一、说明
亮点:在这篇文章中,我们将展示数据增强技术作为提高模型性能的一种方式的好处。当我们没有足够的数据可供使用时,这种方法将非常有益。
教程概述:
- 无需数据增强的训练
- 什么是数据增强?
- 使用数据增强进行训练
- 可视化
二、没有数据增强的训练
一个熟悉的问题是“我们为什么要使用数据增强?所以,让我们看看答案。
为了证明这一点,我们将在TensorFlow中创建一个卷积神经网络,并在Cats-vs-Dog数据集上对其进行训练。
首先,我们将准备用于训练的数据集。我们将首先从在线存储库下载数据集。完成此操作后,我们将继续解压缩并为训练和验证集创建路径位置。
import os
import wget
import zipfilewget.download("https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip")100% [........................................................................] 68606236 / 68606236Out[2]:
'cats_and_dogs_filtered.zip'
with zipfile.ZipFile("cats_and_dogs_filtered.zip","r") as zip_ref:zip_ref.extractall()base_dir = 'cats_and_dogs_filtered'train_dir = os.path.join(base_dir, 'train')
validation_dir = os.path.join(base_dir, 'validation')让我们继续加载本教程所需的必要库。
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
import matplotlib.image as mpimgfrom tensorflow.keras import Model
from tensorflow.keras.optimizers import RMSprop
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Flatten, Dense, Dropout, Activation
from tensorflow.keras.layers import Conv2D, MaxPooling2D
from tensorflow.keras.callbacks import TensorBoard
from tensorflow.keras.preprocessing.image import img_to_array, load_img
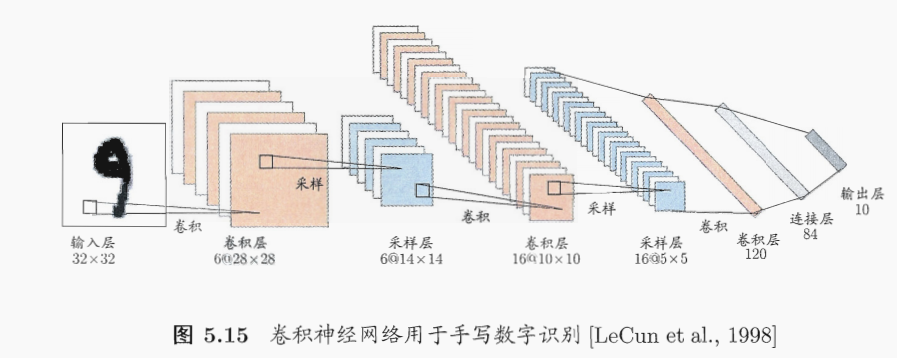
from tensorflow.keras.preprocessing.image import ImageDataGenerator我们将使用“模型子类化技术”来构建模型。这样,我们应该在__init__中定义我们的层,并在调用中实现模型的前向传递。模型的输入将是大小为 \([150, 150, 3]\) 的图像。在卷积层之后,我们将利用两个完全连接的层来进行预测。这是一个二元分类问题,所以我们在输出层中只有一个神经元。
class Create_model(Model):def __init__(self, chanDim=-1):super(Create_model, self).__init__()self.conv1A = Conv2D(16, 3, input_shape = (150, 150, 3))self.act1A = Activation("relu")self.pool1A = MaxPooling2D(2)self.conv1B = Conv2D(32, 3)self.act1B = Activation("relu")self.pool1B = MaxPooling2D(pool_size=(2, 2))self.conv1C = Conv2D(64, 3)self.act1C = Activation("relu")self.pool1C = MaxPooling2D(2)self.flatten = Flatten()self.dense2A = Dense(512)self.act2A = Activation("relu")self.dense2B = Dense(1)self.sigmoid = Activation("sigmoid")def call(self, inputs):x = self.conv1A(inputs)x = self.act1A(x)x = self.pool1A(x)x = self.conv1B(x)x = self.act1B(x)x = self.pool1B(x)x = self.conv1C(x)x = self.act1C(x)x = self.pool1C(x)x = self.flatten(x)x = self.dense2A(x)x = self.act2A(x)x = self.dense2B(x)x = self.sigmoid(x)return xmodel = Create_model()model.compile(loss='binary_crossentropy',optimizer=RMSprop(lr=0.001),metrics=['accuracy'])我们的图像不在一个文件中,而是在多个文件夹中。为了在这样的数据集上训练网络,我们需要使用图像数据生成器。在创建两个生成器(用于训练和验证)后,我们可以使用 fit 方法训练网络。唯一的区别是,我们不是将输入和输出分别传递给我们的网络,而是将数据生成器传递给网络。
最好规范化像素值,以便每个像素值的值介于 0 和 1 之间,以免中断或减慢学习过程。因此,这将是传递给图像数据生成器的唯一参数。然后,我们将使用这些数据生成器遍历目录、调整图像大小和创建批处理。
train_datagen = ImageDataGenerator(rescale=1./255)
val_datagen = ImageDataGenerator(rescale=1./255)train_generator = train_datagen.flow_from_directory(train_dir,target_size=(150, 150),batch_size=20,class_mode='binary')validation_generator = val_datagen.flow_from_directory(validation_dir,target_size=(150, 150),batch_size=20,class_mode='binary')history = model.fit(train_generator,steps_per_epoch=100,epochs=15,validation_data=validation_generator,validation_steps=50,verbose=0)让我们检查一下模型的分类准确性和损失。
在这里,训练集的准确性和损失都以蓝色显示,而验证集的准确度和损失都以橙色显示。
accuracy = history.history['accuracy']
val_accuracy = history.history['val_accuracy']loss = history.history['loss']
val_loss = history.history['val_loss']epochs = range(len(accuracy))plt.plot(epochs, accuracy)
plt.plot(epochs, val_accuracy)
plt.title('Training and validation accuracy')plt.figure()plt.plot(epochs, loss)
plt.plot(epochs, val_loss)
plt.title('Training and validation loss')
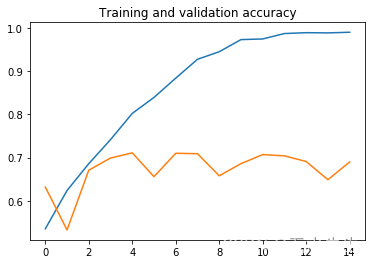

从这些图中,我们可以清楚地看到,模型在训练中的表现比在验证集上的表现要好得多。那么我们能做什么呢?使用数据增强。
三、什么是数据增强?
大多数计算机视觉任务需要大量数据,而数据增强是用于提高计算机视觉系统性能的技术之一。计算机视觉是一项相当复杂的任务。对于输入图像,算法必须找到一种模式来理解图片中的内容。
在实践中,拥有更多数据将有助于几乎所有的计算机视觉任务。今天,计算机视觉的状态需要更多的数据来解决大多数计算机视觉问题。对于卷积神经网络的所有应用来说,这可能不是真的,但对于计算机视觉领域来说确实如此。
当我们训练计算机视觉模型时,数据增强通常会有所帮助。无论我们使用迁移学习还是从头开始训练模型,都是如此。
因此,数据增强是一种技术,可以在不收集新数据的情况下显着增加可用于训练的数据的多样性。您可以在此处找到有关数据增强理论方面的更多信息。
四、 使用数据增强进行训练
乍一看,数据增强可能听起来很复杂,但幸运的是,TensorFlow 允许我们有效地实现它。
因此,我们将像以前一样使用图像数据生成器,但我们将添加重新缩放、旋转、移动、缩放、缩放和翻转。再次重要的是要说,此过程仅适用于训练集,而不应用于验证。
在这里,我们不仅要调整大小,还要添加旋转(以度为单位的范围)、高度和宽度偏移(以像素为单位的范围)、剪切范围(以度为单位的逆时针方向的角度)、缩放范围和翻转。
train_datagen = ImageDataGenerator(rescale=1./255,rotation_range=40,width_shift_range=0.2,height_shift_range=0.2,shear_range=0.2,zoom_range=0.2,horizontal_flip=True,)val_datagen = ImageDataGenerator(rescale=1./255)train_generator = train_datagen.flow_from_directory(train_dir,target_size=(150, 150),batch_size=20,class_mode='binary')validation_generator = val_datagen.flow_from_directory(validation_dir,target_size=(150, 150),batch_size=20,class_mode='binary')Found 2000 images belonging to 2 classes.
Found 1000 images belonging to 2 classes.
此外,Dropout 层将被添加到我们的神经网络中。我们将丢弃\(50%\)个起始神经元。添加 Dropout 图层将有助于防止过度拟合。
class Create_model(Model):def __init__(self, chanDim=-1):super(Create_model, self).__init__()self.conv1A = Conv2D(16, 3, input_shape = (150, 150, 3))self.act1A = Activation("relu")self.pool1A = MaxPooling2D(2)self.conv1B = Conv2D(32, 3)self.act1B = Activation("relu")self.pool1B = MaxPooling2D(pool_size=(2, 2))self.conv1C = Conv2D(64, 3)self.act1C = Activation("relu")self.pool1C = MaxPooling2D(2)self.flatten = Flatten()self.dense2A = Dense(512)self.act2A = Activation("relu")self.dropout = Dropout(0.5)self.dense2B = Dense(1)self.sigmoid = Activation("sigmoid")def call(self, inputs):x = self.conv1A(inputs)x = self.act1A(x)x = self.pool1A(x)x = self.conv1B(x)x = self.act1B(x)x = self.pool1B(x)x = self.conv1C(x)x = self.act1C(x)x = self.pool1C(x)x = self.flatten(x)x = self.dense2A(x)x = self.act2A(x)x = self.dropout(x)x = self.dense2B(x)x = self.sigmoid(x)return xmodel = Create_model()model.compile(loss='binary_crossentropy',optimizer=RMSprop(lr=0.001),metrics=['accuracy'])现在我们可以训练网络了。
history = model.fit(train_generator,steps_per_epoch=100,epochs=30,validation_data=validation_generator,validation_steps=50,verbose=2)Train for 100 steps, validate for 50 steps
Epoch 1/30
100/100 - 92s - loss: 0.9063 - accuracy: 0.5125 - val_loss: 0.7271 - val_accuracy: 0.5000
Epoch 2/30
100/100 - 56s - loss: 0.7020 - accuracy: 0.5625 - val_loss: 0.6551 - val_accuracy: 0.5480
Epoch 3/30
100/100 - 56s - loss: 0.6815 - accuracy: 0.5950 - val_loss: 0.6253 - val_accuracy: 0.6600
Epoch 4/30
100/100 - 57s - loss: 0.6594 - accuracy: 0.6220 - val_loss: 0.6262 - val_accuracy: 0.6350
Epoch 5/30
100/100 - 56s - loss: 0.6352 - accuracy: 0.6485 - val_loss: 0.5916 - val_accuracy: 0.6890
Epoch 6/30
100/100 - 56s - loss: 0.6336 - accuracy: 0.6675 - val_loss: 0.5774 - val_accuracy: 0.6790
Epoch 7/30
100/100 - 57s - loss: 0.6383 - accuracy: 0.6570 - val_loss: 0.5830 - val_accuracy: 0.6980
让我们看看结果。在这里,训练集的准确性和损失都以蓝色显示,而验证集的准确度和损失都以橙色显示。
accuracy = history.history['accuracy']
val_accuracy = history.history['val_accuracy']loss = history.history['loss']
val_loss = history.history['val_loss']epochs = range(len(accuracy))plt.plot(epochs, accuracy)
plt.plot(epochs, val_accuracy)
plt.title('Training and validation accuracy')plt.figure()plt.plot(epochs, loss)
plt.plot(epochs, val_loss)
plt.title('Training and validation loss')Text(0.5, 1.0, 'Training and validation loss')

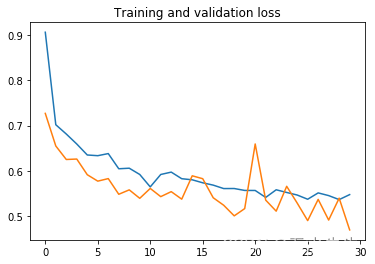
现在的结果好多了。但是,我们模型的准确性还不完美。
我们将在下一篇文章中使用迁移学习来解决这个问题。
五、 可视化
到目前为止,我们只是在讨论如何创建增强图像,但让我们看看它们的外观。
为此,我们需要使用来自生成器的一个图像并“循环它”。这将遍历生成器并执行增强。下面我们展示了这些图像样本的可视化。
augmented_images = [train_generator[0][0][0] for i in range(12)]
plt.figure(figsize=(8,6))for i in range(12):plt.subplot(3, 4, i+1)image = augmented_images[i]image = image.reshape(150, 150, 3)plt.imshow(image)
pyplot.show()
六、总结
总而言之,我们已经学会了如何使用数据增强技术来提高模型的性能。在数据稀缺或数据收集成本高昂的情况下,我们可以使用这种方法。但是,请注意,我们不能将数据集扩充到非常大的比例。此方法有其局限性。在下一篇文章中,我们将展示如何应用迁移学习的过程。
有关该主题的更多资源: