大家好,我是微学AI,今天给大家介绍一下人工智能(pytorch)搭建模型20-基于pytorch搭建文本生成视频的生成对抗网络,技术创新点介绍,随着人工智能和深度学习技术的飞速发展,文本到视频生成已经成为计算机视觉领域中一个重要且具有挑战性的研究方向。该技术通过自然语言处理(NLP)和计算机视觉(CV)两大核心技术相结合,实现从文本描述直接生成对应的视频内容。在电影制作、游戏设计、虚拟现实等众多领域都有广泛应用。
一、应用背景
在许多情况下,我们需要根据文本信息来创建或编辑视频。例如,在电影制作中,导演可能需要根据剧本来创造场景;在新闻报道中,记者可能需要根据文字稿件来编辑相应的新闻片段;而在教育领域中,教师可能需要根据课程大纲来制作教学视频。
然而,这些任务通常需要大量人力物力,并且过程复杂耗时。而文本到视频生成技术则可以有效地解决这个问题:只需输入相关描述信息,就能自动生成高质量的视频内容。
二、文本生成视频模型创新点
近年来, 借助深度学习和神经网络, 文字到视觉内容转换取得了显著进步。特别是GAN(Generative Adversarial Networks) 的出现, 进一步推动了这个领域的发展。
创新点1: 注意力机制
注意力机制(Attention Mechanism)源自人类的视觉感知,当我们观察一个物体时,我们会将更多的注意力集中在与当前任务最相关的部分上。在深度学习中,注意力机制也起到类似的作用。在文本到视频生成任务中,注意力机制可以使模型在生成视频帧时,更加关注输入描述中与当前帧最相关的部分。
例如,对于描述“一个男人正在跑步”的文本输入,在生成表示“跑步”动作的视频帧时,模型应该将更多注意力放在“跑步”这个词上。这样可以使得生成的视频更加符合输入描述。
创新点2: 时间一致性
时间一致性(Temporal Consistency)是指连续帧之间需要有平滑过渡,不能出现剧烈变化。这是因为,在真实世界中,物体不可能突然消失或者突然出现;同样地,在视频中也不应该出现这种情况。
例如,在生成一个表示“男人从走路过渡到跑步”的视频时,不能直接从走路的场景切换到跑步的场景;而应该包含表示过渡动作(比如加快走速、开始小跑等)的帧。通过保证时间一致性,可以使得生成的视频看起来更加自然流畅。
创新点3: 多模态学习
多模态学习(Multi-modal Learning)是指同时考虑多种类型数据源进行训练。对于文本到视频生成任务来说,则可能需要同时考虑音频、文字等不同类型数据源。
例如,在电影制作中,“轻快地背景音乐配合着主角奔跑”的场景比单纯只有主角奔跑显得更生动有趣;而在教育领域,“讲解声音配合着相关图像展示”的方式则能提高学生理解和记忆效果。
通过整合各种信息来源,并正确处理它们之间可能存在的关联和互补性问题, 可以进一步提高模型表达能力与适应性。
三、模型数学原理
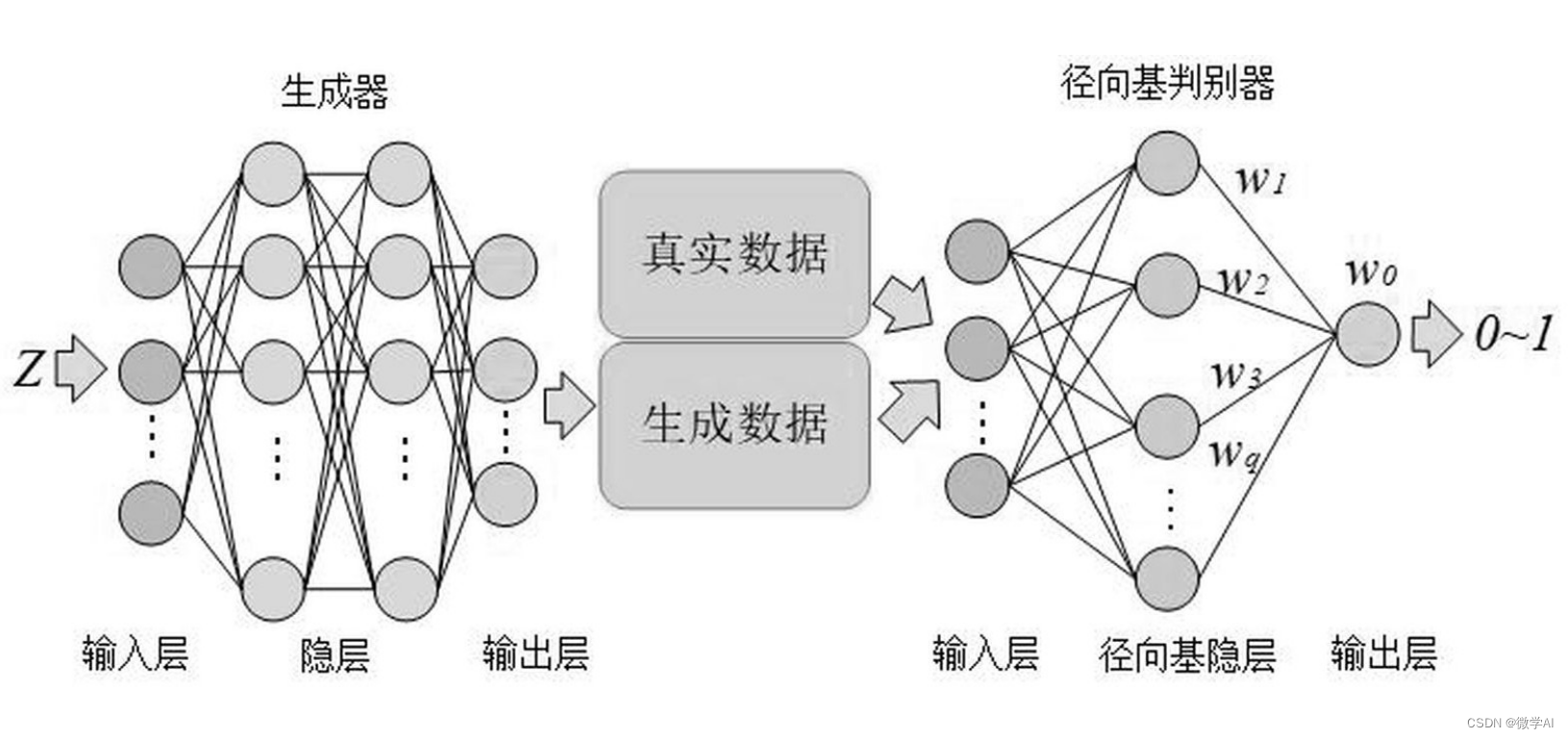
我们将主要介绍基于GAN的文本到视频生成模型。在这个模型中,我们有两个网络:生成器G和判别器D。
3.1 生成器
生成器的目标是根据输入的文本描述,生成尽可能接近真实的视频帧。其形式可以表示为:
G ( z ∣ t ) = x ′ G(z|t) = x' G(z∣t)=x′
其中, z z z 是随机噪声向量, t t t 是输入文本描述, x ′ x' x′ 是生成的视频帧。
3.2 判别器
判别器则需要判断一个给定的视频帧是否是由文本描述生成的。其形式可以表示为:
D ( x , t ) = p D(x, t) = p D(x,t)=p
其中, x x x 是输入视频帧(可能是真实或者由G产生), t t t 是对应文本描述, p ∈ [ 0 , 1 ] p \in [0,1] p∈[0,1] 表示 x x x 是否由 t t t 产生。
3.3 损失函数
模型训练目标就是最小化以下损失函数:
L ( G , D ) = E x , t [ l o g D ( x , t ) ] + E z , t [ l o g ( 1 − D ( G ( z ∣ t ) , t ) ) ] L(G,D) = \mathbb{E}_{x,t}[log D(x,t)] + \mathbb{E}_{z,t}[log(1-D(G(z|t), t))] L(G,D)=Ex,t[logD(x,t)]+Ez,t[log(1−D(G(z∣t),t))]
四、关键技术点
关键技术点主要包括如何设计有效的注意力机制来捕获语义信息、如何保证时间一致性以及如何整合多模态信息等。
五、编码需求
使用PyTorch框架进行编程。首先需要安装PyTorch库以及其他相关库,例如numpy、matplotlib等。
pip install torch torchvision numpy matplotlib
以下是一个生成对抗网络的搭建,展示了如何使用PyTorch构建一个简单的GAN模型,并进行训练和测试。请注意,这个模型并不直接实现文本到视频生成,而只是提供了一种基础框架。
import torch
from torch import nn
from torch.autograd.variable import Variable# 构建生成器
class Generator(nn.Module):def __init__(self):super(Generator, self).__init__()self.main = nn.Sequential(nn.Linear(100, 256),nn.ReLU(True),nn.Linear(256, 512),nn.ReLU(True),nn.Linear(512, 1024),nn.ReLU(True),nn.Linear(1024, 784), )def forward(self, input):return self.main(input).view(-1, 1, 28, 28)# 构建判别器
class Discriminator(nn.Module):def __init__(self):super(Discriminator,self).__init__()self.main = nn.Sequential(nn.Linear(784 ,1024),#nn.LeakyReLU(),#nn.Dropout(),#nn.Linear(),#nn.LeakyReLU(),#nn.Dropout(),#nn.linear())def forward(self,input):input = input.view(-1 ,784)return self.main(input)# 数据预处理阶段需要根据具体数据集进行处理# 模型训练阶段
def train(G,D,data_loader,criterion,opt_g,opt_d):for epoch in range(num_epochs): for i ,(images ,_) in enumerate(data_loader): images = Variable(images)real_labels = Variable(torch.ones(images.size(0)))fake_labels = Variable(torch.zeros(images.size(0)))outputs = D(images)d_loss_real = criterion(outputs ,real_labels) z=Variable(torch.randn(batch_size ,100))fake_images=G(z)outputs=D(fake_images.detach())d_loss_fake=criterion(outputs,fake_labels) d_loss=d_loss_real +d_loss_fake D.zero_grad()d_loss.backward() opt_d.step()outputs=D(fake_images) g_loss=criterion(outputs ,real_labels) D.zero_grad() G.zero_grad() g_loss.backward() opt_g.step()# 模型测试阶段需要根据具体任务来设计测试方法和评价指标
以上并没有包含上文中提到的注意力机制、时间一致性等技术点。真正实现文本到视频生成还需要进一步研究和实现。
同时,数据预处理、模型训练和测试等步骤也需要根据具体的任务和数据集来设计。例如,在数据预处理阶段,可能需要进行文本编码、图像归一化等操作;在模型训练阶段,可能需要设置合适的学习率、批次大小等参数;在模型测试阶段,则需要设计合适的评价指标来评估模型性能。
六、结论
文本到视频生成作为一个新兴且具有挑战性的研究领域,在未来还有很大发展空间。尽管当前已经取得了一些成果,但仍然存在许多问题待解决,并且期待更多优秀研究者和工程师加入这个领域。