简介
梅子留酸软齿牙,芭蕉分绿与窗纱。日长睡起无情思,闲看儿童捉柳花。小伙伴们好,我是微信公众号《小窗幽记机器学习》的小编:卖雪糕的小女孩。更多、更新文章欢迎关注 微信公众号:小窗幽记机器学习。后续会持续整理模型加速、模型部署、模型压缩、LLM、AI艺术等系列专题,敬请关注。
紧接前文LLM 系列 | 04:ChatGPT Prompt编写指南 和 05:如何优化ChatGPT Prompt?,今天这篇小作文主要介绍如何通过构建ChatGPT Prompt以解决文本摘要、推断和转换这些常见的NLP任务。
文本摘要
以商品评论为例。对于电商平台来说,网站上往往存在着海量的商品评论,这些评论反映了所有客户的想法。如果有一个工具能够概括这些海量、冗长的评论,便能够快速洞悉客户的偏好,从而指导平台与商家提供更优质的服务。
示例评论如下:
prod_review_zh = """
这个熊猫公仔是我给女儿的生日礼物,她很喜欢,去哪都带着。
公仔很软,超级可爱,面部表情也很和善。但是相比于价钱来说,
它有点小,我感觉在别的地方用同样的价钱能买到更大的。
快递比预期提前了一天到货,所以在送给女儿之前,我自己玩了会。
"""
限制长度
尝试限制文本长度为最多30词,优化后的 prompt 如下:
prompt = f"""
你的任务是从电子商务网站上生成一个产品评论的简短摘要。请对三个反引号之间的评论文本进行概括,最多30个词。评论: ```{prod_review_zh}```
"""response = get_completion(prompt)
print(response)
输出结果如下:
可爱软熊猫公仔,女儿喜欢,但价钱有点贵,大小不够。快递提前一天到货。
关注不同角度
有时,针对不同的业务,对文本的侧重会有所不同。例如对于同一个商品评论文本,物流侧的相关人员会更关心运输时效,而商家更加关心价格与商品质量,平台更关心整体服务体验。这时可以通过增加Prompt提示,来体现对于某个特定角度的侧重。
侧重于运输
prompt = f"""
你的任务是从电子商务网站上生成一个产品评论的简短摘要。请对三个反引号之间的评论文本进行概括,最多30个词汇,并且聚焦在产品运输上。评论: ```{prod_review_zh}```
"""response = get_completion(prompt)
print(response)
输出结果如下:
快递提前一天到货,熊猫公仔很可爱但有点小,价钱稍高。
从上述结果可以看出,输出结果以“快递提前一天到货”开头,体现了对于快递效率的侧重。
侧重于价格与质量
prompt = f"""
你的任务是从电子商务网站上生成一个产品评论的简短摘要。请对三个反引号之间的评论文本进行概括,最多30个词,并且聚焦在产品价格和质量上。评论: ```{prod_review_zh}```
"""response = get_completion(prompt)
print(response)
输出结果如下:
可爱的熊猫公仔,质量好,面部表情友好,但价钱有点高,尺寸有点小。快递提前到货。
关键信息提取
在上一个章节中,虽然通过添加关键角度侧重的Prompt,使得文本摘要更侧重于某一特定方面,但是可以发现,结果中也会保留一些其他信息,如价格与质量角度的概括中仍保留了“快递提前到货”的信息。有时这些信息是有帮助的,但如果我们只想要提取某一角度的信息,并过滤掉其他所有信息,则可以要求LLM进行“文本提取(Extract)”而非“文本概括(Summarize)”。
prompt = f"""
你的任务是从电子商务网站上的产品评论中提取相关信息。请从以下三个反引号之间的评论文本中提取产品运输相关的信息,最多30个词汇。评论: ```{prod_review_zh}```
"""response = get_completion(prompt)
print(response)
输出结果如下:
快递比预期提前了一天到货。
批量进行文本摘要
在实际的工作流中,我们往往有许许多多的评论文本,以下展示了一个基于for循环调用“文本摘要”工具并依次打印的示例。当然,在实际生产中,对于上百万甚至上千万的评论文本,使用for循环也是不现实的,可能需要考虑整合评论、分布式等方法提升运算效率。
review_1 = prod_review # review for a standing lamp
review_2 = """
Needed a nice lamp for my bedroom, and this one \
had additional storage and not too high of a price \
point. Got it fast - arrived in 2 days. The string \
to the lamp broke during the transit and the company \
happily sent over a new one. Came within a few days \
as well. It was easy to put together. Then I had a \
missing part, so I contacted their support and they \
very quickly got me the missing piece! Seems to me \
to be a great company that cares about their customers \
and products.
"""# review for an electric toothbrush
review_3 = """
My dental hygienist recommended an electric toothbrush, \
which is why I got this. The battery life seems to be \
pretty impressive so far. After initial charging and \
leaving the charger plugged in for the first week to \
condition the battery, I've unplugged the charger and \
been using it for twice daily brushing for the last \
3 weeks all on the same charge. But the toothbrush head \
is too small. I’ve seen baby toothbrushes bigger than \
this one. I wish the head was bigger with different \
length bristles to get between teeth better because \
this one doesn’t. Overall if you can get this one \
around the $50 mark, it's a good deal. The manufactuer's \
replacements heads are pretty expensive, but you can \
get generic ones that're more reasonably priced. This \
toothbrush makes me feel like I've been to the dentist \
every day. My teeth feel sparkly clean!
"""# review for a blender
review_4 = """
So, they still had the 17 piece system on seasonal \
sale for around $49 in the month of November, about \
half off, but for some reason (call it price gouging) \
around the second week of December the prices all went \
up to about anywhere from between $70-$89 for the same \
system. And the 11 piece system went up around $10 or \
so in price also from the earlier sale price of $29. \
So it looks okay, but if you look at the base, the part \
where the b
prompt 如下:
import time
for i in range(len(reviews)):prompt = f"""Your task is to generate a short summary of a product \ review from an ecommerce site. Summarize the review below, delimited by triple \backticks in at most 20 words. Review: ```{reviews[i]}```"""response = get_completion(prompt)print(i, response, "\n")time.sleep(60) # 限流
输出结果如下:
0 Soft and cute panda plush toy loved by daughter, but a bit small for the price. Arrived early. 1 Affordable lamp with storage, fast shipping, and excellent customer service. Easy to assemble and missing parts were quickly replaced. 2 Good battery life, small toothbrush head, but effective cleaning. Good deal if bought around $50. 3 The product was on sale for $49 in November, but the price increased to $70-$89 in December. The base doesn't look as good as previous editions, but the reviewer plans to be gentle with it. A special tip for making smoothies is to freeze the fruits and vegetables beforehand. The motor made a funny noise after a year, and the warranty had expired. Overall quality has decreased. 文本推断
所谓的文本推断,包括抽取标签、抽取名字、理解文本中的情感等等。比如从产品评论和新闻文章中推断情感和主题。
这些任务可以看作是模型接收文本作为输入并执行某种分析的过程。这可能涉及提取标签、提取实体、理解文本情感等等。如果想要从一段文本中提取正面或负面情感,在传统的机器学习工作流程中,需要收集标签数据集、训练模型、确定如何在云端部署模型并进行推断。这样做可能效果还不错,但是这个过程需要很多工作。而且对于每个任务,如情感分析、提取实体等等,都需要训练和部署单独的模型。
大型语言模型的一个非常好的特点是,对于许多这样的任务,你只需要编写一个prompt即可开始产生结果,而不需要进行大量的工作。这极大地加快了应用程序开发的速度。你还可以只使用一个模型和一个 API 来执行许多不同的任务,而不需要弄清楚如何训练和部署许多不同的模型。
情感(正向/负向)
给定一个商品评论文本,比如以下是一盏台灯的评论。
# 中文
lamp_review_zh = """
我需要一盏漂亮的卧室灯,这款灯具有额外的储物功能,价格也不算太高。\
我很快就收到了它。在运输过程中,我们的灯绳断了,但是公司很乐意寄送了一个新的。\
几天后就收到了。这款灯很容易组装。我发现少了一个零件,于是联系了他们的客服,他们很快就给我寄来了缺失的零件!\
在我看来,Lumina 是一家非常关心顾客和产品的优秀公司!
"""
现在来编写一个prompt来分类这个评论的情感。如果我想让系统告诉我这个评论的情感是什么,只需要编写 “以下产品评论的情感是什么” 这个prompt,加上通常的分隔符和评论文本等等。
# 中文
prompt = f"""
以下用三个反引号分隔的产品评论的情感是什么?评论文本: ```{lamp_review_zh}```
"""
response = get_completion(prompt)
print(response)
输出结果如下:
情感是积极的/正面的。
结果显示这个产品评论的情感是积极的,这似乎是非常正确的。虽然这盏台灯不完美,但这个客户似乎非常满意。这似乎是一家关心客户和产品的伟大公司,可以认为积极的情感似乎是正确的答案。
如果想要给出更简洁的答案,以便更容易进行后处理,可以使用上面的prompt并添加另一个指令,以一个单词 “正面” 或 “负面” 的形式给出答案。这样就只会打印出 “正面” 这个单词,这使得文本更容易接受这个输出并进行处理。
prompt = f"""
以下用三个反引号分隔的产品评论的情感是什么?用一个单词回答:「正面」或「负面」。评论文本: ```{lamp_review_zh}```
"""
response = get_completion(prompt)
print(response)
输出结果如下:
正面
识别情感类型
让我们看看另一个prompt,仍然使用台灯评论。这次我要让它识别出以下评论作者所表达的情感列表,不超过五个。
# 中文
prompt = f"""
识别以下评论的作者表达的情感。包含不超过五个项目。将答案格式化为以逗号分隔的单词列表。评论文本: ```{lamp_review_zh}```
"""
response = get_completion(prompt)
print(response)
输出结果如下:
满意,感激,信任,赞扬,愉快
大型语言模型非常擅长从一段文本中提取特定的东西。在上面的例子中,评论正在表达情感,这可能有助于了解客户如何看待特定的产品。
识别愤怒
对于很多企业来说,了解某个顾客是否非常生气很重要。所以你可能有一个类似这样的分类问题:以下评论的作者是否表达了愤怒情绪?因为如果有人真的很生气,那么可能值得额外关注,让客户支持或客户成功团队联系客户以了解情况,并为客户解决问题。
# 中文
prompt = f"""
以下评论的作者是否表达了愤怒?评论用三个反引号分隔。给出是或否的答案。评论文本: ```{lamp_review_zh}```
"""
response = get_completion(prompt)
print(response)
输出结果如下:
否
上面这个例子中,客户并没有生气。注意,如果使用常规的监督学习,如果想要建立所有这些分类器,不可能在几分钟内就做到这一点。我们可以尝试更改一些类似的prompt,比如询问客户是否表达了喜悦,或者询问是否有任何遗漏的部分,并看看是否可以让prompt对这个灯具评论做出不同的推论。
提取产品和公司名
接下来,让我们尝试从客户评论中提取更丰富的信息。信息提取是自然语言处理(NLP)的一部分,与从文本中提取你想要知道的某些事物相关。因此,在这个prompt中,我们要求它识别以下内容:购买物品和制造物品的公司名称。
同样,如果你试图总结在线购物电子商务网站的许多评论,对于这些评论来说,弄清楚是什么物品,谁制造了该物品,弄清楚积极和消极的情感,以跟踪特定物品或特定制造商的积极或消极情感趋势,可能会很有用。
在下面这个示例中,我们要求它将响应格式化为一个 JSON 对象,其中物品和品牌是JSON的键。
# 中文
prompt = f"""
从评论文本中识别以下项目:
- 评论者购买的物品
- 制造该物品的公司评论文本用三个反引号分隔。将你的响应格式化为以 “物品” 和 “品牌” 为键的 JSON 对象。
如果信息不存在,请使用 “未知” 作为值。
让你的回应尽可能简短。评论文本: ```{lamp_review_zh}```
"""
response = get_completion(prompt)
print(response)
输出结果如下:
{"物品": "卧室灯","品牌": "Lumina"
}
如上所示,它会说这个物品是一个卧室灯,品牌是 Luminar,对于该结果我们可以轻松地将其加载到 Python 字典中,然后对此输出进行其他处理。
一次完成多项任务
提取上面所有这些信息使用了 3 或 4 个prompt,但实际上可以编写单个prompt来同时提取所有这些信息。
# 中文
prompt = f"""
从评论文本中识别以下项目:
- 情绪(正面或负面)
- 审稿人是否表达了愤怒?(是或否)
- 评论者购买的物品
- 制造该物品的公司评论用三个反引号分隔。将您的响应格式化为 JSON 对象,以 “Sentiment”、“Anger”、“Item” 和 “Brand” 作为键。
如果信息不存在,请使用 “未知” 作为值。
让你的回应尽可能简短。
将 Anger 值格式化为布尔值。评论文本: ```{lamp_review_zh}```
"""
response = get_completion(prompt)
print(response)
输出结果:
{"Sentiment": "正面","Anger": false,"Item": "卧室灯","Brand": "Lumina"
}
这个例子中,我们告诉它将愤怒值格式化为布尔值,然后输出一个 JSON。小伙伴们可以自己尝试不同的变化,或者尝试完全不同的评论,看看是否仍然可以准确地提取这些内容。
推断主题
大型语言模型的一个很酷的应用是推断主题。比如给定一段长文本,想要了解这段文本是关于什么的?有什么话题?
# 中文
story_zh = """
在政府最近进行的一项调查中,要求公共部门的员工对他们所在部门的满意度进行评分。
调查结果显示,NASA 是最受欢迎的部门,满意度为 95%。一位 NASA 员工 John Smith 对这一发现发表了评论,他表示:
“我对 NASA 排名第一并不感到惊讶。这是一个与了不起的人们和令人难以置信的机会共事的好地方。我为成为这样一个创新组织的一员感到自豪。”NASA 的管理团队也对这一结果表示欢迎,主管 Tom Johnson 表示:
“我们很高兴听到我们的员工对 NASA 的工作感到满意。
我们拥有一支才华横溢、忠诚敬业的团队,他们为实现我们的目标不懈努力,看到他们的辛勤工作得到回报是太棒了。”调查还显示,社会保障管理局的满意度最低,只有 45%的员工表示他们对工作满意。
政府承诺解决调查中员工提出的问题,并努力提高所有部门的工作满意度。
"""
推断5个主题
上面是一篇虚构的关于政府工作人员对他们工作机构感受的报纸文章。我们可以让它确定五个正在讨论的主题,用一两个字描述每个主题,并将输出格式化为逗号分隔的列表。
# 中文
prompt = f"""
确定以下给定文本中讨论的五个主题。每个主题用1-2个单词概括。输出时用逗号分割每个主题。给定文本: ```{story_zh}```
"""
response = get_completion(prompt)
print(response)
输出结果如下:
公共部门满意度调查, NASA, 社会保障管理局, 员工满意度, 政府承诺
为特定主题制作新闻提醒
假设我们有一个新闻网站或类似的东西,这是我们感兴趣的主题:NASA、地方政府、工程、员工满意度、联邦政府等。假设我们想弄清楚,针对一篇新闻文章,其中涵盖了哪些主题。可以使用这样的prompt:确定以下主题列表中的每个项目是否是以下文本中的主题。以 0 或 1 的形式给出答案列表。
# 中文
prompt = f"""
判断主题列表中的每一项是否是给定文本中的一个话题,以列表的形式给出答案,每个主题用 0 或 1。主题列表:美国航空航天局、当地政府、工程、员工满意度、联邦政府给定文本: ```{story_zh}```
"""
response = get_completion(prompt)
print(response)
输出结果如下:
美国航空航天局:1
当地政府:0
工程:0
员工满意度:1
联邦政府:1
所以,这个故事是关于 NASA 的。它不是关于当地政府的,不是关于工程的。它是关于员工满意度的,它是关于联邦政府的。这在机器学习中有时被称为 Zero-Shot 学习算法,因为我们没有给它任何标记的训练数据。仅凭prompt,它就能确定哪些主题在新闻文章中涵盖了。
如果我们想生成一个新闻提醒,也可以使用这个处理新闻的过程。假设我非常喜欢 NASA 所做的工作,就可以构建一个这样的系统,每当 NASA 新闻出现时,输出提醒。
topic_dict = {i.split(':')[0]: int(i.split(':')[1]) for i in response.split(sep='\n')}
if topic_dict['美国航空航天局'] == 1:print("提醒: 关于美国航空航天局的新消息")
输出结果如下:
提醒: 关于美国航空航天局的新消息
文本转换(Transforming)
这里所谓的文本转换任务,包括但不限于语言翻译、拼写和语法检查、语气调整和格式转换(例如 HTML 到 JSON)等。
翻译
ChatGPT 的训练语料库包含各种语言,翻译自然不在话下。
中文翻译成英文
prompt = f"""
将以下中文翻译成英语: \
```您好,我想订购一个搅拌机。```
"""
response = get_completion(prompt)
print(response)
输出结果如下:
Hello, I would like to order a mixer.
语种识别
prompt = f"""
请告诉我以下文本是什么语种:
```Combien coûte le lampadaire?```
"""
response = get_completion(prompt)
print(response)
输出结果如下:
这是法语。
多语种翻译
prompt = f"""
请将以下文本分别翻译成中文、英文、法语和西班牙语:
```I want to order a basketball.```
"""
response = get_completion(prompt)
print(response)
输出结果如下:
中文:我想订购一个篮球。
英文:I want to order a basketball.
法语:Je veux commander un ballon de basket.
西班牙语:Quiero pedir una pelota de baloncesto.
使用不同语气翻译
prompt = f"""
请将以下文本翻译成中文,分别展示成正式与非正式两种语气:
```Would you like to order a pillow?```
"""
response = get_completion(prompt)
print(response)
输出结果如下:
正式语气:请问您需要订购枕头吗?
非正式语气:你要不要订一个枕头?
通用翻译器
随着全球化与跨境商务的发展,交流的用户可能来自各个不同的国家,使用不同的语言,因此我们需要一个通用翻译器,识别各个消息的语种,并翻译成目标用户的母语,从而实现更方便的跨国交流。
user_messages = ["La performance du système est plus lente que d'habitude.", # System performance is slower than normal "Mi monitor tiene píxeles que no se iluminan.", # My monitor has pixels that are not lighting"Il mio mouse non funziona", # My mouse is not working"Mój klawisz Ctrl jest zepsuty", # My keyboard has a broken control key"我的屏幕在闪烁" # My screen is flashing
]
具体 Prompt 如下:
for issue in user_messages:prompt = f"告诉我以下文本是什么语种,直接输出语种,如法语,无需输出标点符号: ```{issue}```"lang = get_completion(prompt)print(f"原始消息 ({lang}): {issue}\n")prompt = f"""将以下消息分别翻译成英文和中文,并写成中文翻译:xxx英文翻译:yyy的格式:```{issue}```"""response = get_completion(prompt)print(response, "\n=========================================")time.sleep(40)
输出结果如下:
原始消息 (法语): La performance du système est plus lente que d'habitude.中文翻译:系统性能比平时慢。
英文翻译:The system performance is slower than usual.
=========================================
原始消息 (西班牙语。): Mi monitor tiene píxeles que no se iluminan.中文翻译:我的显示器有一些像素点不亮。
英文翻译:My monitor has pixels that don't light up.
=========================================
原始消息 (意大利语): Il mio mouse non funziona中文翻译:我的鼠标不工作了。
英文翻译:My mouse is not working.
=========================================
原始消息 (波兰语): Mój klawisz Ctrl jest zepsuty中文翻译:我的Ctrl键坏了
英文翻译:My Ctrl key is broken.
=========================================
原始消息 (中文): 我的屏幕在闪烁中文翻译:我的屏幕在闪烁。
英文翻译:My screen is flickering.
=========================================
语气转换
写作的语气往往会根据受众对象而有所调整。例如,对于工作邮件,我们常常需要使用正式语气与书面用词,而对同龄朋友的微信聊天,可能更多地会使用轻松、口语化的语气。比如将对话体转变成邮件体:
prompt = f"""
将以下文本翻译成商务信函的格式:
```小老弟,我小李,上回你说咱部门要采购的显示器是多少寸来着?```
"""
response = get_completion(prompt)
print(response)
输出结果如下:
尊敬的XXX(收件人姓名):我是XXX(发件人姓名),想向您确认一下我们部门需要采购的显示器尺寸是多少寸。上次我们交流时,您提到过这个问题,但我没有完全记住。如果您能尽快回复我,我将不胜感激。谢谢!此致,敬礼XXX(发件人姓名)
格式转换
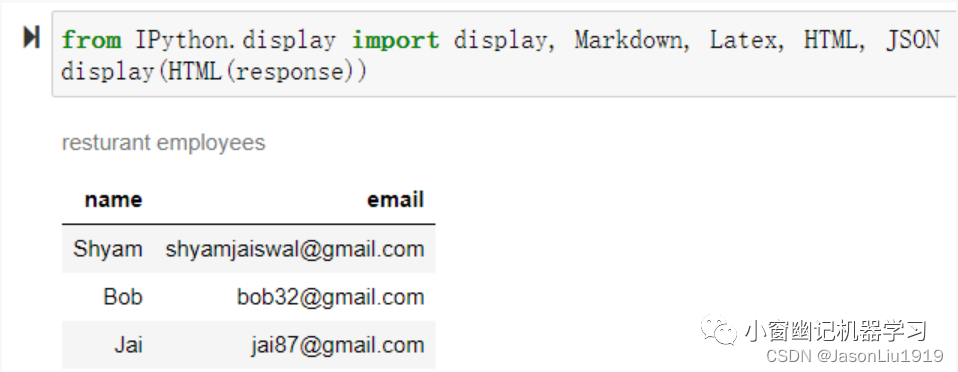
ChatGPT非常擅长不同格式之间的转换,例如JSON到HTML、XML、Markdown等。在下述例子中,我们有一个包含餐厅员工姓名和电子邮件的列表的JSON,我们希望将其从JSON转换为HTML。
data_json = { "resturant employees" :[ {"name":"Shyam", "email":"shyamjaiswal@gmail.com"},{"name":"Bob", "email":"bob32@gmail.com"},{"name":"Jai", "email":"jai87@gmail.com"}
]}prompt = f"""
将以下Python字典从JSON转换为HTML表格,保留表格标题和列名:{data_json}
"""
response = get_completion(prompt)
print(response)
输出结果如下:
<table><caption>resturant employees</caption><thead><tr><th>name</th><th>email</th></tr></thead><tbody><tr><td>Shyam</td><td>shyamjaiswal@gmail.com</td></tr><tr><td>Bob</td><td>bob32@gmail.com</td></tr><tr><td>Jai</td><td>jai87@gmail.com</td></tr></tbody>
</table>
在Notebook中直接显示HTML:
from IPython.display import display, Markdown, Latex, HTML, JSON
display(HTML(response))
输出结果如下:
语法检查
拼写及语法的检查与纠正是一个十分常见的需求,特别是使用非母语语言,例如发表英文论文时,这是一件十分重要的事情。
以下给了一个例子,有一个句子列表,其中有些句子存在拼写或语法问题,有些则没有,我们循环遍历每个句子,要求模型校对文本,如果正确则输出“未发现错误”,如果错误则输出纠正后的文本。
语法检查:在发邮件、写文章时,用 ChatGPT 进行语法检查的 Prompt:
prompt = f"""Proofread and correct the following text. If you don't find and errors, just say "No errors found". Don't use any punctuation around the text:```{text}```"""
text = [ "The girl with the black and white puppies have a ball.", # The girl has a ball."Yolanda has her notebook.", # ok"Its going to be a long day. Does the car need it’s oil changed?", # Homonyms"Their goes my freedom. There going to bring they’re suitcases.", # Homonyms"Your going to need you’re notebook.", # Homonyms"That medicine effects my ability to sleep. Have you heard of the butterfly affect?", # Homonyms"This phrase is to cherck chatGPT for spelling abilitty" # spelling
]for i in range(len(text)):prompt = f"""请校对并更正以下文本,注意纠正文本保持原始语种,无需输出原始文本。如果您没有发现任何错误,请说“未发现错误”。例如:输入:I are happy.输出:I am happy.```{text[i]}```"""response = get_completion(prompt)print(i, response)time.sleep(30)
输出结果如下:
0 The girl with the black and white puppies has a ball.
1 未发现错误。
2 It's going to be a long day. Does the car need its oil changed?
3 Their goes my freedom. They're going to bring their suitcases.
4 输出:You're going to need your notebook.
5 That medicine affects my ability to sleep. Have you heard of the butterfly effect?
6 This phrase is to check chatGPT for spelling ability.
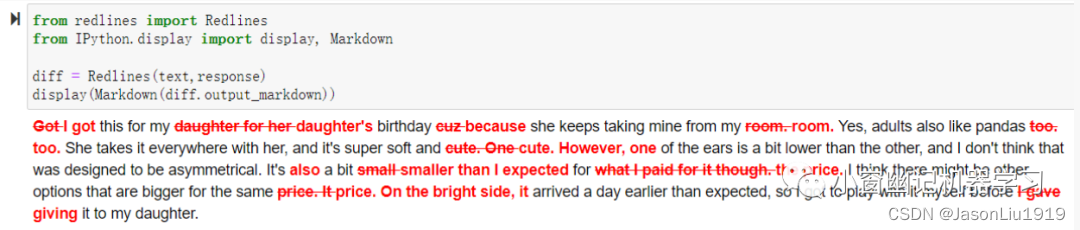
以下是一个简单的类Grammarly纠错示例,输入原始文本,输出纠正后的文本,并基于Redlines输出纠错过程。
text = f"""
Got this for my daughter for her birthday cuz she keeps taking \
mine from my room. Yes, adults also like pandas too. She takes \
it everywhere with her, and it's super soft and cute. One of the \
ears is a bit lower than the other, and I don't think that was \
designed to be asymmetrical. It's a bit small for what I paid for it \
though. I think there might be other options that are bigger for \
the same price. It arrived a day earlier than expected, so I got \
to play with it myself before I gave it to my daughter.
"""prompt = f"校对并更正以下商品评论:```{text}```"
response = get_completion(prompt)
print(response)
输出结果如下:
I got this for my daughter's birthday because she keeps taking mine from my room. Yes, adults also like pandas too. She takes it everywhere with her, and it's super soft and cute. However, one of the ears is a bit lower than the other, and I don't think that was designed to be asymmetrical. It's also a bit smaller than I expected for the price. I think there might be other options that are bigger for the same price. On the bright side, it arrived a day earlier than expected, so I got to play with it myself before giving it to my daughter.
安装 redlines:
# 如未安装redlines,需先安装
pip3.8 install redlines
使用Redlines对比纠错前后的效果:
from redlines import Redlines
from IPython.display import display, Markdowndiff = Redlines(text,response)
display(Markdown(diff.output_markdown))
输出结果如下:
综合样例:文本翻译+拼写纠正+风格调整+格式转换
prompt = f"""
针对以下三个反引号之间的英文评论文本,
首先进行拼写及语法纠错,
然后将其转化成中文,
再将其转化成优质淘宝评论的风格,从各种角度出发,分别说明产品的优点与缺点,并进行总结。
润色一下描述,使评论更具有吸引力。
输出结果格式为:
【优点】xxx
【缺点】xxx
【总结】xxx
注意,只需填写xxx部分,并分段输出。
将结果输出成Markdown格式。
```{text}```
"""
response = get_completion(prompt)
display(Markdown(response))
输出结果如下:
【优点】超级柔软可爱,女儿生日礼物非常合适。
成年人也喜欢熊猫,我也很喜欢它。
提前一天到货,我还能玩一下再送给女儿。
【缺点】一只耳朵比另一只低,不对称。
价格有点贵,但尺寸有点小,可能有更大的同价位选择。
【总结】 这只熊猫玩具非常适合作为生日礼物,柔软可爱,不仅适合孩子,也适合成年人。虽然价格有点贵,但尺寸有点小,不对称的设计也有点让人失望。如果你想要更大的同价位选择,可能需要考虑其他选项。总的来说,这是一款不错的熊猫玩具,但有一些小问题需要注意。