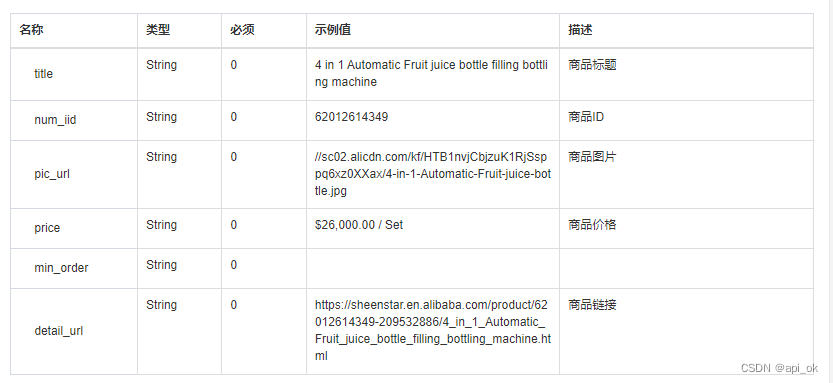
6.0 概述
本章介绍的性能工具能帮助你评估磁盘I/O子系统的使用情况。这些工具可以展示哪些磁盘或分区已被使用,每个磁盘处理了多少I/O,发给这些磁盘的I/O请求要等多久才被处理。
阅读本章后,你将能够:
- 确定系统内磁盘I/O的总量和类型(读/写)(vmstat)。
- 确定哪些设备服务了大部分的磁盘I/O(vmstat,iostat,sar)。口确定特定磁盘处理I/O请求的有效性(iostat)。
- 确定哪些进程正在使用一组给定的文件(lsof)。
6.1磁盘I/O介绍
在深入性能工具之前,有必要了解Linux磁盘I/O系统是怎样构成的。大多数现代Linux系统都有一个或多个磁盘驱动。如果它们是IDE驱动,那么常常将被命名为hda、hdb、hdc等;而SCSI驱动则常常被命名为sda、sdb、sdc等。磁盘通常要分为多个分区,分区设备名称的创建方法是在基础驱动名称的后面直接添加分区编号。比如,系统中首个IDE硬驱动的第二个分区通常被标记为/dev/hda2。一般每个独立分区要么包含一个文件系统,要么包含一个交换分区。这些分区被挂载到Linux根文件系统,该系统由/etc/fstab指定。这些被挂载的文件系统包含了应用程序要读写的文件。
当一个应用程序进行读写时,Linux内核可以在其高速缓存或缓冲区中保存文件的副本,并且可以在不访问磁盘的情况下返回被请求的信息。但是,如果Linux内核没有在内存中保存数据副本,那它就向磁盘I/O队列添加一个请求。若Linux内核注意到多个请求都指向磁盘内相邻的区域,它会把它们合并为一个大的请求。这种合并能消除第二次请求的寻道时间,以此来提高磁盘整体性能。当请求被放入磁盘队列,而磁盘当前不忙时,它就开始为I/O 请求服务。如果磁盘正忙,则请求就在队列中等待,直到该设备可用,请求将被服务。
6.2 磁盘I/O性能工具
本节讨论各种各样的磁盘I/O性能工具,它们能使你调查一个给定应用程序是如何使用磁盘I/O子系统的,包括每个磁盘被使用的程度,内核的磁盘高速缓存的工作情况,以及特定应用程序“打开”了哪些文件。
6.2.1vmstat(IⅢI)
如同你在第2章中了解到的,vmstat是一个强大的工具,它能给出系统在性能方面的总览图。除了CPU和内存统计信息之外,vmstat还可以提供系统整体上的I/O性能情况。
6.2.1.1磁盘I/O性能相关的选项和输出
在使用vmstat从系统获取磁盘I/O统计信息时,要按照如下方式进行调用:
vmstat [-D] [-d] [-p partition] [interval [count]]
表6-1说明的命令行选项能影响vmstat显示的磁盘I/O统计信息。

如果你在运行vmstat时只使用了[interval]和[count]参数,其他参数没有使用,那么显示的就是默认输出。该输出中包含了三列与磁盘I/O性能相关的内容:bo,bi和wa。这些统计信息的说明如表6-2所示。
在用-D模式运行时,vmstat提供的是系统内磁盘I/O系统的总体统计数据。表6-3给出了这些统计信息。(注意:关于这些统计数据的更多信息参见Documentation/iostats.txt下的Linux内核源代码包)。


vmstat的-d选项显示的是每一个磁盘的I/O统计信息。这些统计数据与-D选项的数据类似,表6-4对它们进行了解释。

最后,如果被要求提供特定分区的统计信息,那么vmstat就会显示如表6-5所示的数据项。

vmstat的默认输出提供了关于系统磁盘I/O的一个粗略但良好的指示。vmstat提供的选项则使你能了解更多细节,以发现哪些设备要对I/O负责。vmstat超过其他I/O工具的主要优势是:几乎所有的Linux发行版本都包含该工具。
6.2.1.2用法示例
随着vmstat版本的升级,它能呈现给Linux用户的I/O统计信息数量也不断增加。本节给出的示例针对3.2.0或更高版本的vmstat。此外,vmstat提供的扩展磁盘统计信息只用于内核版本高于2.5.70的Linux系统。
在清单6.1显示的例子中,我们调用的vmstat只取3个样本,时间间隔为1秒。vmstat 输出整个系统的性能概况,如我们在第2章所见一样。
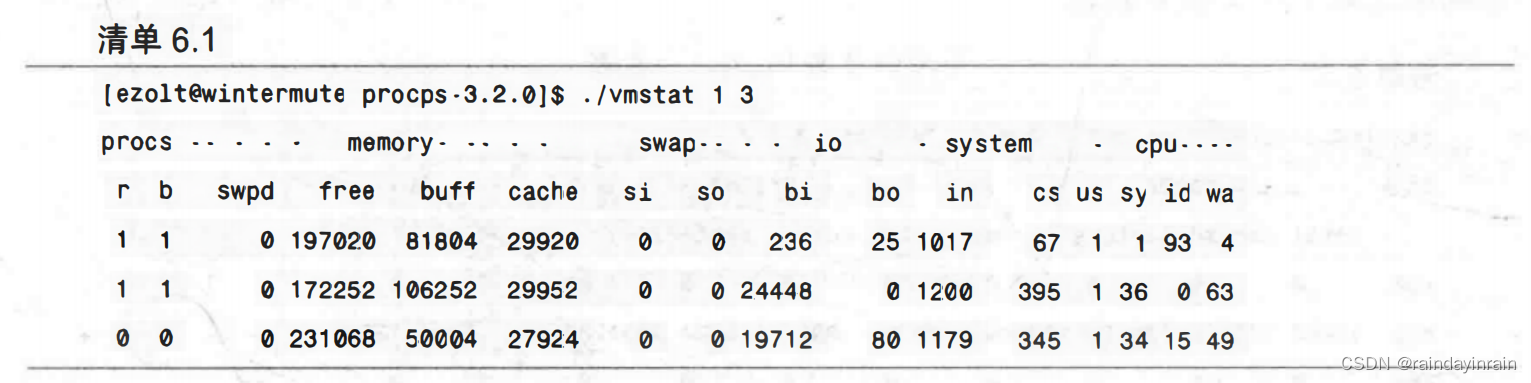
清单6.1显示,在一次采样期间,系统读取了24448个磁盘块。如前所述,磁盘块大小为1024字节,这就意味着系统读取数据的速率约为每秒23MB。我们还可以看到,在这个采样过程中,CPU花费了相当多的时间来等待I/O完成,它有63%的时间用于I/O,而磁盘读取速率约为每秒23MB。在下一个采样中,它有49%的时间用于I/O,而磁盘读取速率约为每秒19MB。
接下来,在清单6.2中,我们要求vmstat提供自系统启动以来I/O子系统的性能信息。


在清单6.2中,vmstat提供了系统内所有磁盘驱动器的I/O统计汇总信息。如前所述,在读写磁盘时,为了提高性能,Linux内核试图合并对磁盘相邻区域的请求。vmstat在报告这些事件时,将它们称为merged reads(合并读)和mergedwrites(合并写)。本例中,大量发给系统的读请求在提交给设备之前被合并了。虽然合并读有约640000个,但真正向设备提交的读命令却只有约53000个。输出还告诉我们从磁盘中总共读出了4787741个扇区,并且自系统启动开始,从磁盘读取共花费了343552毫秒(或344秒)。写性能也可以得到同样的统计信息。这些I/O统计信息能让我们很好地了解整个I/O子系统的性能。
上面的例子显示的是整个系统的I/O统计数据,而下面清单6.3中的例子显示的统计信息则细化到了每个独立磁盘。
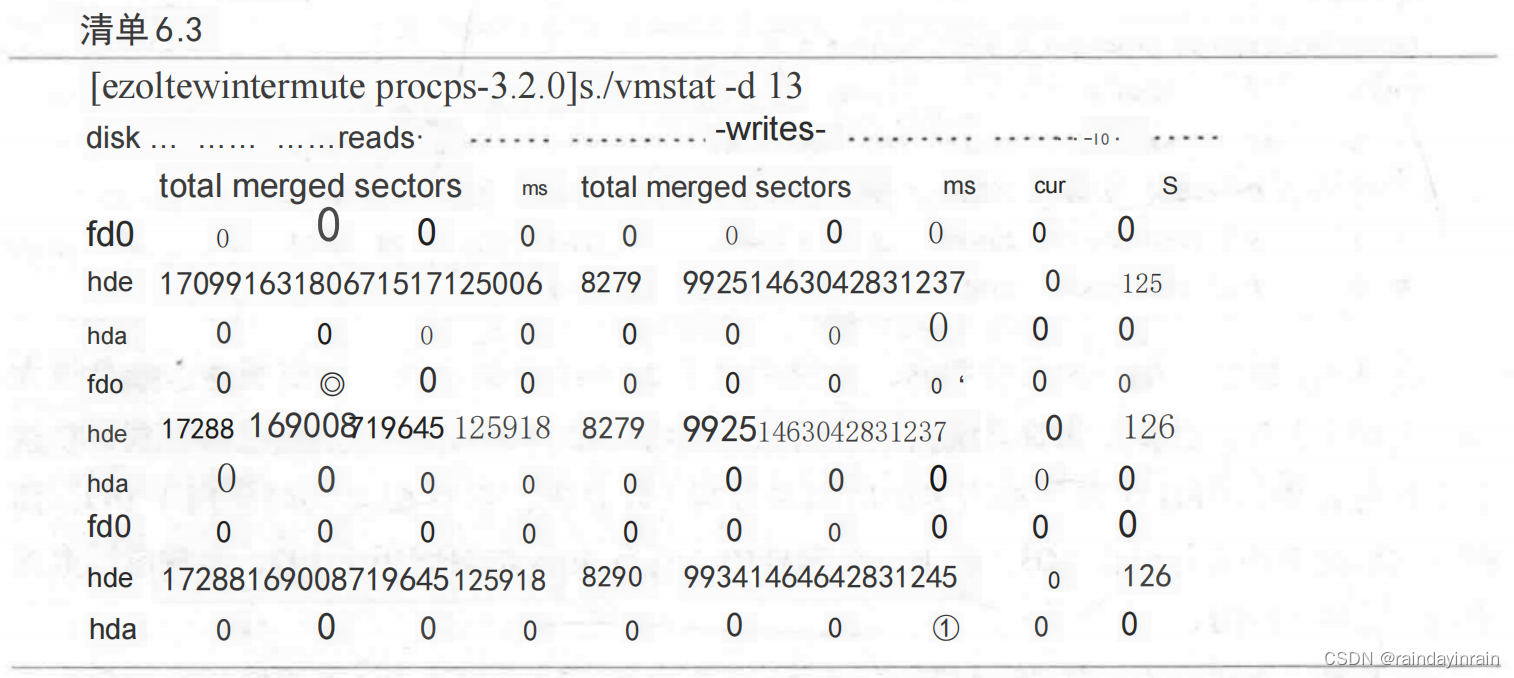
清单6.4显示出有60(19059-18999)个读和94(24795-24701)个写提交给了分区hde3。当你试图确定哪个磁盘分区最常被使用时,这个统计就显得特别有用。

虽然vmstat提供了单个磁盘/分区的统计信息,但是它只给出其总量,却不给出在采样过程中的变化率。因此,要分辨哪个设备的统计数据在采样期间发生了明显的变化就显得很困难。
6.2.2 iostat
iostat与vmstat相似,但它是一个专门用于显示磁盘I/O子系统统计信息的工具。iostat 提供的信息细化到每个设备和每个分区从特定磁盘读写了多少个块。(iostat中块大小一般为512字节。)此外,iostat还可以提供大量的信息来显示磁盘是如何被利用的,以及Linux花费了多长时间来等待将请求提交到磁盘。
6.2.2.1 磁盘I/O性能相关的选项和输出
iostat用如下命令行调用:
iostat [-d] [-k] [-×] [device] [interval [count]]
与vmstat很相似,iostat可以定期显示性能统计信息。不同的选项可以改变iostat显示的统计数据,如表6-6所示。

iostat默认输出显示的性能统计信息如表6-7所示。

当你使用-x参数调用iostat时,它会显示更多关于磁盘I/O子系统的统计信息。这些扩展的统计信息如表6-8所示。
iostat是一个有用的工具,它提供了迄今为止我所发现的最完整的磁盘I/O性能统计信息。虽然vmstat非常普及,并且提供了一些基本的统计信息,但是iostat更加完备。如果你的系统已经安装了iostat并且可用,那么当系统存在磁盘I/O性能问题时,首先使用的工具就应该是iostat。

6.2.2.2用法示例
清单6.5给出了iostat运行的一个示例,一个磁盘基准测试程序向位于/dev/hda2分区上的文件系统写入一个测试文件。iostat显示的第一个采样是自系统启动开始时系统总的平均情况。第二个采样(及其后内容)是每个时间间隔为1秒的统计数据。
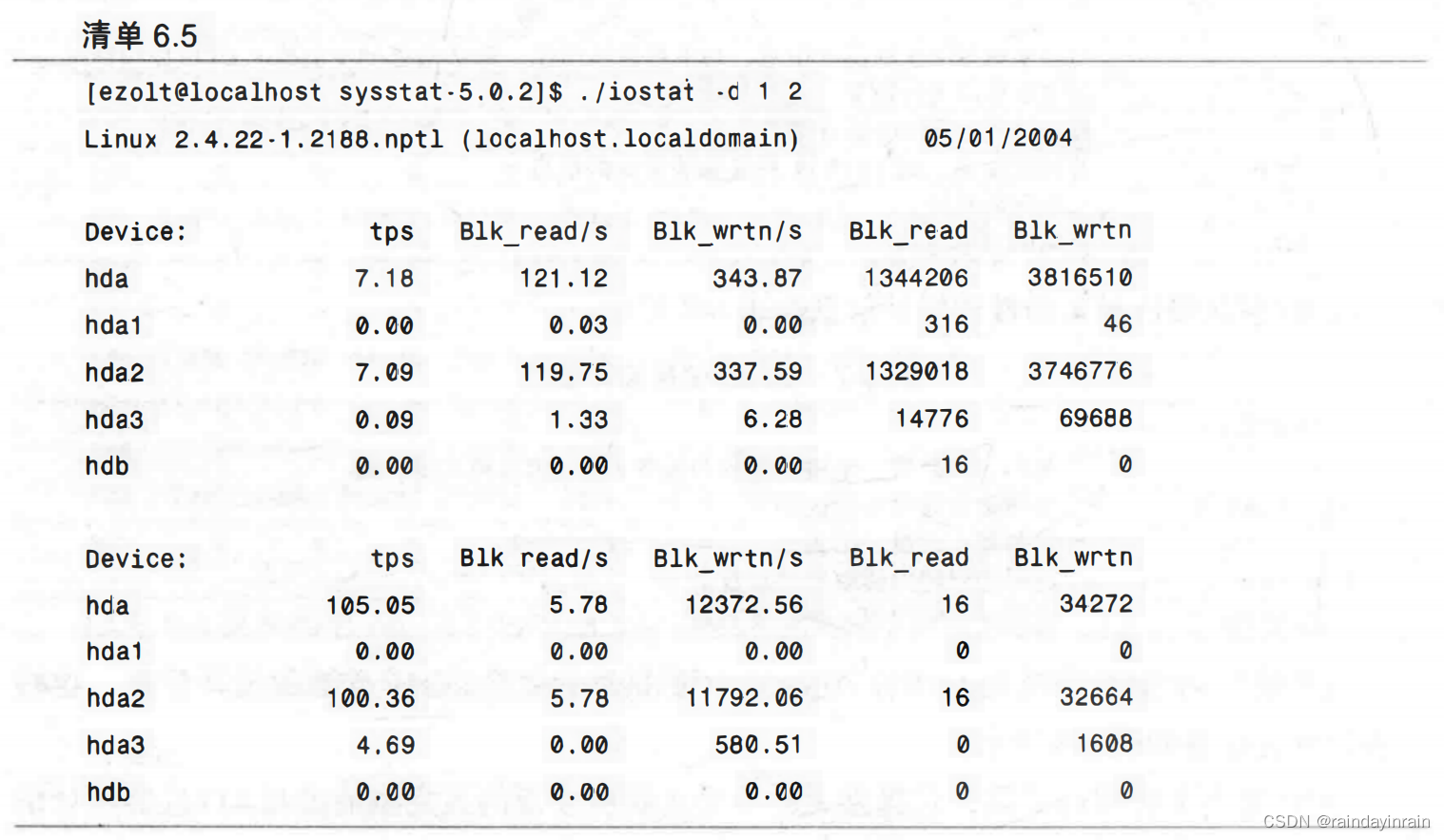
上面例子中一个有趣的地方是,/dev/hda3不太活跃。在被测试的系统中,/dev/hda3是一个交换分区。这个分区记录的任何活动都是由内核将内存交换到磁盘导致的。通过这种方式,iostat提供了一种间接方式来确定系统中有多少磁盘I/O是交换造成的。
清单6.6显示了更多的iostat输出。

在清单6.6中,你可以看到平均队列长度相当高(约237~538),其结果是,请求需等待的时间(约422.44~538.60毫秒)远远高于请求服务所花费的时间(7.63~11.90 毫秒)。这么高的平均服务时间,再加上利用率100%的事实,都表明了该磁盘处于完全饱和状态。
扩展iostat输出提供了太多的统计信息,使得它只适合在很宽的终端上的单行显示。但是,在识别成为瓶颈的特定磁盘时,这些信息几乎全是你所需要的。
6.2.3 sar(II)
第2章中曾经讨论过,sar可以收集Linux系统多个不同方面的性能统计信息。除了CPU和内存之外,它还可以收集关于磁盘I/O子系统的信息。
6.2.3.1磁盘/O性能相关的选项和输出、
当使用sar来监视磁盘I/O统计数据时,你可以用如下命令行来调用它:
sar d [ interval [ count ] ]
通常,sar显示的是系统中CPU使用的相关信息。若要显示磁盘使用情况的统计信息,你必须使用-d选项。sar只能在高于2.5.70的内核版本中显示磁盘I/O统计数据。表6-9对其显示信息进行了说明。

扇区数直接取自内核,虽然有可能发生变化,但通常情况下,其大小为512字节。
6.2.3.2 用法示例
在清单6.7中,sar被用于收集系统设备的I/O信息。在列出设备时,sar使用的是它们的主设备号和次设备号,而不是它们的名字。
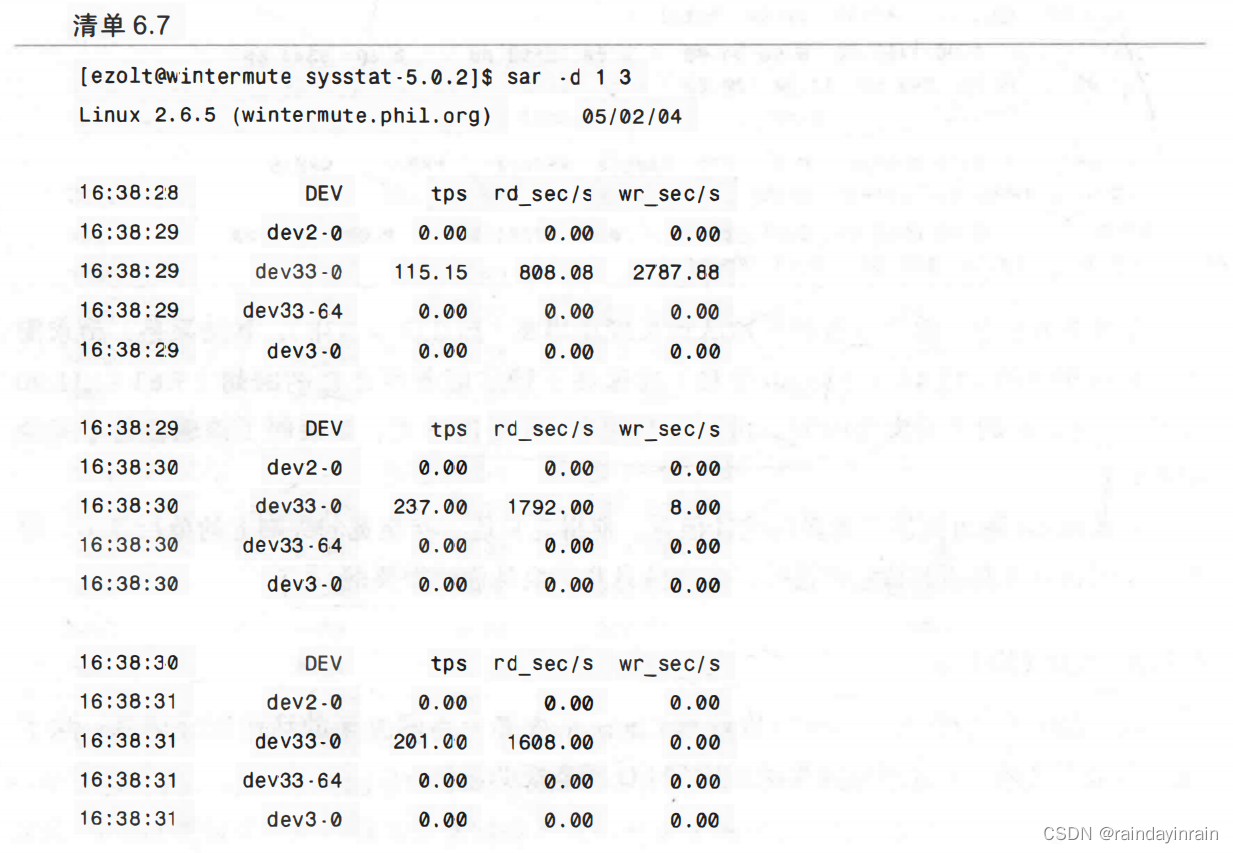
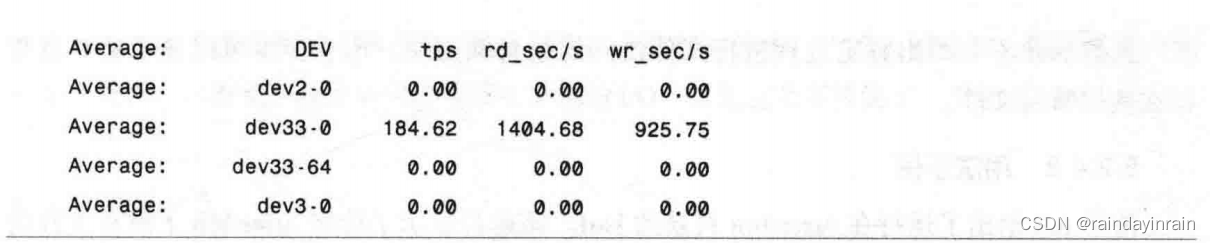
与iostat相比,sar给出的磁盘I/O统计信息数量是有限的。但其可以同时记录多个不同类型统计信息的特点可以弥补这些缺点。
6.2.4 lsof(列出打开文件)
lsof提供了一种方法来确定哪些进程打开了一个特定的文件。除了跟踪单个文件的用户外,lsof还可以显示使用了特定目录下文件的进程。同时,它还可以递归搜索整个目录树,并列出使用了该目录树内文件的进程。在要筛选哪些应用程序产生了I/O时,lsof是很有用的。
6.2.4.1磁盘I/O性能相关的选项和输出
你可以使用如下命令行调用1sof来找出进程打开了哪些文件:
lsof [-r delay] [+D directory] [+d directory] [file]
通常,lsof显示的是使用给定文件的进程。但是,通过使用+d和+D选项,它可以显示多个文件的相关信息。表6-10解释了1sof的命令行选项,它们可用于追踪I/O性能问题。

在展示哪些进程正在使用指定文件时,lsof就会显示表6-11说明的统计信息。

虽然lsof不会给出特定进程进行文件访问的数量和类型,但它至少可以显示哪些进程正在使用特定文件。
6.2.4.2 用法示例
清单6.8给出了运行在/user/bin目录的lsof。该运行显示了访问/user/bin下所有文件的进程。
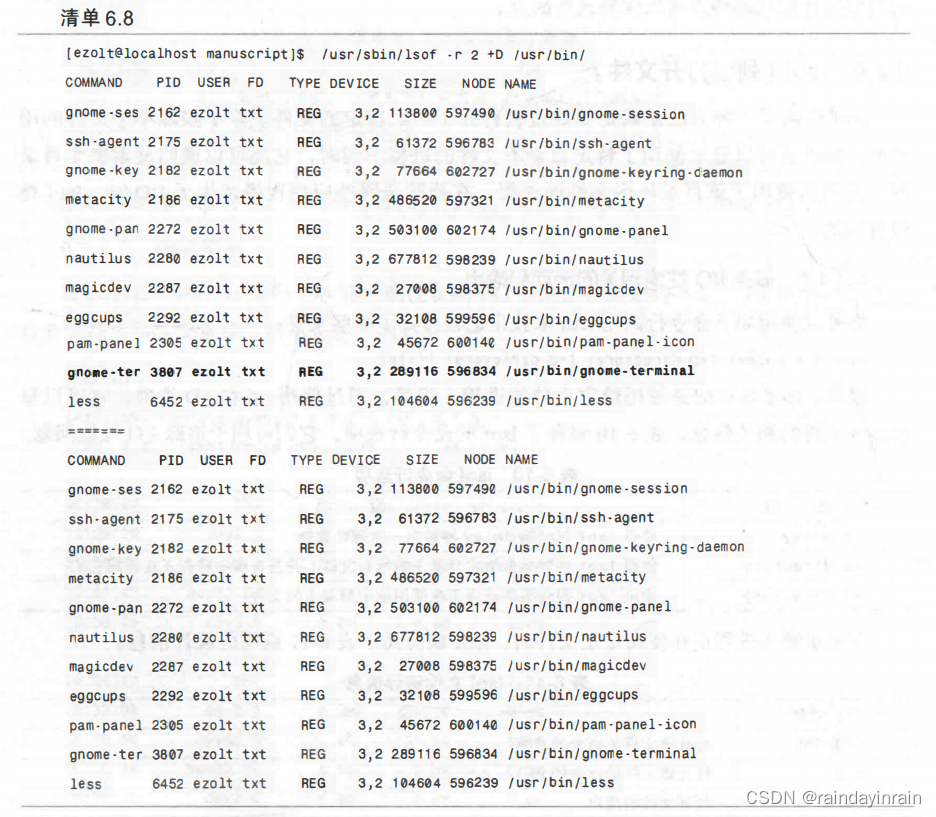
我们特别看看进程3807,它使用了文件/user/bin/gnome-terminal。根据FD列给出的txt,该文件是一个可执行文件,使用它的命令的名称为gnome-terminal。这是合情合理的,因为运行gnome-terminal的进程必须打开这个可执行文件。需要注意的一个有趣的现象是,这个文件位于设备“3,2”上,其对应的是/dev/hda2。(通过执行ls-la/dev并查看通常显示大小的输出字段,你就可以发现所有系统设备的设备号。)如果你知道某个设备是I/O瓶颈的源头,那么了解文件位于哪个设备就会有所帮助。lsof具有一个独特的能力,它能根据打开文件描述符回溯到单个进程。尽管它不会显示哪些进程有大量的I/O,但是它确实提供了一个起点。
6.3 缺什么
所有的Linux磁盘I/O工具都可以提供关于特定磁盘或分区的使用信息。可惜的是,当你确定了某个磁盘是瓶颈之后,没有工具能够帮助你找出是哪个进程导致了这些I/O流量。
一般情况下,系统管理员比较了解哪个应用程序在使用磁盘,但情况并不总是这样。比如,很多时候我正在使用我的Linux系统,而磁盘却开始无缘无故地频繁读写。通常,我可以运行top来找出可能导致这个问题的进程。通过剔除那些我认为与I/O无关的进程,一般就可以找出罪魁祸首。但是,做到这一点就需要具备相应的知识,了解各种应用程序应该做什么。而且这种方式也容易出错,因为对哪些进程不会导致问题的猜测有可能是错误的。此外,对一个有着多个用户或运行多个应用程序的系统来说,要确定哪个应用程序可能引发问题常常不太实用也不太容易。其他的UNIX系统支持ps中的inblk和outblk参数,可以向你显示特定进程的磁盘I/O数量。目前,Linux内核不跟踪进程的I/O,因此工具ps无法收集这些信息。
你可以用lsof来确定哪些进程访问了特定分区上的文件。在列出了访问文件的全部PID后,你就能够对每个PID使用strace,找出具有大量I/O的那一个。虽然这种解决方法有效,但它治标不治本,因为访问一个分区的进程可能很多,且关联并分析每个进程的系统调用也很费时。同时,这还可能错过短进程,而在跟踪进程时,还有可能严重减缓它们的速度。
在这一点上,Linux内核是可以被改进的。若能快速追踪哪些进程产生了I/O,将使得诊断I/O性能相关问题更加迅速。
6.4 本章小结
本章介绍了Linux磁盘I/O性能工具,它们能用于提取关于系统级(vmstat)、特定设备(vmstat、iostat、sar)以及特定文件(lsof)的磁盘I/O使用信息。本章说明了不同类型的I/O统计信息,以及如何用I/O性能工具从Linux抽取这些统计数据。此外,本章还对当前工具主要的局限性和未来可发展的领域进行了讨论。
下一章介绍的工具将能够让你确定网络瓶颈的成因。