Python爬虫 破解js渲染思路一
当我们在谈论网页js渲染的时候,我们在谈论什么
js渲染网页,从某种程度来说,是指单纯的http请求,返回的文本数据,与我们在浏览器看到的内容,相距甚远.其可包括为以下几点:
- HTML文本有数据,但是xpath提取不到,意指结构化的数据(一般为json)需要js执行,才会生成网页显示的正确的结构位置,这种是最简单的,我们可以通过正则或是一些文本处理手段得到数据.
- HTML文本有数据,但是数据与网页有差异,举个栗子:假如我们要爬取一个购物网站,这个网站你想要的是SGD的价格,但你发现文本中却是USD的价格,通过抓包你发现网站并没有传输SGD的价格,这个时候你通过打断点发现价格需要经过文本传输的USD以及汇率,通过专门的汇率的js转换为正确的SGD价格.
- HTML文本没有数据,通过抓包你发现,数据是通过请求额外的API得到的,这里会存在几种情况:
- API可以无限制请求
- API需要通过请求HTML,在HTML中有token数据,在请求API时你需要在请求头中加这个token数据才能正常请求API.
- API需要通过请求HTML,通过HTML返回的response中的cookie中某些数据,在请求API的时候,请求头需要在cookie中添加这些数据,才能正确拿到数据。
- 2和3两种情况合并在一起,才能正确返回数据。
- API需要账户登录生成的token才能正常请求。
- 需要先请求别的API,通过该API得到的参数,再请求正确的API。
举个栗子
现在我们要抓一个js渲染的easy网站
网站 url
# 我们想要抓取一些衣服的数据
https://www.fashion.com/collections/halter-tops
返回的html文本中,我们发现html文本的数据并没有包含所有的衣服数据,例如:价格。


在抓包中搜索,发现数据来自API
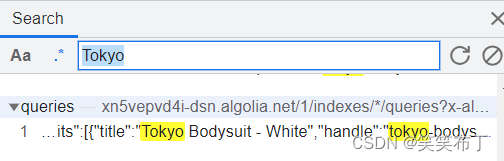
查看API请求,发现一些端倪
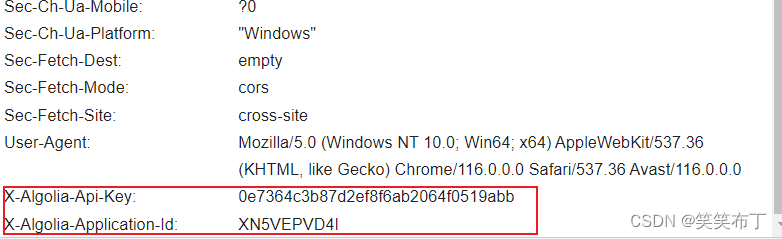
该网站在请求加了两个额外参数,很显然,如果不在请求的时候加上这两个参数,你永远得不到正确的数据。那么这两个参数要怎么得到呢?
面对未知参数,一般先搜为敬,先假设很简单
搜索后你发现,咦,原来某些js文件有该参数:

如何缩小范围?无他,唯有穷举。终于在某个js文件,你发现了端倪。
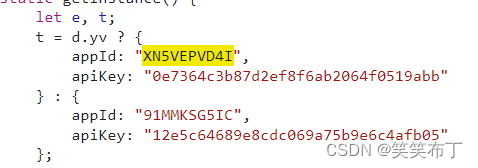
好家伙,居然一个字都没改,真是妙哉。比较难的是,有些网站会根据url,经过js转换生成唯一的token,只有带着唯一的token请求才能拿到正确的数据,比如某东南亚电商巨头
正确的请求
按照上面的思路,我们应该仿照正确翻页API构造正确的api url,但在这之前,我们应该先请求js的url,拿到key之后,把key加到请求头中请求API