介绍
Whisper是OpenAI于2022年9月份开源的通用的语音识别模型。它是在各种音频的大型数据集上训练的模型,也是一个可以执行多语言语音识别、语音翻译和语言识别的多任务模型。
论文链接:https://arxiv.org/abs/2212.04356
github链接:https://github.com/openai/whisper
安装
Whisper主要是基于Pytorch实现,所以需要在安装有pytorch的环境中使用。
1、安装Whisper
pip install -U openai-whisper
或者
pip install git+https://github.com/openai/whisper.git
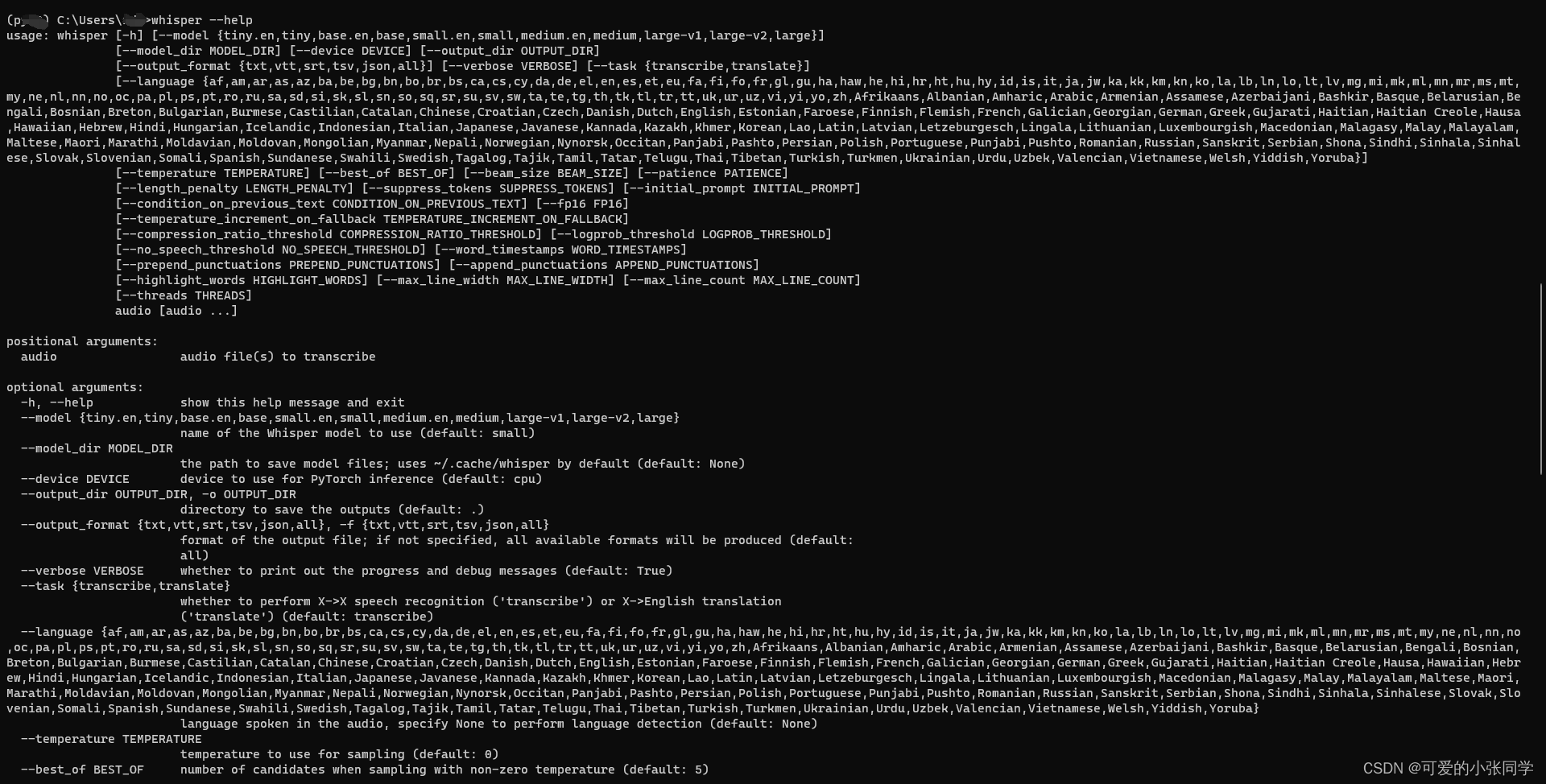
安装好之后,打开cmd界面,执行whisper,出现如下提示说明安装成功

2、安装FFmpeg
FFmpeg是一款音视频编解码工具。Whisper需要使用FFmpeg工具提取声音数据,所以需要安装配置FFmpeg。
参考博客:https://blog.csdn.net/weixin_45487348/article/details/130722161
安装好之后,,打开cmd界面,执行ffmpeg,出现如下提示说明安装成功
3、安装Rust
网上很多步骤说,需要安装Rust,用于实现快速分词,因为我暂时没用到这个,所以大家按需下载~
pip install setuptools-rust
使用
命令行方式
# 帮助信息
whisper --help# 根据官网使用教程可以有以下常用方式
whisper music.mp3 --model tiny --language Chinese --device cuda:0 --initial_prompt "以下是普通话的句子"
Python代码
import whisper
model = whisper.load_model("base", "cpu")
mps_path = r"music.mp3"
result = model.transcribe(mps_path, fp16=False, language='Chinese')
print(result["text"])
说明:如果你的机器有GPU,那这里的**“fp16=False”**不是必须的。因为笔者本地测试机器没有GPU,只用用CPU进行测试,所以这里我设置了这个参数。
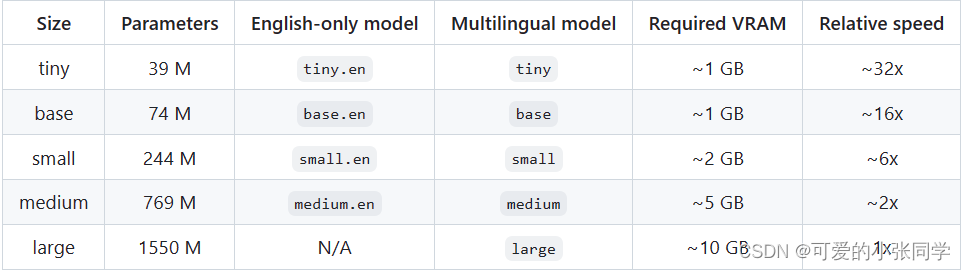
whisper模型
报错信息
以下是笔者调试过程中遇到的错误记录:
Error 1
FileNotFoundError: [WinError 2] 系统找不到指定的文件。
解决办法:
找到External Libraries —> Python 3.8 —> Libs —> subprocess.py —> Ctrl+F 查找“class POpen” ,将shell=False,改为 shell=True。
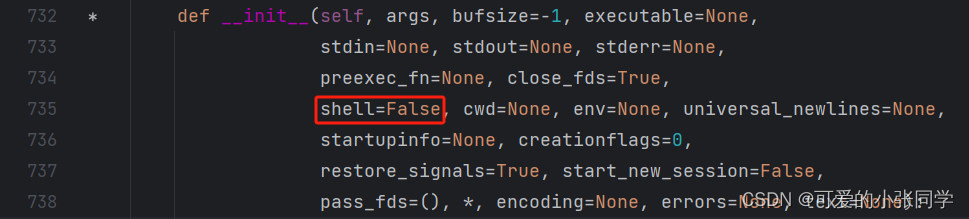
参考链接:https://blog.csdn.net/qq_24118527/article/details/90579328
Error 2
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xb2 in position 9: invalid start byte
解决办法:
这个问题表面上就是ffmpeg造成的,好像在读取文件的时候某个位置的编码有问题。实际上是由于上面的代码修改后,需要重新启动(在windows系统有这个问题)。
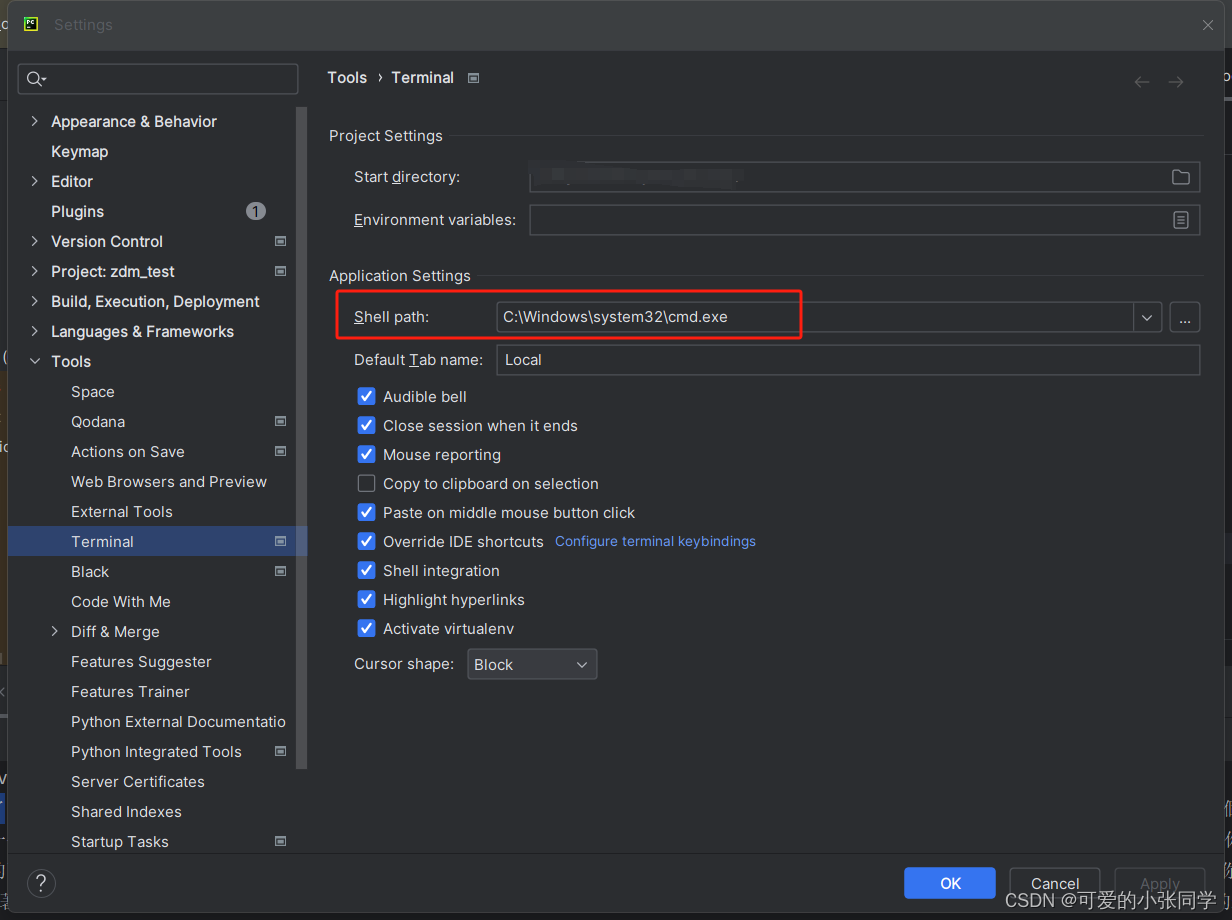
如果重新启动之后,还是出现上述错误,可以按照如下方式重新设置:Pycharm setting —> Tools —> Terminal —> 找到 shell path,将其修改为本地cmd。