目录
📚硬件基础
📚基于块的排序索引方法
🐇BSBI算法(blocked sort-based indexing)
📚内存式单遍扫描索引构建方法
🐇SPIMI算法(single-pass in-memory indexing)
📚分布式索引构建方法
📚硬件基础
- 访问内存数据比访问磁盘数据快得多。
- 进行磁盘读写时,磁头移到数据所在的磁道需要一段时间,该时间称为寻道时间。寻道期间并不进行数据的传输。
- 操作系统往往以数据块为单位进行读写。因此,从磁盘读取一个字节和读取一个数据块所耗费的时间可能一样多。也就是说,将一大块数据从磁盘传输到内存比传输许多小块要快。
- IR系统的服务器往往有数GB甚至数十GB的内存,其可用的磁盘空间大小一般比内存大小要高几个数量级。
📚基于块的排序索引方法
- 面向静态文档集的高效单机索引算法
- 之前提出的倒排索引构建方法(如下),对于小规模文档集来说,均可在内存中完成。在大规模文档集条件下,需要引入二级存储介质来构建索引。
- 扫描文档集合得到所有的词项-文档ID对。
- 以词项为主键,文档ID为次键进行排序。
- 将每个词项的文档ID组织成倒排记录表。


- 现在将词项用其ID来代替,每个词项的ID都是唯一的。我们可以在处理文档集之余将词项映射成其ID(单遍扫描)。或者在一种两边扫描的方法中,第一遍扫描得到词汇表,第二遍扫描才构建倒排索引。
- 这里以Reuters-RCV1语料的统计数据为例。

- Reuters-RCV1语料约有一亿个词条,每个占4B,存储所有的词项ID-文档ID对需要0.8GB存储空间。
- 对大规模文档集而言,将所有词项ID-文档ID放在内存中进行排序是非常困难的。对于很多大型语料库,即使经过压缩后的倒排记录表也不可能全部加载到内存中。
- 由于内存不足,我们必须使用基于磁盘的外部排序算法。对该算法的核心要求就是:在排序时尽量减少磁盘随机寻道的次数。
🐇BSBI算法(blocked sort-based indexing)
- BSBI(blocked sort-based indexing algorithm,基于块的排序索引算法)是一种解决办法:
- 将文档集分割成几个大小相等的部分。
- 对每个部分的词项ID-文档ID对排序。
- 将第2步产生的临时排序结果存放到磁盘中。
- 将所有的临时排序文件合并成最终的索引。
- 在该算法中,我们选择合适的块大小,将文档解析成词项ID-文档ID对并加载到内存,在内存中快速排序。将排序后的结果转换成倒排索引格式后写入磁盘。然后将每个块索引同时合并成一个索引文件。
- 以该算法应用到Reuters-RCV1语料库为例,它要构建的倒排记录数目大概有1亿条,假定内存每次能加载1,000万个词项ID-文档ID,那么算法最后产生10个块,然后将10个块索引同时合并成一个索引文件。
- 合并时,同时打开所有块对应的文件,内存中维护了为10个块准备的读缓冲区和一个为最终合并索引准备的写缓冲区。每次迭代中,利用优先级序列(即堆结构)选择最小的未处理词项ID进行处理。读入词项的倒排记录表并合并,合并结果写会磁盘。

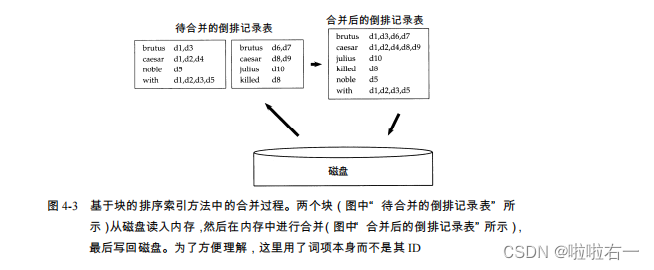
- 由于该算法最主要的时间消耗在排序上,因此其时间复杂度为 Θ(TlogT),其中 T 是所需要排序的项数目的上界(即词项 ID-文档 ID 对的个数)。然而,实际的索引构建时间往往取决于文档分析(PARSENEXTBLOCK)和最后合并(MERGEBLOCKS)的时间。
📚内存式单遍扫描索引构建方法
- 基于块的排序索引算法有很好的可扩展性,但缺点是需要将词项映射成其ID,因此在内存中保存词项与其ID的映射关系,对于大规模的数据集,内存可能存储不下。
- SPIMI(single-pass in memory indexing,内存式单遍扫描索引算法)更具可扩展性,它使用的是词项而不是其ID,它是将每个块的词典写入磁盘,对下一个块则重新采用新的词典。
🐇SPIMI算法(single-pass in-memory indexing)
- 算法逐一处理每个词项-文档ID,若词项是第一次出现,则将其加入词典(最好通过哈希表实现),同时建立一个新的倒排记录表;若该词项不是第一次出现,则直接返回其倒排记录表。注意:这里倒排记录表都是在内存中的。
- 向上面得到的倒排记录表增加新的文档ID。

- 不同于BSBI,这里并没有对词项ID-文档ID排序。
- 内存耗尽时,对词项进行排序,并将包含词典和倒排记录表的块索引写入磁盘。这里,排序的目的是方便以后对块进行合并。
- 重新采用新的词典,重复以上过程。
其实SPIMI和BSBI并没有太多的区别。他们都是基于块来做索引构建,然后将块合并得到整体的倒排索引表。不同的是BSBI需要在内存维护词项和其ID的映射关系,另外BSBI的倒排记录表是排序过的,而SPIMI没有排序。
- 优点:
- 不需要排序操作,处理速度更快
- 保留了倒排记录表对词项的归属关系,节约内存
- 时间复杂度:SPIMI 算法的时间复杂度是 Θ(T),这是因为它不需要对词项-文档 ID 对进行排序操作, 所有操作最多和文档集大小成线性关系。
📚分布式索引构建方法
- 实际中,文档集通常都很大。尤其是Web搜索引擎,Web搜索引擎通常使用分布式索引构建算法来构建索引,往往按照词项或文档进行分割后分布在多台计算机上。大部分搜索引擎更倾向于采用基于文档分割的索引。
- 分布式索引构建方法是基于MapReduce。MapReduce中的Map阶段和Reduce阶段是将计算任务划分成子任务块,以便每个工作节点在短时间内快速处理。
大数据|MapReduce模型 | Hadoop MapReduce的基本工作原理
大数据 | 实验一:大数据系统基本实验 | MapReduce 初级编程
大数据 | 实验二:文档倒排索引算法实现
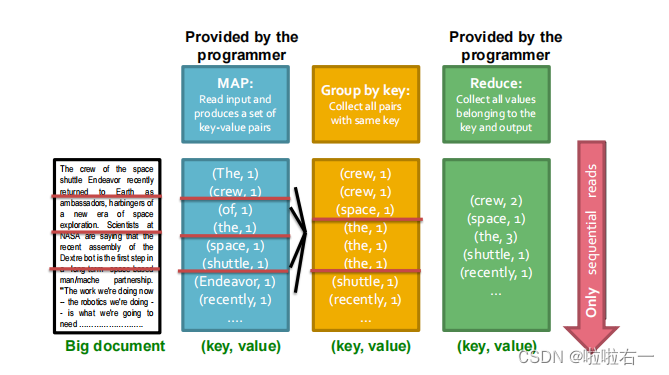
- MapReduce的Map阶段将输入的数据片映射成键-值对即(词项ID,文档ID),这个map阶段对应于BSBI和SPIMI算法中的分析任务,因此也将执行map过程的机器称为分析器(parse),每个分析器将输出结果存在本地的中间文件。
- 在reduce阶段,我们将同一个键(词项ID)的所有值(文档ID)集中存储,以便快速读取和处理。
参考博客:
-
信息检索导论第四章-索引构建








![[人工智能-综述-12]:第九届全球软件大会(南京)有感 -1-程序员通过大模型增强自身软件研发效率的同时,也在砸自己的饭碗](https://img-blog.csdnimg.cn/41aab13b3f8a4e9782dbb7b477900288.png)