在 Spark SQL 中,Window 函数是一种用于在查询结果集中执行聚合、排序和分析操作的强大工具。它允许你在查询中创建一个窗口,然后对窗口内的数据进行聚合计算。
import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.functions._// 创建一个 WindowSpec 对象,指定窗口的分区和排序方式
val windowSpec = Window.partitionBy("category").orderBy(desc("sales"))// 使用 Window 函数计算每个类别的销售额排名
val result = df.withColumn("rank", rank().over(windowSpec))result.show()然后,通过创建一个 `WindowSpec` 对象,指定了窗口的分区方式(`partitionBy("category")`)和排序方式(`orderBy(desc("sales"))`)。
接下来,使用 `rank()` 函数和 `over` 方法应用窗口规范,计算每个类别的销售额排名。`rank()` 函数是一个窗口函数,它返回每个行的排名。
最后,使用 `withColumn` 方法将计算出的排名添加为新的列,并通过 `show()` 方法展示结果。
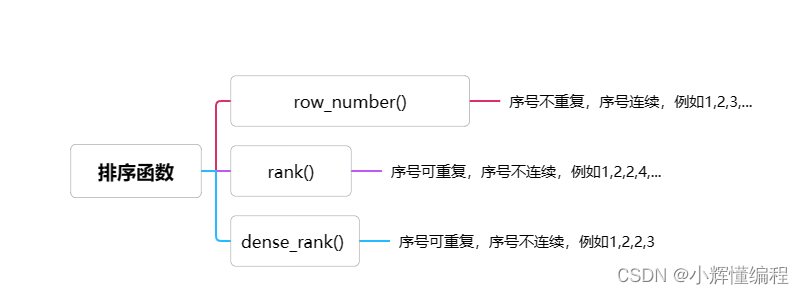
总结
窗口函数首先先进行分组(partition by),在进行排序(order by),得到返回值。再用序号函数用over方法进行调用