文章目录
- (129)FIFO调度器
- (130)容量调度器
- 特点
- 资源分配算法
- (131)公平调度器
- 特点
- 缺额的定义
- 队列资源分配方式
- 基于FIFO策略
- 基于Fair策略
- 资源分配算法
- DRF策略
- 参考文献
(129)FIFO调度器
教程使用的是Hadoop3.1.3版本,截止这个版本,Hadoop里的作业调度器主要有三种:FIFO(先进先出)、容量(Capacity Scheduler)和公平(Fair Scheduler)。其中3.1.3版本的默认调度器是容量调度器。
CDH框架默认的调度器是公平调度器。
具体设置可见:yarn-default.xml文件
<property><description>The class to use as the resource scheduler.</description><name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property>
FIFO调度器,即First in first out,是很常见的数据结构了,单队列,先进的任务先出,跟现实中的排队一样。
就不详细介绍了。贴一个教程里的图吧。
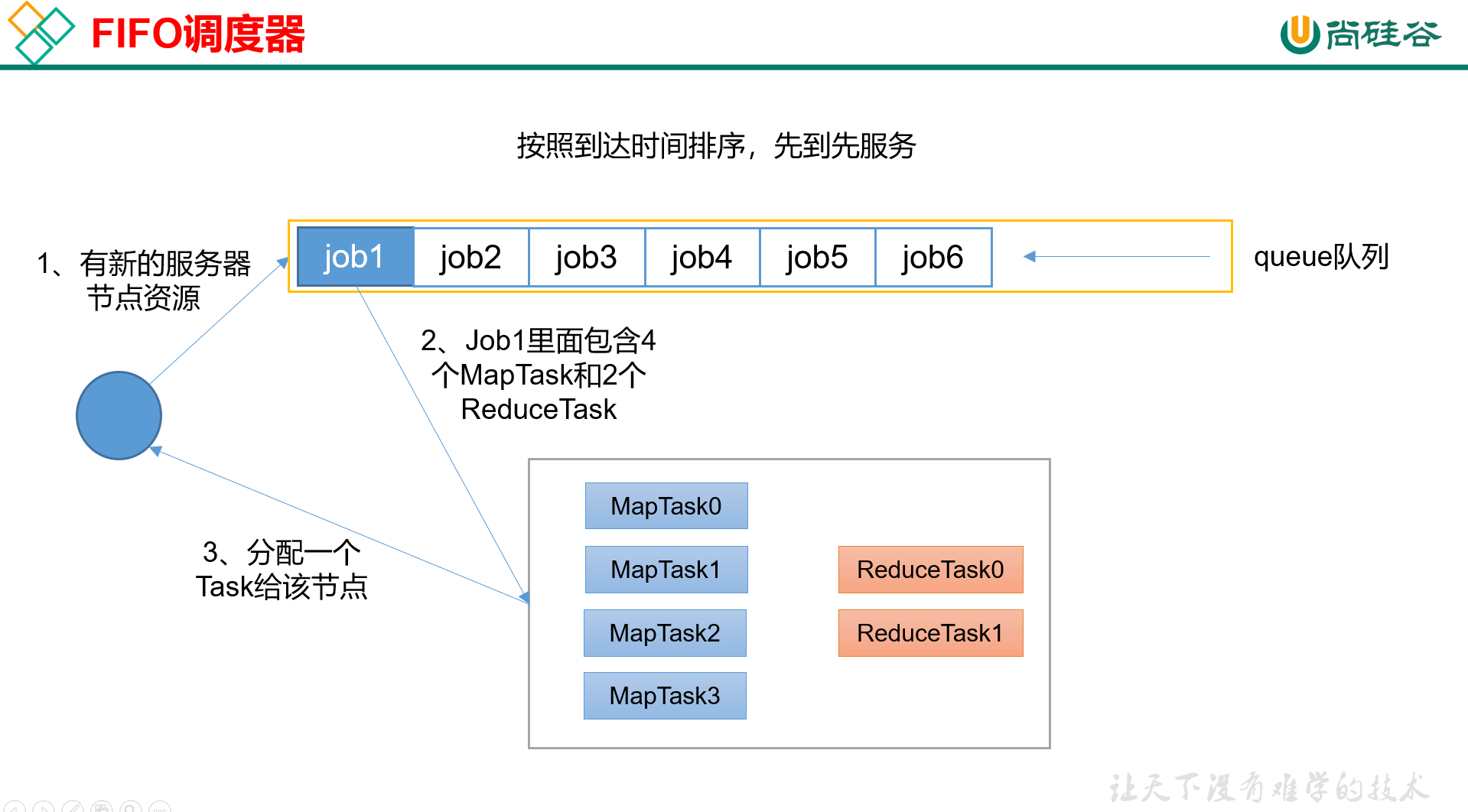
生产环境下基本不用FIFO调度器,因为它是单队列的,无法把集群资源应用到极致。它唯一的好处可能就是原理比较好懂。
(130)容量调度器
容量调度器,即Capacity Scheduler,是Yahoo开发的多用户调度器,也是Hadoop的默认调度器。
所谓的多用户调度,是指多个用户可以同时提交任务,多用户、多应用程序共享集群。
特点
容量调度器,有这么几个特点:
1) 多队列。容量调度器,更像是对FIFO调度器的扩充,相比FIFO只有一个队列,容量调度器同时存在多个队列,每个队列配置固定的资源量,而队列内部默认采用FIFO策略,注意,是FIFO策略,每个队列里,先进的任务先出。
2) 容量保证。管理员可以为每个队列设置资源最低容量和资源使用上限,资源最低容量是一个保证值,队列实际分配到的容量,不应该低于这个保证值。
3) 灵活性。如果一个队列中的资源当前有剩余,可以暂时共享给那些需要资源的队列。但是如果有新的应用提交到前者,即前者需要资源的时候,其他队列借调的资源应该马上归还给前者。(其他队列一般不会马上停掉自己的任务来释放资源,可能会等待运行完成后释放,或者是马上释放部分资源)
4) 支持多租户:
- 支持多用户共享集群,以及多应用程序同时运行。
- 为了防止同一个用户的作业独占全部资源,容量调度器也会对同一用户所提交作业所占的资源总量进行限制。比如说限定用户A,同一时间最多占用5G资源。
资源分配算法
那在实际的生产运行中,容量调度器会怎么给各个队列、job和容器分配资源的呢?
接下来简单介绍一下容量调度器的资源分配算法:
-
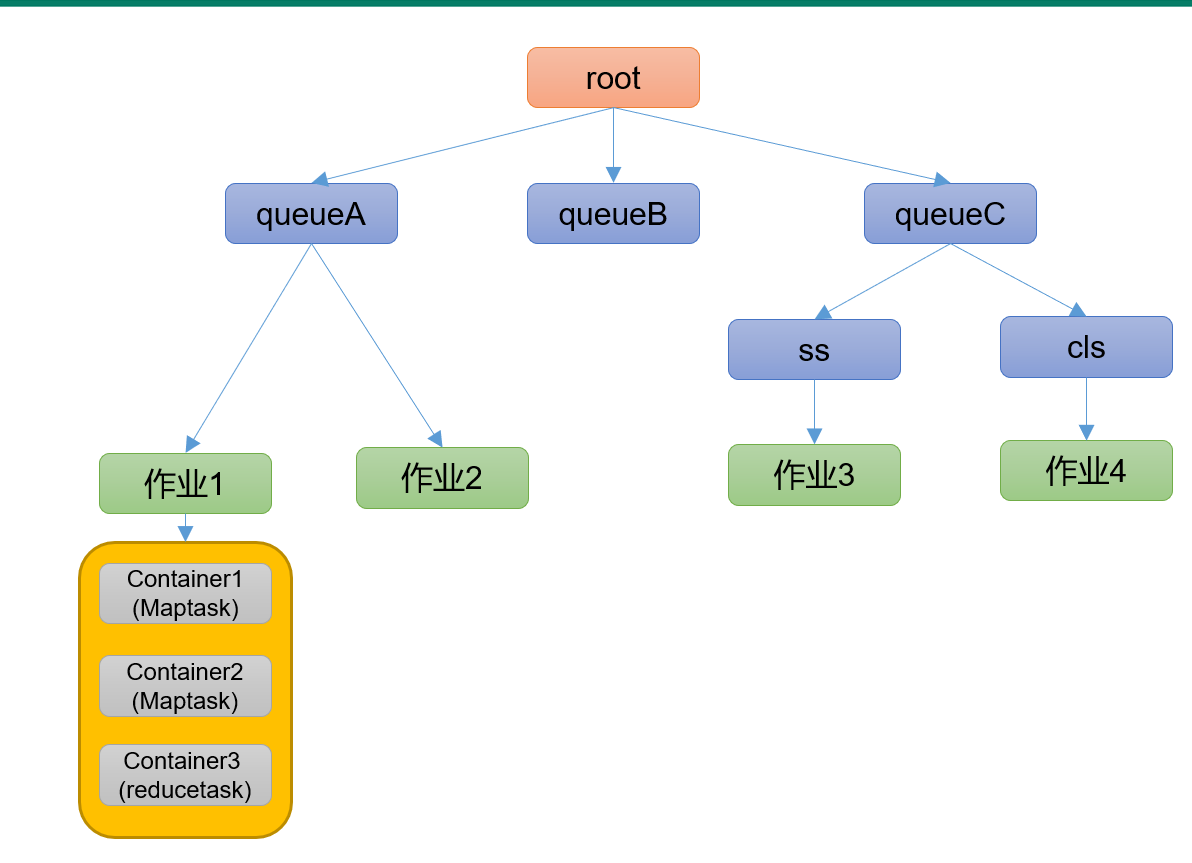
队列资源分配:从root开始,使用深度优先遍历算法,优先选择资源占用率低的队列,分配资源。(这样做的目的其实是尽量让占用资源少的任务尽快结束,这样就可以释放出更多的资源,来支持其他队列)
-
作业资源分配:默认按照作业的优先级和提交时间,顺序分配资源。假设作业A先提交,作业B后提交,但是作业B的优先级更高,一般来讲,先提交的作业A会优先得到一部分资源(如果当时没有其他作业在等待资源的话)。所以优先级高的作业B在后提交之后,顶多多获得一部分资源作为补偿。
-
容器资源分配(一个作业内部会有多个容器):
-
按照容器的优先级分配资源;
-
如果优先级相同,会按照数据本地性原则,即类似之前介绍过的机架感知距离,优先级从高到低依次是:
- 容器和数据在同一节点上;
- 容器和数据在同一机架;
- 容器和数据不在同一节点,也不在同一机架上;
按照数据本地性来排优先级的主要目的,还是为了让本来就可以最快结束的任务更快结束,从而加快释放出资源。比如说容器和数据在同一节点时,网络IO等的消耗是最小的,所以在相同资源供给的情况下,它结束的速度肯定更快。
-
以上过程可以参考下图辅助理解:
(131)公平调度器
公平调度器,即Fair Scheduler,是Facebook开发的多用户调度器,同时也是CDH框架默认的调度器。
特点
公平调度器也是同时存在多个队列,但不同于容量调度器,公平调度器的每个队列内部,所有任务平分共享资源,主打的就是一个公平。
与容量调度器相比,共同点:
- 多队列;
- 管理员同样可以为每个队列设置资源最低保证和资源使用上限;
- 灵活性:队列空闲资源可以分配给其他队列;
- 多租户:支持多租户共享集群和多应用程序同时运行。可以限制每个用户同一时间提交作业的资源总量;
区别是:
- 核心调度策略不同:容量调度器在分配资源的时候,优先考虑资源占用率低的队列。公平调度器则优先考虑对资源的缺额比例较大的队列。
- 公平调度器里,每个队列可以单独设置资源分配方式:
- 容量调度器可选的分配方式是FIFO、DRF;
- 公平调度器是FIFO、FAIR、DRF;
缺额的定义
在公平调度器里,什么是缺额?
如图:
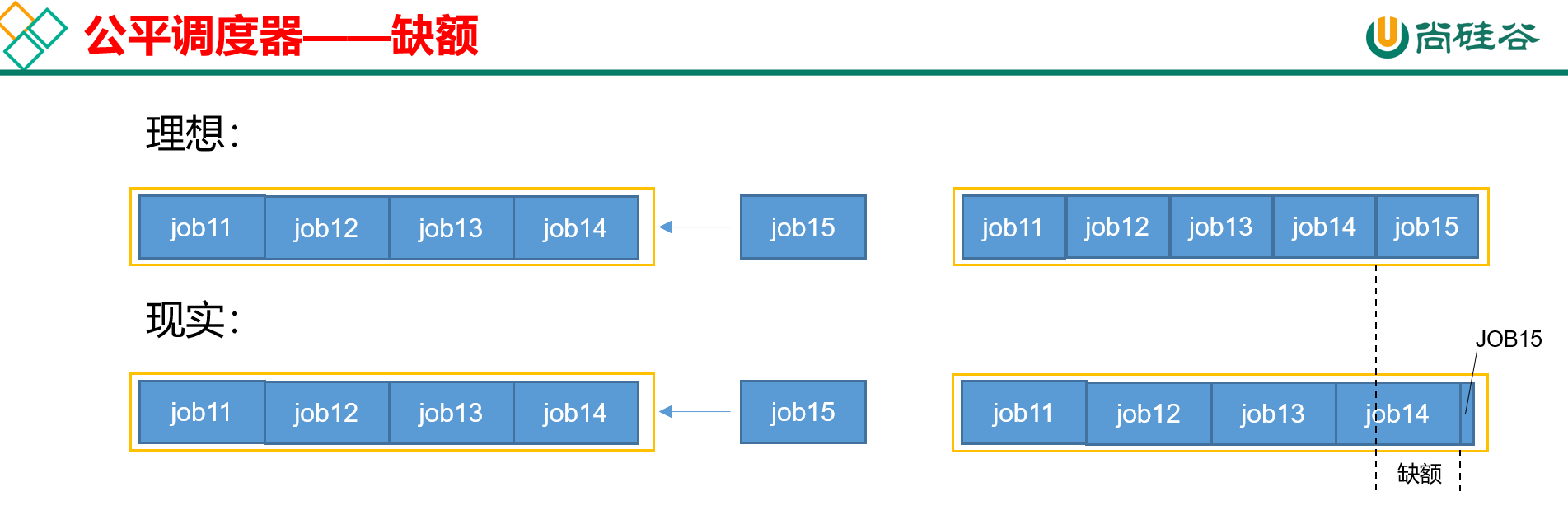
假设当前队列里同时在运行4个任务,第5个任务进来的时候,公平起见,已运行的这4个任务得赶紧空点资源出来给job_5,但是现实里这不是说空就能空出来的,所以在这段时间里,该队列就属于有缺额的队列,其中缺额的作业就是job_5。
教程里是这么描述的:某一时刻一个作业应获取的资源和实际获取的资源的差距,就叫缺额。
调度器会优先为缺额更大的队列,或者说作业,分配资源。
队列资源分配方式
基于FIFO策略
那么公平调度器就会蜕变成容量调度器。
基于Fair策略
这是公平调度器的默认策略,它是一种基于最大最小公平算法实现的资源多路复用方式。
默认情况下,每个队列内部都采用这种策略来分配资源。比如说,如果一个队列有2个作业在同时运行,那么每个作业可以得到这个队列1/2的资源。如果是3个作业在同时运行,则每个作业理论上可以得到整个队列1/3的资源。
具体的资源分配流程和容量调度器一致:先队列,然后作业,最后容器。每一步都是按照公平策略分配资源。
介绍一些概念:
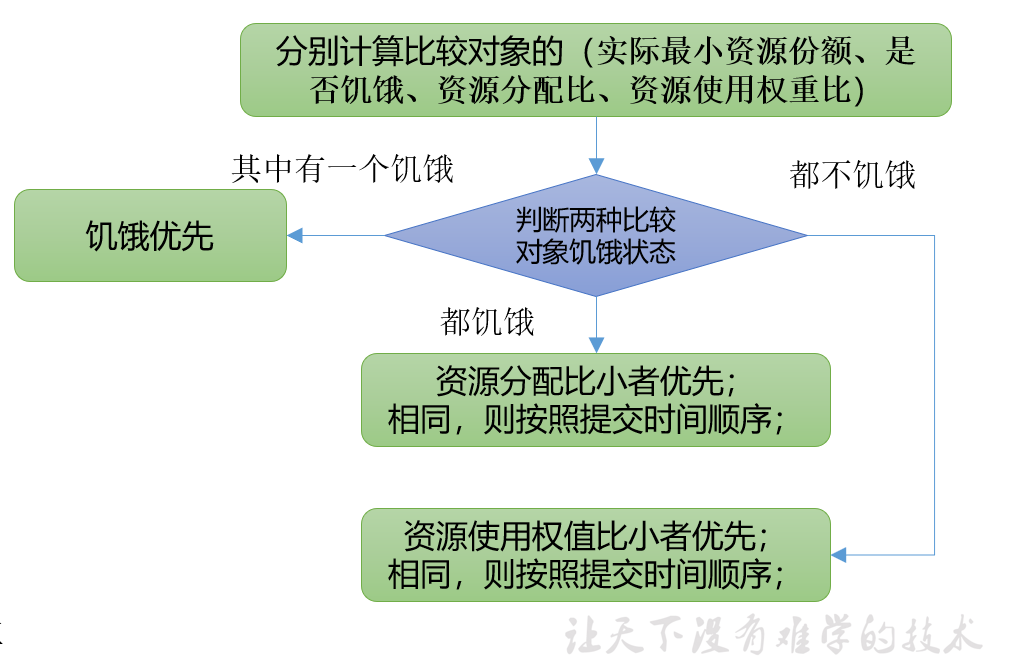
实际最小资源份额:mindshare = Min(当前作业的资源需求量,配置的最小资源)
是否饥饿:isNeedy = 资源使用量 < mindshare(实际最小资源份额)
资源分配比:minShareRatio = 资源使用量 / Max(mindshare, 1)
假设一个作业,资源当前使用量是1,资源需求量是3,配置的最小资源是2,那么它就属于饥饿作业,资源分配比是50%,如果没有分配比比它还低的作业,那么之后分配的时候会优先将资源分配给它。所以这个"资源分配比"是分配时很重要的一个指标。
资源使用权重比:useToWeightRatio = 资源使用量 / 权重
如图,总结一下:
-
如果只有一个作业饥饿,那就直接把资源分配给它就可以;
-
如果都饥饿的话,资源分配比小的作业优先获得资源;
-
如果好几个作业都饥饿,且资源分配比一样呢?这时候会按照提交时间顺序分配资源;
-
如果大家都不饥饿,则会按照资源使用权重比,小的优先,如果相同,再按照提交时间顺序分配。
资源分配算法
1) 队列资源分配:
一般会进行两轮分配。
第一轮分配是公平分配,假设总资源量是100,共3个队列,那第一轮会给每个队列分配33.33;
第二轮是队列间资源调度,因为每个队列对资源的需求量是不一样的,比如说A需要20,B需要50,C需要30,那么明显AC资源有空余,而B有缺额,那么会从AC拿出空余资源,优先补给B。

2) 作业资源分配:
不加权的情况下,重点关注job的个数:
假设当前队列有12个单位的资源,4个job,且job_1需求资源为1,job_2是2,job_3是6,job_4是5。
摆明了无法全部满足需要。
那么公平调度器会怎么分配资源呢?
第一轮,12/4=3,所以给每个job分配3单位资源,于是:
- job_1多给了2单位,
- job_2多给了1单位,
- job_3少3个单位,
- job_4少2个单位;
第二轮,把多余的资源收集起来,2+1=3单位,继续公平分配,3/2=1.5。于是:
- 再给job_3分配1.5单位,
- 给job_4再分配1.5;
如此循环往复,直到没有空闲资源。
如果是在加权情况下,则重点关注job的权重:
假设该队列总资源是16,有4个job,每个job的资源需求和权重如下:
| job_1 | job_2 | job_3 | job_4 | |
|---|---|---|---|---|
| 需求 | 4 | 2 | 10 | 4 |
| 权重 | 5 | 8 | 1 | 2 |
这个例子举的很有意思,就是需求大的权重小,需求小的权重大。
第一轮:
16/(5+8+1+2)=1
job_1,分配5*1=5,多1;
job_2,分配8*1=8,多6;
job_3,分配1*1=1,少9;
job_4,分配2*1=2,少2;
第二轮:
把多余的资源汇总起来,即1+6=7,开始为job_3和job_4分配资源;
然后7/(1+2)=2.33
job_3,继续分配1*2.33=2.33,还少9-2.33=6.67;
job_4,继续分配2*2.33=4.66,多了2.66;
第三轮:
空闲的资源是2.66,就按上面流程给job_3分配了。
如此循环往复,直到没有空闲资源。
这就是加权下的公平。
DRF策略
DRF,即Dominant Resource Fairness。
我们之前所说的资源,实际上就是指内存。但其实现实中,我们需要的资源有很多种,例如内存、CPU、网络带宽等,在多种资源的前提下,我们该如何衡量不同任务间应该分配的资源比例?
假设集群一共有100个CPU和10T内存,应用A需要(2CPU,300GB),应用B需要(6CPU,100GB),那么换算下比例,应用A需要(2%CPU,3%内存),应用B需要(6%CPU,1%内存),那我们就可以说应用A是内存导向的,应用B是CPU导向的。然后具体考虑的时候就可以考虑重点倾向的资源。
大概吧,教程没有详细再说。等有时间我再查查。
参考文献
- 【尚硅谷大数据Hadoop教程,hadoop3.x搭建到集群调优,百万播放】
![WGCNA分析教程五 | [更新版]](https://img-blog.csdnimg.cn/img_convert/6b3ed167c11bfa4e4ccedc5e49452045.png)