ResourceManager(资源)和Driver(计算)之间的解耦合靠的就是ApplicationMaster。 |
Spark内置模块
Spark Core:实现了Spark的基本功能,包含任务调度、内存管理、错误恢复、与存储系统交互等模块。Spark Core中还包含了对弹性分布式数据集(Resilient Distributed DataSet,简称RDD)的API定义。 Spark SQL:是Spark用来操作结构化数据的程序包。通过Spark SQL,我们可以使用 SQL或者Apache Hive版本的HQL来查询数据。Spark SQL支持多种数据源,比如Hive表、Parquet以及JSON等。 Spark Streaming:是Spark提供的对实时数据进行流式计算的组件。提供了用来操作数据流的API,并且与Spark Core中的 RDD API高度对应。 Spark MLlib:提供常见的机器学习功能的程序库。包括分类、回归、聚类、协同过滤等,还提供了模型评估、数据 导入等额外的支持功能。 Spark GraphX:主要用于图形并行计算和图挖掘系统的组件。 集群管理器:Spark设计为可以高效地在一个计算节点到数千个计算节点之间伸缩计算。为了实现这样的要求,同时获得最大灵活性,Spark支持在各种集群管理器(Cluster Manager)上运行,包括Hadoop YARN、Apache Mesos,以及Spark自带的一个简易调度器,叫作独立调度器。 Spark得到了众多大数据公司的支持,这些公司包括Hortonworks、IBM、Intel、Cloudera、MapR、Pivotal、百度、阿里、腾讯、京东、携程、优酷土豆。当前百度的Spark已应用于大搜索、直达号、百度大数据等业务;阿里利用GraphX构建了大规模的图计算和图挖掘系统,实现了很多生产系统的推荐算法;腾讯Spark集群达到8000台的规模,是当前已知的世界上最大的Spark集群。 |
Spark特点
|
| 1.5 Spark 运行环境 ① local 本地模式(单机) - 不需要其他任何节点资源就可以在本地执行Spark代码的环境 学习测试使用。 分为 local 单线程和 local-cluster 多线程。 ② standalone 独立集群模式 学习测试使用。 典型的 Mater/slave 模式。 ③ standalone-HA 高可用模式 生产环境使用 基于 standalone 模式,使用 zk 搭建高可用,避免 Master 是有单点故障的。 ④ on yarn 集群模式 生产环境使用 运行在 yarn 集群之上,由 yarn 负责资源管理,Spark 负责任务调度和计算。 好处:计算资源按需伸缩,集群利用率高,共享底层存储,避免数据跨集群迁移。 ⑤ on mesos 集群模式 国内使用较少 运行在 mesos 资源管理器框架之上,由 mesos 负责资源管理,Spark 负责任务调度和计算。 ⑥ on cloud 集群模式 中小公司未来会更多的使用云服务 比如 AWS 的 EC2,使用这个模式能很方便的访问 Amazon 的 S3。 |





2. Spark运行模式及安装部署
| 部署Spark集群大体上分为两种模式:单机模式与集群模式 大多数分布式框架都支持单机模式,方便开发者调试框架的运行环境。但是在生产环境中,并不会使用单机模式。因此,后续直接按照集群模式部署Spark集群。 下面详细列举了Spark目前支持的部署模式。 (1)Local模式:在本地部署单个Spark服务 (2)Standalone模式:Spark自带的任务调度模式。(国内常用) (3)YARN模式:Spark使用Hadoop的YARN组件进行资源与任务调度。(国内最常用) (4)Mesos模式:Spark使用Mesos平台进行资源与任务的调度。(国内很少用) |
Spark安装
(1)scala环境搭建 解压、改名 [root@kb129 install]# tar -xvf ./scala-2.12.10.tgz -C ../soft/ [root@kb129 soft]# mv ./scala-2.12.10/ scala212 配置环境变量 [root@kb129 soft]# vim /etc/profile #SCALA_HOME [root@kb129 soft]# source /etc/profile
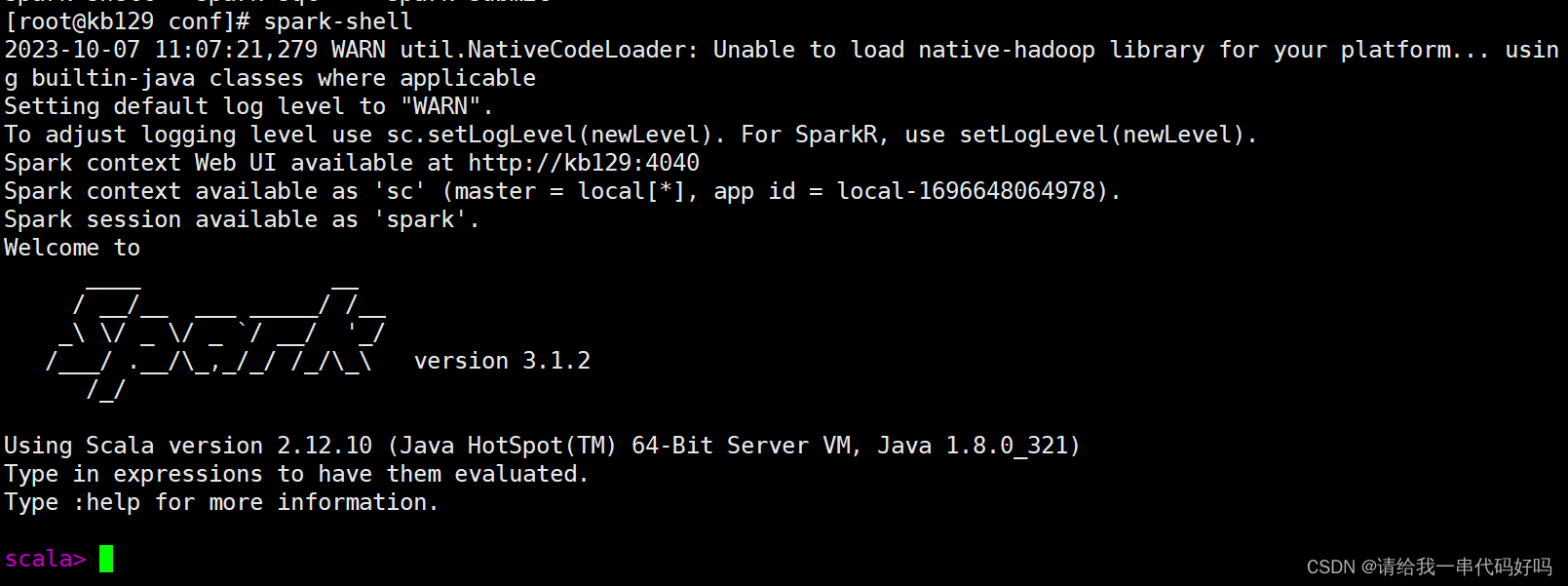
(2)spark安装部署 解压、改名 [root@kb129 install]# tar -xvf ./spark-3.1.2-bin-hadoop3.2.tgz -C ../soft/ [root@kb129 soft]# mv ./spark-3.1.2-bin-hadoop3.2/ spark312 拷贝配置文件,编辑 [root@kb129 conf]# cp spark-env.sh.template spark-env.sh [root@kb129 conf]# cp workers.template workers [root@kb129 conf]# vim /etc/profile #SPARK_HOME export SPARK_HOME=/opt/soft/spark312 export PATH=$SPARK_HOME/bin:$PATH [root@kb129 conf]# source /etc/profile [root@kb129 conf]# vim ./workers
[root@kb129 conf]# vim ./spark-env.sh 末尾追加 export SCALA_HOME=/opt/soft/scala212 export JAVA_HOME=/opt/soft/jdk180 export SPARK_HOME=/opt/soft/spark312 export HADOOP_HOME=/opt/soft/hadoop313 export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop export SPARK_MASTER_IP=192.168.142.129 export SPARK_DRIVER_MEMORY=2G export SPARK_EXECUTOR_MEMORY=2G export SPARK_LOCAL_DIRS=/opt/soft/spark312 [root@kb129 conf]# spark-shell
|
| data 类型为RDD(分布式数据集)
RDD算子
collect收集完装到数组中,数组函数如下
glom
|









3. RDD概述
什么是RDDRDD(Resilient Distributed Dataset)叫做分布式数据集,是Spark 中最基本的数据抽象,它代表一个不可变、可分区、里面的元素可并行计算的集合。在Spark 中,对数据的所有操作不外乎创建RDD、转化已有RDD 以及调用RDD 操作进行求值。每个RDD 都被分为多个分区,这些分区运行在集群中的不同节点上。RDD 可以包含Python、Java、Scala 中任意类型的对象, 甚至可以包含用户自定义的对象。RDD 具有数据流模型的特点:自动容错、位置感知性调度和可伸缩性。RDD 允许用户在执行多个查询时显式地将工作集缓存在内存中,后续的查询能够重用工作集,这极大地提升了查询速度。RDD 支持两种操作:transformation操作和action操作。RDD 的转化操作是返回一个新的RDD 的操作,比如map()和filter(),而action操作则是向驱动器程序返回结果或把结果写入外部系统的操作。比如count() 和first()。 Spark 采用惰性计算模式,RDD 只有第一次在一个行动操作中用到时,才会真正计算。Spark 可以优化整个计算过程。默认情况下,Spark 的RDD 会在你每次对它们进行行动操作时重新计算。如果想在多个行动操作中重用同一个RDD , 可以使用RDD.persist() 让Spark 把这个RDD 缓存下来。 RDD特性
|
| repartition和coalesce的区别 两个都能调整分区数,但repartition的底层依然是调用了coalesce coalesce的语法: coalesce(num,shuffle=False) 默认不启动shuffle repartition的语法: repartition(num) 默认启动shuffle repartition中将shuffle改成了ture,且参数不可修改 因此,repartition常用于增加分区,coalesce常用于减小分区 关键就在于shuffle是否启动 重新分区的根本是通过hash取模后再分区,因此必须通过shuffle 分区数据重新分区时会出现1个分区数据分配到其他多个分区的情况,也就形成了「宽依赖」 减小分区的根本是将1个分区完整归类到另一个分区中,属于1对1的情况,也就形成「窄依赖」 |
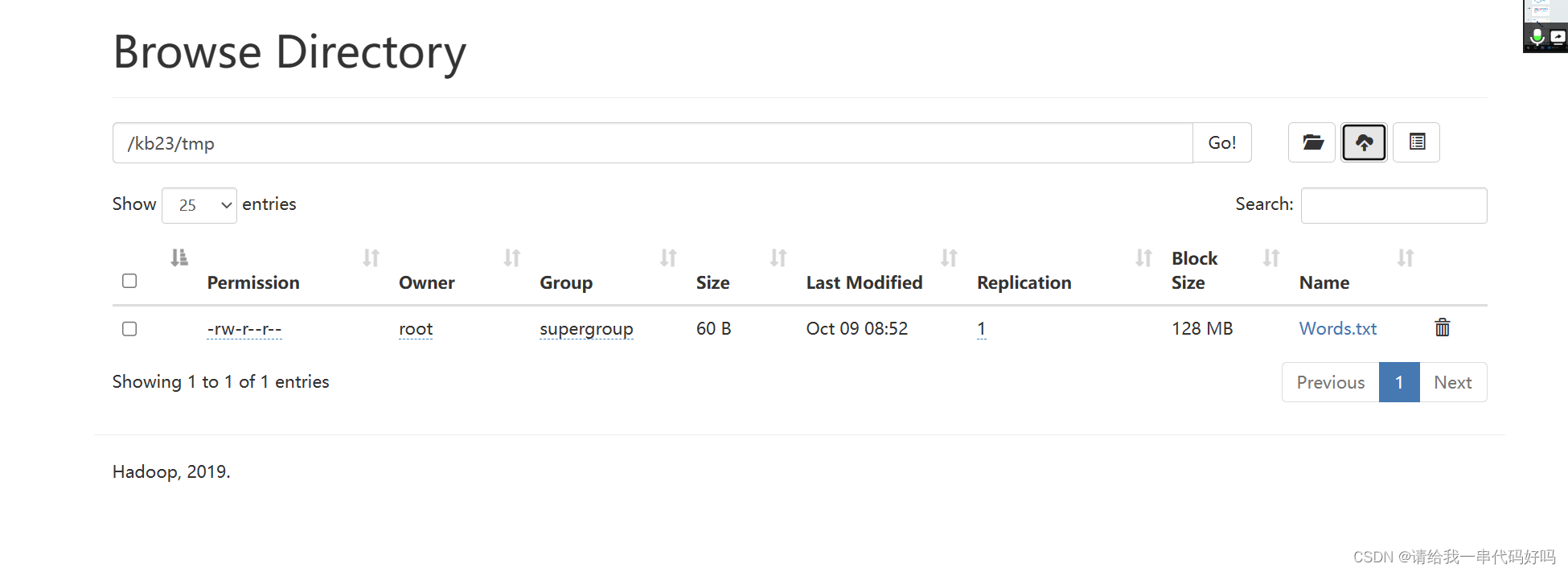
| 实现WordCount Hdfs 上传一个文本
Spark-shell sc.textFile("hdfs://kb129:9000/kb23/tmp/*txt").flatMap(x=>x.split(" ")).map(x=>(x,1)).reduceByKey(_+_).collect
|
| Java实现WordCount (Maven quickStart) 导入依赖
|
| 配置Log4j
新建resources修改文件名为log4j.properties 修改为ERROR
新建Scala object
运行打印结果
补充一个方法(简单版本)
|
| 新建一个 val a = 实现找到张姓同学的最高分
方法一:reduce 首先使用filter过滤,得到张姓同学,然后再进行reduce val rdd = a.filter(x => x._1.startsWith("zhang")).map(x => (x._1, x._2 + x._3 + x._4))
方法二:reduceByKey a.filter(x=>x._1.startsWith("zhang"))
方法三:sortBy a.filter(x=>x._1.startsWith("zhang")).map(x=>(x._1,x._2+x._3+x._4)).sortBy(x=> - x._2).take(1).foreach(println)
方法四:max println(a.filter(x => x._1.startsWith("zhang")).map(x => (x._2 + x._3 + x._4, x._1)).max)
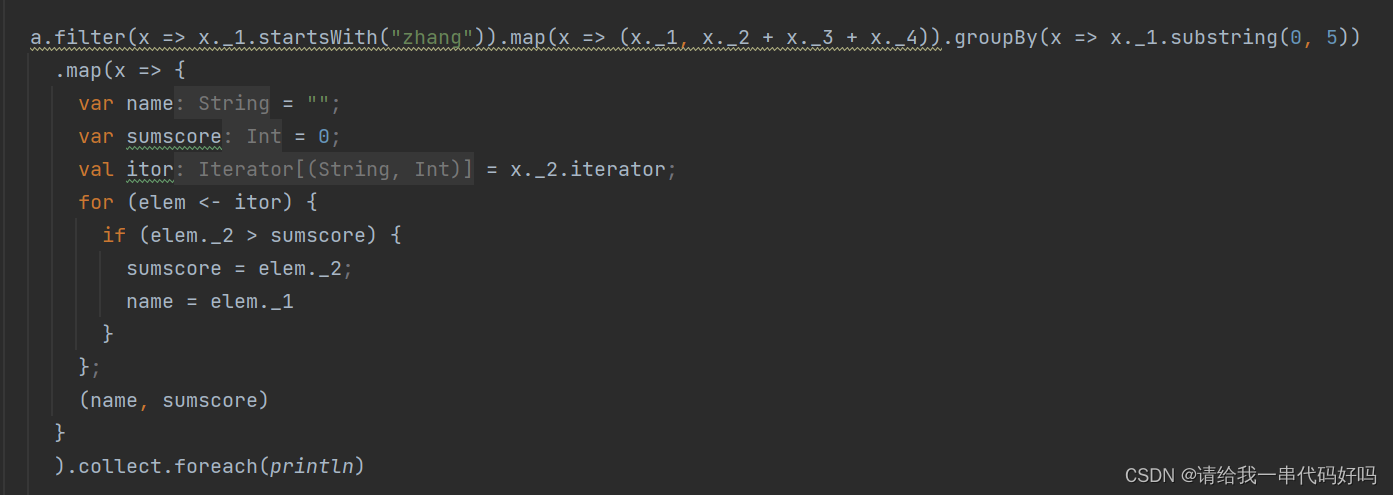
方法五: groupBy + 自定义函数 a.filter(x => x._1.startsWith("zhang")).map(x => (x._1, x._2 + x._3 + x._4)).groupBy(x => x._1.substring(0, 5))
五种方式对应结果
|