join order 的重要性
Join order 是指在执行SQL查询时,决定多个表进行 join 的顺序。它是数据库查询优化的一个重要方面,对查询性能和效率有着重要的影响, 不同的 join order 对性能可能有数量级的影响。
优化器优化 join order 的核心流程
- join plan 枚举
- 根据统计信息估算结果的大小 (cardinality estimation)
- 把 2 中的结果带入到代价模型计算枚举 plan 的 代价 (cost model)
本文中我们只关心第一步 join plan enumeration, 也就是 join reorder 算法。
join reorder 算法
贪心启发式算法
当需要 join 的表都数量过多时(通常超过10个),适合用贪心算法,其优势在于能够较快的找到还不错的 join order.
核心思想:从一张表拓展到 N 张表,每次选出使当前代价最小的一张表,加入到 join tree中,构建出 left-deep tree.
贪心算法也有很多拓展,主要拓展点是围绕如果 避免局部最优以及产生 bushy tree
枚举算法(top-down & bottom-up)
主流的两种
- 基于规则变换的 Top-down 枚举,可以结合 Top-down cascasde 框架通过记忆化的方式来实现
- 基于 DP 的 bottom-up 枚举, 典型代表 DPhyp 算法,其优势在于可以高效的产生 bushy tree
一般情况下,数据库系统会把贪心和枚举有效的结合,从而对任意数量的表 join 都能够在合理的时间内得到有效的 join order
Databend join reorder 现状
databend 优化器基于 Rule 进行优化,每条 Rule 通过 pattern 来匹配 plan 中的 sub-tree。主要分为两个阶段,启发式优化和基于 cascades 框架的代价优化,两个阶段共用一套 Rule。
在启发式阶段优化结束后,会对优化后的 plan 执行 DPhyp 算法来尝试得到最优的 join order, 如果 Dphyp 优化失败,会在 CBO 中找到最优的 left-deep tree. (CBO 中不尝试进行 bushy tree 优化,因为如果 Dphyp 已经优化失败,那么尝试在 CBO 中进行 bushy tree 优化,搜索空间很有可能爆炸,如 tpcds 64)
Databend 目前没有支持贪心算法 (下一阶段的 roadmap 会做相关支持来处理极端情况下的 case),首先会利用 dphyp 算法来得到最优解,如果 dphyp 失败(query 中存在不适合 dphyper 算法的 pattern),会在 cascades 框架中利用基于规则变换的 Top-down 枚举得到 left-deep tree. 如果表的数量过多,如超过十个,会在 dphyp 算法中放弃部分搜索空间来做 tradeoff。
Dphyp 的核心定义及算法
hypergraph
一个超图是一个由节点集合 V 和超边集合 E 组成的二元组 H = (V,E),其中:
- V是非空节点集合。
- E是超边集合,超边是V的非空子集(u ⊂ V)和(v ⊂ V)的无序对(u,v),并且满足额外条件 u∩v = ∅。
有了超图就可以描述多节点之间连接。
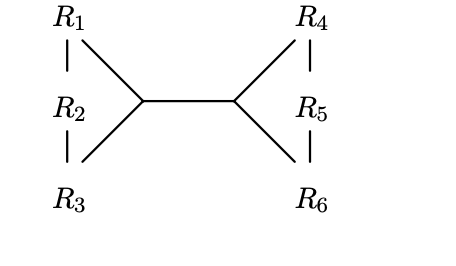
对于上图,它们的 join condition 是 R1.a + R2.b + R3.c = R4.d + R5.e + R6.f 所以 hyperedge 就是 {R1, R2, R3} — {R4, R5, R6}
csg-cmp-pair
csg: connected-subgraph (连通子图)
cmp: connected-complement (连通互补对)
如果两个 csg 之间没有交集,且存在超边连接,其中一个就是另一个的 cmp, 二者构成 csg-cmp-pair. 算法的核心就是通过递归无重复的枚举出所有的 csg-cmp-pair, 找出代价最小的包含所有点的 csg-cmp-pair.
algorithm
算法核心:hypergraph 中的节点是有序的,节点从后往前迭代(递减),每个节点只考虑其自身及其之后(序列号更大)的节点,找到可能的连通子图及其连通互补图,构成 csg-cmp-pair, 计算并更新出其代价,当迭代到最小的节点后,会得到包含所有点的 csg-cmp-pair, 算法结束。
算法流程
- EmitCsg: 寻找 {v} 的互补连通子图
- a. 如果找到, EmitCsgCmp
- b. EnumerateCmpRec:扩展互补连通子图
- 如果扩展后的互补连通子图可以与 {v} 形成 csg-cmp-pair, 则 EmitCsgCmp
- 回到 b,继续扩展
- EnumerateCsgRec: 扩展 {v}
- a. 得到扩展后的 {v’}, 对 {v’} 执行 1
- b. 回到2,继续扩展
核心代码和数据结构定义可参考:
(https://github.com/datafuselabs/databend/blob/main/src/query/sql/src/planner/optimizer/hyper_dp/dphyp.rs)
Connect With Us
Databend 是一款开源、弹性、低成本,基于对象存储也可以做实时分析的新式数仓。期待您的关注,一起探索云原生数仓解决方案,打造新一代开源 Data Cloud。
- Databend Website
- GitHub Discussions
- Slack Channel


![ROS仿真软件Turtlebot-Gazebo的安装使用以及错误处理[机器人避障]](https://img-blog.csdnimg.cn/3056eb60d18f439286f287936dcd6ae1.png)

![[安洵杯 2019]easy_web - RCE(关键字绕过)+md5强碰撞+逆向思维](https://img-blog.csdnimg.cn/d0ff84da22ea4f94aed095be3ef40e27.png)