Mysql实战-SQL语句优化
前面我们讲解了索引的存储结构,B+Tree的索引结构,以及索引最左侧匹配原则,Explain的用法,可以看到是否使用了索引,今天我们讲解一下SQL语句的优化及如何优化
文章目录
- Mysql实战-SQL语句优化
- 1.表结构
- 2 where语句及order的列 建立索引
- 3. where语句不要使用!=,<>
- 4.where语句不要or进行判断
- 5.where语句不要使用 like模糊查询
- 6.where语句 不要 in 和not in, 可能也会导致全表扫描
- 7.where语句不要使用表达式计算及函数运算
1.表结构
新建表结构 user, user_info
#新建表结构 user
CREATE TABLE `user` (`id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键',`id_card` char(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '身份证ID',`user_name` char(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '用户名字',`age` int NOT NULL COMMENT '年龄',PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='用户表'
- id 主键id列
- id_card 身份证id
- user_name 用户姓名
- age 年龄
先插入测试数据, 插入 5条测试数据
INSERT INTO `test`.`user` (`id`, `id_card`, `user_name`, `age`) VALUES (1, '11', 'aa', 10);
INSERT INTO `test`.`user` (`id`, `id_card`, `user_name`, `age`) VALUES (2, '22', 'bb', 20);
INSERT INTO `test`.`user` (`id`, `id_card`, `user_name`, `age`) VALUES (3, '33', 'cc', 30);
INSERT INTO `test`.`user` (`id`, `id_card`, `user_name`, `age`) VALUES (4, '44', 'dd', 40);
INSERT INTO `test`.`user` (`id`, `id_card`, `user_name`, `age`) VALUES (5, '55', 'ee', 50);
2 where语句及order的列 建立索引
表结构先不创建索引,我们看下执行分析
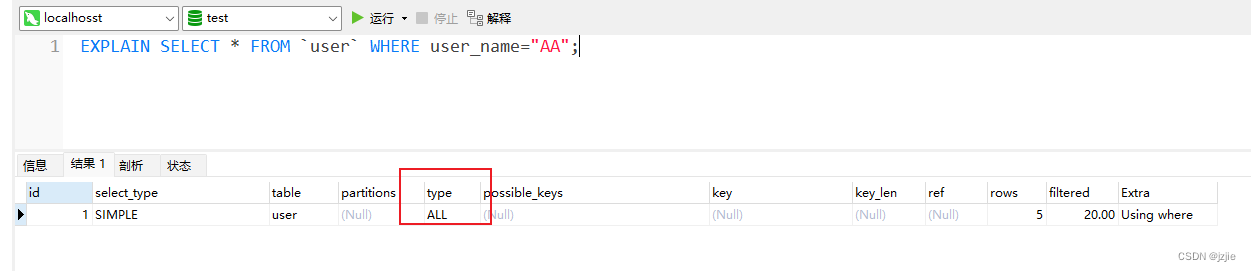
EXPLAIN SELECT * FROM user WHERE user_name=“AA”;
EXPLAIN SELECT * FROM `user` WHERE user_name="AA";
执行成功, type=ALL表示没有索引,查询效率低下
我们在 user_name上建立索引后,再看下
#创建索引
alter table `user` add index `idx_name`(`user_name`);#执行分析
EXPLAIN SELECT * FROM `user` WHERE user_name="AA";
使用了索引,查询效率提升

3. where语句不要使用!=,<>
where语句中使用!= 或者 <>, 或者使用 between and 都会是引擎放弃索引,进行全表扫描
我们新建 age的索引,然后基于age去做查询分析
#创建age索引
alter table `user` add index `idx_age`(`age`);
#执行分析
EXPLAIN SELECT * FROM `user` WHERE age=10;
使用age索引进行查询,没有问题

现在我们使用 != 或者 <> 来进行查询,执行查询分析
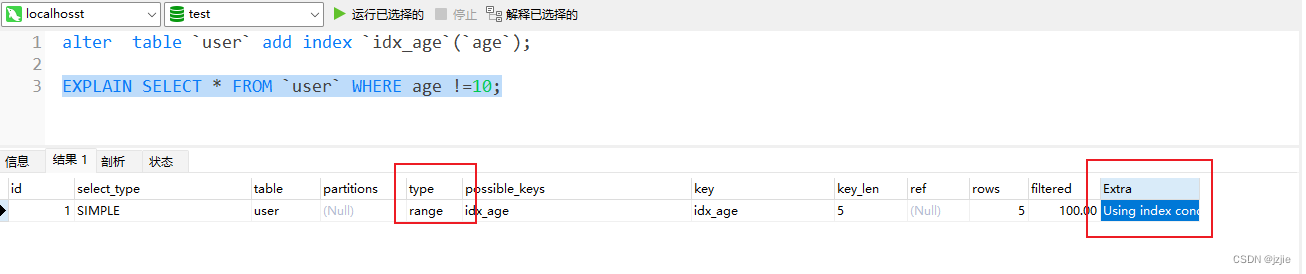
EXPLAIN SELECT * FROM `user` WHERE age !=10;
EXPLAIN SELECT * FROM `user` WHERE age <>10;
EXPLAIN SELECT * FROM `user` WHERE age BETWEEN 10 and 20;
EXPLAIN SELECT * FROM `user` WHERE age > 10 and age < 20 ;
执行结果全都是 type=range 表示在索引范围内查找,对索引的扫描开始于某一点,返回匹配值域的行, 已经不是ref类型了,效率已经不高了
Extra 其他信息= using index condition 表示会先条件过滤索引,过滤完索引后找到所有符合索引条件的数据行,随后用 WHERE 子句中的其他条件去过滤这些数据行;
using index condition = using index + 回表 + where 过滤
4.where语句不要or进行判断
where语句使用or判断,也会导致引擎放弃索引,进而进行全表扫描
使用 or, 也会造成 type=range的情况
EXPLAIN SELECT * FROM `user` WHERE age =10 or age =20;
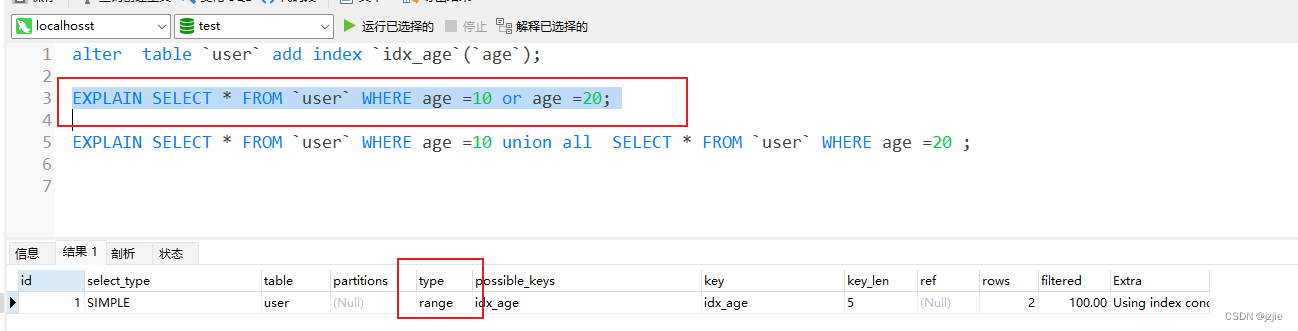
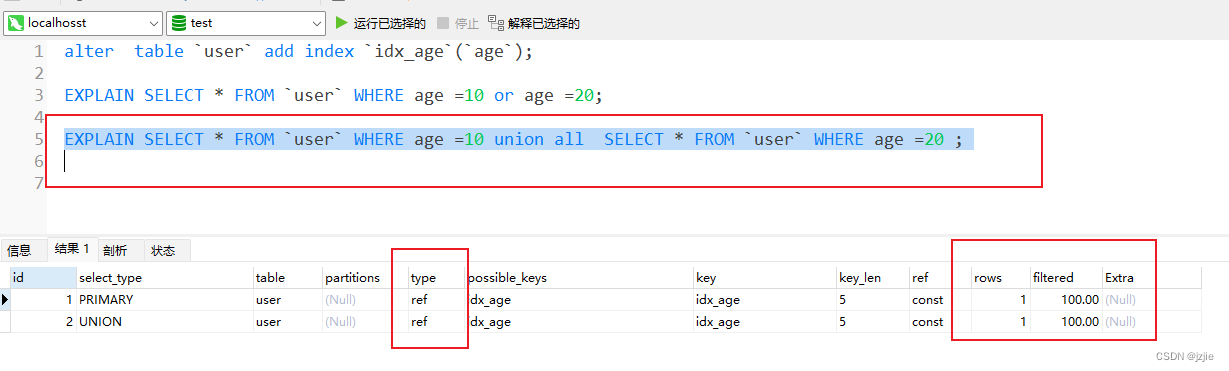
这种情况,我们可以采用 union all 来进行优化
EXPLAIN SELECT * FROM `user` WHERE age =10 union all SELECT * FROM `user` WHERE age =20 ;
5.where语句不要使用 like模糊查询
like模糊查询,也会导致 全表扫描
#1.左侧开头精确匹配,右侧结果模糊
EXPLAIN SELECT * FROM `user` WHERE user_name like "a%";
#2.左侧开头模糊,右侧结果精确匹配
EXPLAIN SELECT * FROM `user` WHERE user_name like "%a";
#3.左侧开头模糊,右侧结果模糊
EXPLAIN SELECT * FROM `user` WHERE user_name like "%a%";
上面3种情况,我们来逐一分析
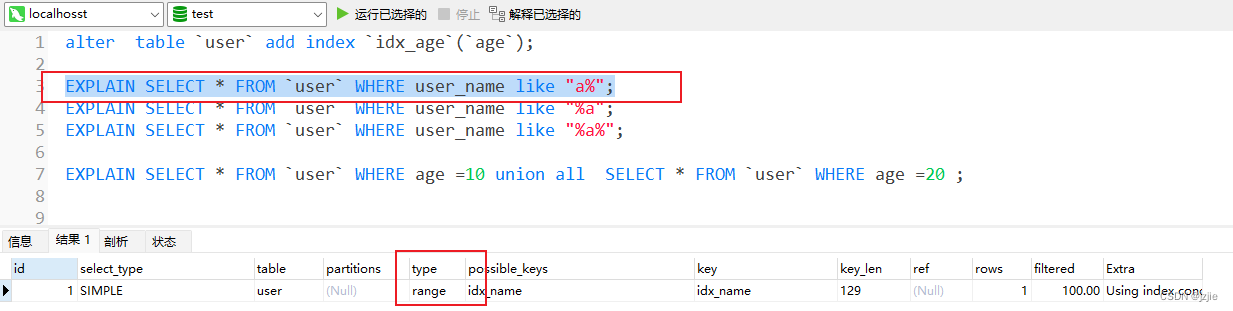
- 左侧开头精确匹配,右侧结果模糊, 查询会使用左侧索引进行匹配,type=range
EXPLAIN SELECT * FROM `user` WHERE user_name like "a%";
2. 左侧开头模糊,右侧结果精确匹配, 查询不会使用索引,全表扫描 type=ALL
EXPLAIN SELECT * FROM `user` WHERE user_name like "%a";
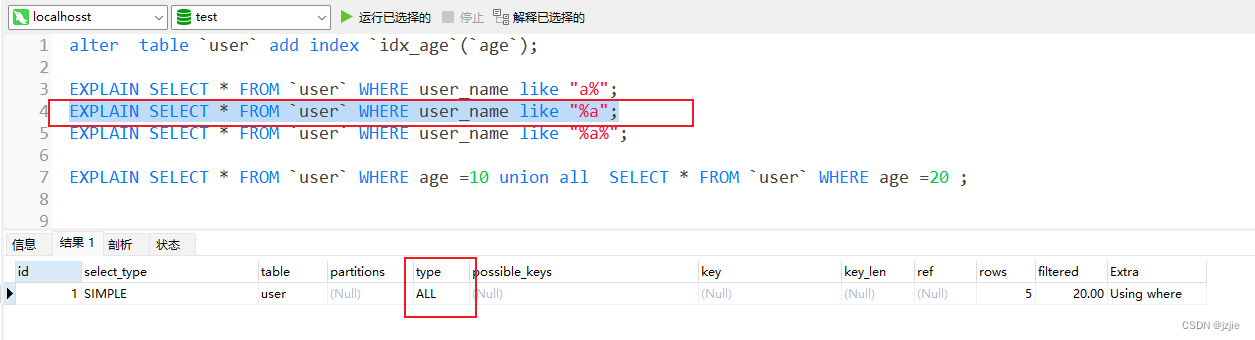
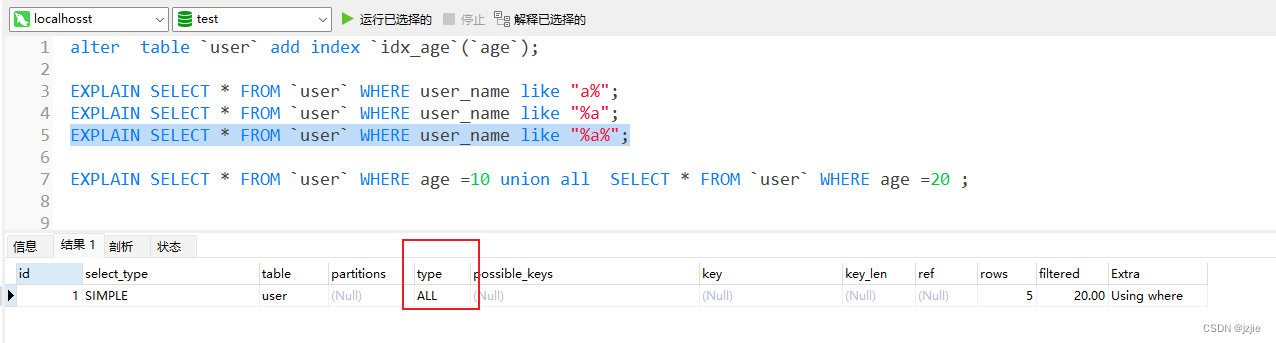
3. 左侧开头模糊,右侧结果模糊, 查询不会使用索引,全表扫描 type=ALL
EXPLAIN SELECT * FROM `user` WHERE user_name like "%a%";
6.where语句 不要 in 和not in, 可能也会导致全表扫描
where子语句,使用 in,not in 也有可能导致全表扫描
所以使用in 到底走不走索引呢?
- in通常是走索引的
- IN 的条件过多,会导致索引失效,走索引扫描
- 当in后面的数据在数据表中超过一定的数量 (有人说是30%,假如上面的例子的全部数据大约100条,匹配数据超过30条 ),会走全表扫描,即不走索引
- in走不走索引和后面的数据有关系,这个比例不准
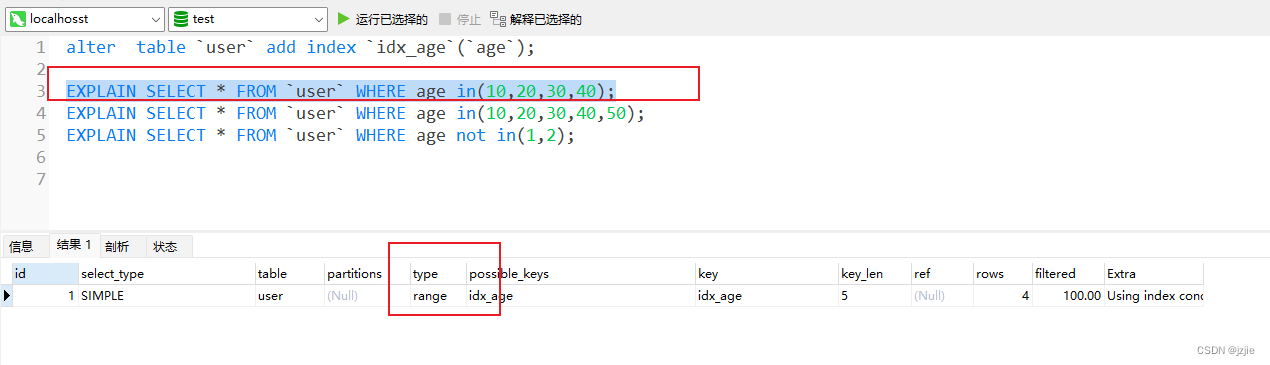
我表中5条数据, 我现在 in(10,20,30,40), in了4条,但是依旧走了索引 type=range, key=idx_age
EXPLAIN SELECT * FROM `user` WHERE age in(10,20,30,40);
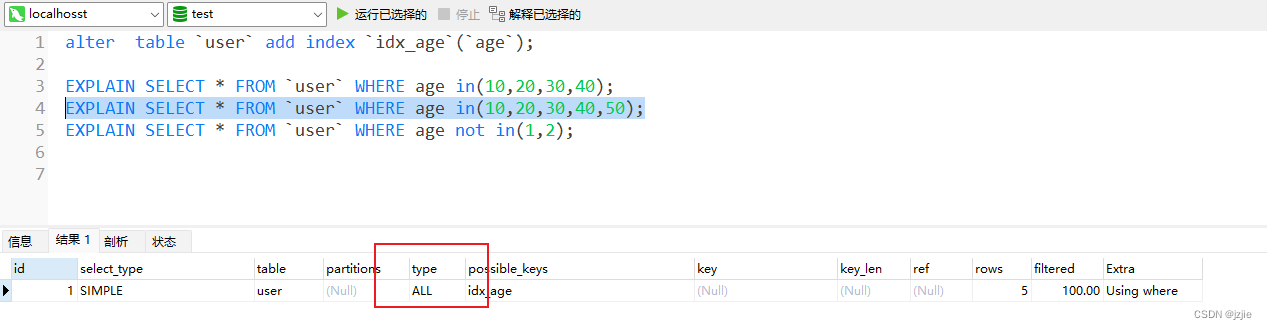
我现在再加一个in条件 in(10,20,30,40,50), 此刻就没有走索引, type=ALL
EXPLAIN SELECT * FROM `user` WHERE age in(10,20,30,40,50);
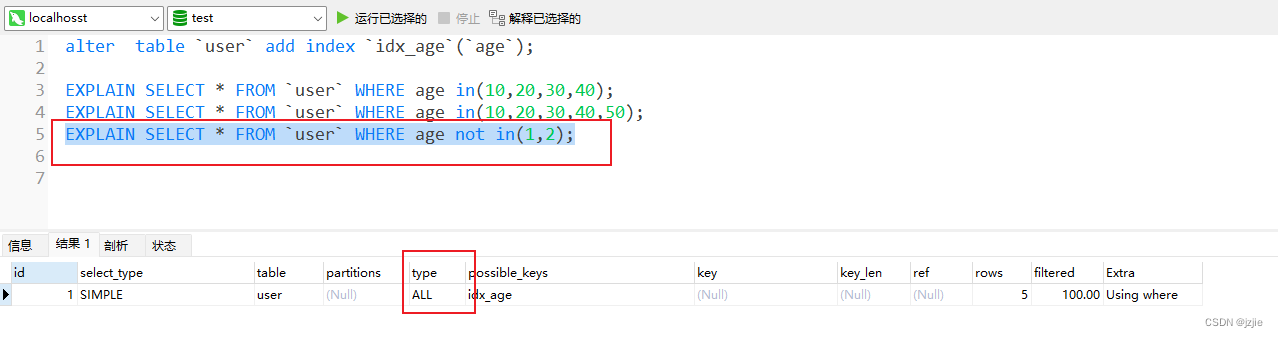
但是 not in 是肯定不走索引的,这是我们明确禁止的
EXPLAIN SELECT * FROM `user` WHERE age not in(1,2);
7.where语句不要使用表达式计算及函数运算
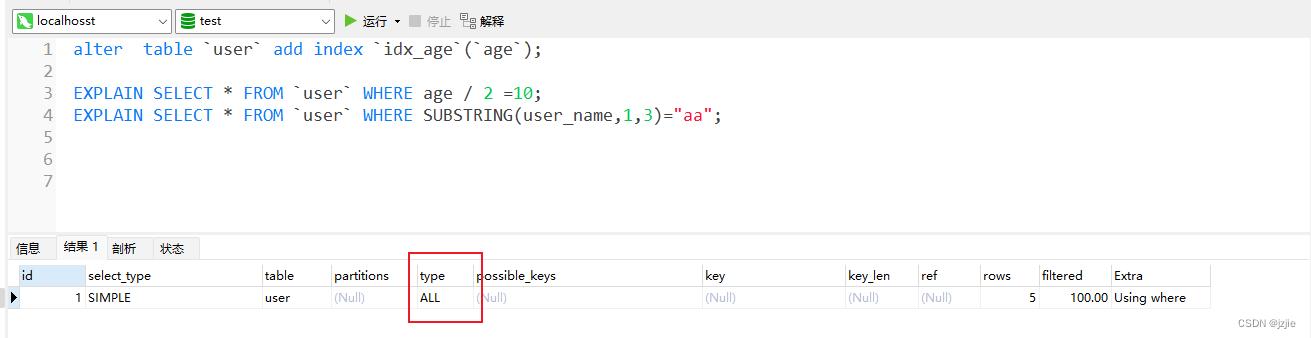
where子句,不要使用表达式计算或者函数运算,这回导致全表扫描
EXPLAIN SELECT * FROM `user` WHERE age / 2 =10;
EXPLAIN SELECT * FROM `user` WHERE SUBSTRING(user_name,1,3)="aa";
执行结果全部都是 type=ALL,使用表达式计算和函数的 都不会使用索引
至此,我们了解如何去优化查询语句,在平时项目中,也应该多注意这些用法,防止出现线上事故